有限次实施中作战方案选择策略比较研究
2015-12-25万贻平张东戈
万贻平 张东戈
(解放军理工大学 指挥信息系统学院,江苏 南京210007)
1 引言
作战方案选择是军事决策的重要内容。“评估—预案”范式,即根据备选方案的战前评估结果制定预案的模式,是方案选择的常用方法,但其有效性依赖于备选方案评估结果的准确性。而通常评估过程的复杂性、评估主体偏好的不确定性、评估方法的多样性以及适用局限性等因素,都可能导致作战方案的评估结果不够准确[1]。军事复杂系统本身具有的动态性和不确定性,使得准确分析和预测军事系统的行为非常困难[2]。此外战场信息具有的不完整性和不确定性,也会使得战场实际应用环境与方案评估时的环境差异过大,从而导致先前的评估经验结果难以后继使用。陈亚洲等曾研究提出,我军目前作战模型和数据的准确性不高,结果难以得到指挥人员认同[3]。对于作战方案选择问题,传统的“战前评估,战时选择”模式并不能有效解决“预案”不可用所带来的困难。如何在缺乏有效方案评估结果的情况下合理选择作战方案,以期达到最优的战场效果,就成为军事决策者面临的一个重大难题。
从公开文献看,目前对这一问题的研究还较少。对于其中一类包含多次“行动实施”的方案选择问题,可以在实施过程中收集战场实际效果(Effects of Battlefield)信息,利用它动态地指导和调整后面几次作战方案的选择。曾松林等人从动态博弈的角度,研究了空袭作战中,攻击飞机以小架次、多波次的方式进行突击情况下,防空火力单元与攻击飞机多次对抗过程中的目标分配问题[4]。童幼堂将协同作战模式下,舰空导弹多次射击的方案序列优选问题等效为多目标多阶段的优化问题进行了研究[5]。上述研究从特定军事问题出发有针对性地进行了方案选择分析,然而这些分析对有限次实施中作战方案选择的一般性方法策略关注还不够,还需要有进一步的研究。
本文在借鉴Multi - armed Bandit[6]算法思想的基础上,权衡了“有限次实施机会”和“稀缺资源”之间的累计实施效果关系,将有限次实施中作战方案选择问题,建模为稀缺资源最优分配问题。通过对4 种策略的比较研究,探索了不同选择策略各自的特点,由此可以为军事决策提供一般性的方法参考。
2 有限次实施中作战方案选择问题
现代作战可以看成是一种由持续离散型事件组成的任务,在信息系统的支持下,每次事件实施效果可以得到实时评估,由此对于作战人员而言,战术方案可以根据实施效果反馈信息进行适应性地动态调整。而动态调整的策略不同,则会有最终不同的累计实施效果。例如,网络涉军舆情引导作战中,需要程式化甚至自动化地选择使用网络舆情引导技术方案,以达到最好的舆情引导效果。在某些场合下,宣传引导网页的累计点击量越大、引导信息的覆盖面越广,可以被视为舆情引导效果越好。而备选舆情引导方案实施前,难以提前获知网民对各备选方案的感兴趣程度,所以必须通过实际的实施来评估方案的效果。如何在有限的时间内,通过动态选择实施备选方案,来达到累计点击量的最大化,是舆论引导人员面临的重要问题。
据此可以进行模型背景想定设定:某项军事任务需将作战行动重复实施有限多次,每次行动实施之前均需从备选方案集合中选择作战方案,行动实施后产生的战场效果无法提前预知,且结果具有一定的随机性。如何为每次作战行动选择方案,使得累积的战场效果达到最大,就是本文研究的有限次实施中作战方案选择问题。
本文研究的“方案选择策略”所指的,不是具体的作战策略本身,而是策略的策略。我们所关注的,不是如何战争,也不是如何对抗。我们关注的要点是:“如何从战争中学习战争”“如何从对抗中学习对抗”,采用何种策略,才能够让学习的成本尽可能地小。
2.1 基本想定假设
在实际作战中,具体的作战行动所面临的战场条件常常千差万别,所遵循的作战准则也可能各有不同。然而,只要作战行动满足某些特定的条件,那么,就可以将这些作战行动划归为同一类,将作战行动实施中面临的“有限次实施中作战方案选择”问题,界定为本文所要研究的问题。
为便于研究,本文对“有限次实施中作战方案选择策略”中作战行动所需满足的条件做如下的想定假设:
假设1:每次行动实施产生的作战效果不受前期行动的影响。
假设2:作战效果可量化为数值参数,且同一个作战方案在各次不同的实施下,所产生的作战效果统计上服从正态分布。
假设3:行动实施后的作战效果能够被迅速观察或者是测量获得。
2.2 问题描述
2.2.1 有限次实施
假设某项军事任务由重复实施N次的“特定作战行动”组成,将其中的每一次行动都认定为一个过程,每个过程都包含“方案的选择”和“方案的实施”两个阶段。包含有限次行动实施的军事任务共被分解为N个过程,名称分别记为P1,P2,…,PN。根据假设1,P1,P2,…,PN各过程行动通过实施所产生的作战效果仅和所选择的方案有关,与实施的次序无关。
2.2.2 作战方案选择
在“特定作战行动”进入某一具体过程后,首先需要从备选方案集合中选择一个方案,然后实施该方案。设备选方案集合为D ={C1,C2,…,Ck},其中C1,C2,…,Ck分别表示k个备选方案。P1,P2,…,PN各个过程的备选方案集合相同,均为D。需要强调的是,本文将备选方案设定为固定的有限集合,备选方案本身在“有限次”实施中并不发生改进,备选方案的数量也不发生增加,是基于以下两点考虑:一是战争资源的有限性,决定了备选方案是固定的有限集合,装备以及人员的物理属性和自然属性决定了作战双方难以在作战过程中临机地改进和创新出新的作战方案;二是现代战场往往不存在改进作战方案的时间。未来现代战场会有很多程式化的执行,即按一个既定的策略方案连续不断地在动态调整中加以实施,而不能在作战实施过程中停下来调整,因为装备的实施特征决定了不存在这样一个反应时间。
2.2.3 累积战场效果
方案i(i =1,2,…,k)实施后所产生的战场效果,用连续型的数值表示,记为Ei。根据假设2,Ei是一个服从正态分布的随机变量。方案i已实施的次数记为Mi,方案i实施后产生的战场效果统计均值记为¯Ei。累积战场效果E定义为N次行动中k种方案战场效果之和。即当时,有:

3 有限次实施中作战方案选择策略
有限次实施中,作战方案选择问题的特点在于,每个备选方案i被实施后产生的战场效果Ei是一个随机变量,可以通过多次实施来观测和评估。某个备选方案被实施的次数越多,通过统计战场效果而得出的战场效果预估值对Ei的描述就越可信。然而,如果每个备选方案都被实施较多的次数,就会将有限的实施机会“浪费”在方案的选择上,如果选中了较差的方案,就会极大地降低全部方案实施后所累积出来的战场效果值。
一个好的策略,需要在“探索最优方案”和“避免浪费实施机会”两者之间做出权衡,更优的选择策略会使得整个军事任务完成后累积出的战场效果的预期值更大。作战方案选择策略,就是用于P1,P2,…,PN各个过程方案选择的规则。
3.1 随机策略
随机策略(Random Strategy)是第一种策略,它是一种随机选择作战方案的策略。随机策略下,每一个过程Pi中的“方案选择”阶段均随机地从备选方案集合D中随机选择一个方案,然后实施该方案。随机策略是一种通常的策略,本文将随机策略定为不同策略比较的基础,其他策略的特点优劣都通过与随机策略的比较来完成。
3.2 直觉策略
直觉策略(Naive Strategy)是第二种策略,它是首先给每个备选方案分配m次实施的机会,然后将实施完成后各方案战场效果的平均值,作为其战场效果的预估值。该策略将预估值最大的方案作为一个最终的“最佳方案”。以后的N - mk次过程,均选择和实施这个最终的“最佳方案”。该策略简单直观,符合人们的直觉,所以叫作直觉策略。它有以下特点:
(1)策略分为两个明显不同的阶段。前mk次实施为第一阶段,目的是探索最终的“最佳方案”;后N-mk次实施为第二阶段,利用探索阶段所得到的“最佳方案”来实施,以产生最大的战场效果。
(2)m值的选取影响策略的效果。m值如果选得过小,难以保证“最佳方案”可信;m值如果选得过大,则过多的行动机会可能会被分配给较差的方案,甚至是给了明显较差的方案,这会造成实施机会的“浪费”。
3.3 贪心策略
对于有限次实施中作战方案选择问题,可以将有限的N次行动机会等价为稀缺资源,k个备选方案作为资源分配的k个选项,累积战场效果E作为N次分配的总收益。经过这样的考虑,可以将有限次实施中作战方案选择问题等价为稀缺资源最优分配问题。Multi - armed Bandits 作为解决稀缺资源分配问题的算法,被广泛运用于运筹学中的随机调度[7]、临床试验[8]、最优投资及最优分配等相关领域[9,10]。Multi - armed Bandits 算法根据每次收集到的收益信息,在每个决策时点上,动态地调整规则,从而使总收益的预期最大化。该算法由一组可控的随机过程组成,每个随机过程有两种选择:“继续探索”和“坚持以往”[6]。其优势在于,探索阶段将资源更多地分配给先前较优的方案,对先前较差方案,则不做过度探索。
基于Multi - armed Bandits 算法改进出的ε贪心策略(ε-Greedy Strategy),借鉴了Multi-armed Bandits 算法的思想,每个过程均动态选择备选方案。在P1,P2,…,PN各个过程进行方案选择时,以某一较小概率ε随机地选择行动方案,以概率1-ε坚持“当前最佳方案”。该策略用已实施各方案的战场效果的平均值,作为该方案战场效果的预估值,将预估值最大的方案判定为临时的“当前最佳方案”。临时的“当前最佳方案”有可能随探索的进行而继续发生变化。相比较于直觉策略,该策略有以下特点:
(1)保证大部分实施机会(大于1-ε的概率)分配给了“当前最佳方案”,从而避免为较差的方案分配过多的实施机会。
(2)考虑到“当前最佳方案”不一定是最佳方案,该策略以概率ε来“继续探索”最佳方案,从而避免将实施机会永久分配给局部最佳方案。
3.4 置信上限策略
在数理统计理论里的未知量估计问题中,置信区间和置信水平是用来描述估计值可信程度的重要指标。基于Multi - armed Bandits 算法的置信上限策略(Upper Confidence Bound Strategy),用置信上限代替均值作为预估值。对于已实施方案i的战场效果Ei,设其置信水平为1- α时的置信上限为Ui。该策略在各个过程P1,P2,…,PN进行方案选择时,均先计算已实施各方案战场效果的置信上限Ui,将其作为各方案战场效果的预估值,然后判定预估值最大的方案为临时的“当前最佳方案”,并在本次过程中将实施机会分配给“当前最佳方案”。
根据假设2,各方案产生的作战效果服从正态分布,则设方案i实施后所产生的战场效果Ei ~N(μ,σ2),则是μ的无偏估计,且有:

式(2)中,μ为战场效果的期望,σ为战场效果的标准差。
按标准正态分布的上α分位点的定义[11],根据式(2)有:
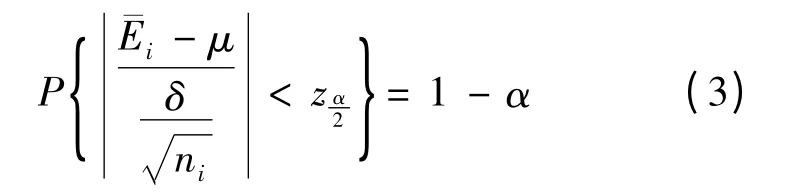
式(3)中,ni为方案i实施次数为标准正态分布的分位点。则:

即已实施方案i的战场效果置信水平为1- α的置信上限Ui为:
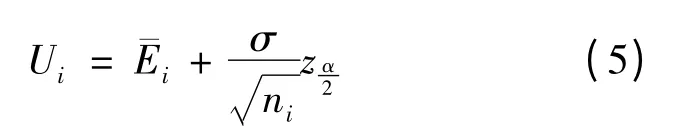
式(5)中,σ与均为常数,且方案i的战场效果均值¯Ei相对稳定,则随着方案i实施次数ni的增大,其预估值ui将变小,这样已实施次数较少的方案就有可能成为新的“当前最佳方案”。相比于贪心策略,该策略将预估值Ui与实施次数ni在公式(5)中结合起来,利用“当前最佳方案”的同时也在探索最优方案,避免了贪心策略中以概率ε“随机探索”的资源浪费。
4 选择策略的仿真计算研究
为了能够更为直观地了解各种选择策略的效果,我们可以通过计算机仿真计算实验对4 种选择策略的特点做定量化的描述。仿真实验采用Monte Carlo 方法,用随机数模拟方案实施后产生的战场效果。为降低随机性的影响,实验重复了1000 次。
4.1 仿真计算参数设定
仿真中涉及的参数设定如下:
(1)作战行动重复实施次数N =3000;备选方案数k =4。
(2)设定4 个备选方案的战场效果期望分别为5、9、6、15,标准差均为2。
(3)直觉策略先给4 个备选方案各分配m =10 次实施机会;之后的N-mk =160 次实施机会均分配给“最佳方案”。
(4)贪心策略中ε的值设定为0.2。
(5)置信上限策略使用σ =1,1- α的正态分布的置信上限作为方案战场效果的预估值。
4.2 仿真计算结果及分析
通过仿真计算,可以得到如下结果,见图1、图2 和表1。
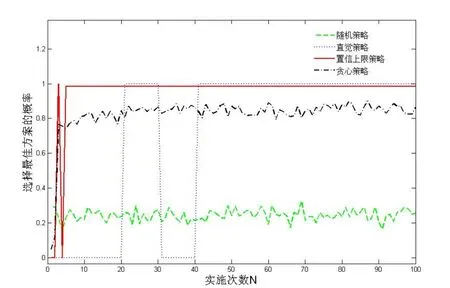
图1 四种策略选择最佳方案的概率

图2 四种策略的累积作战效果

表1 直觉策略和置信上限策略对比
从图1 可以看出,随机策略从4 种备选方案中选择到最佳方案的概率在0.25 附近波动;直觉策略在20-30 次实施时选中最佳方案,40 次实验之后选到最佳方案的概率为1,说明该策略在40 次实验之后成功找到最佳方案;贪心策略选到最佳方案的概率在前几次实验中迅速提高,并维持在0.8 左右的水平,这是由于ε =0.2;95%置信上限策略选到最佳方案的概率在前几次实施中有所波动,并迅速稳定在接近1 的水平。
从图2 可以看出,作战行动重复实施次数N不大于100 的情况下,95%置信上限策略始终保持最大的累积战场效果;直觉策略重复实施次数N超过40 后,累计战场效果保持高增长率。
从表1 可以看出,重复实施次数N超过182 时,直觉策略的累积战场效果超过贪心策略;重复实施次数N超过2350 时,直觉策略的累积战场效果超过95%置信上限策略;重复实施次数N为3000 时,直觉策略的累积战场效果为44746,超过但未显著超过置信上限策略的累积战场效果44736。
通过以上仿真计算,可以得到如下结论:
(1)随机策略是一种较差的策略。
(2)置信上限策略选择最佳方案的概率一直稳定在接近1 的高水平,是一种较为理想的策略。尤其是当有限次实施的重复次数不大时,置信上限策略产生的预期累积战场效果大于其他3 种策略。
(3)当有限次实施的重复次数特别大时,直觉策略可能优于置信上限策略,但优势不明显。
5 结束语
有限次实施中作战方案选择问题是现代战争面临的一个重要问题,性能良好的“方案选择策略”能够指导和帮助作战指挥人员、战场设计人员、武器系统研究人员和装备作战使用研究人员,研究和设计在信息系统的支持下的备选方案动态选择。本文提出并模型化了有限次实施中作战方案选择问题,并比较研究了几种选择策略的特点,为作战方案选择问题提供了方法参考。然而,作战双方或多方的动态应对、方案作战效果的统计学特征和实施次数等因素影响着选择策略的有效性,本文对此未做深入探讨分析。在下一步的研究中,我们将研究不同因素对较优的方案选择策略的影响。
[1] 许诚,杜茂华,孙有田,等. 反舰导弹武器系统作战效能评估风险初探[J].军事运筹与系统工程,2010,24(2):30 -33.
[2] 黄柯棣,赵鑫业,杨山亮,等. 军事分析仿真评估系统关键技术综述[J].系统仿真学报,2012,24(12):2439 -2447.
[3] 陈亚洲,刘建平.作战模拟在指挥决策领域推广应用面临的问题与对策[J].军事运筹与系统工程,2012,26(4):27 -38.[4] 曾松林,王文恽,丁大春,等. 基于动态博弈的目标分配方法研究[J].电光与控制,2011,18(2):26 -72.
[5] 童幼堂.舰空导弹指挥决策模型及应用研究[D]. 大连:大连理工大学,2005.
[6] WHITE J. Bandit algorithms for website optimization[M]. O'Reilly Media,Inc.,2012.
[7] CAI X,WU X,ZHOU X. Optimal Stochastic Scheduling[M].Springer,2014.
[8] LAI T L. Sequential analysis:some classical problems and new challenges[J]. Statistica Sinica,2001,11:303 -408.
[9] MCLENNAN A. Price dispersion and incomplete learning in the long run[J]. Journal of Economic dynamics and control,1984,7(3):331 -347.
[10] KELLER G,RADY S. Optimal experimentation in a changing environment[J]. The review of economic studies,1999,66(3):475 -507.
[11] 盛骤,谢式千,潘承毅. 概率论与数理统计[M]. 北京:高等教育出版社,2008.
