基于关联规则的网络行为分析
2016-01-12刘宗成,张忠林,田苗凤
基于关联规则的网络行为分析
刘宗成,张忠林,田苗凤
(兰州交通大学 电子与信息工程学院,甘肃 兰州730070)
摘要网络用户访问网站的过程中,产生了大量的用户浏览网页的相关记录,隐含着用户在上网过程中的行为习惯。但其中潜在的用户信息难以发现。因此,急需有效的方法提取这些数据中的信息,数据挖掘应用而生。其中,关联规则技术是应用广泛的技术之一。文中利用Apriori算法对Web结构数据进行关联规则挖掘,所得到的规则反映出页面之间的链接关系。分析挖掘结果可得到用户访问的行为规律,为相关网站的安全性和优化改进提供有效的决策依据。
关键词Apriori算法;网络日志挖掘;关联规则;行为分析
收稿日期:2015-03-09
基金项目:甘肃省科技支撑计划基金资助项目(1104GKCA016)
作者简介:刘宗成(1988—),男,硕士研究生。研究方向:数据挖掘。E-mail:liuzongcheng1234@163.com
doi:10.16180/j.cnki.issn1007-7820.2015.09.004
中图分类号TP301.6
Analysis of Network Behaviors Based on Association Rules
LIU Zongcheng,ZHANG Zhonglin,TIAN Miaofeng
(School of Electronic and Information Engineering,Lanzhou Jiaotong University,Lanzhou 730070,China)
AbstractThe large number of web browsing records contains the implicit behaviors of users on the Internet,which however is difficult to find.Therefore,effective methods for extracting the information from the data,or the data mining applications are in urgent need.Among them,the association rules technology is one of the widely used.This paper adopts the Apriori algorithm to analyze the Web structure data mining for association rules,and the resulting rules reflect the page link between the relationships.Analysis of the results reveals the pattern of user access behaviors,providing an effective decision-making basis for the security and improvement of websites.
KeywordsApriori algorithm;web log mining;association rules;behavior analysis
随着网络信息爆炸式的增长给人们带来了诸多不便。全球每天约有数以百万计的网页诞生,有数亿人次通过浏览器访问各种网站、进行在线交易等活动,由此产生数以亿计的数据[1]。但这些数据长期以来无法得到充分利用。因此,人们迫切需要一种有效的方法能从海量的网络资源中获取可用的信息或知识,因此,数据挖掘[2]应运而生。具体而言,数据挖掘是通过一定的技术,从海量的网络数据中分析获得有趣规则,发现隐含的有用知识的过程,是网络信息中知识发现的重要方法。目前,网络数据挖掘主要分为内容挖掘、结构挖掘和使用挖掘[3]。其沿用了Robot、全文检索等网络信息检索中的优秀成果,同时综合运用了人工智能、模式识别、神经网络领域的各种技术[4]进行信息处理。为确保网络信息的安全,现有的技术,如防火墙、入侵检测、身份认证等[5],是不能完全保证的。其主要原因是这些技术均侧重于对已发生的攻击行为做出响应,彻底解决这一问题的根本策略应当从网络行为安全分析入手。
1网络行为及其安全性
通过对用户在上网过程中的一系列连续行为的处理,分析得出用户网络行为特征信息,可作为决策的一种数据支持。面对网络安全问题日益严重的现实,国内外众多专家和学者坚持不懈,积极研究如何提高网络安全性。一般,网络入侵检测[6]包括误用检测和异常检测,误用检测主要是依据模式匹配原理来进行检测的,正确率相对较高,但仅能检测已知入侵类型进行。异常检测主要依据特征比对原理进行检测,其能检测出未知的入侵类型,但误检率较高[7]。图1是常用的网络检测模式。

图1 常用的网络检测模式
后来出现的聚类分析、隐马尔可夫、模式匹配等检测方法,均是基于统计学或专家系统的检测,要求有较多的经验数据,准确率有时偏低[8-10]。
网络行为分析[11]也是一个数据挖掘的过程,是对网络行为异常的分析,但侧重点在于网络用户特征分析。网络行为分析尽可能将网络中不同节点存储的数据尽量融合起来进行综合分析,以便观察和发现网络内部的具体情况,主要目的在于挖掘网络中潜在的关键性的能够反映网络行为的信息,文献[12~13]分别从网络访问控制和网络行为模拟方面对网络行为分析进行了探讨。
2网络日志挖掘过程
由于互联网用户的持续激增,Web服务器中的日志数据也随之呈指数性增长。这些Web日志数据当中隐含着非常重要的数据资源之间的关联信息。Web日志的挖掘过程,一般分为4个阶段:原始数据采集、数据预处理、数据挖掘及对挖掘出的结果进行评估分析[1]。
原始数据的采集指对记录的用户访问信息数据有针对性地进行收集,即收集存储于服务器上的Web日志内容中所需的数据项。
数据预处理是一个复杂的过程,包括数据清理、转换和规约等一系列过程,是进行挖掘的基础。
数据挖掘是在上述过程处理结果的基础上进行的,应用挖掘技术,例如关联规则技术,找出潜在的规则,模式等。
结果评估分析指根据实际对挖掘结果进行分析、解释,并利用它们做出决策,指导实践。
3关联规则算法
关联规则[14]算法是数据挖掘中的重要算法之一。数据挖掘是一种从海量数据中挖掘潜在知识的方法,关联规则描述了同一事物中不同属性之间的关联关系和依赖关系。关联规则挖掘步骤可分为两个子步骤:找出所有频繁项集、由频繁项集产生关联规则。其中,找出所有频繁项集的效率对关联规则挖掘的整体效率起到关键作用。Apriori算法是一种成熟的,经典的关联规则挖掘算法,其采用迭代法挖掘频繁项集,过程主要分为两步:连接步和剪枝步[15]。
Apriori算法描述如下:
假设D为事务数据库,Ck为候选项集,Lk为频繁项集,min_support为设定的最小支持度。
算法:Apriori。
输入:D;min_support。
输出:Lk。
(1)L1=find_frequent_1_itemsets(D);
(2)for (k=2;Lk-1≠Φ;k++) {
(3)Ck=apriori_gen(Lk-1,min_support);//由频繁k-1项集生成候选k项集
(4)for each transactiont∈D
(5)Ct=subset(Ck,t);//构造t的候选子集
(6)for each candidatec∈Ct
(7)c.count++;
(8)}
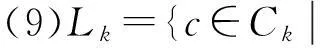
(10)}
(11)returnL=∪kLk;
其中,函数apriori_gen(k-1)利用频繁k-项集生成候选项集,算法描述如下:
1)for each itemsetl1∈Lk-1
2)for each itemsetl2∈Lk-1
3)ifl1[1]=l2[1]∩l1[2]=l2[2]∩…∩l1[k-1]=l2[k-1]
then {
4)c=l1×l2;//连接
5)if has_infrequent_subset(c,Lk-1) then
6)deletec;//剪枝
7)else addctoCk;
8)}
9)returnCk;
函数has_infrequent_subset()实现了候选k-项集的剪枝,即删除k-项集中非频繁项(k-1)-项子集。其算法描述如下:
(1)for eachk-1 subsetsofc
(2)if nots∈Lk-1then
(3)return TRUE;
(4)return FALSE;
关联规则算法是从事务数据库中存储的大量数据集合之间发现有趣的关联关系,用于帮助人们进行各种决策。文献[16]中介绍了不同的数据挖掘方法在网络安全中的应用,文献[17]利用数学模糊逻辑与关联规则相结合的方法检测异常。
4实例
在网络行为分析中,Web日志是重要的数据来源之一。因此,本文以某Web日志文件记录作为数据源,数据处理之后,运用Apriori算法进行关联规则挖掘分析,从而获得有关用户行为的信息。表1记录了日志文件中一些典型的内容。

表1 部分日志文件内容
在对Web日志文件中的数据进行挖掘之前,先要进行必要的数据预处理过程。数据预处理是对原始数据进行清理、过滤和标准化,将数据转化为需要的抽象类型,为下一步进行数据挖掘做好准备。在本文中,数据预处理时,选择用户会话级的数据,会话是指同一用户在某一次浏览网页过程中请求显示一个网页序列的过程。
为了方便分析,简化分析过程,在数据预处理之后,选取5个会话,并只保留相同类型的数据作为数据挖掘的对象。如表2所示,将IP分别以数字1到5代表,表示有5次会话,将URL分别以字母A~Z代表,表示访问页面地址的集合。在这5次会话中访问的页面地址是{A,B,C,D,E,F}。

表2 数据预处理结
根据表2,生成事务数据库表3,其中每个事务项(TID)包含一个地址项集。现假设最小支持度计数为2,即min_supp=2(这里所示为绝对支持度,因使用支持度计数,对应的相对支持度为2/6=33.3%)。
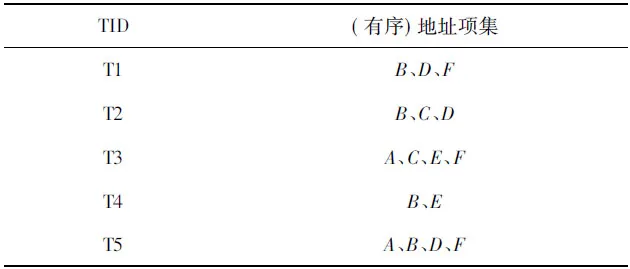
表3 事务数据库
利用表3的数据和Apriori算法挖掘频繁项集,挖掘到的频繁项集是{B,D,F}。根据挖掘出的所有的频繁项集,产生相应的关联规则。
给定用户最小置信度(min_conf)为70%,由频繁项集产生的关联规则是:
(1)B→D,c=3/4=75%(c代表该规则的置信度,下同)。
(2)D→B,c=3/3=100%。
(3)(B,F)→D,c=2/2=100%。
(4)(D,F)→B,c=2/2=100%。
上述关联规则反映了网页地址间的关联关系。因此,可根据得到的4条规则分析用户访问网页的行为。例如:
规则1B→D,c=3/4=75%,意味着用户在一次会话中访问了页面B之后,有75%的可能会去访问页面D。
规则3(B,F)→D,c=2/2=100%,反映出用户在一次会话中访问了页面B,F之后,有100% 的可能会去访问页面D,即肯定访问页面D。依据挖掘结果,发现用户的网络行为特征,分析用户网络行为的安全性。有针对性地优化网站链接、提高服务,使用户用较短的时间访问所需的页面。
5结束语
本文通过利用Web日志记录,运用关联规则算法中的Apriori算法对用户的网络行为进行分析,挖掘用户的网络行为特征,为优化网络服务,提高网络的安全性提供支持。
Apriori算法是数据挖掘中的经典算法之一,能够在海量数据中挖掘出关联规则,在网络行为挖掘中是比较适用的。但Apriori算法的效率较低,尤其当数据集规模较大时。这主要表现在:(1)Apriori算法要多次扫描数据集。当扫描海量数据时,该算法必定耗费大量时间,严重影响算法执行效率。(2)Apriori算法在执行过程中产生大量的中间项集。这势必要有大量空间用以存储这些中间项集,占用大量内存,影响算法执行效率。
基于上述缺陷,提出一种改进的Apriori算法,以提高效率,更好地运用于解决网络行为挖掘中去,是今后的主要研究工作。
参考文献
[1]冯凌,林杰,雷星晖.Web日志数据挖掘模型研究[J].计算机集成制造系统,2005,11(8):1073-1074.
[2]金燕,张玉峰.网络数据挖掘及其在面向Web的知识检索中的应用[J].现代图书情报技术,2003(6):55-57.
[3]吴小波,徐维祥.多支持度关联规则在网络使用挖掘中的应用[J].计算机工程与应用,2005(31):168-171.
[4]李村合.网络信息挖掘技术及其应用研究[J].情报科学,2002(11):1212-1214.
[5]缪红保,李卫.基于数据挖掘的用户安全行为分析[J].计算机应用研究,2005(2):105-107.
[6]杨宏宇,朱丹,谢丰,等.入侵异常检测研究综述[J].电子科技大学学报,2009,38(5):587-596.
[7]杨向荣,宋擒豹,沈均毅.基于行为模式挖掘技术的网络入侵检测[J].西安交通大学学报,2002,36(2):173-176.
[8]刘智国,张雅明,林立忠.基于粒子群LSSVM的网络入侵检测[J].计算机仿真,2010,27(11):136-140.
[9]郭亚周,高德远.模糊聚类分析在入侵检测系统中的应用研究[J].沈阳理工大学学报,2005,24(4):26-28.
[10]赵俊忠.入侵检测系统中检测技术的研究[J].计算机工程与应用,2005(2):11-13.
[11]江泓,何恩.行为分析技术及其在可信网络中的应用前景[J].信息安全与通信保密,2009(2):67-69.
[12]ZengBin,ZhangDafang,LiWenwei.Designandimple-mentationofanetworkbehavioranalysis-orientedIPnetworkmeasurementsystem[C].NZ:IEEEComputerSociety,2008:374-379.
[13]KimTaekyu.Ontology/dataengineeringbaseddistributedsimulationoverserviceorientedarchitecturefornetworkbe-havioranalysis[M].Arizona:UniversityofArizona,2008.
[14]王光宏,蒋平.数据挖掘综述[J].同济大学学报:自然科学版,2004,32(2):246-252.
[15]韩家炜,坎伯.数据挖掘:概念与技术[M].北京:机械工业出版社,2001.
[16]KimSeungwoo,ParkSanghyun,WonJungIm,etal.Privacypreservingdataminingofsequentialpatternsfornetworktrafficdata[J].InformationSciences:anInternationalJournal,2008,178(3):694-713.
[17]LuoJ,BridgesS.Miningfuzzyassociationrulesandfuzzyfrequencyepisodesforintrusiondetection[J].InternationalJournalofIntelligentSystems,2000,15(8):687-704.

