逻辑回归模型在互联网金融P2P业务信用风险的应用
2015-12-10徐喆
徐喆
(南京证券股份有限公司,江苏南京 210008)
逻辑回归模型在互联网金融P2P业务信用风险的应用
徐喆
(南京证券股份有限公司,江苏南京 210008)
随着互联网金融在我国蓬勃发展,个人借助互联网金融平台P2P展开的信贷业务也在不断地扩展。在极大地方便了客户,提高了互联网金融公司收入的同时,个人信贷违约事件也越来越引起互联网金融行业的重视。本文运用Logit和Probit模型,对个人信贷业务的违约风险相关因素进行量化分析研究。
互联网金融;个人信贷;Logit模型;Probit模型
信用风险是指借款人、证券发行人或交易对手因某些原因不愿或无力履行合同而构成违约,使银行、投资者或交易对手遭受损失的可能性。信用风险还包括由于履约能力的变化引起的损失的可能性。因此信用风险的大小主要取决于客户的财务状况和风险状况。
2010年后,互联网金融个人借贷P2P(Peer to Peer)业务平台初露锋芒。2012年后,互联网P2P业务进入全面爆发期,一年后,更是以每天1到2家业务平台的惊人速度发展。互联网金融极大地提高借贷人与收款人之间的资金对接率,部分解决了个人的投融资困难的问题,并推动了我国金融体制的改革。但是,P2P最难的地方就在信用风险控制。很多平台没有相应资质或者经验,审查材料不严,导致大量资信不良的个人成功借贷。有些还是大数额的贷款。这种情况导致平台累积了许多不良借贷,大量的贷款人逾期不能还款,贷款无法按时收回。再加上平台本身的资本不够雄厚,无法承受大量的逾期贷款,导致平台无法正常运行。
在借贷业务中,个人信用的不确定性包括外在不确定性和内在不确定性两种。外在不确定性来自于客户以外,是整体外在经济运行过程中随机性、偶然性的变化。内在不确定性来源于客户自身原因,它是由行为人主观决策及获取信息的不充分性等原因造成的,带有明显的个人特征。
一、相关文献综述
我国互联网金融相关机构企业急需对个人信贷的信用风险展开研究,特别是借贷人的违约可能性。本文采用了两种逻辑回归模型:Logit模型和Probit模型,对个人信用数据进行了量化实证分析;并对两种模型进行了比较。
用Logit模型解决借贷人的信用风险问题最早是由Wiginton在1980年提出,他认为该模型能够取得比判别分析分更好的效果。Steenackers和Govaerts在1989年对Logit模型做了后续的应用研究。在2004年,Cramer则对Logit模型的几个变种进行了研究。Logit模型的因为其前提假设少,稳定性高的优点而被广泛运用。Probit模型和Logit模型原理相似,最早由Grablowsky和Talley在1981年使用在信用风险评价模型里,他们得出了该模型比多元判别分析效果更好的结论。综合各个论文的结论来看,究竟是哪一种模型更好,学者们并没有得出统一的结论。主要的原因,一是实证的数据差异比较大,二是研究者们采用的模型结构参数有区别。
二、数据
本文数据由个人信贷数据库组成,一共2000个样本。分为因变量和自变量。
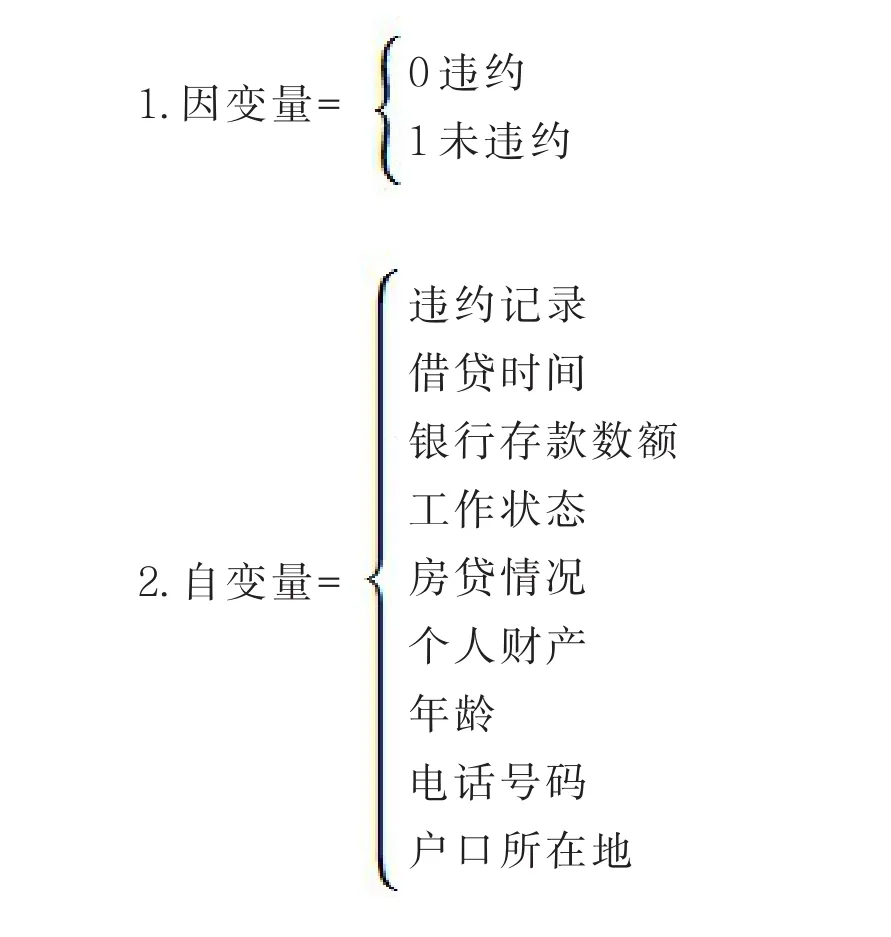
三、Profit模型和Logit模型
在因变量中,0代表客户违约,1代表客户没有违约。使用Logit和Probit模型进行估计,先建立如下由一个潜在变量方程和遵循逻辑分布的扰动项组成的模型:
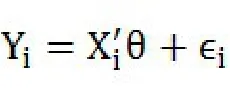
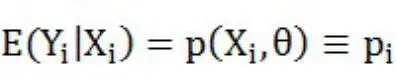
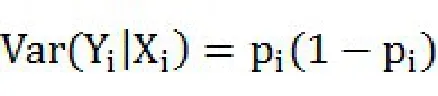
概率函数为:
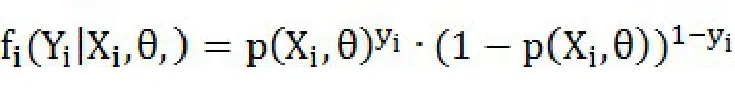
带入普通对数似然函数
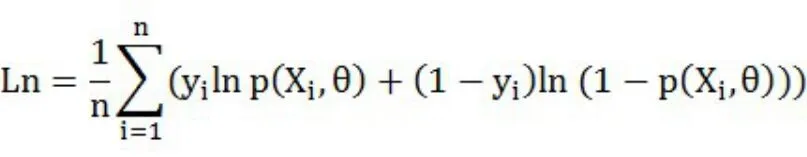
做关于的导数
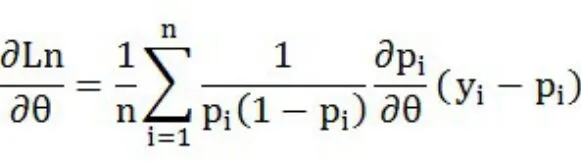
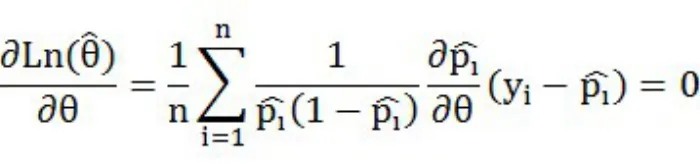
(一)Logit模型
Logit模型可以由一个潜在变量方程和遵循逻辑分布的扰动项组成:
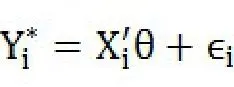
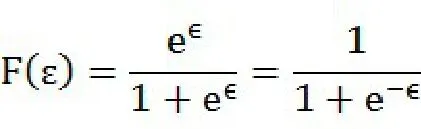
和密度函数:
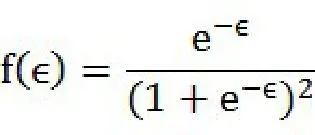
Kotz(1970b:Chapter 22)。
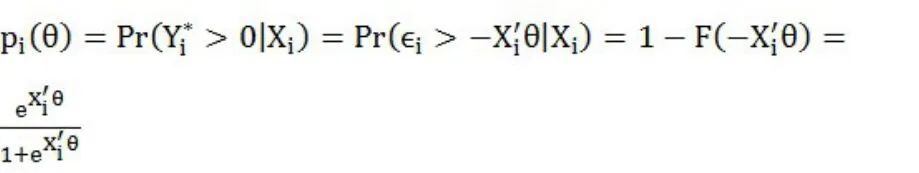
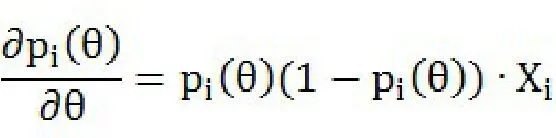
(二)Probit模型
和Logit模型相同,Probit模型可以由一个潜在变量方程和遵循逻辑分布的扰动项组成:
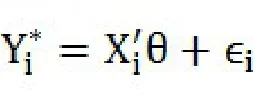
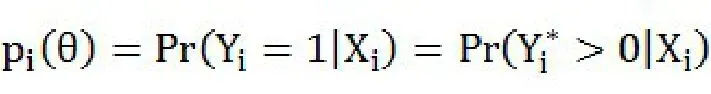
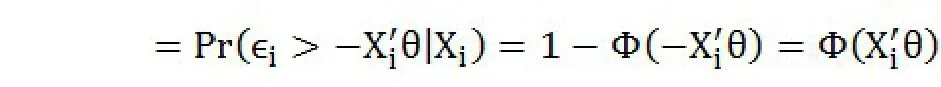
同Logit模型,得到下列等式:
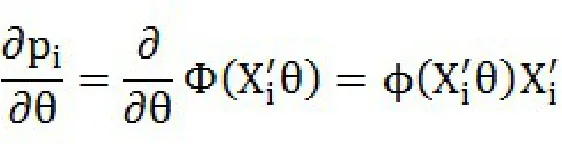
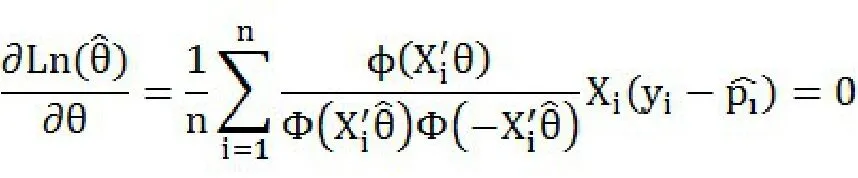
Logit模型和Probit模型之间最主要的差别在于对关于的假设,但Logit模型较Probit模型在个人信用评分领域的试用也要广泛得多,这是由于逻辑分布函数形式简单,计算方便。因为:
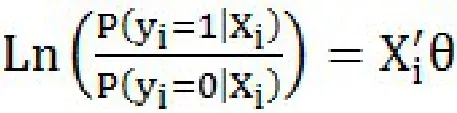
四、实证结果
使用Stata软件,我们得到如下结果:
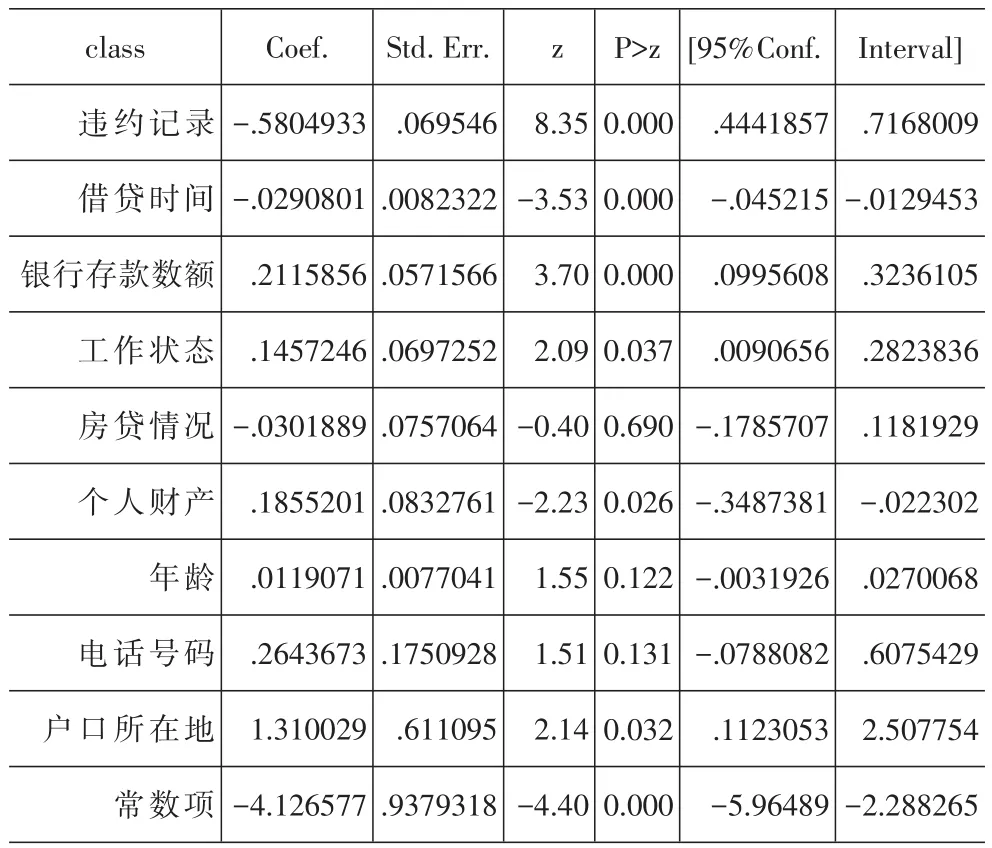
1.Logit模型
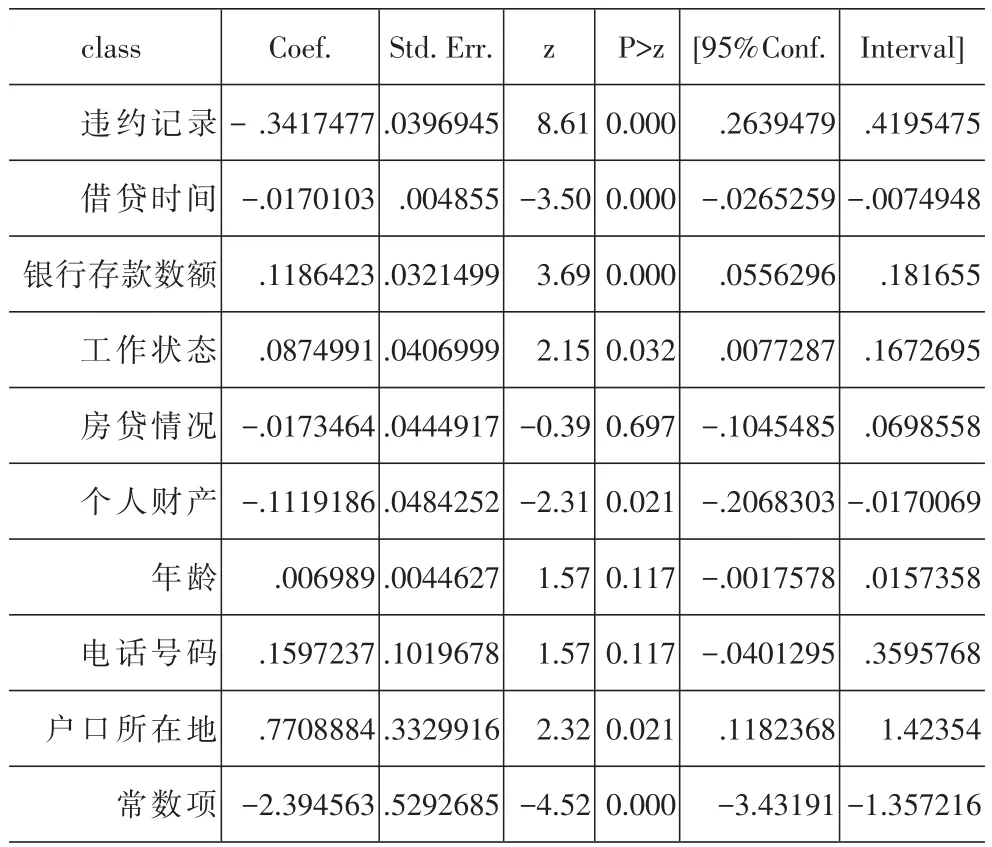
2.Probit模型
上述模型显示,无论是Logit模型还是Probit模型,两个模型里自变量与因变量之间的正负关系是一致的,只是两个模型的自变量系数的大小不同而已。其中正相关系数表示自变量越大,违约概率越小;负相关系数表示自变量越大,违约概率越大。下面逐一分析:
1.违约记录:之前没有违约历史记录的客户更加有信用,在之后违约的可能性也比较小。之前有过信用卡逾期未还款、股票融资被平仓后没有归还欠款的客户,违约记录越多的客户,以后违约的可能性也比较大。
2.借贷时间:借贷时间越长的客户,违约的概率越大。借贷时间越长,外在的经济环境和客户自身的资产负债情况的不可预知性越大,违约的概率也随之增加。
3.银行存款数额:银行存款数额的大小,一定程度上反映了客户的财务状况,较好的财务状况表明了更好的偿贷能力,违约的可能性更小。
4.工作状态:客户目前职业,收入对于客户的偿贷愿望都有着直接影响。如果一个客户有着良好的工作,稳定的收入,该客户的现金流更加容易预测,违约的几率也随之降低。
5.房贷情况:这个比较复杂,一方面较高的房贷对于客户来说是财政负担,偿还其他贷款的能力有所降低;另一方面,如果有足够的公积金偿还房贷,又恰恰证明了其较高的收入,能够负担起其余的债务。所以该自变量的P>|z|比较大,解释能力比较牵强。
6.个人财产:学区房、商业区等较高房价的住房可以作为借贷抵押。一般拥有这些住房的客户,资产较高,可以更好地承担债务。
7.年龄:年龄较小的客户消费欲望强烈,收入不稳定,积蓄不多,更有违约的风险。年龄较大的客户一般都有明确的消费计划,收入稳定,有着较为丰厚的积蓄,性格也比较稳重,个人违约的意愿也比较小。但是P>|z|较大,说明解释能力比较弱。
8.电话号码:联系方式对信用方式有正的方式。且与登记手机号码的客户相比,登记座机号码的客户更加稳定,但是可以这个变量的P>|z|较大,远远超过了0.05,也就是这个变量的解释能力较弱。
9.户口所在地:城市户口的客户一般收入较高,也比较稳定;农村户口的客户一般在城市打工或者在农村务农,收入无法得到切实的保障,遵守契约的意识也比较淡薄,违约可能性更大。
五、结论
Logit和Probit模型的稳健性好、可解释性强、建模过程相对简单、容易操作。两个模型都得到了相似的结论:客户的违约记录、借贷时间、银行存款数额、工作状态、个人财产、户口所在地这些变量对于客户的违约可能性有着较为显著的解释能力,而房贷情况、年龄、电话号码的解释能力较差。随着互联网金融深入到社会的各个角落,信用违约事件层出不穷,相关企业机构应该多加强对信用风险的研究,把风险保持在可以控制的范围以内。
[1]Wiginton,J.C.,A note on the comparison of logit and discriminant models of consumer credit behavior.Journal of Financial and Quantitative Analysis,1980.15:pp 757-770.
[2]A,S.,M.J Govaerts,A credit scoring model for personal loans.Insurance Mathematics and Economics,1989.98: pp.31-34.
[3]Cramer,J.S.,Scoring bank loans that may go wrong: a case study.Statistica Neerlandica,2004.58:pp365-380.
[4]Grablowsky,B.J.,W.K.Talley,Probit and discriminant functions for classifying credit applicants:a comparison. Journal of Economics and business,1981.33:pp.254-261.
[5.]向晖.个人信用频分组合模型研究与应用.经济科学出版社,2012.
(责任编辑:高萍萍)
