基于作者共引分析的推荐系统研究知识图谱构建
2016-01-04黄文彬徐扬张惟恺
黄文彬+徐扬++张惟恺
摘 要 者共引分析是文献研究中所采用的重要和有效方法。本文针对推荐系统领域的研究,用基于作者共引分析的方法构建知识图谱。利用Web of Science数据库作为数据来源,提取1997-2014年的推荐系统研究文章,生成作者共引矩阵后转化为Pearson相关系数矩阵,再进行因子分析、聚类分析与多维尺度分析,构建推荐系统研究领域的知识图谱。分析表明,推荐系统研究目前处于快速发展时期,相关学者人数与研究范围不断扩大,其中基于协同过滤的推荐算法是最为核心的研究内容,个性化推荐、基于内容的推荐算法和基于数据挖掘的推荐算法等方向是目前该领域的研究热点。
〔关键词〕推荐系统;作者共引分析;知识图谱;科学研究;论文
DOI:10.3969/j.issn.1008-0821.2015.11.001
〔中图分类号〕G250252 〔文献标识码〕A 〔文章编号〕1008-0821(2015)11-0003-10
Mapping the Intellectual Structure of Recommender System
Studies Based on Author Co-citation Analysis
Huang Wenbin Zhang Weikai Xu Yang
(Department of Information Management,Peking University,Beijing 100871,China)
〔Abstract〕ACA,Author Co-citation Analysis(ACA)is an important and effective research approach in literature analysis.This paper mapped the intellectual structure of recommendation system studies using author co-citation analysis.In this paper,Web of Science database was used as the data source to filter out the set of core authors from the research articles in 1997-2014.This paper calculated these authors co-citation matrix and transformed it to Pearson correlation coefficient matrix.Furthermore,the results were then processed by using factor analysis,cluster analysis and multidimensional scaling analysis.The intellectual structure of recommendation system studies was finally mapped.The study showed that recommendation system was currently in rapid development period,and the number of scholars and research scope were expanding rapidly.Collaborative filtering algorithm was the most critical topic in this field.Personalized recommendation,content-based recommendation algorithm,and recommendation algorithm based on data mining were the hotspots in this field.
〔Key words〕recommender systems;author co-citation analysis;intellectual structure;scientific research;paper
随着互联网的普及和发展,网络上的信息呈现爆炸式的增长,用户在利用互联网搜索时,往往会检索出过度冗杂的信息,而推荐系统的目的则是根据用户需求和个性偏好等特征,利用相关算法为用户推荐最有可能需要的信息[1-2]。自90年代中期关于协同过滤的研究成果出现以来,推荐系统已成为一个重要的研究领域[3]。目前,推荐系统广泛应用于诸多领域,例如音乐、电视、书籍、文档、电子学习、电子商务、移动应用和网络搜索等[4]。无论是应用层面还是理论层面,关于推荐系统的研究都在不断深入。本文利用作者共引分析(Author Co-citation Analysis,下文简称ACA)的方法,构建国际期刊上推荐系统研究的知识图谱。
White和Griffith于1981年正式提出作者共引分析(ACA)[5],该方法假定两个作者的文章同时被后继的研究引用则表明这两个作者之间具有联系性,且共同被引用的次数越多,他们之间的关系就越紧密。一组相关作者的共引频次模式分析能揭示出作者间突出的链接,并能解释他们各自或共同代表的主题领域[6-7]。ACA分析方法通过映射图揭示研究领域内部专业人员之间的联系与结构特点,进而反映他们从事的专业间的联系与发展。此外,著作相关的作者在之后的文献中被重复引用的,将倾向于聚集在映射图中,而很少或从未被共同引用的作者会偏离且分散[8-9]。科学知识图谱(简称知识图谱)是显示科学知识的发展进程与结构关系的一种图形,利用可视化技术描述人类随时间积累的知识资源及其载体,绘制、挖掘、分析和显示科学技术知识以及它们之间的相互联系[10-11]。知识图谱是对科学知识及其之间的关系可视化所得出的结果,具有直观、定量、简单与客观等诸多优点[12-13]。知识图谱是一种综合性的、有效的知识可视化分析方法和工具,被广泛应用,并取得了可靠结论[14]。在情报分析领域中,有许多基于ACA与知识图谱的研究[15-19],但针对推荐系统的分析研究较少,主要原因在于推荐系统的发展在近年来才成为亮点议题。endprint
本文主要提取Web of Science数据库中1997-2014年的推荐系统相关论文,利用作者共引分析构建推荐系统研究领域的知识图谱,使用SPSS软件从因子分析、聚类分析与多维尺度分析3个角度分别进行分析探讨[20]。本文的因子分析采用主成分方法和方差极大正交旋转,聚类分析采用层次聚类,选择离差平方和法与欧氏距离平方法,二维图由多维尺度分析生成。最后,利用相关知识结合上述方法对结果进行分析解释。通过将数据源切分为1997-2002年、2003-2008年、2009-2014年3个时段分别进行上述方法的知识图谱构建与分析,发现该领域研究热点的发展趋势。
2015年11月 第35卷第11期 现?"代?"情?"报 Journal of Modern Information Nov,2015 Vol35 No11
2015年11月 第35卷第11期 基于作者共引分析的推荐系统研究知识图谱构建 Nov,2015 Vol35 No11
1 数据来源与数据处理
11 数据来源
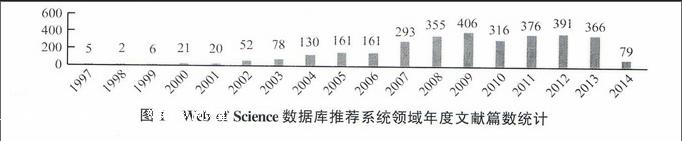
本文的数据来自ISI Web of Science的数据库,以“Recommender Systems”为关键词在数据库中进行检索,共获得3 218篇文献(检索期限至2014年4月),进而获得这些文献共79 734篇的参考文献记录和21 349位参考文献的第一作者。本文将这些作者之间的共引关系作为重点分析对象,统计了这些文献的年度分布情况,如图1所示。推荐系统领域的论文大约从1997年开始出现,到2008年一直呈逐年递增的趋势,2008年之后发文量较为稳定(注:2014年的文献只统计到2014年4月)。
12 数据处理
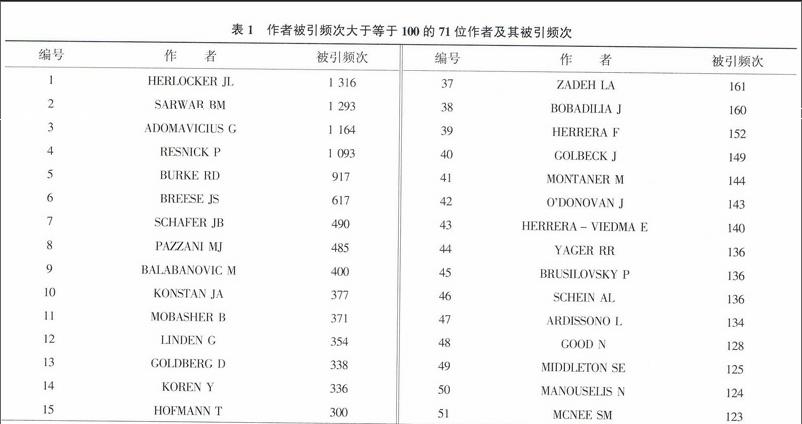
从ISI Web of Science数据库中检索出推荐系统领域相关文献后,提取该文献以及其参考文献的作者,选取被引频次大于等于100的71位作者作为ACA分析对象,如表1所示。通过统计这些作者之间的共引频次生成71×71共引矩阵,如表2所示,将其转换成Pearson相关系数矩阵,作为因子分析、聚类分析和多维尺度分析的基础,并综合这些分析方法得到推荐系统领域的知识图谱。
2 作者共引矩阵的数据分析
21 因子分析
因子分析是利用少数因子去描述多个指标或因素之间的联系,从多个变量指标中选取少数综合变量指标降维的多元统计方法。该方法将密切相关的变量归为同一类,每一类变量成为一个因子,以较少的因子反映原始资料的大部分信息[8]。通过因子分析,作者共引矩阵的因子数为8个,累计贡献率为77171%,其中前4个因子累计贡献率达到65958%,说明其所代表的学术团体是推荐系统领域的主要研究力量,如表3所示。
根据以上的因子分析结果以及该因子所属学者的研究方向,可将这8个因子解释为:基于协同过滤的推荐算法(因子1)、基于内容的推荐算法(因子2、7)、基于数据挖掘的推荐算法(因子3、8)、基于信任的推荐系统(因子4)、个性化推荐(因子5)、基于模糊语言处理的推荐算法(因子6)。其中,多位学者在多个因子中都有较高的负载值。例如HERLOCKER JL与BREESE JS在因子1和2中的负载值均大于04,说明这两位学者在这两个分支领域中均有一定的学术影响。
22 聚类分析
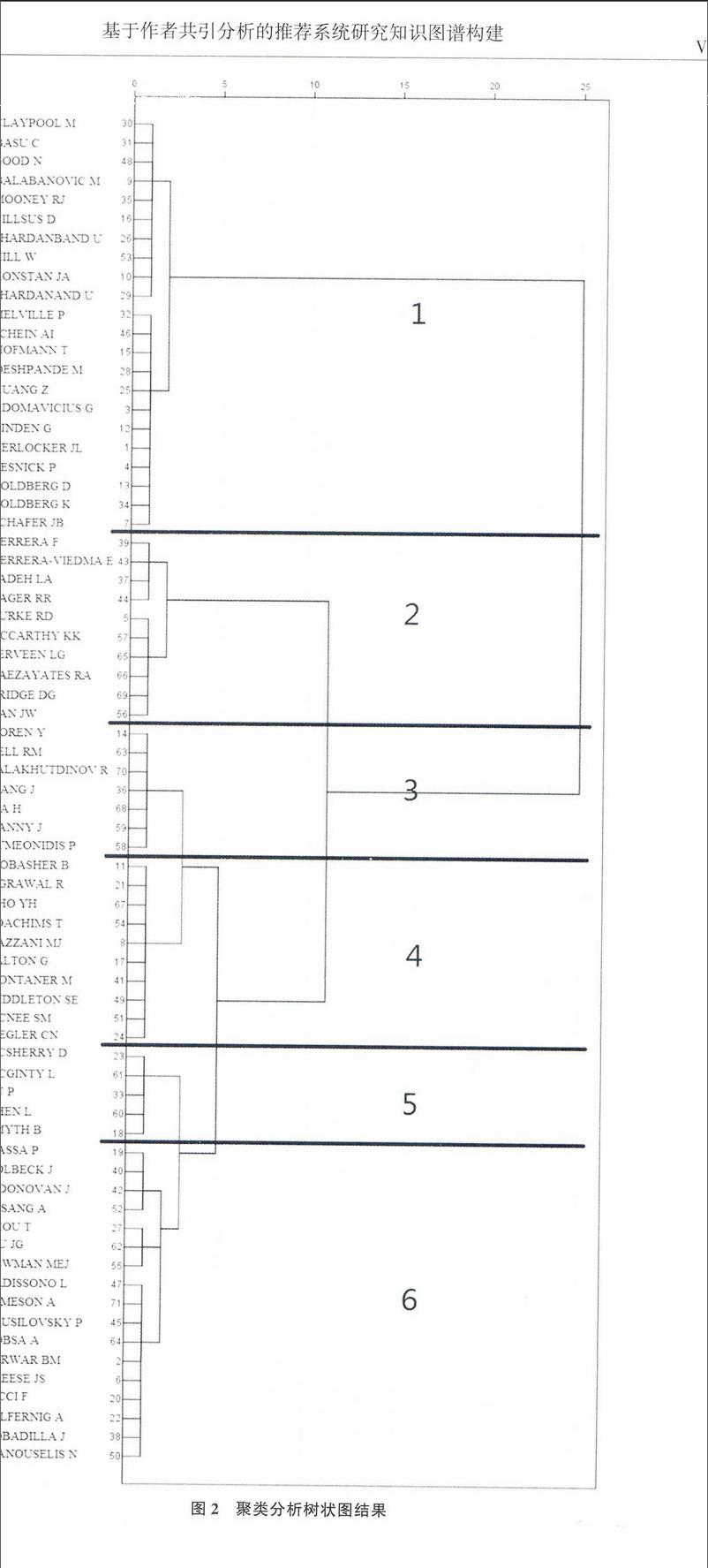
聚类分析是把分析对象分类,根据彼此之间的相关程度形成群,群间的关系具有一定的相异程度。共引聚类分析可以反映某学科或专题的研究情况[8]。本文通过聚类分析方法得出推荐系统研究专题相关的结果,如图2所示,纵轴为文献作者名字,具有关联性的作者相互连接。结果显示,该研究群聚出6类,通过检索相关学者的研究方向发现,这6类有许多交叉,第1类与第3类为基于协同过滤的推荐算法;第2类中包含了基于数据挖掘的推荐算法和基于模糊语言处理的推荐算法,同时第5类也是基于数据挖掘的推荐算法;第4类为基于内容的推荐算法,而第6类中包含了基于信任的推荐系统、个性化推荐和基于内容的推荐算法。由此可见,推荐系统领域的研究热点之间有许多关联,每一个研究热点本身也有许多单独的分支方向。这也反映出该领域仍然是目前新兴的研究领域。
23 多维尺度分析
虽然因子分析可以把原本数量众多的变量用少数几个因子表示出来,并通过这些因子来分析作者之间的关系,但由于前2个主因子只能反映较少的全部变量的信息,很难直观地表示变量间的内在联系,不便于分析解释,因此必须取2个以上的因子进行分析。此外,利用聚类分析的树状图虽然能够反映分类过程的细节信息,但无法反映最终类群之间的相异程度。多维尺度分析可以解决上述问题,其产生的散点图可以反映一定的类群关系。结合聚类分析和因子分析结果,把分析对象的点用线圈成点群,最后根据点、群之间的相关位置进行分析研究。本文通过多维尺度分析结果得到了推荐系统研究的知识图谱,如图3所示。其中Stress值为009721,RSQ值为096607,说明模型的拟合效果较好。根据因子分析和聚类分析的结果,并结合在
Web of Science中检索出的相关作者的研究方向与著作,可将多维尺度分析结果划分为6片区域。由于每个区域的作者数量甚多,以下只列代表作者与至多5位相关作者。这6片区域分别为:
区域1:基于协同过滤的推荐算法:以HERLOCKER JL、BALABANOVIC M为代表,包括MIDDLETON SE、ADOMAVICIUS G、RESNICK P、GOLDBERG D、SHARDANBAND U等学者。
区域2:个性化推荐:以BREESE JS、JOACHIMS T为代表,包括MOBASHER B、JAMESON A、RICCI F、SMYTH B等学者。
区域3:基于数据挖掘的推荐算法:以BAEZAYATES RA、PU P为代表,包括MCGINTY L、MCSHERRY D、BURKE RD、MCCARTHY KK、HAN JW等学者。endprint
区域4:基于内容的推荐算法:以SARWAR BM、FELFERNIG A为代表,包括BRUSILOVSKY P、NEWMAN MEJ、LIU JG、ZHOU T等学者。
区域5:基于模糊语言处理的推荐算法:以ZADEH LA、HERRERA F、HERRERA-VIEDMA E、YAGER RR、BRIDGE DG为代表。
区域6:基于信任的推荐系统:以GOLBECK J、ODONOVAN J、JOSANG A为代表。
由此可见,基于内容的推荐算法、基于模糊语言处理的推荐算法和基于信任的推荐系统这3个方向的研究相对独立,研究人数也较少。基于协同过滤的推荐算法研究人数众多,是推荐系统领域最为核心的研究方向,其次是个性化推荐研究。另外,部分作者之间的距离非常接近,例如基于数据挖掘的推荐算法研究的TERVEEN LG、BAEZAYATES RA与基于模糊语言处理的推荐算法研究的HERRERA F、HERRERA-VIEDMA E、BRIDGE DG,表明这两个方向的研究关系密切,这些作者也开展了一定的交叉研究。不过,从这个图上无法了解推荐系统领域研究热点的发展变化情况,因此本文又分别绘制了3个时间段的知识图谱(如图4、图5、图6所示),从中可以发现一些趋势及变化。
24 分时段知识图谱
为了分析推荐系统领域研究热点的发展变化,本文采用相同的图谱构建方式与分析方法,分别生成3个分时段内的知识图谱来进行领域分析,分别为1997-2002年、2003-2008年、2009-2014年。由于各时间段内的文献篇数相较于总篇数会减少很多,所以在观察各时间段的作者
被引频次后,分别选择被引频次大于10、50、80的作者作为主要分析对象。
1997-2002年时段的多维尺度分析结果如图4显示。其中Stress值为010804,RSQ值为095755。根据因子和聚类分析的结果,结合相关作者的研究方向,将结果划分为4片区域,分别为:
区域1:基于协同过滤的推荐算法。以RESNICK P、SHARDANAND U为代表,包括BILLSUS D、SHARDANBAND U、GOLDBERG D、BASU C、HILL W、BALABANOVIC M、KONSTAN JA、HERLOCKER JL、SALTON G、JOACHIMS T、DELGADO J等学者。
区域2:基于数据挖掘的推荐算法。以BREESE JS、AGRAWAL R为代表,包括SARWAR BM、MOBASHER B、PAZZANI MJ、MCSHERRY D、QUINLAN JR、COOLEY R等学者。
区域3:多准则推荐。以BURKE RD、SMYTH B为代表。
图6 2009-2014年时段多维尺度分析结果
区域4:基于知识的推荐系统。以RAMAKRISHNAN N、HOUSTIS EN为代表。
综合以上结果,1997-2002年时段作为推荐系统领域研究的初始阶段,学者们的研究方向相对集中,大多数学者围绕基于协同过滤的推荐算法这一核心方向,也有部分学者研究基于数据挖掘的推荐算法,还有一小部分学者研究多准则推荐与基于知识的推荐算法,但是人数较少。
2003-2008年时段多维尺度分析的结果如图5所示。其中Stress值为005791,RSQ值为099013。根据分析结果与作者的研究方向,将多维尺度分析结果划分为5片区域,分别为:
区域1:基于协同过滤的推荐算法。以LIEBERMAN H、RESNICK P为代表,包括ADOMAVICIUS G、BALABANOVIC M、GOLDBERG D、BILLSUS D、SHARDANBAND U等学者。
区域2:个性化推荐。以MCSHERRY D、SMYTH B为代表,包括AGRAWAL R、MCGINTY L、PU P、RICCI F、ARDISSONO L、REILLY J等学者。
区域3:基于内容的推荐算法。以SARWAR BM、BREESE JS、TERVEEN LG、BRIDGE DG、YAGER RR为代表。
区域4:基于知识的推荐系统。以BURKE RD、FELFERNIG A、MCCARTHY KK为代表。
区域5:基于信任的推荐系统。以ZIEGLER CN、MASSA P为代表。
综合上述分析,此时段研究学者人数有所增加,并且出现新的研究热点。虽然大部分学者仍在进行基于协同过滤的推荐算法的研究,但也有相当数量的学者开始研究个性化推荐。此外,基于内容的推荐算法和基于信任的推荐系统开始成为新兴热点,引起了一部分学者的注意。
2009-2014年时段多维尺度分析的结果如图6所示。其中Stress值为012304,RSQ值为095122。将分析结果划分为6片区域,分别为:
区域1:基于协同过滤的推荐算法。以ADOMAVICIUS G、HERLOCKER JL为代表,包括RESNICK P、KOREN Y、SCHAFER JB、LINDEN G、HOFMANN T等学者。
区域2:个性化推荐。以BREESE JS、MOBASHER B为代表,包括FELFERNIG A、RICCI F、BOBADILLA J、SALTON G、AGRAWAL R等学者。
区域3:基于内容的推荐算法。以SARWAR BM、BURKE RD为代表,包括ZHOU T、LIU JG、O'DONOVAN J、SALAKHUTDINOV R、BRUSILOVSKY P等学者。
区域4:基于模糊语言处理的推荐算法。以HERRERA F、HERRERA-VIEDMA E、PORCEL C、YAGER RR、ZADEH LA为代表。endprint
区域5:基于信任的推荐系统。以MASSA P、GOLBECK J、NEWMAN MEJ、JOSANG A为代表。
区域6:基于数据挖掘的推荐算法。以PAZZANI MJ、SCHEIN AI为代表。
分析结果表明,该时段研究学者人数明显增加,而相较于2003-2008年时段,研究热点也有一定变化,基于模糊语言处理的推荐算法和基于数据挖掘的推荐算法的热点程度已经超过基于知识的推荐系统。这说明目前推荐系统领域中各热点的研究学者人数逐步增加,新兴领域也在不断出现。最为核心的研究热点依旧是基于协同过滤的推荐算法。此外,个性化推荐、基于内容的推荐算法与基于信任这3个方向也正在稳步发展。
3 分析与结语
31 分 析
全时段与各分时段的分析结果汇总如表4所示。在推荐系统领域的发展过程中不断涌现出新的核心学者,说明该领域知识创新和积累非常迅速,研究十分活跃。在全时段和各分时段中,基于协同过滤的推荐算法与个性化推荐基本保持在前两名,说明它们是推荐系统领域的核心热点,特别是基于协同过滤的推荐算法。从1997-2002年时段到2003-2008年时段,基于知识的推荐系统一直是研究热点,而多准则推荐与基于数据挖掘的推荐算法则被个性化推荐、基于内容的推荐算法和基于信任的推荐系统所超越。这说明随着时代需求的变化,学者们逐渐倾向于某些具体类型的推荐系统的研究,更加注重实际应用。从2003-2008年时段到2009-2014年时段,个性化推荐、基于内容的推荐算法和基于信任的推荐系统等3个研究持续保持热度,而基于知识的推荐系统被基于模糊语言处理的推荐算法超越,基于数据挖掘的推荐算法也重新出现。这说明随着用户对信息系统的需求提高和网络上信息量的爆炸式增长,如何更好地理解用户需求和在大量数据中挖掘出最有用的信息是学者们更加关注的。
数据显示,一些学者随着研究热点的变化也在不断地改变自己的研究方向。例如,SMYTH B在1997-2002年时段属于多准则推荐方向,到了2003-2008年时段及2009-2014年时段则属于个性化推荐方向,在全时段中该作者也属于个性化推荐方向。这说明该作者在自己最初所处的方向逐渐弱化后能够迅速调整研究方向,并且在个性化推荐方向取得了长足进展。而另一些学者的研究领域则较为稳定,例如很多学者长期处于基于协同过滤推荐算法的研究方向。这说明该方向具有很高的研究价值,能够吸引很多学者参与其中。而许多后进研究人员也不断参与到基于协同过滤的推荐算法方向的研究中,使得该方向的研究人数显著提高,研究不断深入。
32 结 语
本文针对推荐系统进行了基于ACA分析方法的知识图谱构建。分析表明,推荐系统研究近年来处于快速发展时期,相关学者人数与研究范围不断扩大。其中基于协同过滤的推荐算法是最为核心的研究方向,目前已经发展出多个具体分支;个性化推荐、基于内容的推荐算法、基于数据挖掘的推荐算法等方向也是该领域的研究热点。一些曾经的研究热点由于时代需求的变化被其他新兴方向所超越。综合上述研究,在今后推荐系统领域的发展中,基于协同过滤的推荐算法方向在较长时期内仍将是该领域的核心研究方向,并且会进一步细分为更多分支。而个性化推荐、基于内容的推荐算法、基于数据挖掘的推荐算法和基于模糊语言处理的推荐算法方向将较为稳定地发展。基于信任的推荐系统有可能被逐渐弱化。基于其他方式的推荐系统研究以及应用将会出现。
参考文献
[1]孙彦超,韩凤霞.基于协同过滤算法的个性化图书推荐系统的研究[J].图书馆理论与实践,2015,(4):99-102.
[2]杨博,赵鹏飞.推荐算法综述[J].山西大学学报:自然科学版,2011,(3):337-350.
[3]GAdomavicius,ATuzhilin.Towards the Next Generation of Recommender Systems:A Survey of the State-of-the-Art and Possible Extensions[J].IEEE Transactions on Knowledge and Data Engineering,2005,17(6):734-749.
[4]JBobadilla,FOrtega,AHernando,AGutierrez.Recommender systems survey[J].Knowledge-Based Systems,2013,(46):109-132.
[5]HDWhite,KWMcCain.Visualizing a Discipline:An Author Co-Citation Analysis of Information Science,1972-1995[J].Journal of the American Society for Information Science,1998,49(4):327-355.
[6]耿海英.共引分析方法及其应用研究[D].北京:中国科学院研究生院,2007.
[7]孟祥保,钱鹏.国际图书情报学研究群体结构——以核心作者互引分析为视角[J].情报科学,2015,(5):124-128.
[8]HDWhite,BCGriffith.Author Cocitation:A Literature Measure of Intellectual Structure[J].Journal of the American Society for Information Science,1981,32(3):163-171.
[9]苑彬成,方曙,刘合艳.作者共被引分析方法进展研究[J].图书情报工作,2009,(22):80-84.
[10]侯海燕.基于知识图谱的科学计量学进展研究[D].大连:大连理工大学,2006.
[11]秦长江,侯汉清.知识图谱——信息管理与知识管理的新领域[J].大学图书馆学报,2009,(1):30-37.
[12]邱均平,吕红.近五年国际图书情报学研究热点、前沿及其知识基础——基于17种外文期刊知识图谱的可视化分析[J].图书情报知识,2013,(3):4-15.
[13]高鹏斌,于渤,吴伟伟,等.基于知识图谱的即兴领域知识结构及其演化分析[J].科技管理研究,2015,(6):112-117.
[14]杨思洛,韩瑞珍.国外知识图谱绘制的方法与工具分析[J].图书情报知识,2012,(6):101-109.
[15]向剑勤,赵蓉英.国内外图书情报学研究主题的知识图谱比较研究[J].情报杂志,2014,33(2):86-94.
[16]赵勇,沙勇忠.当代情报学研究的知识图谱:基于ACA的分析[J].图书馆论坛,2008,(6):63-69.
[17]奉国和,梁晓婷.国内推荐引擎学术研究知识图谱分析[J].情报科学,2012,30(1):144-148,160.
[18]孙海生.图书馆学高频被引论文共被引分析[J].现代情报,2012,(1):107-112.
[19]詹川.大数据研究的知识图谱分析[J].图书馆论坛,2015,(4):84-91.
[20]吴占福,马旭平,李亚奎.统计分析软件SPSS介绍[J].河北北方学院学报:自然科学版,2006,(6):67-69.
(本文责任编辑:马 卓)endprint
