基于海量电力数据的用电管控平台
2015-12-16钟世冠
钟世冠,苏 超
(广东电网有限责任公司清远供电局,广东清远,511515)
基于海量电力数据的用电管控平台
钟世冠,苏 超
(广东电网有限责任公司清远供电局,广东清远,511515)
针对电力企业自动化、信息化高速发展产生的海量电力数据,建立了基于Hadoop的数据存储管理与挖掘平台,结合MySQL数据库,Spark技术,满足了离线、实时储存和处理海量用电数据的要求;同时,结合GIS技术,将分析结果动态展示在GIS地图上,以可视化的方式展示电网各项指标及电力供需情况。本文基于此平台进行电力数据的挖掘分析并将其应用到电力系统中,能够有效地进行用电行为分析,馈线分析应用以及电力的负荷预测,实时预测与状态分析,从而进行更有效地电力管控。
Hadoop平台;数据挖掘;电力系统
0 引言
随着电网规模快速扩大、信息技术的快速发展,信息自动化技术已广泛应用于电网各系统中,在提高供电可靠度和客户服务方面取得了显著的成效,为满足国民经济和社会发展的需要,提高客户服务质量提供了有力支撑。随着信息化技术的应用,电网采集数据的实时性高且数据量剧增,而企业对数据应用管控能力却远远滞后于数据的增长。在传统的存储中采用磁盘整列,关系型数据库和套装软件,虽然能满足日常管理,但从海量的数据中得出有效的结论需经过长时间的整理分析,无疑降低了对数据的有效利用。随着智能电网的发展,云技术,分布式计算以及挖掘算法都被应用到电网中,进行电力数据的处理并取得了一定的成果。云技术尚处于发展的初期,其虚拟技术,安全问题,具体的框架体系等还需进一步研究;分布式计算与挖掘算法更适用于离线分析,但很难满足电网数据的实时存储与处理要求。
本文建立的用电管控平台充分结合这些技术,基于Hadoop平台,采用实时数据库与分布式数据库的存储方式,同时将实时与关系型数据库相结合,可以高效离线、实时存储和处理海量用电数据,提高系统运行性能,有效减轻现有计量自动化系统的负担,满足更高的用户精细化多样化的需求。

表1 本文用电管控平台与传统电力数据存储分析的对比Table 1 The comparison between the management and control platform in this paper and traditional storage and analysis of electric power data

图1 用电管控平台构架Fig. 1 The frame of management and control platform
1 平台构架
本文构建的用电管控平台的构架如图1所示,平台中采用的关键技术包括Hadoop技术,关系型数据库及Spark技术等。Hadoop技术的核心为HDFS分布式文件系统和MapReduce模型。HDFS分布式文件系统实现了对Hadoop分布式存储的底层支持,而MapReduce的分布式处理框架很适用于处理大规模的数据,集群系统具有良好的伸缩性,为分布式处理提供了编程框架支持。在数据处理中的关系型数据库是MySQL数据库。根据MySQL数据库实时性好,运行速度快,在处理小型数据时更占优势,且对硬件要求低以及价格较低等优势。因此,在平台搭建中结合Hadoop技术与MySQL数据库的优点,来处理电力系统中的数据。Spark技术将中间处理数据保存在内存中,减少对磁盘的读写次数,数据处理速度快。在处理实时流数据方面,Spark Streaming容错性高,集成性好,可以同时进行批量和实时数据处理,将历史数据与实时数据结合起来。Spark可以通过Hadoop2发布的YARN资源管理器与Hadoop结合,弥补Hadoop在速度和实时处理上的不足。
本平台中处理的数据源主要来自计量自动化系统,能量管理系统(EMS系统),营销系统,营配一体化数据中心及外部数据。数据的获取通过web服务或采用传统或实时ETL技术从MySQL数据库获取,存储于分布式数据库及传统数据库中,利用Spark,SmartMing及结合R语言的RHadoop进行数据分析,通过数据管理平台,可视化平台,GIS平台及移动应用平台,进行客户分析,包括计量装置分析,实时线损计算,用电行为分析,馈线分析应用,电力负荷预测,负荷实时预测等。
基于前面对于Hadoop,传统数据库及Spark技术的分析可以知道,实时数据的处理主要采取实时与关系型数据库相结合的方式,而分布式存储则主要应用与离线分析。
表1展示了本文用电管控平台与传统电力数据存储分析的技术与性能上的对比。

图2 电力海量数据的数据管理平台Fig. 2 The management platform of massive electric power data
2 数据管理平台
用电管控平台中数据的管理平台如图2所示,构建包括数据接入、数据处理、数据加工、数据存储、元数据管理、访问服务、支撑工具以及平台管理等服务功能;主要分为以下几个部分:
2.1 FLUME数据接入层
FLUME可以可靠地采集、聚合和传输分布式海量日志,将其用在最开始的层面进行数据的接入导出,从数据源或者web服务收集数据后,将数据缓存起来,并提供对数据简单的预处理,进行多路数据分发,存入HDFS,Hbase或MySQL数据库中以便进行离线计算,或实时分发去进行实时计算。
2.2 AMBARI系统监控部署层
采用AMBARI支持Hadoop集群的供应、管理与监控使得Hadoop的管理更加简便。本平台中Ambari系统监控部署层包括集群部署和系统监控,集群部署包括模板部署和快速扩展,系统监控包括对资源负载和机器存活的监控以及问题的快速定位。
2.3 基础组件层
基础组件层包括RPC(Remote Procedure Call)远程过程调用,对象持久化,Zookeeper节点管理以及安全管理:SSH(Secure Shell,安全外壳协议)和SSL(Secure Sockets Layer,安全套接层)。远程过程调用保证了在分布式系统中,一台计算机上的程序能调用另一台计算机的程序,实现服务器间的通信。对象持久化将内存中的数据保存在数据库或存储设备中,保证数据不会丢失。Zookeeper是针对大型分布式系统的可靠协调系统,协调集群中的各个节点的工作,保证了配置数据的一致性和高可用,并基于Zookeeper实现分布式同步,配置维护,命名服务和集群管理等。而安全管理:SSH和SSL安全协议则保证了数据通讯在应用和传输中的安全性。
2.4 数据库存储层
数据存储层包括MySQL数据库和HBase NOSQL数据库,Hbase是一个建立在HDFS上的高可靠,高并发读写,高扩展,可实时读写的数据库系统,相对HDFS更适合低延时的处理,与MySQL适合结构化数据存储相对,Hbase适合半结构化和非结构化数据的存储。Hbase是Hadoop的子项目之一,因此,属于于Hadoop与传统数据库的一个结合。MySQL用来进行小数据的处理和Meta数据(元数据)的管理。MySQL数据库和HBase NOSQL数据库通过Sqoop进行互联互通,Sqoop还可以通过Hadoop的Mapreduce将数据从关系数据库导入到据到HDFS。
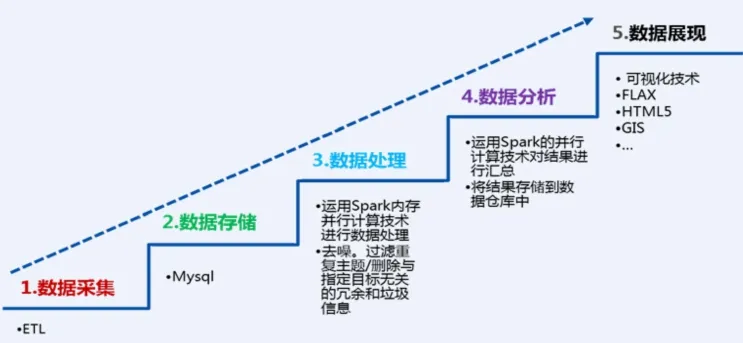
图3 实时计算流程Fig. 3 Flow chart of real-time computing
2.5 资源管理层
资源管理层采用YARN资源管理器,YARN是Hadoop新一代的的数据处理框架,突破了MapReduce框架的一些性能瓶颈,YARN能够允许多种应用程序高效、可控地同时运行于同一集群上,可以运行如MapReduce,Spark,Storm等各种计算框架,能够有效地将这些技术结合起来。
2.6 数据仓库层
数据仓库层是分布式,高扩展及并行处理的框架,利用Hive和Impala系统进行SQL查询,能查询HDFS和HBase中的PB级大数据,Hive适合需长时间运行的批处理,而Impala省去了MapReduce的启动,更快速,适用于实时查询满足查询的交互性。Pig较为灵活,可以开发简洁的脚本进行数据的转换,加载数据以及存储最终结果,提供了简单一个的操作和编程接口。MapReduce用于离线处理分析,而Spark则负责实时处理分析。Mahout包含许多实现,包括聚类、分类、推荐过滤、频繁子项挖掘等,可以快捷地从数据中创建智能应用程序,用于分布式数据挖掘。
3 实时计算及数据挖掘
本平台中海量数据实时计算的流程如图3所示,数据采集主要通过ETL技术,数据的存储采用传统的Mysql数据库,数据的处理与分析采用Spark实时计算和并行计算技术,将结果存储到数据仓库中,利用可视化技术将其展示出来。本平台的数据挖掘,采用ETL技术从数据库或通过web服务获取到数据,数据的存储与处理基于Hadoop技术,采用HDFS分布式存储系统以及MapReduce计算框架,处理后的结果将其存入MySQL中,然后再利用数据挖掘技术(R Hadoop、Spark)对其进行分析挖掘,R Hadoop是结合了R语言的Hadoop,R语言和Hadoop在数据分析上各有所长,结合了R语言之后的RHadoop在数据分析功能上更为完善,最后再将结果存入MySQL中,并通过可视化技术展示出来。数据挖掘的总体架构如图4所示。

图4 数据挖掘总体架构Fig. 4 Overall architecture of data mining
4 应用分析
4.1 变电站运行计量装置有效性实时测试,及电量数据追捕
使用ETL技术,每隔15分钟采集一次数据,并将数据存入MySQL,面向最终要展现的指标,使用Spark技术进行数据处理,包括汇总、过滤、排序等。建立常见的错误接线模型(纠偏公式模型),对计量装置进行实时测试(错误接线模型),对电量异常进行报警,并在云GIS地图上显示。通过对其功能点的研发,可实现对计量装置实时监测,对电量异常进行电量追补,并将结果反馈在云GIS地图上。通过在线监测数据为电量状态管理、故障处理等提供了技术支持。
4.2 海量数据的实时线损计算
基于各个计量点的最小颗粒度数据,进行实时线损计算(计算频率为15分钟),大大的提高了线损计算效率、准确性及实时性。实时线损计算结果反馈在云GIS地图上,线损查询可按日期区间或单点时间选择查询,日期区间查询精确到分钟(15/30分钟),单点时间查询按15分钟,30分钟,小时,天查询。这样可以快速查询指定区域的线损信息,为业务部门提供快速、全面、准确的决策和管理依据。
4.3 馈线分析应用
馈线分析应用的核心是预估某馈线上现有用户各个时段的总用电量,主要方法:
(1) 建立时间序列预测模型,以某馈线下所有用户为总体研究对象,针对历史总用电数据进行训练学习,建立预测模型,总结用电规律,量化分析,并使用模型对未来用电量进行预测。
(2) 使用大数据定律的思想,建立每个时段的平均预测模型。即计算每天、每周和每月同期用电的平均值,以平均值作为未来同期预测的依据。
完成模型建设和评估之后,针对最终选择的模型进行应用,将算法写到后台,建立预测分析体系,并开发BS架构的web交互系统,满足用户的分析查询和结果呈现。
本平台自动统计馈线容量,追踪其饱和状态的持续时间,用户容量及剩余容量,判断馈钱是否可以报装新用户,给予业务部门提示,这样将传统统计馈线容量的方式转变为自动化的工作模式,大大的提高了业务部门的工作效率,并为公司业务部门提供决策支持。
5 结语
本文详细研究了基于海量数据用电管控平台的建设,重点分析了其数据管理平台,在Hadoop构架的基础上结合了其最新技术,引入实时数据库和分布式数据库的存储方式,同时将实时与关系型数据库相结合,以符合高效离线、实时存储和处理海量用电数据的要求,提高系统运行性能,有效减轻现有计量自动化系统的负担,对海量的用电数据进行挖掘,为电力系统提供了更高效的用电管控平台参考。由于Hadoop技术应用到电力系统仍处于初步阶段,硬件平台及具体实践等仍需进一步研究。
[1] 江道灼,申屠刚,李海翔,等.基础信息的标准化和规范化在智能电网建设中的作用与意义[J].电力系统自动化, 2009, 33(20): 1- 6.
JIANG Daozhuo,SHEN Tugang,LI Haixiang,et al. Significance and roles of standardized basic information in developing smart grid[J]. Automation of Electric Power Systems,2009,33( 20): 1-6.
[2] 赵江河,陈新,林涛,等,基于智能电网的配电自动化建设[J].电力系统自动化, 2012, 36(18):33-36.
ZHAO Jianghe,CHEN Xin,LIN Tao,et al. Distribution automation construction in smart grid[J]. Automation of Electric Power Systems,2012, 36(18):33-36.
[3] 王景燕.基于云计算的电力调度信息化研究[J].电工技术, 2011(12):3-4.
WANG Jingyan.Power construction enterprise information
strategy based on cloud computing[J]. Electric Engineering, 2011(12):3-4.
[4] 王德文, 宋亚奇, 朱永利.基于云计算的智能电网信息平台[J].电力系统自动化,2010,34(22):7-12.
WANG Dewen,SONG Yaqi,ZHU Yongli.Information platform of smart grid based on cloud computing[J].Automation of Electric Power Systems, 2010, 34(22):7-12.
[5] 胡平,王忠群,刘涛,等.基于分布式OSGi的通用电力数据平台[J].计算机工程,2014, 40(3): 71-75.
HU Ping,WANG Zhongqun,LIU Tao,et al.General electric data platform based on distributed OSGi[J]. Computer Engineering, 2014, 40(3): 71-75.
[6] 熊浩,李卫国,黄彦浩,等.基于模糊粗糙集理论的综合数据挖掘方法在空间负荷预测中的应用[J].电网技术, 2007, 31(14): 36-40, 56.
XIONG Hao,LI Weiguo,HUANG Yanhao,et al.Application of Comprehensive Data Mining Method Based on Fuzzy Rough Set in Spatial Load Forecasting[J],Power System Technology, 2007, 31(14): 36-40, 56.
[7] 贺瑶,王文庆,薛飞.基于云计算的海量数据挖掘研究[J]. 计算机技术与发展, 2013, 23(2): 69-72.
HE Yao,WANG Wenqing,XUE Fei.Study of Massive Data Mining Based on Cloud Computing[J].Computer Technology and Development, 2013, 23(2):69-72.
[8] 赵俊华,文福栓,薛禹胜,等.云计算:构建未来电力系统的核心计算平台[J].电力系统自动化,2010,34(15): 1-5.
ZHAO Junhua,WEN Fushuan,XUE Yusheng,et al. Cloud computing:Implementing an essential computing platform for future power systems[J].Automation of Electric Power Systems, 2010,34(15): 1-5.
[9] 李伟,张爽,康建东.等.基于hadoop 的电网大数据处理探究[J]. 电子测试, 2014(1): 74-77.
LI Wei,ZHANG Shuang,KANG Jiandong,et al. Research on Massive Data for Grid Using Hadoop[J]. Electronic Test, 2014(1):74-77.
The Management and Control Platform Based on Massive Electric Power Data
Zhong Shiguan,Su Chao
(Guangdong Power Grid Corporation,Qingyuan,511515,China)
In order to deal with the massive electric power data generated by the automation of power enterprise and the high-speed development of information technology,this paper establishes a Hadoopbased data storage,management and mining platform.It combines MySQL database,Spark technology and meet the requirements of offline and real-time storage and processing of massive electric power data;in the meantime,it combines GIS technology and dynamically displays the analysis results on GIS maps,which visually demonstrates the indices of power grid and the situation of electricity supply and demand.This paper conducts data mining and analysis of electric power data based on the platform and applies them in electric power system,which can effectively analyze the behavior of electricity consumption and feeder line analytic application and forecast electric load,and therefore better controls and manages the electric power system.
Hadoop platform;data mining;power system
TM734
A
钟世冠(1975—),男,高级工程师,主要研究方向:电力系统信息化管理。
广东电网有限责任公司科技基金资助项目(K-GD2014-0777)
苏超(1985—),男,工程师,主要研究方向:电力系统信息化管理。
