大数据环境下基于MapReduce的网络舆情热点发现
2015-12-25王书梦吴晓松
王书梦 吴晓松

摘要:大数据环境下的网络舆情分析更侧重于在海量数据的采集、存储、清洗和文本聚类,因此传统的仅依据数据统计的舆情分析方法不再适用。文章对大数据网络舆情分析的相关文献进行总结研究,归纳出网络舆情分析的基本流程框架,并阐明了在大数据环境下网络舆情分析中文本聚类的各个阶段如何运用MapReduce进行分布式计算,以此提高网络舆情分析的准确度与及时性。
关键词:大数据;舆情热点;MapReduce;文本聚类
中图分类号:TP391.1
文献标识码:A
DOI: 10.3969/j.issn.1003-6970.2015.07.022
0 引言
舆情是一定时期一定范围内社会民众对社会现实的主观反映,是群体性的态度、思想、情绪和要求的综合表现。大数据时代已经到来,大数据下的网络舆情分析已经成为当前政府和科研机构研究的热点问题。2011年,经济学人发表“Building with big data”指出在数据极度膨胀的时代,要掌握数据分析的能力,成为数据的主人,而不要成为数据的奴隶。
在大数据时代,如何及时的收集、分析处理海量数据,并为决策者提供有用的信息是当前研究的热点与难点。相较于传统的舆情分析,大数据环境下的网络舆情分析更侧重于在海量数据的采集、存储、清洗和文本聚类,因此传统的仅依据数据统计的舆情分析方法不再适用。
文章对大数据网络舆情分析的相关文献进行总结研究,归纳出网络舆情分析的基本流程框架,并提出了在大数据环境下网络舆情分析各个阶段的解决方案,构建大数据网络舆情分析的基础模型,以此提高网络舆情分析的准确度与及时性。
1 网络舆情分析发展概述
从已有的舆情分析的相关文献中不难发现,社会舆情分析大致经历了以下几个阶段,简单的社会舆情分析,网络舆情分析和大数据环境下的网络舆情分析三个阶段。简单的社会舆情分析主要分析当下热点事件、政府颁布的法令法规与社会舆情之间的关系。简单的社会舆情分析主要通过问卷调查取得原始数据进行分析,例如MacLennan等通过抽样调查的方式研究新西兰民众对于酒精政策的态度,Alan等使用盖洛普世界民意调查数据研究了恐怖袭击与民众态度之间的关系。网络舆情分析伴随着Facebook、微博、微信、人人、Twitter等社交网络平台的兴起应用而生,例如著名的Ceron通过分析2012年Twitter上的法国大选时网民的情感取向数据预测大选的结果。大数据环境下的网络舆情分析是在海量、多样性网络数据的背景下利用大数据分析技术进行的网络舆情分析。
目前大数据时代的数据具有规模性、多样性、变化快速性特征,首先由于网络的开放性每天产生大量的信息,其次多媒体的发展使得数据有多种形态比如文本、视频、图片、音频等。基于目前网络舆情分析的大数据特征,出现了以下几种网络舆情分析方法:基于网络日志数据挖掘的舆情分析、基于社会网络分析的舆情主体关系发现、网络舆情热点分析、关联不同领域的数据舆情分析。
大数据网络舆情分析是一个热点问题,从现有的研究文献来看,对于大数据网络舆情分析更多的是体现在大数据舆情分析的机遇与挑战、以及研究方法的概述与总结上,从技术层面对大数据网络舆情分析的研究较少。
2 大数据网络舆情分析技术
2.1 大数据技术
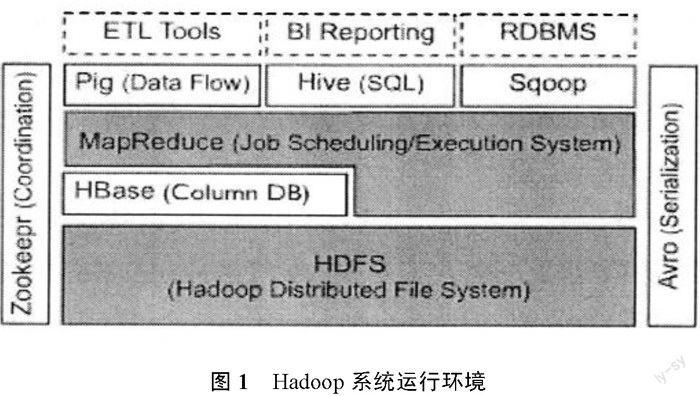
大数据时代的到来对现有的数据处理技术带来了巨大的挑战,目前针对大数据的多样性等特征,在数据存储和数据处理方面都提出了相应的解决方案。在数据存储方面,目前网络舆情分析的数据存储方法主要还是将获取的热点数据直接存储在传统的SQLServer、ORACLE、Sybase等数据库中,大数据的出现导致数据结构多样性,传统的结构性数据库远不能满足当下快速多样的大数据存储的要求,对此目前出现了三种大数据的存储技术:针对海量的非结构化数据的分布式文件存储系统、针对海量半结构化数据存储的NoSQL数据库、针对海量结构化数据存储的分布式并行数据库。在数据计算处理方面,目前并行处理和云计算是解决大数据计算的比较有效率的方式,Hadoop是当前学术界和企业用来解决大数据存储和分析的一个主要技术手段,它是Apache开源分布系统的架构基础,由HDFS、MapReduce和HBase组成,其运行环境如图1所示。
(l)HDFS(Hadoop分布式文件系统)
HDFS是整个Hadoop体系结构中处于最基础的地位,分为三个部分:客户端、主控节点(Namenode)和数据节点(Datanode)。Nanenode是分布式文件系统的管理者,主要负责文件系统的命名空间、集群的配置信息和数据块的复制信息等,并将文件系统的元数据存储在内存中;Datanode是文件实际存储的位置,它将数据块(Block)信息存储在本地文件系统中,并且通过周期性的心跳报文将所有数据块信息发送给Namenode。
(2)MapReduce
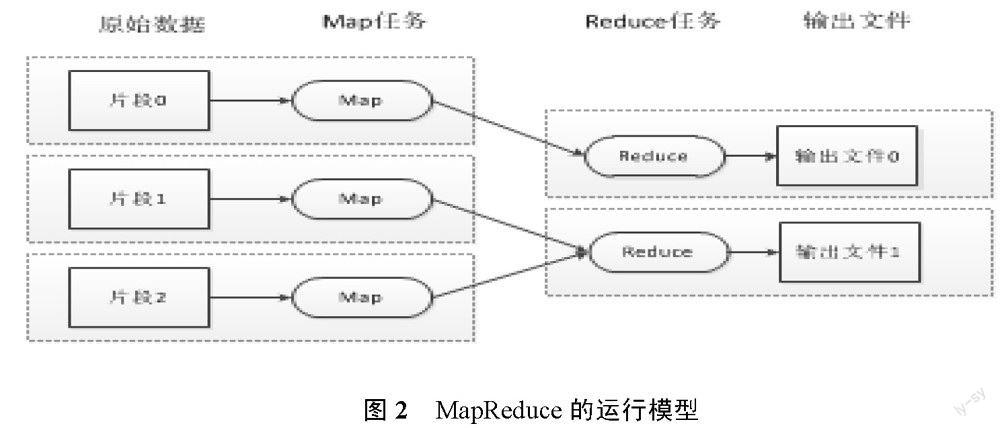
MapReduce分布式计算模型,封装了并行运算、容错处理、本地化计算、负载均衡等细节,提供了简单而强大的接口。通过这个接口,可以把大数据量的计算自动地并发和分布执行,其运行模型如图2所示。
(3) HBase
HBase即Hadoop Database,是一个构建在HSFS上,面向列的开源分布式数据库系统,是GoogleBigtable的开源实现。HBase不是关系型数据库,不支持SQL,HBase提供了一组简单的API接口,用于存储和管理数据。
2.2 网络舆情分析技术
网络舆情分析主要涉及数据采集、文本分词、文本向量表示、文本聚类分类几个方面。
(1)向量空间模型
向量空间模型(VSM)起源于信息检索,简单说来VSM是一种将非结构化的文本表示成向量形式的模型,网络文本用VSM向量空间模型来表示:
v(d)=(t1,w1(t1);…;ti,wi(ti);…tIl,wn(tn))
其中,ti为网络文本d的关键词,wi(ti)为关键词的权值。
如何确定关键词和关键词的权重是网络舆情分析是否有效的关键因素,文章采用TF.IDF指标来确定网络文本的关键词和权值。词频(TF)指的是某一文档中给定单词出现的频次,规范化的表示一般用给定单词的频数除以文档总的单词数。IDF是指逆向文件频率,是一个词语普遍性的度量,规范性的表示一般由包含此单词的文档的数量除以文档的总数,然后取对数得到。
(2)文本相似度计算
相似度计算方式目前有海明距离(Hamming Distance)、欧几里得距离(Euclidean Distance)、余弦距离(Cosine Distance),其中文本相似度计算比较常用的是余弦距离,其计算公式1如下
其中,ai、bi是文本A和B的项。余弦距离的取值区间是[0,1],“0”代表两个文本完全一样,“1”代表两个文本完全不相似。
(3)文本聚类算法
文本聚类算法有很多,比较常用的有四种,基于层次的聚类、基于密度的聚类、基于网格的聚类、基于划分的聚类。文章选用在文本聚类中应用比较多的基于划分的聚类中的K-Means算法,其流程如表1所示。
3 实验方案
文章对大数据环境下网络舆情热点发现提出了基本的技术路线如图3所示
3.1 数据采集
网络信息的采集可以利用网络爬虫技术在特定的网站上进行数据收集也可以利用网站的API接口直接对网站的信息进行采集,获得的网站数据存储在Hbase中。传统的基于网络爬虫的网页解析方式抓取速度较慢,在大数据环境下基于某网站API的分布式数据抓取具有更快的速度。
文章采用了基于Mapreduce的文本采集技术对网站信息进行采集,将普通的网页爬虫系统部署在hadoop平台上,文本采集由主节点和若干分节点组成,主节点作为爬虫系统的NameNode和Jobtracker,负责文件管理及任务调度;分节点作为DataNode和TaskTracker,负责存储文件及运行任务。Jobtracker作为主节点负责分发任务给各分节点,在Map阶段分节点TaskTracker通过网站API进行信息抓取,抓取的数据分布存储在各个DataNode中。
3.2 数据预处理
数据的预处理主要是对原始数据的清洗、抽取元数据,对于网络的文本信息预处理主要是文本的分词、去停用词(主要是一些标点、单字和一些没有具体意义的词,如:的、了等重复出现的词)、文本的特征向量提取、词频统计、文本的模型化表示等操作。
文章采用基于MapReduce的文本预处理技术,MapReduce以函数的方式提供了Map和Reduce操作来进行分布式计算,利用一个输入key/value集合来产生一个输出的key/value集合。在文本预处理过程中,Map函数主要完成文本的分词,将输入的文本进行中文分词,形成词语序列(X1、x2、x3、x4……、Xn)将文本用key/value的形式表示,输出的形式为:(xl、1),(x2、1),(x3、1),……,(xn、1),当所有的Map任务完成后,由主程序将Map函数的输出作为Reduce函数的输入即Reduce函数的输人为(k,[vl、v2、……、vn]),其中(k,V1),(k,v2)……,,(k,vn)Map函数输出结果中键为k的key/value值,如表2所示Map处理过程。
Reduce函数需要计算出特定某个词的IDF值,通过IDF的计算公式 可知需要知道文本数据大小和词语在文本中出现的频率,此时Map输出的Value值为词语的频率,N在文本预处理时可以直接计算得到,经过Reduce计算过后可得到词语的IDF值,将之与Value中的TF值相乘可得到词语的TF.IDF值,将其存储在HBase中的TF.IDF表中。
对于每个文档,保留排列在前面的10个TF.IDF值,识别其对应的主题,以向量空间模型(VSM)表示,行表示主题数,列表示文档数,通过VSM与单位列向量的乘积统计出每个主题所包含的文档数,从而发现网络舆情热点。以上的主题识别和VSM矩阵向量的乘法,同样可以通过Map和Reduce分布式计算得到,在此就不再赘述。
4 实验结果
文章的实验环境总共有四台主机,其中每台机器搭载CORE 15双核处理器,1G内存,500G硬盘,选择其中一台主机作为master节点,剩余3台作为slaves节点,配置Hadoop,配置Linux和Eclipse。文章通过新浪微博的网站API收集了170万条数据,利用上述数据分析方法,对数据进行分析处理得到的分析结果如表3所示:
实验结果与2014年新浪微博热点话题分析报告里的结果有很大程度上的相似,说明了并行分析的准确性,而实验用时比起传统的分析方法节约了很多时间。
5 结论与展望
随着互联网的快速发展,每天都会产生巨大的网络数据,如何快速有效的分析处理数据而不是让数据成为灾难,是在大数据环境下迫切需要解决的问题,在海量的网络数据中快速的获得准确的舆情信息是当前研究的热点和重点。文章结合网络舆情热点发现的基本理论方法和大数据处理技术,提出了在大数据环境下分布式舆情分析的解决方案,重点对网络舆情分析中数据的分布式预处理做了详述,最后利用K-means聚类算法进行网络舆情热点发现。
当然文章还存在很多不足,只是对网络舆情分析的基本过程使用了分布式的处理方法,关于舆情分析过程中的情感倾向分析以及语义分析并未进行研究。
