基于分块切片的软件错误定位技术
2015-12-20文万志陈建平鞠小林
文万志,陈建平,陈 翔,鞠小林
(南通大学 计算机科学与技术学院,江苏 南通226019)
0 引 言
基于 谱的 软 件 错 误 定 位 技 术[1-4](spectrum-based fault localization,SBFL又称为基于覆盖的软件错误定位技术)被普遍认为是一种当前最高效的软件错误定位技术之一,其研究主要集中在两个方面:一是可疑度的度量;二是测试覆盖信息的优化。可疑度度量通过改进可疑度计算公式来提高软件错误定位技术效率,典型的可疑度计算公式有Tarantula[2]、Ochiai[2]、WONG3[2]、ILI[5]等。测试覆盖信息的优化技术一般通过删除冗余测试用例、设置测试用例优先级等方法来改进可疑度度量的精确性,例如,Yoo等的基于信息理论的测试用例优先级技术[6]、Xuan等的分割测试用例技术[7]、Masri等的测试用例聚类技术[8]。
SBFL技术的主要缺点是语义分析较弱,而且顺序语句的可疑度通常无法区分。基于程序切片的错误定位技术[9-11]通过提取兴趣点处与兴趣变量依赖相关的语句以缩小错误搜索范围,这在一定程度上可改进SBFL 技术的语义较弱问题。不足是,大规模程序的程序切片构造代价较大。文中提出了一种基于不可区分块构建分块切片的方法,并通过实验验证了分块切片的约减度及基于分块切片错误定位技术BSlicing-SFL技术的有效性。
1 分块切片的构造
1.1 不可区分块
定义1 不可区分语句:令F(s)为计算程序P中语句s的可疑度计算公式,对同一组测试覆盖δ,F(s)=f(failed(s),passed(s)),其中,failed(s)是失效测试通过s的统计次数,passed(s)是成功测试通过s 的统计次数,f 是变量failed(s)和passed(s)的函数,若F(si)≡F(sj),则程序语句si和sj为不可区分语句。
上述定义中,failed(s)、passed(s)的统计次数根据不同公式统计方法有所区别,可以是程序击谱的统计,也可以程序频谱的统计。一般来说,顺序执行的语句是不可区分的。
理论上,所有不可区分语句可作为一个分块,然后基于分块进行可疑度度量可大大减少统计规模。然而,同一个分块内聚性如果过低,会引入大量错误无关元素,从而降低错误定位的效率。通常,一个不可区分块为一个函数方法或过程 (以下统称为方法)中连续的不可区分语句组成。
定义2 不可区分块:给定程序P的方法M 中语句序列为<s1,s2,…,si,…,sj,…,sn>,则满足以下3个条件的语句序列<si,…,sj>称为不可区分块:
(1)语句序列si,…,sj中所有语句为不可区分语句;
(2)si,… ,sj-1序列中所有语句为非调用语句;
(3)si-1或sj+1加 入 到 序 列 组 成 的 新 序 列 不 满 足 条 件(1)或 (2)。
条件 (1)限定不可区分块中语句为不可区分语句,条件(2)限定不可区分块的划分不但要在代码序列上保持连续性,也要在执行序列上保持连续性;条件 (3)限定不可区分块应当是不可扩展的最大的块。
程序由函数方法组成,方法之间存在调用关系,每个方法由顺序、选择和循环3 种结构组成。令CallNode,BrachLast,PreNode,LoopLast,MethodLast分别表示调用节点,选择分支块尾节点,选择和循环条件谓词节点,循环体尾节点,方法尾节点,不可区分块构造算法如下:
算法1:不可区分块构造算法
输入:程序P
输出:不可区分块集合BlockSet

程序中,语句的选择执行会造成语句的覆盖信息不同,PreNode,BranchLast,LoopLast这3种类型的语句的下一条语句的覆盖信息有改变的可能,根据定义1,它们是可区分语句,属于不同的块。CallNode和MethodLast节点的下一条语句是另一个方法或程序执行结束,根据定义2,属于不同的块。设程序规模为n,则整个不可区分块的构造时间复杂度为O(n)。
1.2 分块切片的构造
分块切片由兴趣块的控制依赖块和兴趣变量的数据依赖块组成。
定义3 块系统依赖图BSDG (block system dependence graph)。块系统依赖图是一个二元组 (B,E),其中,B 是程序P 中不可区分块集合,E=DDEdge∪CDEdge,DDEdge是块间数据依赖边集合,CDEdge 是块间控制依赖边集合。
定义3中,不可区分块B 通过算法1构造,算法2给出了的块间数据依赖和控制依赖实现算法。
算法2:块系统依赖图构造
输入:程序P
输出:块系统依赖图BSDG

算法2中,块间控制依赖和数据依赖的前提条件是Bi,Bj间存在一条可执行路径,即Bj∈Path(Bi)。控制依赖不同于控制流图中的边,当前节点只控制依赖于前驱转向节点PreNode和CallNode。数据依赖要求是当前块中的变量在前驱节点中被使用,并且当前节点和前驱节点的中间节点Bm没有对变量重新定义。
传统的动态切片根据不同的输入集提取与兴趣语句和兴趣变量相关的语句,然而构造大量的动态切片的时间复杂度和空间复杂度都很大,效率不高,基于此,本文采用以下切片准则。
定义4 切片准则:切片准则是一个三元组<B,V,T>,其中B 为程序P中一个不可区分块,V USE [B],T 为P的某个测试覆盖的基本块集合。
根据上述准则,构造分块切片可分为两步:①根据兴趣块B 和兴趣变量集V 逆向遍历BSDG,得到静态切片BlockBWSlice;②生成动态切片BlockDSlice=BlockBWSlice∩T。
静态BlockBWSlice一旦构造,根据历史测试覆盖,在时间复杂度为O(n)规模下完成BlockDSlice的构造。
1.3 基于分块切片的错误定位
基于分块切片,本文的错误定位模型如图1所示。
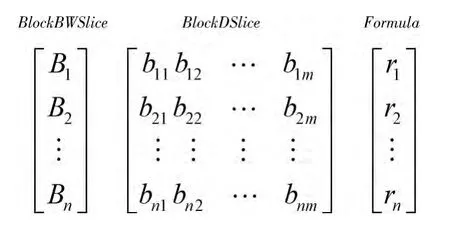
图1 基于分块切片的软件错误定位模型
图1中,Bi(i=1,…,n)为静态BlockBWSlice,bij(i=1,…,n;j=1,…,m)表示每个测试tj(j=1,…,n)对Bi的覆盖情况,ri(i=1,…,n)根据测试覆盖统计公式计算的语句可疑度值,据此值从大到小依次检查相应语句来定位程序中的错误。较传统模型,本文的模型从3个方面进行了改进。通过分块切片,将不可区分的语句组合成一个基本块,并通过构造静态BlockBWSlice极大减少错误定位元素规模;只有满足Bi∈BlockBWSlice∩Ti,即Bi∈BlockDSlicei时,bij才表示成被覆盖,减少了无关元素对可疑度度量的干扰;基于BlockDslice约减重复测试用例,减少测试覆盖的重复统计,如果BlockDSlicej=BlockDSlicei,则BlockDSlicej为直接重复覆盖,如果BlockDSlicek=BlockDSlicei-BlockDSlicej或 BlockDSlicek= BlockDSlicei+BlockDSlicej,则BlockDSlicek为间接重复覆盖。
1.4 实例分析
图2通过一个简单例子说明上述我们的方法过程,其中,图 (a)是较常见的实例程序,图 (b)是块依赖图BSDG,图 (c)是根据切片准则实例<14, {a}, {1,2,3,4,6,7,8,9,10,11,12,13,14,15}>通过逆向遍历BSDG 得到的BlockBWSlice 和BlockDWSlice,图 (d)是基于BlockBWSlice (14,{a})错误定位模型。
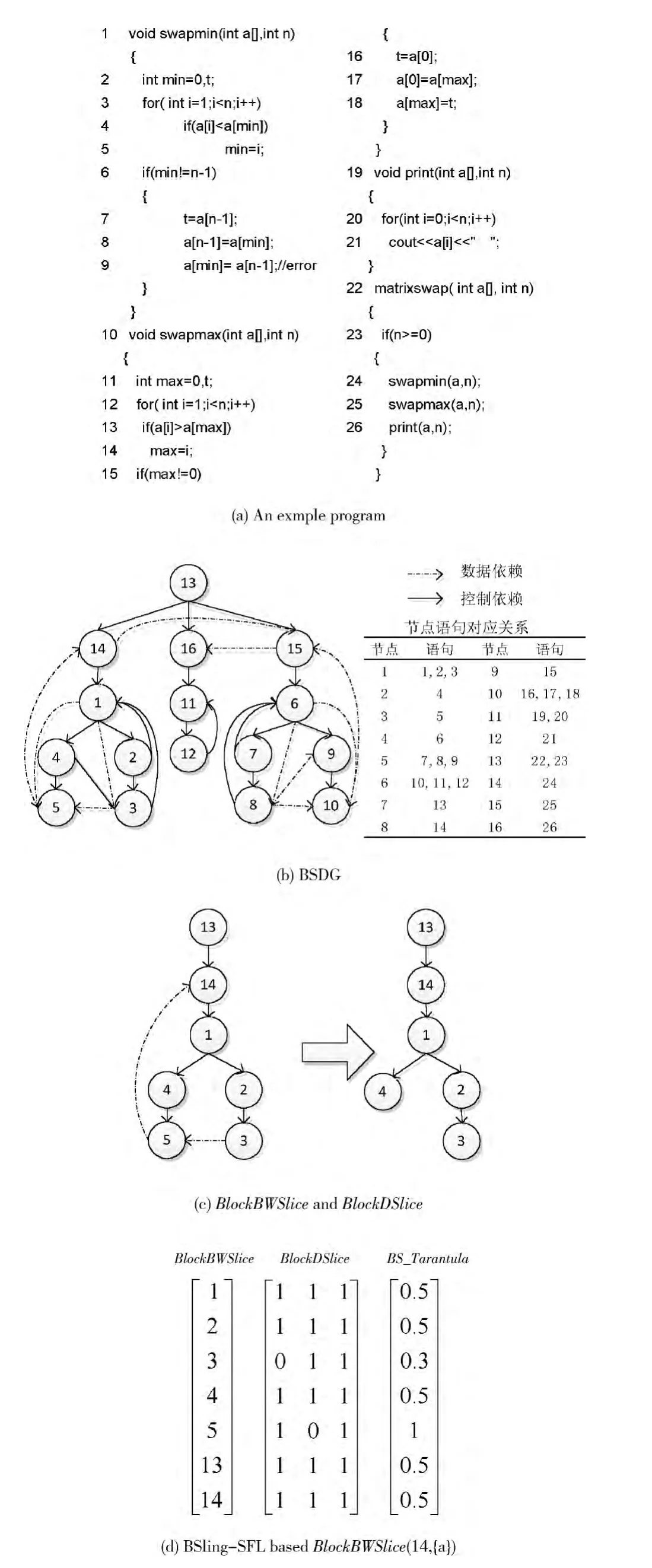
图2 BSlicing-SFL实例
图2 (a)中,程序语句1,2,3;7,8,9;10,11,12;16,17,18;19,20;22,23 (为方便描述,文中函数头节点、谓词节点等统称为语句)在传统的基于程序覆盖的错误定位算法中,其覆盖信息总是相同,因此它们的可疑度大小总是相同,是无法区分的。大量的可疑度列表只会让软件调试者选择更加传统的全手动方式进行软件错误定位。因此,文中对不可区分语句进行分块,对类型为PreNode,BranchLast,LoopLast,CallNode,MethodLast等语句作为分块基线 (算法1)。语句3,6等为PreNode语句,其后的语句实现跳转;语句9为BranchLast语句,因为程序分支的选择执行,后续语句覆盖信息改变;语句21 为Loop-Last,其是否执行取决于循环条件;语句24为CallNode语句,虽然后续顺序语句25与语句24的覆盖信息相同,语句24执行时直接跳转到调用方法,其控制依赖和数据依赖关系和语句25有着很大的不同,如果语句24和25属于同一个基本块,切片的提取将会有很大的冗余;语句9 为MethodLast语句,执行结束后会跳转到主调函数。这里,虽然语句9既是BranchLast,又是MethodLast,并不影响最终分块。图2 (b)右下表格中详细列出了语句对应的分块列表,并给出了块之间的数据依赖和控制依赖。由于语句块14的执行取决于PreNode语句块13的执行,所以图中语句块14控制依赖于语句块13,CallNode语句块14执行决定了语句1的执行,因此,语句块14控制依赖于语句块13。语句块5使用了语句块1中定义的变量a和n,而且在语句块1到语句块5的可达路径上变量a,n 没有被重新定义,因此语句块5 数据依赖于语句1。据此方法生成了BSDG (算法2)。图2 (b)中,如果两节点之间同时存在数据依赖边和控制依赖边,我们只构造一条边,不影响图的连通性和切片的求解。图2 (c)根据切片准则实例<14,{a},{1,2,3,4,6,7,8,9,10,11,12,13,14,15}>生成的程序切片。从节点14 逆向遍历BSDG 得到BlockBWSlice (14, {a})= {1,2,3,4,5,13,14},提取了程序的一个片段,较大的减小了程序规模。在一般简单的例子程序中,语句间大多存在控制依赖关系和数据依赖关系,有些切片效果并不明显。例如,本例子中,如果求解BlockBWSlice(15,{a}),由于变量a依赖于swapmin的求解结果,所得切片相对较大。但针对稍大型的实际软件,切片效果会很明显,下文通过实验验证了这点。图2 (c)中BlockDSlice= {1,2,3,4,5,13,14}∩ {1,2,3,4,6,7,8,9,10,11,12,13,14,15}= {1,2,3,4,13,14}。图2 (d)中,BSlicing-SFL 技术将传统的错误度量元素约减成BlockBWSlice(14,{a});删除重复测试覆盖,BSlicing-SFL只包含3 条测试覆盖信息。例子程序中,语句9是错误语句,测试1和测试3 是失效测试,结合Tarantula度量算法,得到图2 (d)中第三列可疑度度量结果,根据可疑度大小顺序,能很快定位到错误语句块5。
2 实证研究
本节通过3个实例验证了基于分块切片的软件错误定位技术的有效性,本文主要研究了以下几个问题:
(1)分块切片的约减度;
(2)当前主流的软件错误定位技术与BSlicing-SFL 技术的有效性比较;
(3)当前主流的软件错误定位技术与BSlicing-SFL 技术定位同一错误时优劣比较。
2.1 实验对象
本文选择了3 个实际应用中的程序作为实验对象,见表1。

表1 实验对象
表1 中,Tetris 和SimpleJavaApp 为 开 源 代 码(http://www.percederberg.net/games/tetris/tetris-1.2-src.zip,http://codecover.org/documentation/tutorials/SimpleJavaApp.zip)。Tetris为经典的俄罗斯方块游戏,SimpleJavaApp主要完成对书目列表的编辑。JHSA 是我们团队开发的一个JAVA 程序的层次切片工具,相比前两个实验对象,增加了程序规模。表1的第二列是程序中植入的错误数。3个实验对象均使用JAVA 语言编写,实验基于Eclipse平台实现。
2.2 评价指标
本文使用约减率RR (reduction ratio)来度量分块切片的约减度,其评价方法为
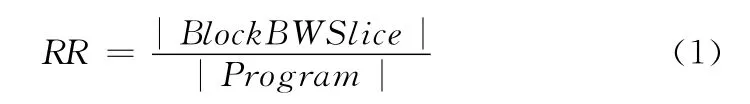
上述公式中,绝对值表示元素规模。在程序规模不变时,当定位错误所构造的BlockBWSlice规模越小,则约减度越大,定位效果越好。
软件错误定位技术有效性通过定位率LR (location ratio)来度量,其评价方法为

式 (2)中SLFR (successfully located faults ratio)是已经成功定位到的错误与总共植入的错误比率,ECR(examined code ratio)是成功定位到错误已经检测的程序代码与程序总代码的比率。当ECR 相同时,SLFR 值越大,即检测相等比例规模的程序代码能定位到更多的错误,则错误定位有效性越高。理论上,对所有错误版本,如果ECR 趋向0,SLFR=1,则软件错误定位技术达到最优化。
对于不同软件错误定位技术的定位同一错误,本文通过ECR 大小来评价技术的优劣。
2.3 实验设计
实验验证比较了BSlicing-SFL 技术基于流行的Tarantula、Union、Intersection度量方法的有效性。其中,Tarantula技术由于其效率高,易实现,被广泛应用于软件错误定位技术中。其对程序元素可疑度的度量方法如下

式中:suspiciousness(e)——程序元素e的可疑度,failed(e)、failed——通 过e 的 失 效 测 试 数 和 失 效 测 试 总 数,passed(e)、passed——通过e 的成功测试数和成功测试总数。
Union技术和Intersection技术是典型的切片集合度量技术。其可疑程序元素集合为

式中:f、p——失效测试、成功测试,P——成功测试集合。
实验中,为了比较技术优劣,错误定位次数以定位到程序中语句统计,块或集合中语句按程序代码顺序依次遍历定位。
本文的主要实验过程如下:
(1)利 用 开 源 工 具codecover(http://www.codecover.org/)收集测试覆盖信息;
(2)基于文中算法框架构造分块切片BlockBWSlice、BlockDSlice;
(3)统计约减度RR;
(4)基于Tarantula、Union、Intersection 度量方法统计错误定位率LR,并进行比较分析。
2.4 实验结果与分析
2.4.1 分块切片约减度RR 的统计
理论上,分块切片提取了与错误依赖相关部分,在一定程度上减少了程序中可疑元素度量规模。实验中,通过统计分块切片的约减度RR 来验证约减程度,表2 列出了各对象程序的RR。

表2 约减度
表2中第二列给出了统计RR 的BSlicing 兴趣集。实验对象Tetris和SimpleJavaApp数据依赖和控制依赖较强,最终得出的切片约减度在0.3以上,实验对象JHSA 的约减度相对较好,主要是因为JHSA 的子功能较多,切片集中与兴趣数据无关的子功能代码被约减。由于JHSA 基数较大,切片的绝对代码量要大于Tetris和SimpleJavaApp。总体上,如此约减规模已经较大的减少了传统的全代码度量规模。
2.4.2 错误定位率LR 的统计
本节通过Tarantula、Union、Intersection的度量方法验证BSlicing-SFL技术的有效性。实验统计了定位所有错误版本所需检测的代码率,图3展示了不同技术的统计结果。其中,BS_Tarantula、BS_Union、BS_Inter是采用Tarantula、Union、Intersection可疑度度量方法的BSlicing-SFL技术。为了统一度量规模,实验中以定位到程序中错误语句为成功定位,对语句块或可疑度相等的程序元素(块或语句),按代码顺序检测。

图3 错误定位技术有效性比较
图3中横坐标是式 (2)中代码检测率ECR,纵坐标是式 (2)中成功定位到的错误与总错误的比率SLFR,曲线的斜率大小反应了错误定位率LR。ECR 很小时,如果曲线斜率越大,则LR 越大,错误定位效率越高。一般认为,在代码检测率很小时成功定位到的错误率最能反映错误的有效性,因此,实验中特别统计了ECR 为0.01,0.05 时SLFR 的值。从图中可以看出,BSlicing-SFL 技术要优于传统的技术。图3 (c)中,BS_Tarantula与Tarantula技术都有着较高的定位效率,在ECR<0.01时成功定位到的错误率接近0.2,随后,直到ECR 为0.3,BS_Tarantula技术以更大的斜率增长,效率更高。图3 (a)、图3 (b)的技术在ECR 很小时,错误定位效率较低。这主要和Union、Intersection的度量方法有关。Union、Intersection 的度量方法的语句检测顺序是先检测集合中的语句,如果错误不在集合,Union按程序代码顺序依次检测失效测试和程序,Intersection则依次检测成功测试交集和程序。Union方法在通过错误语句的测试都失效的情况下,程序错误在集合中,定位效果较好。本实验中,Intersection方法所得到的所有错误版本的集合都是空集,因此错误定位效率较低。BS_Union、BS_Inter错误检测顺序为先检测BlockDSlice的Union和Intersection集合,然后检测BlockBWSlice 集合。在相等的ECR 时,BS_Union、BS_Inter有着相对较高的效率。
2.4.3 同一错误的ECR 比较
为了比较不同的技术在具体的程序错误定位方面的优劣,实验选取了其中的10 个错误,对其检测代码率ECR进行了统计分析,如图4所示。
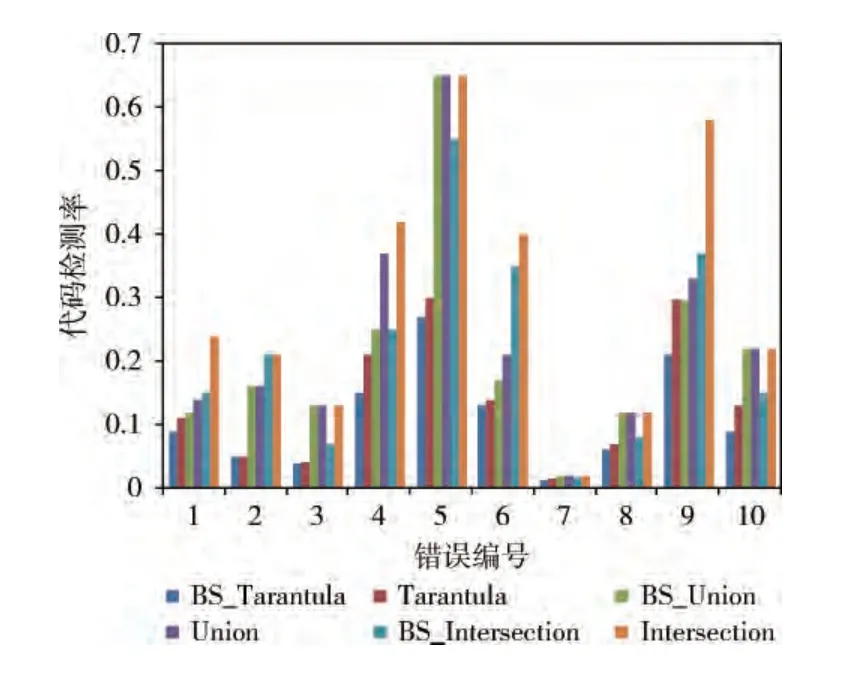
图4 相同错误的检测代码率比较
图4中纵坐标是成功定位到错误所检测的代码率,横坐标是错误编号。10个错误中,基于BSlicing-SFL 技术要优于或等于同类度量方法的技术;不同度量方法,错误1、2、6、9采用Union技术优于BS_Intersection技术,Tarantula技术优于BS_Union技术,其余6个错误采用BS_Intersection技术要优于Union技术。
2.5 讨 论
2.5.1 有效性威胁
通过上述实验结果和分析,BSlicing-SFL 技术能有效缩小错误元素度量的规模,并且能有效改进相同度量方法的Tarantula、Union、Intersection技术的有效性。实验中,主要存在两方面的不足:
(1)程序切片技术是基于数据依赖和控制依赖关系构建的。如果程序错误是由于依赖关系的破坏或缺失引起的,基于程序切片的软件错误定位技术效率会大大降低,本文的BSlicing-SFL技术也是如此。例如,在构建数据依赖时,当前节点使用的变量在程序流图中的前驱节点中如果被定义,且没有被重新定义过,则当前节点依赖于前驱节点。然而,如果前驱定义节点有错误,无法判断变量被定义,则当前节点的依赖关系就会向前追溯,从而构造的切片将不会包含错误节点,造成错误定位效率的降低。
(2)由于并发依赖的复杂性以及构造效率低下,文中并没有考虑并发依赖,因此文中的技术局限于单线程程序。
2.5.2 相关工作
BSlicing-SFL技术通过识别不可区分块生成不可区分块,然后构造分块切片进行错误定位。与该技术密切相关的主要是基于程序切片的错误的定位技术。
自从Weiser提出程序切片技术以来,基于程序切片的软件错误定位技术一直是研究的热点[9-13]。近几年提出的基于程序切片的软件错误定位技术主要有:Ju等提出的基于全切片和动态切片的技术[10];Mao等提出的近似动态后向切片的统计技术[11];Binkley等提出的不依赖语言的程序切片技术[14];笔者提出的基于程序切片谱技术等[9]。文中通过划分不可区分块,构造程序切片,在更大程度上减少了程序度量规模,减少程序可疑度分析努力,这与当前的技术是不同的。
3 结束语
本文提出了一种基于分块切片的软件错误定位技术——BSlicing-SFL实现方法。本文给出了不可区分块构造算法、基于块数据依赖和块控制依赖的系统依赖图构造算法,随后通过遍历系统依赖图生成静态切片BlockBWSlice和动态切片BlockDSlice,在此基础之上,统计计算静态切片BlockBWSlice中元素可疑度值进行错误定位。文中通过3个实际应用程序验证了BlockBWSlice 的约减度、BSlicing-SFL错误定位的有效性。
分块切片与其它切片技术一样会因为依赖关系的破坏而造成软件错误定位技术效率的降低,未来,将着重构造一些潜在依赖关系来解决这类问题。
[1]Wikipedia.List of software bugs[EB/OL].http://en.wikipedia.org/wiki/List_of_software_bugs,2015.
[2]Xie X,Chen TY,Kuo FC,et al.A theoretical analysis of the risk evaluation formulas for spectrum-based fault localization[J].ACM Transactions on Software Engineering and Methodology,2013,22 (4):1-40.
[3]DiGiuseppe N,Jones JA.On the influence of multiple faults on coverage-based fault localization [C]//Proceedings of the International Symposium on Software Testing and Analysis,2011:210-220.
[4]Xue X,Namin AS.How significant is the effect of fault interactions on coverage-based fault localizations [C]//Proceedings of ACM/IEEE International Symposium on Empirical Software Engineering and Measurement,2013:113-122.
[5]Moon S,Kim Y,Kim M,et al.Ask the mutants:Mutating faulty programs for fault localization [C]//Proceedings of the IEEE International Conference on Software Testing,Verification and Validation,2014:153-162.
[6]Yoo S,Harman M,Clark D.Fault localization prioritization:Comparing information theoretic and coverage based approaches[J].ACM Transactions on Software Engineering and Methodology,2013,22 (3):19.
[7]Xuan J,Monperrus M.Test case purification for improving fault localization [C]//Proceedings of the 22nd ACM SIGSOFT International Symposium on Foundations of Software Engineering,2014:52-63.
[8]Masri W,Assi RA.Prevalence of coincidental correctness and mitigation of its impact on fault localization [J].ACM Transactions on Software Engineering and Methodology,2014,23(1):8.
[9]Wen W.Software fault localization based on program slicing spectrum [C]//Proceedings of the 34th International Conference on Software Engineering,2012:1511-1514.
[10]Ju X,Jiang S,Chen X,et al.Hsfal:Effective fault localization using hybrid spectrum of full slices and execution slices[J].Journal of Systems and Software,2014,90 (4):3-17.
[11]Mao X,Lei Y,Dai Z,et al.Slice-based statistical fault localization[J].Journal of Systems and Software,2014:89:51-62.
[12]Xie X,Wong WE,Chen TY,et al.Metamorphic slice:An application in spectrum-based fault localization [J].Information and Software Technology,2013,55 (5):866-879.
[13]Lei Y,Mao XG,Chen TY.Backward-slice-based statistical fault localization without test oracles[C]//Proceedings of the International Conference on Quality Software,2013:212-221.
[14]Binkley D,Gold N,Harman M.ORBS:Language-independent program slicing [C]//Proceedings of the 22nd ACM SIGSOFT International Symposium on Foundations of Software Engineering,2014:109-120.
