基于Hadoop的海量气象雷达小文件存储研究
2015-12-02杨芙容王永丽王文明
杨芙容, 王永丽, 王文明
(成都信息工程大学信息安全工程学院,四川成都610225)
0 引言
近年,气象现代化业务飞速发展,为广大用户提供更加全面、更加精细化的气象服务,其中,气象雷达近年呈高速发展的态势,受到世界多数国家和国际气象组织的高度重视[1]。尤其是多普勒天气雷达技术日益普遍的使用,获得了更多的探测数据信息,提高了天气的监测能力,对预报强对流天气等具有非常重要意义。同时,气象现代化造成气象数据的成倍增长,对系统的存储和处理能力提出很高的要求。
传统的关系型数据库系统在存储和管理数据上出现负载饱满读写性能不理想等问题[2],迫切需要新的海量数据处理方案,在众多的海量数据处理平台中,Apache Hadoop[3]已经迅速成为存储和处理海量数据的首选平台之一。国际上著名的互联网门户网站雅虎、社交网络服务网站Face Book,以及国内淘宝、百度等众多知名的IT企业,先后采用Hadoop开发出适合自己的数据管理平台。Hadoop具有吞吐量大、效率高、容错性高、可靠性高、成本低等优点,能够扩展到云环境,适用于气象雷达这种有多种处理需求的应用场景。
1 Hadoop核心组成
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,核心组件包括 HDFS、Map Reduce、HBase等[4],HDFS形成Hadoop的文件分布式系统;HBase是一个面向列的分布式数据库,可靠性高、可伸缩、提供实时读写;Map Reduce是Hadoop的数据处理模块,能对存储在HDFS和HBase中的大规模数据进行高效的分布式并行处理。
HDFS采用主从式架构设计模式(master/slaver structure),一个名称节点(Name Node)和若干数据节点(Data Node)构成HDFS集群。Name Node是 HDFS中的管理者,负责存储和管理文件系统的命名空间(name space),文件目录的元数据,集群配置(cluster configuration)和存储块的复制情况等信息。Name space是一个分层结构的文件和目录,记录权限,修改和访问时间,命名空间和磁盘空间配额等属性。DataNode是HDFS的基本组成部分,提高文件数据的存储服务。它将文件以分块形式存储到本地文件系统,并周期性地将所存块的信息发送给Name Node。
HBase的设计源于Big Table的启发,在HDFS上开发的一个分布式数据库。数据集,主要存储处理大规模的非结构化和半结构化的数据。Hbase使用LSM树型结构,将需要修改的数据直接写入内存。操作数据时直接定位到相应的HRegion server,在region上找到匹配的数据,而且引入高速缓存,使HBase能提供实时计算服务。
2 小文件问题
把海量小文件(小于16MB的文件)直接存储在HDFS上存在的问题简称为小文件问题[5]。为节省内存空间和提高传输效率,气象雷达文件在存储和使用前通常先做压缩处理,压缩后文件大小在几KB到几百KB之间,属于小文件范畴,这就可能引发小文件问题。
(1)Name Node内存溢出
Name Node直接把文件系统的元数据存储在主存中,通常一个文件的元数据占250bytes内存,每个块的3个复制文件的元数据占368bytes[6],文件数目越大,占用的Name Node内存空间也成倍数增加。此外,DataNodes定时向Name Node发送块报告信息,Name Node收集这些信息,作为块映射信息存储在内存中。当文件数目很大时,这部分信息所占内存不容忽视。由式(1)可以看出减少Name Node内存占用的主要方法是减少Name Node管理的文件个数和块数目。
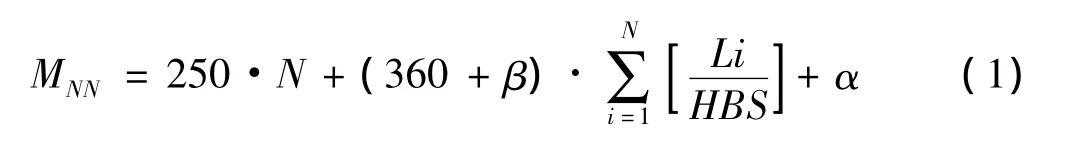
其中M是Name Node的内存占用,N文件数,β代表块的映射信息,HBS是设定的块大小,默认取整为64 M,Li是每个小文件的大小表示比值向上取整,a为Name Node所占内存,这部分内存很小。
(2)访问延迟高
当读取大量的小文件出现高访问延迟主要有3个原因:首先,HDFS客户端每操作一个文件都需要访问一次Name Node元数据,引发元数据服务器的频繁相互作用的延迟。如640 MB的大文件(10个64 MB文件)I/O吞吐量,HDFS客户端只需要访问Name Node 5次,而在相同大小下(如10240个64 KB文件),客户需要访问Name Node 5120次,这种延迟很明显。其次,HDFS失去块间关系。HDFS有自己的放置策略,可以在可扩展性、读效率、写带宽之间达到很好的平衡。但没有考虑文件的连续性,连续文件不一定连续放置,甚至可能被放在不同的块中[7]。再者,HDFS目前没有提供预取函数降低I/O延迟,没有为数据的放置和预取机制考虑文件的相关性,从HDFS中读取小文件时,通常需要多次查找和在Data Node和Data Node之间反复来回跳转。
(3)Map任务过多
在HDFS中文件按块存储,文件不满64 MB(Block默认64 MB)也占用一个Block。Map任务通常一次处理一个块输入,这样Block数目越多,Map任务越多,而实际上,每个map只处理很少的数据量,这就造成额外的簿记开销,大量时间浪费在任务启动和结束上。如处理1 GB的一个大文件需要16个64 MB的块,而处理1 GB的1万个左右100 KB的小文件需要1万个64 MB的块。这1万个小文件的map效率要比大文件map效率低几十到几百倍。
3 优化方案设计
目前,基于HDFS的海量小文件存储和访问效率问题的解决方法主要分为3类。
(1)利用Hadoop自身提供的方法合并小文件,如hadoop 归档[8](Hadoop archive,HAR)、Sequence File[9]等,但这些方法存在很多问题,最突出的是访问效率低下。
(2)针对具体的应用提出对应的文件合并、组合方法,通常在HDFS上添加一个小文件处理模块[10],由处理模块完成数据的合并、更新、删除、缓存等操作:Xuhui Liu等[11]将地理位置信息相邻的多个小文件合并成一个大文件,为检索到小文件的位置,为其建立一个全局的位置索引,减少Name Node的内存占用。但是当小文件数据量非常大时,全局的位置索引文件就变得十分庞大,每次定位一条数据耗费大量时间,文件的检索速率低;Bo Dong等[12]提出将同一个课程 PPT的多个图片小文件合并成大文件,在Data Node上为每个文件建立一个本地的单独索引查询方法,分担Name Node的查询负担。但合并文件超过默认块大小时,该方法比较复杂,需要人为干预小文件的合并和建立索引操作。
(3)改进系统的架构。文献[13]提出一种增强型的HDFS,扩展单一的Name Node成分层Name Node的架构,同时扩展的HDFS架构中集成高速缓存,提高文件的读取效率。刘小俊等[14]提出将 RDBMS和 Hadoop结合,前端RDBMS作为小文件访问入口和合并工具,后端Hadoop存储和处理海量数据,发挥各自的优势。但总的来说,改进架构非常复杂,成本高而且较难实现。
3.1 基本思想
多普勒天气雷达通常每几分钟(6 min)完成一个体扫,每个体扫文件里包含N·(Z、V、W)一次产品文件、一个VOL和根据需要设定的多个二次产品文件,其中N表示每次抬高的仰角层数,一天24小时不间断采集雷达数据。
为节省磁盘空间和网络带宽,把每个体扫的产品文件采用压缩方式存储。针对气象雷达数据的特征,压缩后将文件格式命名为:年月日_时分秒.扫描层号.产品Type.扫描模式.产品参数20141214-125233.00.004.000-0.47.zdb,表示20141214.12:52:33.表示:第0层.v产品.000扫描式.0.47产品参数(仰角)的一个V产品文件。

表1 压缩文件命名格式
压缩后体扫文件大小在几KB到几百KB之间,其中一次产品文件压缩后文件大小为通常几到几十KB,这部分数据对系统的数据处理实时性要求比较高,在存储时选择HBase。HBase基于HDFS之上,可以将操作分散到多个节点上并行处理,执行效率很高,能够提供实时计算服务。其他的VOL文件和二次产品文件通常对系统的实时性要求不高,是由一次产品文件根据需要计算整合。对于这些文件采用Sequence File合并技术,以VOL文件和二次产品文件的文件名为key、文件内容为value的形式进行合并,减少元数据的内存占用量,节省Name Node的内存空间。全文存储系统架构模型如图1所示。
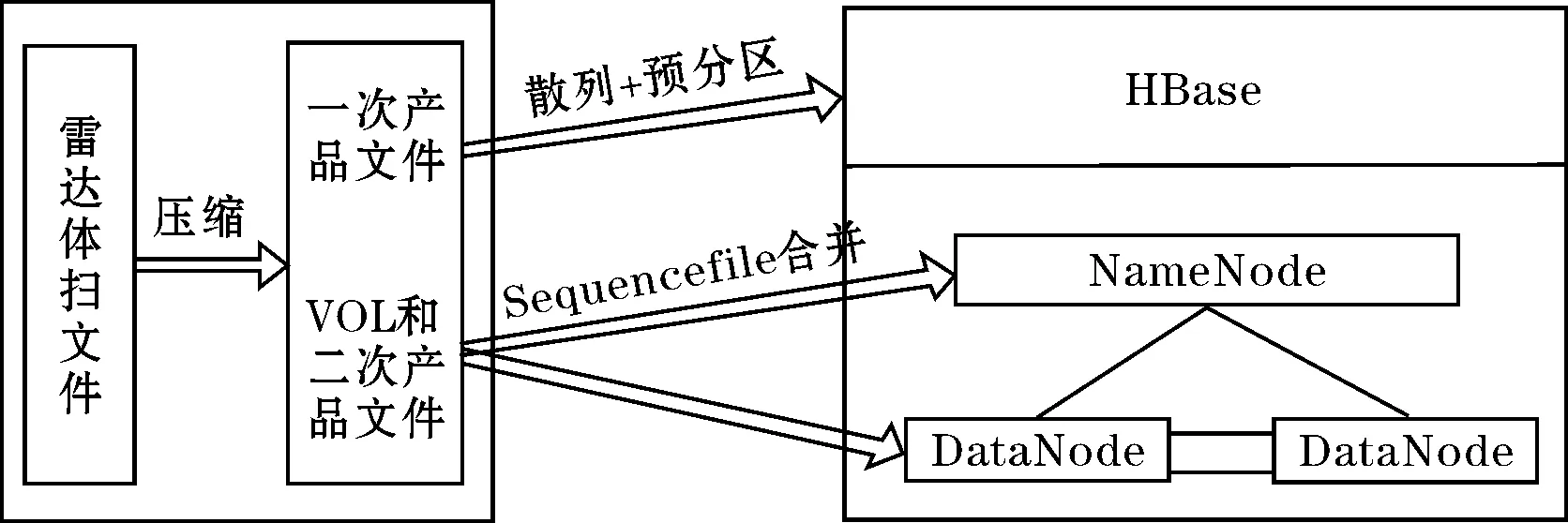
图1 存储系统架构模型
3.2 一次产品文件的存储
HBase无模式无类型,由行和列组成。行和列的坐标交叉决定表格单元格(cell)。cell的内容是未解释的字符数组。HBase具有很好的可伸缩性,表可以数十亿个数据行“高”;表可以很“宽”(数百万个列)。表的模式直接反映存储形式,可以提供高效的数据结构的序列化、存储和检索。HBase处理几十KB的小文件时,查询效率很高[15],把ZVW一次产品文件直接存储在HBase中有利于提高文件的读取效率。
HBase行键设计:HBase通过行键(row key)、列族(Column Family)、列和版本4个维度定位某条数据,它不能像传统数据库一样支持where等条件查询,只能全盘扫面或按row key检索数据。HBase存储模型设计时,首先需要根据业务设计行键,检索记录的主键,可以利用其存储排序特性提高性能。
在天气雷达业务中,雷达产品文件一般以时间和产品参数作为标识,这两个维度也是常用的检索条件,因此设计时间+产品参数的行键设计方案。为能将region server的负载均衡,防止出现所有新数据都在一个region server上堆积的现象,设计row key时采用随机散列与预分区二者相结合的方法。预分区开始就预建好一部分region,这些region都维护着自已的star tend keys,由MD5方式生成随机字符串,写数据能均等地命中这些预建的region,解决写热点问题,大大地提高性能。
HBase列族设计。HBase表中列族需要提前定义,是表chema的重要组成部分。不同列族的数据是存储在不同的HFile中,所以一般把同时访问的数据放在一个列族中,而在气象雷达应用中,因为业务需要访问全要素,所以把同一类型的数据都放置在一个列族中;以首字母和产品参数作为列族和列的标识符。例如列FP∶Z、FP∶V都属于FP(First Product)这个列族。
3.3 VOL文件和二次产品文件的存储
由于VOL文件和二次产品文件的存储和访问对系统的实时性要求不高,而且经过压缩后的VOL文件和二次产品文件大小通常为几十到几百KB,采用Hadoop提供的应用程序编程接口 API:Sequence File[16],主要由一个Header后跟多条Record组成。Header主要包含版本、Key、value类名、压缩方式判断、自定义信息和同步标识等,同步标识用于快速定位到记录的边界。每条Record以键值对的方式进行存储,表示字符数组。
Sequence File根据压缩与否有3种存储形式,Value压缩、block压缩和不压缩存储,通过Sequence File类的内部类Compression Type表示。采用不压缩方式存储 io.seqfile.compression.type=NONE。
Sequence File通过创建Sequence File.Write实现写入,然后调用writer.append(key,value)打包记录。它就像为存储提供一个容器,将多个小文件打包统一存储。在存储气象雷达数据时,采用Sequence File技术将文件进行合并处理,将VOL和二次产品文件的文件名作为key,文件的内容作为value序列化合并成一个大文件,合并后的文件元数据信息存储在Name Node中,节省Name Node的内存空间。
4 实验测试
4.1 测试环境
测试使用4台服务器构建集群,其中1台作为主服务器 master,3 台从节点 node1、node2、node3;服务器配置Intel(R)Core(TM)2 Quad CPU Q8200@2.33 GHz 2.34 CHz,内存4GB硬盘500GB,操作系统 Red Hat Enterprise Linux Sever release 6.5,Hadoop版本是1.2.3,HDFS副本数dfs.replication设置为3,HDFS最小块设置为默认值64 MB,Second Name node配置在node1上。HBase版本是0.94.1,使用HBase自带的zookeeper。
4.2 实现方法
实验测试中数据是某台多普勒气象雷达2014年6月观察的数据,701134条记录,压缩后总大小为11.2 GB,每条记录都在1~500 KB,其中一次产品文件压缩文件大都小于100 KB。
Name Node的内存受限问题一直是制约其对海量小文件存储的关键因素,因此减少Name Node的内存占用具有重要意义。HDFS设计建立在更多地响应“一次写入,多次读出”任务的基础之上,因此提高文件的读取速率也至关重要。故从Name Node的内存占用和文件读取时间两个方面进行测试和评估方案。这里把提出的方法和直接存储HDFS方案进行比较。
4.3 实验结果
Name Node内存占用(MB/文件个数)

图3 Name Node内存占用
图3表示2种方案对不同数量的文件存储时,Name Node内存使用情况,文件数量由0、5000、10 000依次递增至25 000。绿色线表明在对小文件不做任何处理直接存储时,随着小文件数目的增加,内存占用量呈现线性增长趋势。采用将VOL文件和二次产品Sequence File合并技术打包存储极大地减少元数据的内存占用,同时一次产品文件是存储在HBase上的,节省了Name Node的内存空间。
读操作(s/文件个数)

图4 读取时间
由于气象数据在存储和调用时多数时间操作时间连续的那些文件,所以分别测试时间连续的50 000~250 000个文件。而在存储方案中把一次产品和其他产品文件采用两种不同的方式存储,在测试读取时间时需要分别讨论。分别将HBase和sequence File访问时间与直接HDFS读取时间比较。测试结果表明,HBase对一次产品文件的响应时间远小于直接从HDFS读取气象文件的时间。而对气象雷达数据的操作频繁牵涉到对一次产品文件的访问,HBase提供实时操作服务,极大地提升文件的访问速率,节省了文件的读取时间。
5 结束语
针对气象雷达数据的特征,先把每个产品文件采用压缩方式存储,压缩后每个产品文件大小为几KB到几百KB,节省了Data Node的内存空间。由于每个体扫中的一次产品文件对数据处理的实时性要求比较高,针对这些特殊原因,在存储时选择HBase,它提供实时计算,处理速度非常快。采用时间+产品参数的行主键设计方案,利用随机散列与预分区保证负载均衡,最终提高一次产品文件的读取效率。
此外,一个体扫周期除了生成ZVW一次产品文件,还生成一个VOL文件和根据需要计算生成多个二次产品,对系统的实时性要求不高,而且大小通常为几十到几百KB。对于这些文件直接存储在HBase上加重其负担,同时HBase更适合处理几十KB的文件,文件过大降低其处理速度,所以利用Hadoop自身提供的Sequence File技术先小文件合并为大文件,Name Node中只需要存储合并后的文件元数据,节省Name Node的内存空间。
HBase不支持辅助索引,但在气象数据检索时效性上仍需要使用辅助索引[17],在接下来的工作中,将考虑设计适合气象数据的辅助索引模块;同时对 Sequence File中的VOL和二次产品文件设计索引和查找算法,以提高其查找速度。
[1] 伍志方,曾沁,易爱民,等.短时大暴雨的多普勒雷达探测及暴雨预警信号发布[J].灾害学,2006,21(2):59-63.
[2] 陈东辉,曾乐,梁中军,等.基于HBase的气象地面分钟数据分布式存储系统[J].计算机应用,2014,34(9):2617-2621.
[3] Shvachko K,Kuang H,Radia S,et al.The Hadoop Distributed File System[C].In:IEEE 26th symposium on mass storage systems and technologies(MSST).IEEE;2010:1-10.
[4] Jilan Chen,Dan Wang,Lihua Fu,et al.An Improved Small File Processing Method for HDFS[C].International Journal of Digital Content Technology and its Applications(JDCTA).2012,(6):200-205.
[5] Tom White.The Smal Files Problem[EB/OL].Http://www.clouder.com/blog/2009/02/02/the small files problem/.
[6] Tom White.The Smal Files Problem[EB/OL].Http://issues.apache.org/jira/browse/Hadoop-1687.
[7] Bo Dong,QinghuaZheng,FengTian,et al.An optimized approach for storing and accessing small files on cloud storage[C].elsevier.2012,(6):1847-1862.
[8] Chatuporn,Vorapongkitipun,Natamut,Nupairoj.Improving Performance of Small File Aceessing[C].International Joint Conference on Computer Science and Software Engineering(JCSSE)2014(11):200-205.
[9] 赵晓勇,杨扬,孙莉莉,等.基于Hadoop的海量MP3文件存储架构[J].计算机应用,2012,6(1):1724-1726.
[10] K P Jayakar,Y B Gurav.Managing Small Size Files through Indexing in Extended Hadoop File System[C].International Journal of Advance Research in Computer Science and Management Studies.2014,8(8):161-167.
[11] Liu X,Han J,Zhong Y,et al.Implementing webgis on hadoop:a case study of improving small file i/o performance on hdfs.[C]In:IEEE international conference on cluster computing and workshops,2009,12,(1):1-4.
[12] BoDong,Qiu Jie,Qinghua Zheng,et al.A novel approach to improving the efficiency of storing and accessing small files on hadoop:a case study by Power Point files[C].Proceedings of the 7th Int ernational Conference on Services Computing.Piscataw ay,N J,USA:IEEE,2010:65-72.
[13] Xiayu Hua,Hao Wu,Zheng Li,et al.Enhancing throughput of the Hadoop Distributed File System for interaction-intensive tasks[C].2014:2770-2779.
[14] 余思,桂小林,黄汝维,等.一种提高云存储中小文件存储效率的方案[J].西安大学报,2011,45(6):60-63.
[15] Ganggang Zhang,Min Zuo,Xinliang Liu,et al.Improving the efficiency of storing SNS small files in HDFS[C].CCIS 426.2014:154-160.
[16] 薛胜军,删寅.基于Hadoop的气象信息数据仓库建立与测试.计算机测量与控制[J].2012,20(4):926-928.
[17] Chen P,AN J.The key as dictionary compression method of inverted index table under the HBase database[J].Journal of Software,2013,8(5):1086-1093.
