基于hadoop的大规模查询日志分析模型设计
2015-12-12马宪敏
马宪敏
(黑龙江外国语学院,黑龙江哈尔滨,150025)
基于hadoop的大规模查询日志分析模型设计
马宪敏
(黑龙江外国语学院,黑龙江哈尔滨,150025)
日志分析对于在用户搜索领域有着很重要的意义,目前的日志分析系统有着不少弊端,比如:海量数据无法处理、离线处理模式、处理时延长等。对日志数据采用分级归档,可以实现大数据的分级优化处理。本文通过提出在一种基于Hadoop的大数据日志分析模型,并对其业务处理流程以及功能架构进行深入分析,实验结果反映出该系统扩展性强、海量数据处理能力卓越、满足在线处理等,具有良好的可行性和有效性。
Hadoop;海量日志处理;查询;模型设计
0 引言
查询日志是记录搜索引擎用户查询词和返回的网页等相关信息的文件。通过分析用户查询日志,提取用户搜索行为特征,对搜索引擎检索结果进行处理,可以使搜索引擎返回更加准确的检索。
用户查询日志分析是信息检索领域的一个热点,也是研究搜索引擎效率和用户行搜索行为的重要手段。近年来,国内外的学者对搜索引擎查询日志分析已经做了很多研究。随着网页信息量的增加,要进行大规模日志分析,将面临系统扩展性,并发性,数据稳定性等诸多问题,因此本文提出了一种基于hadoop的大规模用户查询日志分析模型。其中hadoop是一个分布式处理框架,该模型借助Hadoop框架下的HDFS实现了查询日志的分布式存储,利用分布式数据仓库Hive实现了海量数据的并行查询与分析。
1 hadoop相关技术
1.1 hadoop框架
Hadoop是一个分布式系统基础架构。hadoop框架的核心包括:分布式文件系统HDFS,大规模并行计算编程模型Mapreduce。
HDFS是hadoop下实现的分布式文件系统,由一个命名节点Namenode和若干个数据节点Datanode组成。采用主/从(Master/Slave)工作模式,由Namenode作为主节点(Master),负责数据的管理,由Datanode作为从节点(Slave),负责数据的分布式存放与备份。HDFS有着高容错性的特点,非常适合超大规模数据集的应用。
Mapreduce是hadoop框架下的分布式编程模型,由map和reduce两个阶段组成,使得开发分布式并行计算程序的难度降低。输入文件通过map阶段将原始数据映射到用户自定义的key/value键值对集合中,reduece阶段将键值对集合进行处理后输出最终结果。
1.2 Hive
Hive是一个分布式的数据仓库工具。有以下4层结构:①用户接口形式;②元数据的存储方式与格式;③解释器、编译器、优化器、执行器;④HDFS。
用户接口分为3个部分:CLI, Client和WUI。其中CLI是比较常用的,启动CLI会同时有一个Hive副本产生。Hive的客户端是Client,Hive Server作为服务器供用户连接。客户端模式启动的时候,Hive Server应该指定所在节点并同时在此节点来启动服务器。Hive是通过WUI用浏览器访问的。
数据库被Hive用来存放元数据,如mysql、derby。Hive中的元数据有如下结构:表的名字;表的列和分区及其属性;表的属性;表的数据所在目录等。
在HQL查询语句中,解释器用于词法分析,编译器用于语法分析,优化器用于编译、优化同时生成行查询计划并存储在HDFS中,然后通过Mapreduce调用并执行。
Hive的数据存储在HDFS中,大部分的查询由Mapreduce完成。
2 查询日志分析模型
2.1 数据集与数据格式
搜索引擎日志分为用户点击日志和用户查询日志,本文采用的是实验室提供的搜索引擎用户查询日志,为期一个月,共计21426940条。与用户点击日志不同的是用户查询日志更加简洁。
2.2 模型整体设计与工作流程
利用hadoop框架下HDFS安全可靠的存储性能,根据大规模数据分布式存储的需求,并结合分布式数据仓库Hive下HQL编程简洁易懂,日志分析模型如图1所示,该模型包括三个模块:并行ETL模块,并行分析模块,结果处理模块。
首先,并行ETL模块从日志服务器得到用户查询日志后,对日志进行预处理操作,并加载到分布式的HDFS上,由hadoop框架自动实现备份。然后,并行分析模块根据具体的分析方法,并行加载HDFS上的文件到Hive所建立的表中,通过HQL语言进行统计分析,Hive会将HQL语言转化为Mapreduce,Mapreduce由各个节点并行执行。最后返回分析结果并存储。
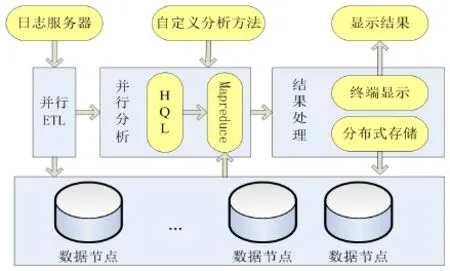
图1 模型整体框架设计
2.2.1 并行ETL模块
ETL(Extraction-Transformation-Loading)是数据提取、转换和加载的简称,是数据仓库技术中数据预处理必不可少的一步。将日志进行了如图2所示的ETL处理。

图2 并行ETL模块
(1)数据提取
实验室提供了一个月的用户查询日志,以一天为单位,共计一个月的日志信息量。
(2)数据转换
首先,用户查询日志的编码格式是GBK,我们需要将GBK转化为Hive中采用UTF-8格式,防止查询词出现乱码的情况。其次,各个字段之间的分隔符不一样。采用自定义Hive的输入格式inputformat来控制输入。
(3)数据加载
用HQL语言在Hive中为每天的查询日志建立表:CREATE EXTERNAL TABLE Sogou_query_log (字段1,字段2……) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' LINES TERMINATED BY ' ', 表的字段和日志的字段相同。Hive并行地加载本地日志文件到表中,表被保存到hadoop下的HDFS上,并实现自动备份。
2.2.2 并行分析模块
经过ETL操作,得到了可用于直接查询的日志信息。日志分析模块提供了统计查询词长,查词频分析,URL排名与点击量关系的分析,高级搜索比例等分析功能,并允许用户添加自定义的分析方法。分析模块使用编程难度低的HQL语言实现。根据分析请求,Hive将HQL语句解释成为相应的Mapreduce程序,读取分布式文件系统HDFS保存的日志表文件,各个数据节点并行执行,计算出相应分析结果。
2.2.3 结果处理模块
该模块包括了存储和显示两个操作,将分析模块输出结果自动保存到HDFS中,数据节点相互备份,安全稳定地存储日志文件和分析结果文件,并提供到终端予以显示。
3 结果分析和模型优化
3.1 实验结果分析
使用4台PC机搭建hadoop分布式计算模型, 分别为pc1~ pc4, 其中pc1作NameNode,并在pc1上配置Hive,pc2~ pc4作DataNode和TaskTracker。每台PC机具体配置如下:硬件环境: Intel( R) Core(TM)2 Duo CPU 2.20GHz; 2GB内存; 100G硬盘; 100Mbps网口。软件环境: Ubuntu 10; JDK1.6.0_27; hadoop 0.20.3; Hive 0.10.0。
3.1.1 查询词长分析
查询词长是对查询词包含中文字个数的度量。查询词的长度能在一定程度上影响返回的查询结果,并反映用户查询习惯。经实验数据分析,在用户查询日志中的平均查询词长为9.5个字节,约为4个汉字。查询词长为2个字节到32个字节的用户占了所有查询的96.5%。文献在Excite和AltaVista搜索引擎上所测得英文查询词平均长度为2.25个英文单词。说明中文和英文查询用户的查询词都比较短,搜索引擎要准确地检索结果存在一定困难。所以这要求中文搜索引擎需要对查询用户的需求有更好的理解和分析,才能更好地提供查询结果。
3.1.2 查询词频分析
查询词频分析也称为热榜排名分析,查询词频是指同一查询词重复查询次数。经统计,排名前100的查询词查询次数占总查询次数的69.13%。
结果分析表明搜索引擎查询词出现频率和频率的排名存反比关系。所以搜素引擎每天处理的工作有大部分是相同的,少部分的查询能够满足大部分查询用户的需求。为此,引入缓存机制和建立多级索引机制能够很好的适应用户的重复查询特性。
3.1.3 用户首次点击与URL排名关系
用户提交一次查询,搜索引擎根据提交的查询词,检索算法和排序算法返回相关联的网页,用户根据个人喜好和检索特点,选取合适的网页点击。为了研究用户对返回网页的点击行为,我们对URL排名和用户的点击量的关系进行了分析。根据实验结果,我们将实验结果分为两组:排名前20的网页和排名100到1100的网页,两组结果分别如图3和图4所示。
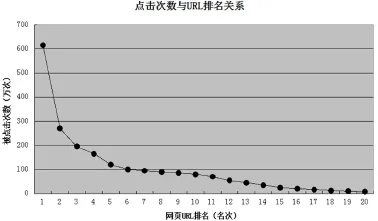
图3 点击量与URL排名(排名前20)
在第一组实验结果中,点击量前10的网页点击次数总共约为1763万条,占总查询数的82.29%,这说明约80%的用户只关注查询结果排名前10的网页,即返回结果首页的网页。分析结果要求搜索引擎采用的排序算法能将与查询词相关度高的网页尽可能地显示在前面。

图4 点击量与URL排名(排名100-1100)
在第二组分析结果中,可以看出排名1000的网页点击量约达到22000次,如图4所示。排名靠后却点击量巨大,这似乎不合常理,但是进一步分析,我们发现该类网页属于搜索引擎推广网页。该类网页的查询词均属于医疗,就业,培训等。在进行页面显示时,检索算法将这些排名较低的网页人为的显示到靠前页,从而获取商业价值。这说明在考虑搜索结果精确度的同时,商业搜索引擎会在一定程度上有目的地将一些排名低的网页显示在首页。平衡好推广网页和用户查询网页关系,才能更好地满足用户查询需求。
3.1.4 高级搜索比例
搜索引擎的高级搜索是通过限定查询范围,将关键词用逻辑连接词连接起来进行查询的一种方法。本文中,我们对搜索引擎用户高级搜索行为进行了分析,在约为2200万条查询中,使用site:、link:等关键词和+、-等逻辑连接词进行查询的记录数为约18万条,占总查询条数的0.84%。结果表明在使用搜索引擎时,国内查询用户更加喜欢简单的查询方式。所以,在高级搜索设计上,中文搜索引擎应该从国内用户的查询习惯和简便性出发,在提供准确查询的前提下,降低高级搜索的复杂度。
3.2 效率分析以及模型优化
结合hadoop分布式框架的特点和实验过程中发现的问题,可以从四个方面进行了模型优化:
(1)数据倾斜:使用Hive提供的通用负载均衡算法,优化模型整体性能。
(2)数据拷贝:Hive提供了combiner机制,可以使数据在map端部分聚合,相当于Mapreduce编程模型下的combiner层。
(3)Jion操作:单个日志文件小于1G,用map join语句代替join。map join操作在map阶段完成,不再需要reduce,节约了系统的开销。
(4)连接顺序:位于Join操作符左边的表会被加载进内存,将条目少的表放在左边,可以有效减少发生内存溢出错误的几率。
通过以上方法优化后,在不同数据集大小的条件下,分别测试伪分布式环境,以及分布式优环境化前后的运行时间,结果如图5所示。由实验结果可以看出在数据集较小的时候,分布式日志分析模型没有体现出优势。因为在分布式环境下,各数据节点之间的相互拷贝,I/O通信,消耗了大量时间,所以该模型不适合小文件处理。随着数据集的增大,分布式日志分析模型表现出了良好的性能,在经过上述优化操作后,系统运行时间减少,在数据集较大的情况下,系统优化效率最高能够达到6%。
4 结束语
用户查询日志分析是研究用户查询行为的前提和技术,本文设计和实现了基于hadoop的大规模用户查询日志分析模型,将分布式技术运用于大规模数据处理,解决了大规模数据分析的扩展性和并发性瓶颈。对检索算法、排序算法、缓存机制等方面的研究给出了建议,对于搜索引擎的优化有一定的指导意义。
[1] White T.Hadoop:The Definitive Guide[M].O'Reilly Media,Inc,2012:755-795.
[2] Ghemawat S,Gobioff H.The Google File System[C]. ACM Symposium on Operating Systems Principles, 2003.
[3] Thusoo,Sarma.Hive - a petabyte scale data warehouse usinghadoop[C].Long Beach,CA:International Conference on Data Engineering,2010:996-1005
马宪敏,女,1979.12-,山东省日照市,硕士,副教授,研究方向:软件工程。
Design of massive query log analysis model based hadoop
Ma Xianmin
(Heilongjiang international university,HeilongjiangHarbin,150025)
Log analysis has a very important significance for the field in the user search,the current log analysis system has a lot of disadvantages,such as:massive data cannot be processed,off-line processing mode,processing delay and other. the classification of log data archiving, in order to achieve big data classification optimization of growing demand.It puts on a large Hadoop log data based on the analysis model,and the business processing process and functional structure of the in-depth analysis,experimental results show the system expansion and strong, massive data processing ability of excellence,online processing,with good feasibility and effectiveness.
Hadoop;log processing;query;model design
