基于免疫算法的大米加工厂选址研究
2015-12-25余翠兰
余翠兰


摘要:针对大米加工厂选址问题,首先分析了影响大米加工厂选址的因素及介绍了免疫算法的概念和特点,然后采用免疫算法对大米加工厂选址进行建模,并给出了模型的求解方法。利用该方法可以方便地得到大米加工厂选址的最优解。
关键词:大米加工厂;选址;免疫算法
中图分类号:TP183
文献标识码:A
DOI: 10.3969/j.issn.1003-6970.2015.07.016
0 引言
大米加工方法随着人民生活水平的提高不断发展,在一些地处亚热带地区、热量丰富、雨量充沛、土地肥沃、盛产稻米的区县建立中小型大米加工厂是非常有必要的,而建厂的位置不同则米源、市场、成本等就会不同,那么如何选址才能使投资者成本最小、利润最大呢?
解决选址问题的方法主要有:重心法、层次分析法、专家选择法等,但这几种方法在进行选址问题研究时考虑的因素比较单一,不能将多个因素有机结合起来,本文选定免疫算法来构建大米加工厂选址模型。免疫算法是源于生物免疫系统的性质而衍化出来的一种智能算法。选择它是因为:免疫算法具有较强的全局寻优索搜索能力;能保证解的多样性;计算求解时采用并行搜索方式,保证解的准确性;同时该算法可以把影响大米加工厂选址的各方面如距离、运费等因素有机结合起来。
1 大米加工厂选址的影响因素
1.1 问题描述
某县盛产稻谷,投资者想建立两个大米加工厂。假设全县水田较多的村有M个,需要将稻谷送到大米加工厂的量较大,这M个村简称M个需求点,在这M个需求点中估计出N个作为加工厂的备选地点,那么备选地点中在哪两个地点建厂最能使投资者的成本(包括建造成本和运营成本)最低、利润最大呢?
1.2 影响大米加工厂选址的因素
大米加工厂应建在谷源丰富、谷质优及交通便利的地方。通过分析,本文考虑的影响大米加工厂选址的主要因素包括:距离、服务量及运营费用。
(1)距离:指备选地点到需求点间的距离总和,且距离的计算采用两地点间使用的公路的实际距离。
(2)服务量:指备选地点能得到的稻谷总量。即备选地点服务范围内各村农户会将稻谷送到大米加工厂服务的数量。也叫需求服务量、稻谷量。
(3)运营费用:水、电、气费用、技术工人费用、管理费、设备维修保养费以及车辆的折旧费用等。
另外,我们还进行下面的假设:
(1) -个备选地点可服务多个需求点,但一个需求点只能被一个备选地点服务,不允许一个服务地点被多个备选地点进行服务。
(2)各需求点的需求量是已知的。
(3)备选地点的服务能力能够服务范围内客户的全部需求,即无服务量的限制、无库存容量的限制。
(4)总费用只考虑固定的大米加工厂建设费用和运营费用,且建设费用已知。
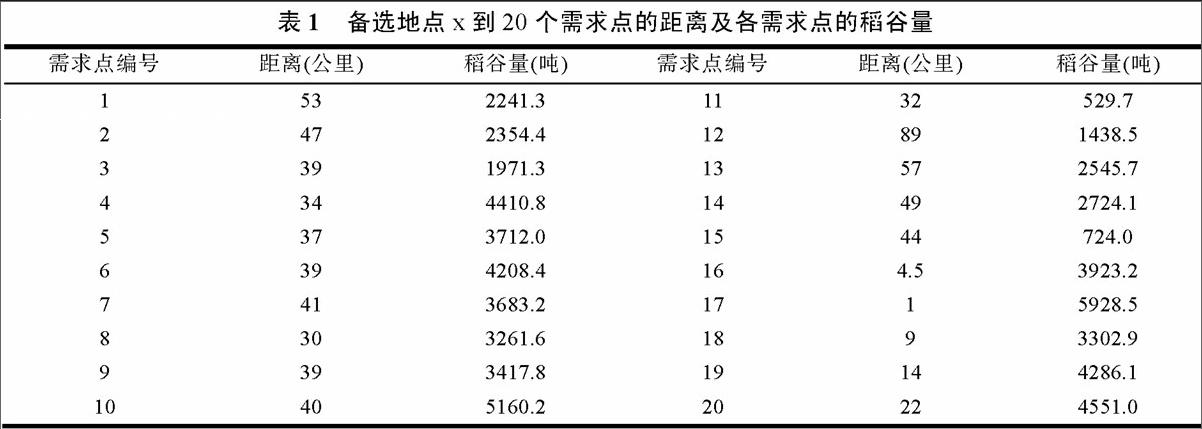
例如,通过走访调研,可获得各备选地点到需求点的实际距离及稻谷量,如表1为其中一个备选地点的数据。
2 基于免疫算法的大米加工厂选址模型构建
2.1 免疫算法
免疫算法是一种模拟生物免疫系统的智能优化算法,实现了类似于生物免疫系统的抗原识别、细胞分化、记忆和自我调节的功能,具有良好的系统应答性和自主性,对干扰具有较强维持系统自平衡能力。如果将免疫算法与求解优化问题的一般搜索方法相比较,那么抗原、抗体、抗体和抗原之间的亲和度分别对应于优化问题的目标函数、优化解、解与目标函数的匹配程度。
2.2 大米加工厂选址模型的建立
基于上节的分析及假设,根据免疫算法目标函数,大米加工厂选址的目标函数:
其中, 为备选地点与m个需求点(村)的距离与运输费率的乘积; 为备选地点对需求点提供的服务费用,等于备选地点的服务量与服务费率的乘积; 为备选地点在生产运营时水、电、气、设备维修保养费以及车辆的折旧费用。N={l,2,…,n}为备选地点的集合,Mj={l,2,…,m}为满足客户需求点的服务村的集合;zij为0-1变量,表示备选地点与需求点的服务需求分配关系,当Zij=1时,说明需求点i的稻谷由备选地点j进行加工,否则zij=0;ti表示备选地点到需求点的运输费率;dij表示从需求点到离它最近的备选地点的距离;F表示需加工的稻谷总量;f表示稻谷加工费率;Pi表示备选地点的平均消耗费用。
约束条件中的第1个保证每个需求点只能由一个备选地点进行服务,第2个确保需求点的服务需求量能被备选地点处理,第3个表示大米加工厂选址备选地点数量为b,第4个表示Zij、hj是0-1变量,第5个保证需求点在备选地点可服务的范围内。
2.3 大米加工厂选址模型求解
求解选址模型的步骤如下:
步骤1:初始抗体的产生。(初始抗体群的产生)将需求点看作免疫算法中的抗原,抗原数量为M,用1、2、…,m表示;从中选出N个作为备选地点,将备选地点看作免疫算法中的抗体,用b1、b2、…、bN表示。要在N个抗体中选出2个抗体作为与抗原进行有效结合,其中,抗体表示全局最优解,抗原为需解决的问题。设定种群数量为M的初始种群。
步骤2:计算抗体与抗原间的亲和力。亲和力用于表示抗体对抗原的识别程度,此处针对上述大米加工厂选址模型的亲和力的计算公式为:
其中,Fv为选址问题的目标函数,分母中第二项表示为违反距离约束的解给予惩罚,C取较大的正整数。endprint
步骤3:计算抗体与抗体间相似度。在免疫算法中为了表示种群中抗体的多样性,引用了平均信息熵的概念。在选址模型问题上,平均信息熵表示:对备选地点求得解的平均相似信息量,在本文中表示种群个体的平均存活质量。同一抗体间不存在平均信息熵。其性质有平均信息熵越高,则种群多样性越低;反之平均信息熵越低,则种群多样性越高。本文中群体内有抗体N个,则有该抗体的平均信息熵H(N)为:
其中,Aij为第i个抗体与第j个抗原的亲和力,表示第i个备选地点是否能够需求点j的问题。当抗体与抗原的相似度越高时,则该备选地点作为大米加工厂建厂的概率越大。
抗体间相似度表示利用免疫算法选址模型求得的有效解与解之间的相似性的百分比的度量。相同抗体是相似的,相似度等于1。抗体间相似度Sij的公式为:
步骤4:计算抗体浓度。抗体的浓度Cv是群体中相似抗体所占的比例。用抗体浓度的大小来衡量抗体对抗原结合程度,抗体浓度也可作为抗体个体是否优质性的重要依掘。Cv的公式如下:
其中, T为预先设定的一个阈值。
通过分别计算N个抗体的个体浓度,则可得到Cx和Cy(x,y<=N)(假设需选定两个建厂地址)的抗体浓度较高,这两个抗体可初步作为两个全局最优解,能够解决全局内出现的问题,即这两个抗体可初步作为建立大米加工厂的地点,之后需要经过被选择的概率来验证是否有体会选择这两个抗体。
步骤5:计算抗体被选择的概率。在生物群体中,抗体浓度较高时,免疫算法就会认为该抗体越容易被生物机体选择,因此较高的抗体可以作为全局最优解,抗体被选择的概率P的公式为:
在利用免疫算法求解选址问题中,求得优质的解是经过免疫算法的循环计算后储存在记忆库中并进行对比得出的,若该求得的解出现的频率较高,且于记忆库中在对比条件下具有优势时,则容易被免疫算法记忆库保留下来,作为全局最优解。若抗体被选择的概率较低,免疫算法则会放弃本次选择的抗体,继续寻找概率较大的抗体个体。
也就是说,通过计算N个抗体被选择的概率,假设是Px和Py最高,则说明模型求得的是全局最优解,x和y这两个备选地点可作为大米加工厂的建厂地点。
步骤6:计算期望繁殖概率。抗体的期望繁殖概率Q公式为:
其中,a为O 个体适应度高与期望繁殖概率大的抗体存留于记忆库中。在选址问题中,在机体的免疫平衡机制的作用下保证了解的多样性,随着需求点的稻谷量、运营费用等因素不断变化时,选址地点的自身条件也会在市场作用下相应的更新,能够继续成为最适合的建厂地点。 3 小结 文章首先分析了影响大米加工厂选址的因素,然后构建了基于免疫算法的大米加工厂选址模型,给出了模型的求解方法和步骤。该方法具有很强的全局收敛功能,还具有解的多样性与自适应性等特点。利用免疫优化算法可以方便地得到大米加工厂选址优化问题的最优解。
