基于空间密度聚类的移动用户热点区域识别方法
2015-12-09杜翠凤余艺蒋超
杜翠凤,余艺,蒋超
(广州杰赛科技股份有限公司,广东 广州 510310)
基于空间密度聚类的移动用户热点区域识别方法
杜翠凤,余艺,蒋超
(广州杰赛科技股份有限公司,广东 广州 510310)
识别移动用户热点区域是为了解决用户在不同地理位置对业务的不同需求,以此作为移动运营商规划设计的重要依据。为此,将基于大量用户的移动信令数据,通过空间密度聚类的方法(DBSCAN)来识别用户的热点区域。实验证明,通过DBSCAN方法来识别热点区域比传统方法更准确高效。
DBSCAN移动用户热点区域识别
1 引言
当前针对用户轨迹进行聚类的研究主要有:文献[2]提出对轨迹点进行空间密度的聚类,但是该方法由于没有对轨迹的噪音进行预处理,而且只通过K近邻的算法对数据进行聚类,因此聚类结果的区分度不够高,在现实中无法有效应用;文献[3]将轨迹点转化为线段序列,通过对线段序列进行聚类来挖掘热点路径,但是该方法由于只适用于GPS数据,因此对手机采集的信令数据并不适用;文献[4]通过将序列转换成网格序列,然后基于网格进行聚类发现热点区域。由于基于手机信令的用户轨迹点数量庞大,且分布的区域分散,传统的轨迹聚类方法已经不能满足热点挖掘的要求,因此研究基于密度的空间聚类轨迹挖掘算法必然成为当今的需求。基于此,本文提出了DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法),通过先找出用户停留的聚类热点,然后再找出聚类热点的边界来确定热点区域的边界。实践证明,基于该算法在处理海量数据的时间效率和热点区域识别的准确率上都有很好的效果。
2 基于用户信令数据进行定位
2.1手机信令数据“噪音”预处理
由于现实生活中用户发生业务时受到外界因素的干扰,因此信令数据中夹杂了大量的“噪音”,包括:重复定位、虚假切换信息、兵乓效应、记忆效应、孤岛效应等。这些“噪音”会对热点区域识别产生较大的干扰和误差,因此本文通过大数据相关工具对手机信令的“噪音”进行剔除。
2.2基于3D射线模型与KNN模型的用户定位
定位方法的主要思想是:第一,把整个地市划分为100×100m的网格;第二,通过3D射线追踪模型得到建立每个网格的定位指纹库,包括覆盖范围内手机接收到的服务基站信息(含基站和信号平均值);第三,根据实时采集的小区信号强度与定位指纹库进行相似度计算,求出最大相似度所在网格,以该网格作为用户的位置。
3 基于DBSCAN算法的热点识别方法
3.1DBSCAN算法
DBSCAN是一种基于密度的空间聚类算法。该算法将具有足够密度的区域划分为簇,并在具有噪声的空间数据库中发现任意形状的簇,它将簇定义为密度相连的点的最大集合。
该算法利用基于密度的聚类的概念,即要求聚类空间中的一定区域内所包含对象(点或其他空间对象)的数目不小于某一给定阈值。DBSCAN算法的显著优点是聚类速度快且能够有效处理噪声点和发现任意形状的空间聚类。
3.2基于DBSCAN算法的热点提取过程
(1)网格的局部密度
按照上述方式进行用户定位,该定位精度是100×100m的网格。假设待聚类网格的数据集为S={xi}(i=1,…,N),Is={1,2,…,N}为指标集,dij=dist(xi,xj)表示网格xi和xj之间的距离(网格的距离表示两个网格中心点之间的距离)。对于网格数据集中任何网格xi,可以定义局部密度距离ρi和δi。下面定义ρi和δi的含义为:

其中,ρi表示网格数据集S中与网格xi之间的距离小于dc的网格的个数。与网格xi的距离小于dc的网格数量越多,ρi的值就越大。
(2)网格局部密度选取的距离
参数dc的确定直接影响网格热点的确定,如果dc取值太大,将会导致每个聚类热点的ρ值都很大,从而导致网格热点区分度不高;如果取值太小,则聚类数量太多,没办法看到明显的聚类热点。从经验来看,选取一个dc使每个网格包含的相邻网格个数为总数的1%~2%所形成的聚类热点最佳。
在计算每个网格热点所包含的距离δi之前,先对每个网格所形成的ρi值进行排序;然后再计算每个网格的距离δi值(网格的距离是指两个网格的中心点之间的距离)。距离δi是指某个网格所形成局部密度ρi时,当网格xi具有最大局部密度时,表示S中与网格xi距离最大的网格和网格xi之间的距离;否则,δi表示在所有局部密度大于网格xi的网格中,与网格xi距离最小的那个网格和网格xi之间的距离。

(3)网格热点的确定
文献[5]提到的确定网格的聚类中心的方法:计算ρ和δ的综合值,以作为确定聚类中心个数的参考值。

很显然,该网格的γ值越大,那么该网格越有可能形成一个聚类中心,因此只需要对γ值进行降序,并把γ值进行数值检测。通过检测,作为聚类中心的网格前后两个γ值差异性较大,因此斜率也较大;非聚类中心的网格的γ值差异性小,因此通过判断一个“拐点值”就能把聚类中心识别出来,从最大的γ值到“拐点值”都形成网格的聚类中心,那么网格的热点以及聚类数量就确定。
3.3基于DBSCAB算法的热点区域边界确定
待聚类网格的数据集为S={xi}(i=1,…,N),设上述确定的聚类数量nc个聚类数目;{mj}(j=1,2,…,nc)为各个网格的热点对应的编号;{ni}(i=1,2,…,N)表示网格S中所有局部密度(排序意义下)比xi大的网格与xi距离最近的网格编号。
从上文可知,网格的热点已经形成,下一步就需要把非热点的网格作归类,具体步骤如下:
(1)按照ρ值从大到小进行遍历;
(2)通过ρ来获取每个热点所包含的网格编号{ni};
(3)确定每个聚类热点区域的边界。
4 实验结果
4.1数据来源
本文采用保定某运营商提供A接口、IuCS接口2014年8月16日的信令数据,该信令数据大小为150G,包含200多万用户发生业务切换及位置更新的相关信息,其中A接口数据约5.4亿条,IuCS接口数据约3.6亿条。
4.2实用性分析
本系统基于Hadoop平台进行后台数据处理和分析,采用SSH框架体系,以每半小时为颗粒度来展现某运营商保定热点区域分布情况。如图1所示,展现了2014年8月16日早高峰的保定市区热点区域分布情况,该分布符合该运营商的话务量热点分布区域特征。

图1 用户热点区域分布情况
4.3效率分析
由于DBSCAN算法先识别聚类热点再确定边界的思想,因此相比传统算法更高效。本实验选取了一些比较完整的用户信令进行试验,分别是1万、5万、10万用户,对用户的信令数据用传统的K-近邻算法和DBSCAN算法进行比较,得出的时 间消耗如图2所示:
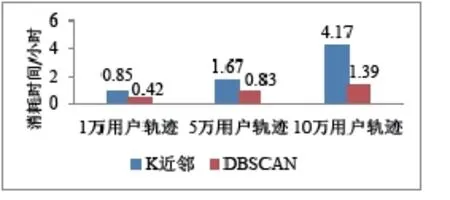
图2 算法消耗时间分析对比
从图2可以看出,随着用户数据量越大,该算法的效率优势就越明显。
5 结束语
基于手机信令的用户热点区域识别具有投资小、数据采集覆盖范围广、实时性好的特点,应该强化其在通信规划领域的运用。由于通信用户行为的不稳定性和复杂性等特点,基于手机信令的用户热点区域识别只能反映大部分用户出行的规律;其次,基于网格的DBSCAN热点提取的精度相比于GPS来说有一定的局限性。在未来的研究中,还需要针对这两方面存在的缺陷进行更进一步研究。
[1] 桂智明,向宇,李玉鉴. 基于出租车轨迹的并行城市热点区域发现[J]. 华中科技大学学报, 2012(40): 187-188.
[2] Yang Yue, Zhang Yan, Li Qingquan, et al. Mining timedependent attractive areas and movement patterns from taxi trajectory data[A]. Proc of Geo Informatics[C]. Fairfax: IEEE Press, 2009: 1-6.
[3] Lee Jae-Gil, Han Jiawei. Trajectory clustering: apartitionand-group framework[A]. Proc of SIGMOD[C]. New York: ACM Press, 2007: 593-604.
[4] Pang L X, Chawla S, Liu Wei, et al. On mining in road traffic streams[A]. Proc of ADMA[C]. Berlin: Springer Press, 2011: 237-251.
[5] Alex Rodriguez, Alessandro Laio. Clustering by fast search and fi nd of density peaks[J]. Science, 2014(344): 1492.
[6] Rakesh A, Johanners G, Dimitrios G, Prabhakar R. Automatic subspace clustering of high dimensional data for data mining applications[A]. Proc. of the 1994 ACM SIGMOD[C]. Snodgrass RT: ACM Press, 1994: 94-105.
[7] Hans-Peter Kriegel, Peer Kroger, Alexey Pryakhin, et al. Effective and efficient distributed model-based clustering[A]. Proc. of 5th IEEE International Conference on Data Mining[C]. Houston: IEEE Press, 2005: 8-19.
[8] Maria Halkidi, Michalis Vazirgiannis. Clustering validity assessment: Finding the optimal partitioning of a data set[A]. Proc. of Intel Conf. Data Mining[C]. California: IEEE Press, 2001: 95-102.
[9] 熊忠阳,孙思,张玉芳,等. 一种基于划分的不同参数值的DBSCAN算法[J]. 计算机工程与设计, 2005,26(9): 2319-2321.
[10] 杨静. 分层模糊最小—最大聚类算法及其在图像聚类中的应用研究[D]. 合肥: 合肥工业大学, 2007.
[11] 许慧. 基于数据分区和QR*树的并行DBSCAN算法研究[D]. 哈尔滨: 哈尔滨工程大学, 2007.★

杜翠凤:硕士毕业于广东外语外贸大学,现任广州杰赛科技股份有限公司通信规划设计院研发中心大数据项目组项目经理,擅长数据挖掘工具的应用,主要从事用户行为分析、用户轨迹分析工作。

余艺:硕士毕业于南京邮电大学,现任广州杰赛科技股份有限公司通信规划设计院研发中心大数据项目组研发工程师,擅长无线定位、用户感知分析、关联分析等方面的算法研究。

蒋超:硕士毕业于吉林大学,现任广州杰赛科技股份有限公司通信规划设计院研发中心大数据项目组研发工程师,擅长大数据分布式数据处理、数据处理平台开发、数据库建模。
Mobile User Hotspot Recognition Method Based on Space Density Clustering
DU Cui-feng, YU Yi, JIANG Chao
(GCI Science & Technology Co., Ltd., Guangzhou 510310, China)
Mobile user hot spot identification can solve different demands of users in different geographic locations and provide an important reference to telecom operators’planning and designing. The method based on mobile user space density clustering (DBSCAN) was used to identify hotspot area according to large amounts of mobile signaling data. Experiments demonstrate that, compared with traditional algorithms, DBSCAN algorithm is more accurate and effi cient to identify hotspot area.
DBSCANmobile userhot spot identifi cation
10.3969/j.issn.1006-1010.2015.16.008
TP391.4
A
1006-1010(2015)16-0040-04
2015-08-13
责任编辑:袁婷yuanting@mbcom.cn
引用格式:杜翠凤,余艺,蒋超. 基于空间密度聚类的移动用户热点区域识别方法[J]. 移动通信, 2015,39(16): 40-43.
