语义词库关联的藏文Web语义检索系统研究与实现
2015-12-14高红梅魏西峰王崧华扎西
高红梅魏西峰王崧华扎西
(西藏大学藏文信息技术研究中心西藏拉萨850000)
语义词库关联的藏文Web语义检索系统研究与实现
高红梅魏西峰王崧华扎西
(西藏大学藏文信息技术研究中心西藏拉萨850000)
文章依据所抓取的大量藏文网页URL,对相关的藏文信息网页进行除噪去重处理,得到较为完善的藏文信息库。对用户要查询的藏文信息进行预处理和藏文语义标注,通过基于本体的词汇相关性算法,扩展藏文的查询词汇,建立一对多的藏语词汇联系,从而实现藏文查询中的相关性检索,得到更加符合用户需求的语义关联网页信息。
藏文网页;信息库;藏文语义相关;藏文语义扩展
引言
艾瑞报告显示,2015年第一季度,中国搜索引擎市场规模达到156.4亿元,同比增长34.6%,同比增速较上季度下降10.6个百分点[1]。虽然移动互联网发展如火如荼,但是传统互联网依旧是市场的主流。随着藏文信息处理技术的发展,使用藏文网页的人群也越来越多,覆盖区域越来越广。Google和微软等公司都在藏文检索方面有所研究,但目前还都是基于关键字的搜索应用,准确率与查全率都不尽人意。
目前,国内藏文搜索研究还处于摸索期,海南藏族自治州藏文信息技术研究中心以青海湖藏汉文网站为平台,于2013年4月正式启动了藏文搜索引擎系统的开发,但至今仍未投入使用。同时,很多研究机构开始进行藏文语义搜索研究。本文通过构建语义知识库实现藏文语义检索来完善当前藏文检索方式的不足,使检索系统能自动“联想”到与其同义或者近意的词,提高信息匹配的准确度,达到提高检索系统整体性能的目的。
1 藏文网页抓取预处理
1.1 藏文分词
藏文字为拼音文字的印度字体体系,每一组单音节藏文字符串代表藏语中的一个音节,每个音节代表藏语中的一个词或词素[2],每个藏语句子由音节字构成,每个音节字又由音节点或其它符号隔开。目前,西藏大学、中科院、青海民族大学等多家高校和研究机构根据藏文语言文字的特性,进行了多种规则研究和统计研究,各有侧重点,但没有形成规模的藏文分词系统。因此,本文仍采用基于词典的最大匹配法进行分词。
1.2 藏文网页除噪去重
网址库抓取的藏文网页包含多种噪声信息,如广告、版权、导航条、网站目录等,可以通过去掉HTML文档中的修饰标签、去掉网址中包含的“?”、“#”、“=”、“(”等链接,或者去掉藏文文本中包含等链接的方式去噪。由于下载的网页重复率较高,会使检索的网页数据量异常庞大和冗余,因此还需对除噪后的网页进行去重处理。通过对下载的300多篇藏文网页信息进行分析后发现,目前网页重复现象主要表现为完全重复和近似重复两种情况。前者称为镜像网页,可用“If URL(P1)≠URL(P2)and Tit le(P1)=Tit le(P2)”语句直观判断,如果为真,比较文档首行和最后一行,若判断相同放弃;后者用MD5算法为每个文档计算出一组摘要,如果网页P1和P2计算出的摘要满足判定条件,则可判断网页信息内容部分重复,不再进行保存和处理。
2 藏文语义关联分析
2.1 藏文语义检索模型
信息检索是根据用户检索请求,从大量信息源中找出满足请求的信息,将结果按照用户检索词的相关性大小进行排序后反馈给用户。如果对已经存在的大量信息源不做任何处理,检索效率会降低。对文本进行预处理,才能达到提高检索效率的目的,使用户搜索出的信息更加有用。
划分信息检索模型一般有3种依据:表示文本和查询、判断查询内容与资源相关以及计算相似度。信息检索分为数据检索、全文检索和语义检索3种,其中较为常用的是数据检索和全文检索,而语义检索难度较大[3]。
本文从文本信息中提取出有用信息文档是预处理的目的,根据领域知识建立文本的词汇与概念之间的映射关系,将非结构化的文本信息与结构化的领域知识建立关联,从而利用结构化的知识来协助检索非结构化的文本信息,处理过程见图1。
2.2 藏文文本语义映射构建
如图2所示,将已经下载的网页信息保存为text文档格式,分析网页并判断出符合要求的藏文信息,提取出网页的链接和文档藏文标题,并同时用“主要内容”、“关键词”、“高频词”和其他与文本内容有关的藏文词汇对文档进行修饰,建立一对多的相关性文档匹配库,将文档直接抽象成藏文词汇。形成文本内容语汇关联,生成Web页码入口的索引。
那天,我们一进屋,就见炕沿上坐着一位身材苗条,衣着讲究,模样漂亮的姑娘,眯着好看的大眼睛向我们直笑。霎时,我们就像进了老师的办公室,规规矩矩地总想往别人后面站。
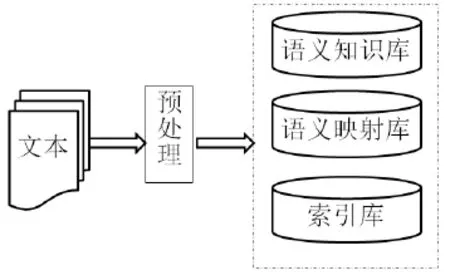
图1 文本处理过程

图2 藏文索引文档保存流程图
2.3 文本语义提取
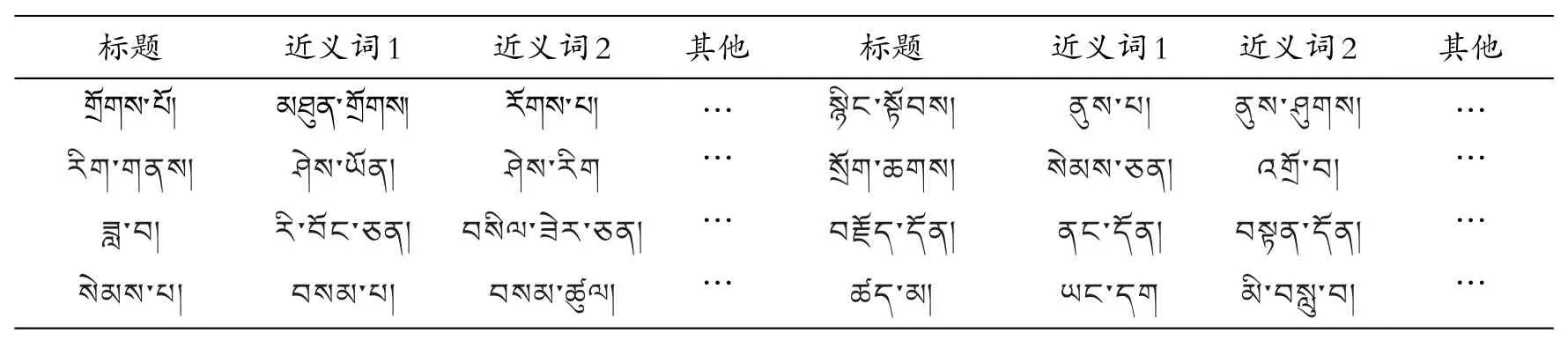
表1 藏语词汇关联库
表1显示,通过分析文档内容的藏语特征词汇,通常为文本标题词汇、关键字、高频词和其他补充信息词汇等,构建藏语词汇与文档语义之间的映射关系。实验对400多名有藏文搜索体验的用户进行调查发现,对检索结果中标题相关的关注率为64.4%、对关键字的关注率为40.2%、对高频词的关注率为32.7%、其补充信息诸如体裁、文体格式等的关注率为20.9%。给以上数据不同的权重值,使文档与词汇有明确的数量级关系,再分析知识库中词汇的语义,评价其是否存在于已经抽取的特征词汇中。若存在,将包含该语义的文档以及权值一并标在该语义旁,达到将文档和知识库关联起来的目的,即用词汇表现出文档隐含的语义信息。表2为图2中下载保存文档提取的主题词、高频词、格式和内容等词汇和URL的映射关系。检索词汇时可以先通过表1拓展查询范围,再和表2进行关联,就可以得到更多的地址值,起到增加查询范围的目的。
2.4 语义知识库的构建
在检索中,以某一领域的知识体系为基础,形成该领域所有知识的信息库,对信息库中的信息进行逻辑推理和分析,构建信息的组织体系和对文档进行语义标注,可以从语义上理解用户的查询目的,从而实
现语义层面的信息检索[4]。对藏文文本建立基于概念的索引,本质上是在对藏文文本内容特征提取的基础上生成索引,其目的是要在索引中反映出文本标引词之间的内在联系。基于概念的索引方式是通过将每一个词汇库内的藏文词汇进行语义分析,对同义词或近义词进行线性相关的连接,使藏文词汇之间产生联系,起到“举一反三”的效果,从而使词库中的藏文词汇与之前没有任何联系的藏文文本之间建立关系。如图3“日喀则”概念实体举例中,需要先创建地区类,其中包括特色旅游、交通方式和所属县等,然后再创建日喀则对象,对其定义相关内容进行使用,实现对象实例化。

表2 URL映射关系库
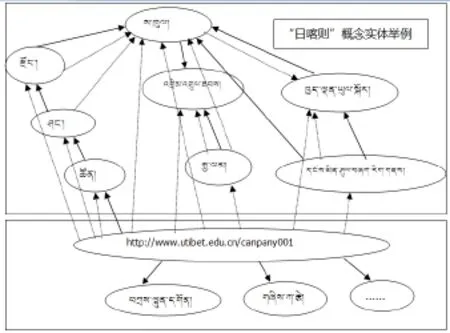
图3 语义知识库
3 基于领域知识库的藏文文档检索
图4为藏文相关性检索流程图,通过对输入的检索词进行分词处理后,首选先判断是否有检索结果,没有则改变检索条件再次进行匹配。在有检索结果的情况下通过词汇关联和语义知识库关联,把检索结果进行相似度计算,最后得出显示结果。
3.1 检索信息词汇处理
用户先在已有的检索界面输入目标藏文检索词或语句,然后对检索信息进行分词,去掉藏文文本中的虚词,仅取有实际意义的词或词组。如果条件允许,还可对文本信息进行情感分析。选择索引项,确定可用作索引元素的词(词干、词组),获得能正确表达藏文文本内容的概念性词或词组。如在句子中和是问句中的主要信息,其他均为虚词,在处理过程中,可以去除这些对用户目的无影响的无关因素,留下有实际意义的藏文词汇作为查询词传递给查询转换模块。然后在已有的语义表中查找出相应的词汇概念,若藏文词库中找不到的概念词进行保留操作,随后反馈给用户,让用户及时调整检索策略,重新定义目标词。
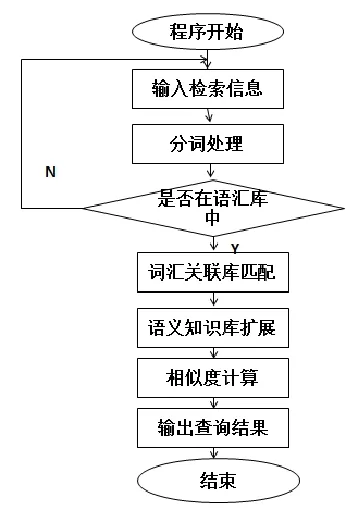
图4 藏文相关性检索流程图
3.2 词汇关联库匹配
3.3 基于语义知识库的藏文语义查询扩展
在普通信息检索中,经常出现由于用户所选择的词和文档中出现的目标词不匹配或者匹配度不高等问题,导致了检索效率低下乃至整个检索失败。在藏文信息检索中,由于藏文网页较少,用户所选藏文词汇与目标藏文词汇的匹配度更低,甚至会出现用户搜索的藏文信息在信息库中无法查询的现象。在此情况下,查询扩展技术(QueryExpansionTechnology)在原有查询技术的基础上增加了与用户输入的查询词相关联的相关词,使查询信息的表达词汇更长、更准确,这样可以在一定程度上弥补用户查询信息不足的缺陷。藏文查询扩展技术借助如图3所示的藏文语义知识库及其推理机制,对用户要查询的藏文信息进行语义层次的不同方向的扩展,使检索系统可以更好地分析出较完整的用户查询意图,清楚用户的查询目标。这样将扩大检索信息范围,用户更容易找到想要的目标信息。
3.4 基于领域知识库的藏文文本相似度计算方法
在藏文信息检索的整个过程中,检索系统首先要参照领域知识库对用户所输入的藏文查询信息进行预处理。在对输入的藏文查询信息预处理后,还要解决用户查询信息概念的“多义词”,基本明确用户的信息检索意图,结合概念在自然语言领域中的上下文语境,初步得出藏文语义信息。以为例,其近义词为和通过概念在自然语言中的环境相似度,对词汇与词汇之间建立联系。
但要解决藏文查询信息中经过预处理抽离出的藏文词汇中的“多义词”,对用户查询请求中的关键藏文词汇进行语义扩展,仍需要借助藏文词汇相关性和相似性的计算来处理。藏文语义扩展的主要依据即是藏文词汇相似性和相关性,所以提高藏文词汇间的相似度和相关度计算精度,就是藏文语义信息检索的核心技术。
本文采用JaccardSimi larity方法计算文档相似度。采用两个文档主题词以及其相关的同义词和近义词集合的交集除以两个集合的并集,得到的值即为两个集合的相似度。
数学表达式是:s1={主题词1U标题1U关键词1U其同义词1U近义词1}
S2={主题词2U标题2U关键词2U其同义词2U近义词2}
Sim(s1,s2)=|s1∩s2|/|s1U s2
此方法容易实现,计算结果按相似度从大到小进行排序,最后在用户界面中显示出查询的排序结果,由用户自行选择需要的目标结果。对匹配结果的排序并不是无休止的,对查询结果的显示进行阀值设定,只需对阀值以上的结果进行排序即可,阀值以下的目标结果可理解为相关性极低或无相关性,对其不予处理。
4 结论
本文给出了一种的藏文语义检索模式,在用户对目标信息进行描述后,通过对用户输入信息的判断,将所得处理结果和领域知识库内的藏文词汇进行匹配,并通过相似度计算,根据阀值筛选出满足用户需求的藏文网页链接,点击进入目标页面。与传统的藏文检索结果相比较,运用基于概念索引和基于领域知识库查询的检索方式的查全率和查准率均有所提高。
[1]张希,艾瑞:2015Q 1中国搜索引擎市场规模156.4亿元[EB/OL][2015-11-10].http://report.iresearch.cn/htm l/20150515/ 250202.shtm l.
[2]刘涛,杨秀霞.中国多民族文字信息处理中的Unicode编程[J].计算机工程与设计,2006(6):2021-2025.
[3]毛会芳.基于本体的Web语义检索方法的研究[D].广州:华南理工大学,2011:7-8.
[4]张健.BIM环境下基于建设领域本体的语义检索研究[D].大连:大连理工大学,2013:6-7.
[5]余传明.语义检索的原理及其实现[J].理论与探索,2007(2):182-183.
Research on Searching Tibetan W eb’Semantic related to Semantic Association Thesaurus
Gao Hong-mei WeiXi-feng Wang Song-hua Zha xi
(Research Centerof Tibetan Information Technology,TibetUniversity,Lhasa 850000,China)
Tibetan information pagewasmanipulated by de-noising and de-duplicating process to obtain an im⁃proved Tibetan information database based on the a large number of Tibetan web page URL grasped.Semantic tagging and preprocessing was conducted for the querying Tibetan information user wanted and association of one tomany Tibetan vocabularieswas established based on the running the vocabulary correlation algorithm,ex⁃tending the querying Tibetan words so as to realize the relevance of Tibetan query retrievaland to obtain related semanticweb information in linewith needsofuser.
Tibetanweb page;information library;Tibetan semantic relevancy;Tibetan semantic extension
10.16249/j.cnki.54-1034/c.2015.02.015
TP393.092
A
1005-5738(2015)02-090-06
[责任编辑:索郎桑姆]
2015-09-17
2014年度西藏大学国家级大学生创新创业训练计划项目“藏文Web语义检索的研究与实现”(项目号:201410694018);2013年度国家自然科学基金重点项目子课题“藏文词法分析系统与舆情监测知识库构建”(项目号:61331013);2013年度青年科研培育基金项目“西藏旅游目的地营销系统运营模式研究”(项目号:ZDPJSK2013080)阶段性成果。
高红梅,女,汉族,四川乐山人,西藏大学藏文信息技术研究中心讲师,主要研究方向为语义网。
