Hadoop 平台下森林物联网多环境参数关联研究
2016-01-09杨博文汪子炎刘晓峰朱正礼
杨博文+汪子炎+刘晓峰+朱正礼

摘要:基于南京某森林TB量级关于无线传感器网络持续记录的森林的大气温度、土壤湿度以及土壤温度的大数据,利用Google公司的Hadoop云计算平台对数据进行分析,进而研究气温、土壤湿度对土壤温度的影响。利用Hadoop平台下的MapReduce框架对传感器传回的数据进行噪声处理、二次排序等操作,并综合利用MATLAB、SPSS等软件对数据进行综合处理分析,进而研究气温土壤湿度对土壤温度的影响,而土壤温度对植株处于良好的生长状态具有重要现实意义[1]。
关键词:大数据;云计算;物联网;Hadoop;MapReduce
中图分类号:TP391 文献标识码:A 文章编号:1009-3044(2015)30-0200-04
Research on Relevance between Multiple Environmental Parameters in Internet of Things for Forest Based on Hadoop
YANG Bo-wen,WANG Zi-yan,LIU Xiao-feng,ZHU Zheng-li
(School of Information Science and Technology, Nanjing Forestry University, Nanjing 210037, China)
Abstract: The TB level of data about the atmospheric temperature, soil moisture, and soil temperature in Nanjings forest is measured by Wireless Sensor Networks. Researchers use Googles Hadoop cloud computing platform to analyze these data, and then study the effect of temperature and soil moisture on soil temperature. Researchers use framework of the MapReduce to carry out the data of the sensor data processing, sorting. In the end, researchers use MATLAB, SPSS and other software to analyze the data, and then to study the effect of temperature and soil moisture on soil temperature, which is considered of strategic importance for plant growth.
Key words:big data; cloud computing; Internet of Things; Hadoop; MapReduce
1 概述
Hadoop是Google公司提出的一个针对大量数据进行分布式处理的软件框架,并且实现了高吞吐率的数据读写以及强大的数据处理能力[2]。针对南京某森林TB量级关于传感器持续记录的森林的大气温度、土壤湿度、以及土壤温度的大数据,要对这大量的数据进行处理,研究它们之间的关系,使用传统的数据处理方法已不太适用。另外,传感器本身较脆弱,由于仪器损坏、电量不足等问题会产生大量的噪声数据,而对大量的噪声数据的处理,也是传统数据分析方法的难题。应用Hadoop平台对大量数据的处理具有十分大的优势。
该研究首先会利用Hadoop平台的MapReduce框架对数据进行初步去噪、去重操作,去除一部分无效数据。然后会对数据按气温递增的方式进行排序,如果气温相同,则按土壤相对湿度递增的方式排序。对数据排序的目的是为了方便取出气温相同的数据,进而研究土壤湿度和土壤温度之间的关系。接下来,则按一定方式取出部分数据,进行数据拟合。该研究会利用MATLAB进行数据拟合,从而对气温、土壤湿度与土壤温度的关系进行回归分析,以及会使用SPSS等软件对数据进行分析。
2 数据处理方法
2.1 MapReduce编程模型
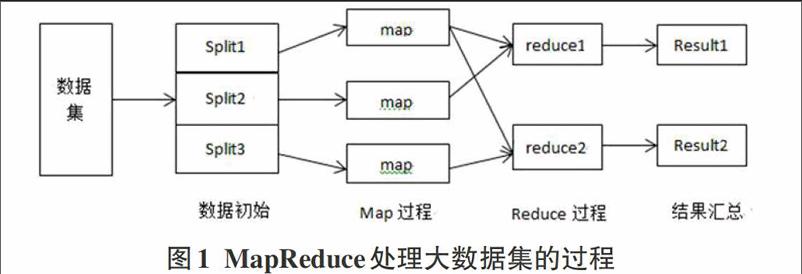
MapReduce是Hadoop平台下的一种处理大数据的并行编程模型框架,对于处理TB级及以上的大规模数据效果显著,并且它是一种标准的函数式编程模型[3]。MapReduce模型大致分为3个阶段,分别是数据初始阶段,Map和Reduce阶段,以及数据汇总阶段。MapReduce使用的是“分而治之”的处理思想,它把对大规模数据集的处理操作“分而治之”,处理思想是先把数据分发给一个主节点管理下的各个分节点,这个过程一般被称为Map过程。接下来,各个分节点完成数据的处理,然后将各自的结果整合,这个过程一般被称为Reduce过程。最后汇总为最终的结果。
MapReduce数据的处理方法是始终以
在Reduce阶段,各个Reducer把Map过程的输出
2.2基于 MapReduce的数据去噪、去重
由于传感器损坏、电量不足等会产生大量的错误数据,并且会产生一些和其他数据不相一致的数据,即噪声数据。去除噪声数据在研究过程中十分必要。
在这里,该研究只需要对数据进行初步去噪。利用MapReduce初步去噪过程十分简单,只需要在map过程中初步判断数据的正确与否。由于气温、土壤湿度、土壤温度在正常情况下具有一定的取值范围。在map过程中,如果数据超出了该范围,则在map过程直接舍弃该数据即可,不必输出键值对。
数据去重的宗旨是让初始数据中出现一次或多次的数据在输出结果中只出现一次。利用MapReduce的解决办法是将同一个数据的所有记录都交给同一个reduce节点,这个数据最后无论出现了多少次,只需要在最终结果中输出一次。具体就是让reduce的输入应该以数据作为K值,V值不作讨论,即任意。当reduce接收到一个
数据的去噪、去重在MapReduce中可以同时进行操作。具体实现伪代码如图2:
2.3基于 MapReduce的二次排序
对单个关键字的排序在该研究中并不能满足需求。针对大量数据的研究,需要对气温和土壤湿度进行排序,先按气温的升序排列数据,如果气温相同则按土壤湿度升序排序。以此进一步研究数据间的关系以及满足下一步分析的需要。
基于MapReduce二次排序,其基本思想是将两个数据组合抽象成一个数据,也就是把两个数据当成一个K值来处理,这就需要用户自定义一个针对此类型的排序方法[6]。在该map过程中,键值对的表现形式为<
2.4数据分析
2.4.1气温、土壤湿度与土壤温度之间的关系
为了能较直观地反映出三者之间的关系,拟通过三维图像来反应它们之间的关系。又由于数据量过于庞大,不便于直接分析,利用MapReduce编程模型,随机取出经过初步去噪、去重的5万组数据。再利用MATLAB软件进行三维图像拟合,绘画出了图像。图4是数据拟合后基于南京某森林关于气温、土壤温度、土壤湿度三者间的关系,土壤数据取自地表下5cm。
2.4.2气温对土壤温度的影响
进一步地研究大气温度对土壤温度的影响,将图4在气温和土壤温度间进行投影,得出气温和土壤温度间的关系,见图5。
由图5可见,土壤温度和气温间几乎呈现一次线性关系,气温越高,土壤温度也就越高。并且土壤温度在气温一定范围内波动。
2.4.3土壤湿度对土壤温度的影响
进一步研究发现,在气温一定的条件下,土壤湿度和土壤温度间有一定的关系。针对排序后的数据,首先分为多组相同气温下的数据,每组再随机取出10组数据进行处理,利用MATLAB软件,对一定气温下土壤湿度和土壤温度间的数据进行拟合分析。为了保证获取的关于土壤湿度温度间的数据的多样性,拟把R±0.1℃作为R℃。分别取R=15,R=20,R=25,R=30,画出其拟合图像如图6、图7、图8、图9。
结果表明,在气温一定的条件下,土壤温度与土壤湿度具有较高的关联性,其回归方程式如表1。此回归方程在土壤湿度为10%~50%范围内时结果较为准确。
3 结论
1)在该研究区内地表下5cm处的土壤温度和气温密切相关,土壤温度和气温呈线性关系,气温越高,土壤温度相应也会越高。土壤温度在一定程度上趋近于气温。
2)在气温一定的条件下,土壤温度是关于土壤湿度的二次函数关系,且土壤相对湿度在35%左右时,土壤温度达到最大值。
该研究在进行数据分析时处理方法较为简单,所以探索如何使用Hadoop平台进行大数据的相关数据前期处理工作是本研究的工作重点。此外,该研究对森林日常数据进行处理,缺乏极端天气情况下的数据,对极端气温土壤湿度对土壤温度的影响难以讨论。因此,长期收集森林相关数据显得很有必要,利用Hadoop平台讨论极端天气条件下气温土壤湿度对土壤温度的影响是将来研究工作的方向之一。
参考文献:
[1] 陈绍兰. 土壤温度对植物生长发育的影响[J].农业科技情报, 1990(2):12-14.
[2] 刘鹏. 实战Hadoop[M]. 北京:电子工业出版社,2011:4-5,60-61.
[3] Dean J, Ghemawat S. MapReduce:simplified data processing on large clusters[J].Communications of the ACM,2008,51(1):107-112.
[4] 徐文龙. 基于Hadoop分布式系统的重复数据监测技术研究与应用[D]. 长沙:湖南大学,2013:16-17.
[5] 俞善海. 基于Hadoop的重复数据删除技术 [D]. 上海:华东理工大学,2014: 24-26.
[6] 路秋瑞. 基于Hadoop的大规模数据排序算法的研究[J]. 信息与电脑,2015(17):110-112.
[7] 崔杰,李陶深,兰红星. 基于Hadoop的海量数据存储平台设计与开发[J]. 计算机研究与发展,2012(S1).
[8] 陈康,郑纬民. 云计算:系统实例与研究现状[J]. 软件学报, 2009(5).
