云数据中心集群间网络性能优化的探讨
2015-12-31蒋多元陈海雄
蒋多元,陈海雄
(中国石化石油勘探开发研究院 北京100083)
1 引言
出于容错备份、业务隔离、可扩展性等需求,现代的大规模云计算任务往往被划分到多个集群进行处理。例如,规划专用于计算的集群和专用于存储的集群已经成为一种常见的部署模式。在这种模式下,由于任务的完成需要多个集群协作完成,因此,规划连接集群的网络且保证网络的性能具有重要意义。
由于集群间网络一般用来承载数据备份、文件传输等需要大容量网络的情况,对带宽的要求很高;另一方面,由于集群一般会跨地域部署,链路时延一般相对较高。这两个特性导致了经常需要针对网络实际承载业务的特性来对集群间网络进行有针对性的优化。本文首先介绍了一次集群间网络的性能问题的真实案例。这个案例来源于一个用于大规模实时数据处理的数据中心,在一次大规模并发任务中发现在带宽并未完全使用的情况下发生了严重的分组丢失现象。其后,基于对拓扑结构的分析,介绍了对性能瓶颈的定位过程。接着,通过搭建测试环境并进行实际测试,对性能瓶颈的来源进行了发掘。最后,基于一个简单的模型,分析了各个要素对于性能的影响,并基于分析结果设计了最终的解决方案。
2 相关研究工作
出于容灾、提高访问速度等目的,现在很多大型的公司或组织在不同的地理位置建设了云服务集群。这些数据中心间一般通过专用的私有网络或者从网络运营商租借的链路进行连接。这类网络一般用来承载跨数据中心的大数据量传输的任务。
由于这类网络一般有较高的建设和运维成本,其建立者会寻求充分利用这种网络的能力。为此,当前集群(或者数据中心)间的网络性能优化是一个热门的学术问题,具体介绍如下。
· Google[1]和 Microsoft[2]研究了如何基于 SDN[3]技术来提高集群间网络的利用率。提高网络的利用率有助于降低其平均成本,但是由于散列不均衡等因素的影响,简单地采用负载均衡技术并不能有效利用数据中心间的链路带宽。此外,缺乏全局视图的调度反而可能造成拥塞恶化。SDN恰好能解决这些问题,一方面,SDN能够采用更加细粒度的分流技术,使得链路能够被充分利用,避免不均衡的情况;另一方面,SDN可以基于全局视图规划流量,避免本地最优导致的全局恶化现象。
·Netstitcher[4]研究了跨数据中心的大规模数据传输问题,提出利用存储—转发的方法和不同数据中心的可用带宽的时间差,将数据中心间的带宽在时间上“缝合”起来,从而满足数据传输的带宽需求;参考文献[5]研究了一种数据中心间数据传输的按需的带宽供给方案,采用按需供给的方式满足数据传输的带宽需求。
·由于数据中心间的链路往往是基于峰值进行计费的,参考文献[6]研究了如何基于对大规模数据传输的调度来平抑峰值,降低数据中心间数据传输的调度开销。
· 基于网络的调度往往是被动的、基于当前的,这导致无法取得主动、平稳的调度结果;Microsoft最新的研究[7]表明,如果对大文件传输任务在时间域上进行一个合理的规划,将会更加有利于任务在时间期限前完成。
现有研究主要关注的是如何提高带宽利用率来满足带宽敏感的业务的带宽需求,而本文的研究主要关注的业务场景是不同的:除了对带宽的需求,网络同样需要满足时延和分组丢失率的要求,以满足实时性业务的特征。据笔者所知,这是一个现有研究并未涉及的领域。和关注数据中心内部数据传输时延的研究[8~11]不同的是,本文的研究关注的是跨数据中心的业务。
3 集群间网络性能优化案例场景
某云数据中心规划的结构如图1所示。其中计算集群A和计算集群B执行实时性较高的计算任务,在完成计算之后,需要将数据及时写入存储集群。计算集群A和计算集群B都需要处理大量的并发任务。但计算集群A经常出现报文重传或者任务失败的现象,导致数据无法正常写入存储集群,而计算集群B没有出现类似问题。

图1 集群间网络性能优化案例场景
4 性能瓶颈定位
在故障追查中,首先考虑的是带宽不足导致的问题,即路由器C和存储集群之间的链路成为了瓶颈。但是,由于计算集群B到存储集群并未出现网络问题,这就否定了这段链路出现拥塞的可能性。而对实际数据的分析也发现,这段链路的利用率不足50%。由于这段链路没有出现带宽不足的问题,计算集群A到存储集群的整个路径上也不应该出现带宽问题。
在排除带宽问题和路由器B、C的问题之后,将问题定位在交换机A上。初步推测是交换机A的某些配置不足造成的性能问题。
5 测试与结果
尽管初步估计是交换机A造成的性能低下,但是由于现网环境复杂,难以确定是什么原因造成了性能不足。为了进一步追查问题,对交换机A展开了测试。测试环境如图2所示。所有链路、接口带宽都为10 Gbit/s。

图2 测试场景
用qperf(qperf是测量网络带宽和时延的常用工具)测试从服务器A到其他服务器的时延情况。时延均为链路满负荷时的时延。消息的大小范围是1~1 024 KB。实验结果见表 1。
作为对比,用qperf测试从服务器C到其他服务器的时延情况。消息的大小范围同样是1~1 024 KB。实验结果见表 2。
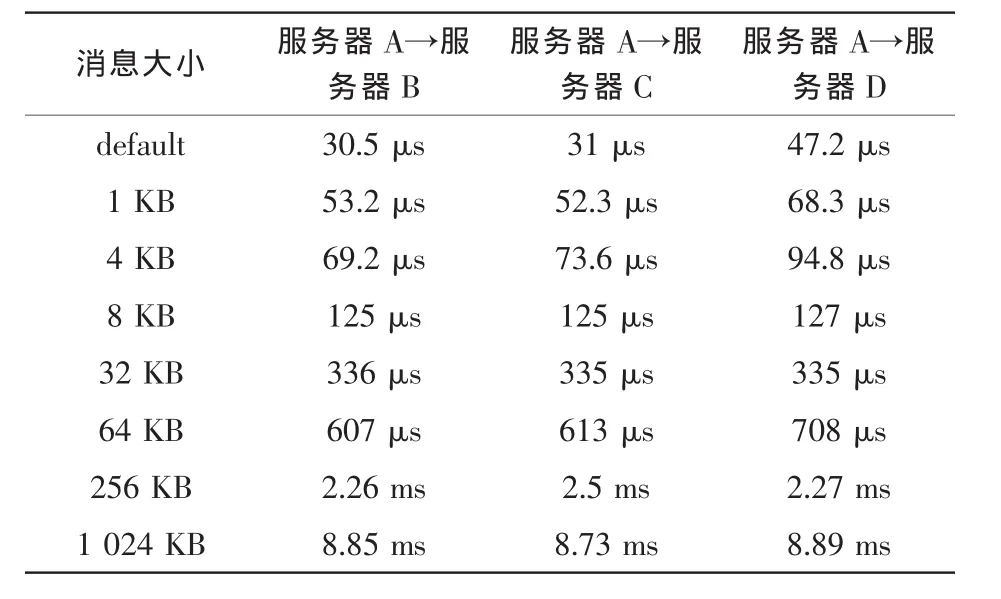
表1 服务器A到达其他服务器的时延

表2 服务器C到达其他服务器的时延
为了方便比较,将时延和消息大小的关系画在一张图中,如图3所示。
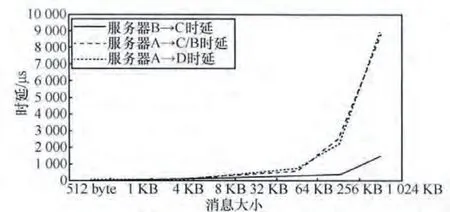
图3 时延和消息大小的关系
由图3可以明显发现两个问题。
(1)即便在默认的分组长度下,交换机A造成的时延也显著大于路由器C的时延,甚至可能高于服务器的网卡时延。这说明交换机A的转发速率并不高。
(2)当报文的大小超过一个阈值(8 KB左右)时,交换机A造成的时延将会急剧增加。由于这种报文长度大于链路层MTU,所以会被分片。时延的急剧增加说明交换机A可能丢弃数据帧的概率较高,这导致分片的重传,进而增加时延。而交换机A丢弃数据帧的可能原因是缓存队列已经满了,无法进一步存储报文。
这两个问题共同说明交换机A的处理能力和缓存可能构成了瓶颈。
6 问题分析与解决
为了解决交换机A的问题,笔者首先建立了一个简单的模型描述这个问题。
对于现代的交换机而言,其处理能力只与帧的到达速率有关,和帧大小的关系很小,为此,记交换机的处理能力是帧/秒(f/s)。缓存大小是Mbyte,链路带宽是Bbyte,帧的大小是Fbyte。
如果交换机的处理能力是网络的瓶颈,即:

在20 Gbit/s的链路中,采用默认的以太网帧大小1 500 byte,相应的交换机处理能力应该达到1.71×106f/s。如果仅有这个能力的一半 (如10 Gbit/s网络设计的交换机),交换机A的缓存仅有40 MB,这时缓存将在0.03 s内被耗尽,进而出现分组丢失现象。
提高网络对峰值流量容忍能力的最直接方法是提高交换机的处理能力。图4说明了提高交换机处理能力和可容忍峰值时间之间的关系。不过可以明显看到的是,除非交换机处理能力非常接近或者高于峰值的帧速率,否则依然很难在流量达到峰值时正常工作。

图4 在M=40 MB、B=20 Gbit/s时,能够容忍的峰值时间和交换机处理能力间的关系
另外一个方法是增加交换机缓存。不过,如图5所示,增加缓存取得的效果是线性的,而且即便将缓存增大到400 MB,容忍时间依然不够长。

图5 通过增加缓存的大小来提高对网络峰值流量的容忍能力
相比之下,提高帧的大小是一个更加有效的方法,如采用巨帧(jumbo frame)技术[12]。现在大多数交换机都已经支持巨帧技术[13]。如图6所示,如果把帧的大小从默认的以太网上限1500 byte提高到2 600 byte左右,就可以对峰值流量的容忍时间更长。相比之下,改变帧的大小是相当灵活的,比提高交换机的能力成本更低,适应性更好。通过在网络中开启巨帧,最终解决了交换机A导致的重传和写入失败问题。

图6 通过增加帧的大小来提高对网络峰值流量的容忍能力
7 结束语
当前针对云计算集群间网络的研究主要的关注点在于提高网络的利用率,以满足对带宽需求高的应用(如数据备份)。本文主要讨论了另外一种场景:在集群间网络支持实时性要求较高的应用时,如何满足这类应用对于低时延和低分组丢失率的需求。本文通过实验和分析发现,交换机的帧处理能力可能成为网络的瓶颈,进而导致时延增加和分组丢失。通过分析发现,增加帧的大小可以有效避免交换机处理能力不足导致的分组丢失,并通过巨帧技术解决了这一问题。本文是对当前研究的一个重要补充。当前对大规模数据处理的性能和实时性要求不断增加,笔者认为,在跨集群网络上支持高度实时的应用将成为一个广泛的需求。特别地,如何在提高网络利用率的情况下依然为实时性要求较高的应用提供传输质量保证,将是一个值得深入研究的问题。
1 Jain S,Kumar A,Mandal S,et al.B4:experience with a globally-deployed software defined WAN.Proceedings of the ACM SIGCOMM 2013 Conference on SIGCOMM,Hong Kong,China,2013
2 Hong C Y,Kandula S,Mahajan R,et al.Achieving high utilization with software-driven WAN.Proceedings of the ACM SIGCOMM 2013 Conference on SIGCOMM,Hong Kong,China,2013
3 McKeown N,Anderson T,Balakrishnan H,et al.OpenFlow:enabling innovation in campus networks.SIGCOMM Computer Commununication Review,2008,38(4):69~74
4 Laoutaris N,Sirivianos M,Yang X,et al.Inter-datacenter bulk transfers with netstitcher.Proceedings of the ACM SIGCOMM 2011 Conference,Toronto,Ontario,Canada,2011
5 Mahimkar A,Chiu A,Doverspike R,et al.Bandwidth on demand for inter-data center communication.Proceedings of the 10th ACM Workshop on Hot Topics in Networks,Cambridge,Massachusetts,2011
6 Nandagopal T,Puttaswamy K P N.Lowering inter-datacenter bandwidth costs via bulk data scheduling.Proceedings of the 12th IEEE/ACM International Symposium on Cluster,Cloud and Grid Computing(CCGrid 2012),Ottawa,Canada,2012
7 Kandula S,Menache I,Schwartz R,et al.Calendaring for wide area networks.Proceedings of the 2014 ACM Conference on SIGCOMM,Chicago,Illinois,USA,2014
8 Wilson C,Ballani H,Karagiannis T,et al.Better never than late:meeting deadlines in datacenter networks.Proceedings of the ACM SIGCOMM 2011 Conference,Toronto,Ontario,Canada,2011
9 Vamanan B,Hasan J,Vijaykumar T N.Deadline-aware datacenter TCP (D2TCP).ProceedingsoftheACM SIGCOMM 2012 Conference on Applications,Technologies,Architectures,and Protocols for Computer Communication,Helsinki,Finland,2012
10 Lee C,Jang K,Moon S.Reviving delay-based TCP for data centers.Proceedings of the ACM SIGCOMM 2012 Conference on Applications,Technologies,Architectures,and Protocols for Computer Communication,Helsinki,Finland,2012
11 Liu Y J,Gao P X,Wong B,et al.Quartz:a new design element for low-latency DCNs.Proceedings of the 2014 ACM Conference on SIGCOMM,Chicago,Illinois,USA,2014
12 Murray D,Koziniec T,Lee K,et al.Large MTUs and internet performance.Proceedings of IEEE the 13th International Conference on High Performance Switching and Routing(HPSR),Belgrade,Serbia,2012
13 Hogg S.Jumbo frames.http://www.networkworld.com/article/2224722/cisco-subnet/jumbo-frames.html,2013
