领域词义关联实验数据获取的一些方法
2016-01-14王忠振
王忠振
摘要:领域关联处理就是处理网络信息中各领域中的词汇关联,该文将应用到维基百科上的分类来获取特征词,用这些特征词从维基百科、百度搜索和新浪微博中获得网络信息。这里的网络信息内容包含有文字、图片、声音、视频等,因此在获取信息时,需要对网页内容进行预处理,去除大量的无用信息,包括图片、声音、视频等。
关键词:特征词;语料;领域
中图分类号:TP18 文献标识码:A 文章编号:1009-3044(2015)19-0007-04
在处理领域词义关联过程中,要获取领域的特征词库,并以其做了维基百科的词条进行爬取语料;特征还将做了百度搜索和新浪微博的关键字进行相关数据的获取。由于网络资源极其丰富,做全网测试难度较大,这里从维基百科、百度搜索和新浪微博上获取相关领域语料,涉及对不同形式的网站进行获取语料,这里就需要多模式爬虫,如今互联网上的语料数据基本都是通过“网络机器人”来实现的,本文的语料从通过三种方式自动提取语料的程序:
1维基百科信息的爬取
图1中可以看出维基百科词条的一类形式,可依据领域特征词对特定词条进行爬取,对词条内相关词条的属性形成内链接进行第二层爬取,对网页去除噪音等处理,通过爬取得到领域文本集合。由于维基百科语料中存在汉语的繁体字,因此有必要做繁体向简体转换操作。
这里“词条”都是维基百科的基本单元,“词条”由一篇文章进行解释,可能包含有图片,有些复杂的词条页面图可能还包含结构化、模板化的解释,图1是维基百科中有代表性的词条,其词为“护士”,其词为同义词为“护理人员”,词条里有对词汇解释的内链接,可以根据自己的兴趣跳转到属性解释页面;有涉及同义词的重定向,重定向就是含义相同而表述不同的词条用相同的页面来解释;而这里歧义比较大的例如在解释的时候,涉及护士工作或学习地方有“学校”,“学校”作为内链接所得到的语料内容虽然是护士工作或学习的地点,但内容应该属于教育领域;词条页面里列举图片一般是起到典型的解释作用,比如“南丁格尔”。
图2是对维基百科内链接的一个图示。
由于领域语料的丰富,需要从领域中找出领域特征词,这个数据量是少的,找出特征词的URL队列,对由Java开发的Ti-ka1.4的开源项目进行扩展来实现模块功能。本文用它来从网上抓取想要的资源,它具有良好的可扩展性,对其实现的功能进行丰富,可以实现自动爬取。首先要在开始爬取时提供特征词队列的维基的URL给种子文件,获得了初始的URL后,在爬取维基词条过程中,不断从当前词条中获取词条属性词的URL种子文件放人URL,直到满足功能模块提供参数时停止。注意在新增加的URL中,对队列原有的URL种子列表进行匹配,如果在原来队列中存在,则不进行添加,否则添加。
这里对深度优先爬虫进行修改,因对维基百科中进行爬取,往往会对词条内一层内链接进行再爬取,因其一般会对词条有解释作用,有助于深度学习算法对语料集中领域词义关联进行计算,这里词条的内链接URL会被提取,需要对链接地址进进行查复,就在爬取的队列中是否存在,如果存在则抛出,否则把链接地址追加爬取队列的底部等待爬取,也就达到了去重目的。歧义的词条页面语料出现毕竟其数据很少,所以在大量的领域语料中一般其词频的阈值不会构成干忧。
这里爬虫获取语料属于预定领域的可以被称为正领域,否则称为负领域,根据上述方法,如果用户提供的特征词越丰富爬全率越高;用户提供的特征词越准确则爬准率越高。在这种情况下,爬准率和爬全率显得更为重要,分别测试了领域语料的准确性和完整性,这里通过领域区分的混合矩阵可以得出这两个特性的评估标准,高的爬全率一般是牺牲爬准率为代价的,就是爬取语料越多,语料里跨领域的信息就越多,因此语料数量适中就好。
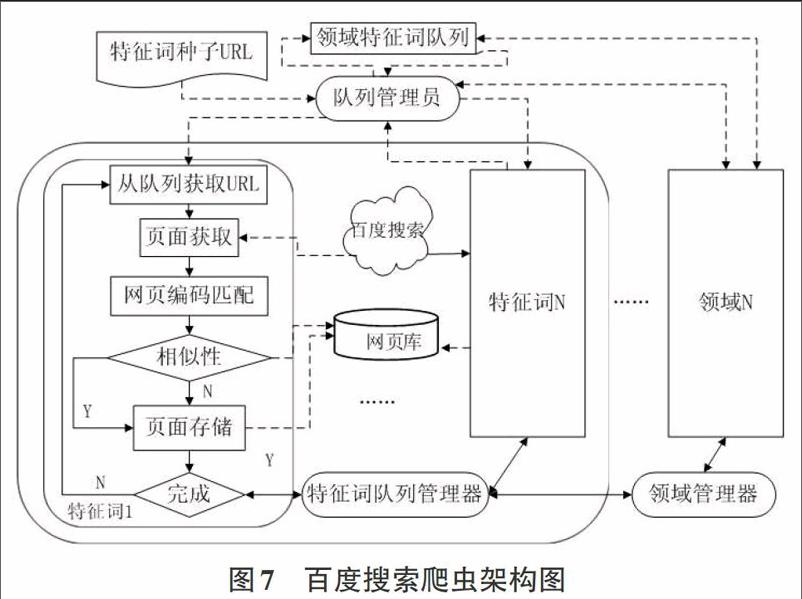
2百度搜索信息的爬取
因为维基百科具有两个优势:没有爬虫陷阱和没有拒绝服务攻击。相比之下百度百科API设置了频繁访问次数和时间间隔,因此适合广度搜索,并设置爬取时间间隔。
2.1百度搜索信息获取的方法
为了获取各大门户网站上关于某个领域的新闻情况时可以通过百度搜索,由于本文所做的是一段时间内的研究,因此这里对领域内每条特征词进行两百条的搜索并进行爬取,经兴趣小组人工检测,这个数量相当于一个月的新闻总数,除非在此领域有重特大事件发生。百度百科没有提供API接口并且设置了频繁访问次数和时间间隔,这大大增加了获取语料的难度。
图5中可以看出,在百度搜过中,每个搜索词对应各类型站点,网页的编码形式也不尽相同,因此对每一个网页都需要做出预处理。
这里不同于维基百科,因为每个网页可能属性不同的页面,课题的需求就是对网页的正文部分进行爬取,但这里存在的问题就是,网页i(1《i≤n)与网页i(1≤j≤n)可能在内容大部分相似;特征词2中的网页也可能与特征词1里的网页相似,这里需要对内容相似部分进行去重处理,本文采用余弦向量法进行相似性检测。
其实百度百科的汉语领域语料相当全面,但由于其设定对用户的频繁访问限制,因此不适合做类似于维基百科的领域语料。上面领域的语料体系丰富后,要对网上的关于某领域的新闻动态进行追踪,这里用到百度搜索。这里的爬取方法与上面的不同,这里通过特征词表提供的词汇输入到队列,利用百度搜索引擎接口,对每个特征词搜索200条,这个值不是固定,如果体系一直在运行状态,可以改成20条,因为每天更新的信息数量并不是特别大,除了新发生的热点事件。这里需要强调即使是热点事件,很多新闻的内容都大致相同,所以这里需要相似性计算,如计算得出两个以上的新闻内容相似性高则只保留一篇。
2.2百度搜索信息获取模块的去重
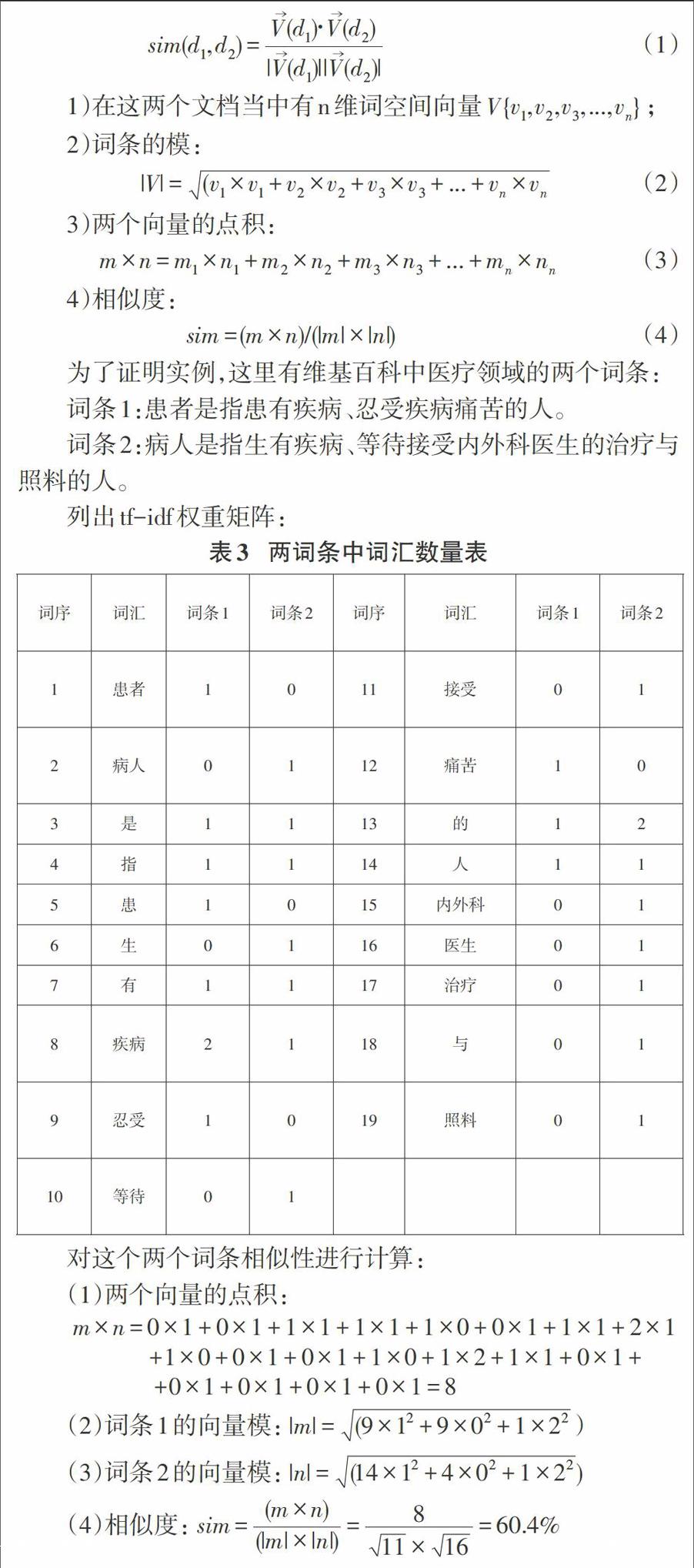
两个文本的相似性检测,文本主要是由词和短语对比构成,所以这里需要对文本进行分词,分词的方法可以采用以字符串为匹配的分词方法,是在爬取后进行分词,把分词的文本另存储到备份目录,因此其相似度用单位向量内积的方法检测:
为了证明实例,这里有维基百科中医疗领域的两个词条:
词条1:患者是指患有疾病、忍受疾病痛苦的人。
词条2:病人是指生有疾病、等待接受内外科医生的治疗与照料的人。
列出tf-idf权重矩阵:对这个两个词条相似性进行计算:(1)两个向量的点积:
因此在本文中,即便内容不一致的两个文档也运用空间向量模型运算都可能有很高的相似度。如果百度搜索爬取的网页出现在爬取的文本B与语料库中文本A相似度高于90%的就被判定其相似,导致文本B不存于语料库中。这里还有一个好处就是,进行相似性匹配时,为各别网站的拒绝服务式攻击延迟了时间。
2.3百度搜索信息获取中的爬准率和爬全率
在百度搜索中,有些领域特征词虽然属于这个领域,由于媒体编辑的随意性,导致有些语料并不属于这个领域,因此影响爬准率;而且百度搜索中,虽然能够链接属于这个领域的,但其网页解析出的内容没有价值,比如本文是作词义关联的,网页中如有涉及图片视频的内容,有些就不是课题需要的内容,这影响爬全率。百度的爬全率不同于维基的爬全率,维基的爬取基数是不可预测的,而百度搜索的是设定固定的值,那么能爬下来的信息所占的比重就是百度的爬全率;百度的爬准率是在爬下来的数据中,属于预设领域语料所点的比重:
本文中每个特征词设置了200条,比医疗这个领域的“护士”特征词,其中有4条是图片或视频新闻,不采集,因此爬全率是:96%;在96篇文档中65篇是护士招聘或影视信息、4篇是游戏内容,不属于课题需要研究的内容,因此爬准率是:(96-69)/96=28%。也不能因为一个特征词就不采取百度搜索的语料,因为领域的特征词并不只是一个,像“导弹”就有82%爬准率,这里跟每个时间是否在该领域内有热点事件有关,百度搜索的爬取有助于热点事件的追踪。
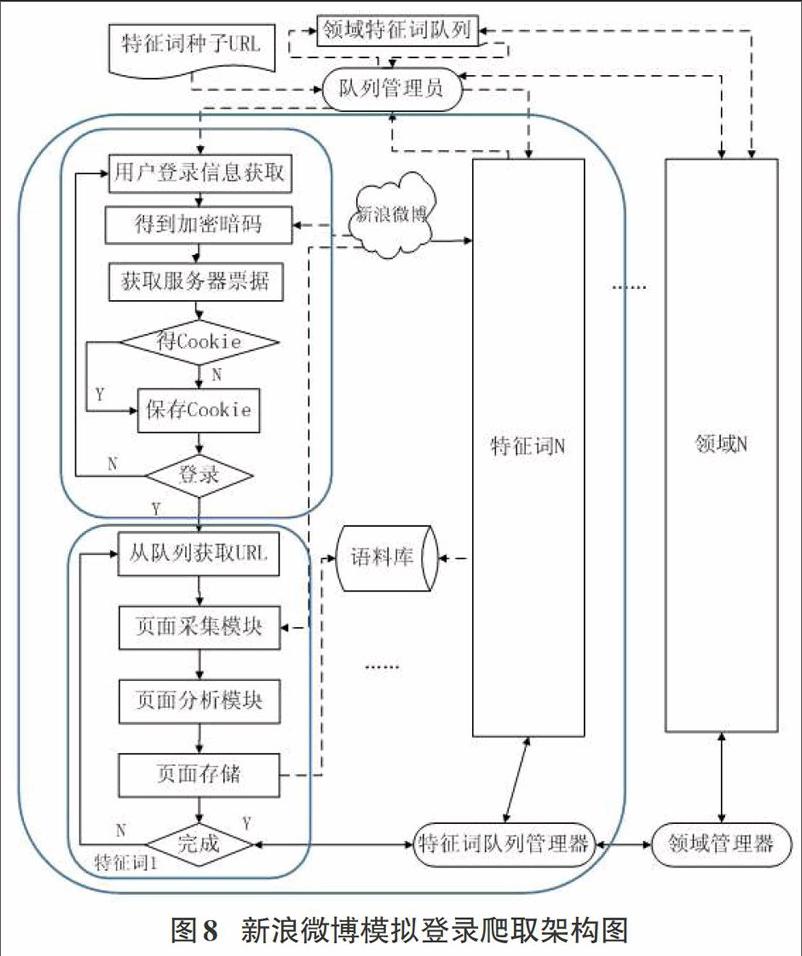
3新浪微博信息的爬取
中国的微博用户数量已成世界第一,特别是新浪微博,作为传播媒介,广大用户都成为微博信息传播的驱动力,对新浪微博上博文进行爬取,有效分析每天产生的上亿条微博对热点事件的影响。但是传统的网络爬虫方式没有新浪微博的身份验证,获取的微博数量有限,而调用新浪API进行爬取,也会受到调用次数的限制。
因此采用基于爬虫模拟登录的策略实现微博爬取。
4多源语料并行爬取框架
为了节省整个体系中服务器的处理器、硬盘、网络的开消,上述三种资源开销都可能成为体系的瓶颈,网络受限于带宽的控制、服务器的处理速度以及磁盘的寻道和传输时间。如需要提高爬虫效率,则需要设置合适的并发线程或进程服务数目。
软件工程中要求,“高内聚、低耦合”,领域词义关联体系在各个模块部分中要求把数据处理好,每个块块都只有一个入口,一个出口,这样才能保证输入输出数据一致。在语料爬取模块分为三个部分:维基百科,由于这部分语料更新较慢,所以提前做好的;百度新闻,则是面对各大网站的新闻,还包换个人的博客,论坛的帖子等,这里先不考虑其语料的真实性;新浪微博,以每天人们对新兴事件的发帖、评论或转发,也以继续对热点事件新介入的因素进行关注和评论。
