基于教育技术领域的网络信息采集系统设计
2015-11-16赵磊磊杨永
赵磊磊 杨永

摘 要:为了应对网络大数据的挑战,本文通过对教育技术网站的页面布局和网页源码的分析,结合正则表达式和网页解析开源类库的使用,实现了网络信息的准确匹配提取和人本化信息采集,在一定程度上有利于有效获取教育技术最新新闻动态,从而有助于提高机构和个人的业务决策能力。
关键词:教育技术;信息采集;正则表达式;网页解析
中图分类号:G434 文献标志码:A 文章编号:1673-8454(2014)19-0087-03
一、引言
网络信息采集是指将非结构化的网页信息抽取出来并能实现结构化数据库保存的过程。[1]在搜索引擎的开发过程中,网页信息的采集、解析和抽取都是至关重要的技术步骤,由于网页的结构具有多样性、复杂性,当前一般选用基于模板的网页信息解析技术。[2]数据挖掘对实现教育技术大数据的有效处理和利用起着非常关键的作用,面向教育技术新闻的网络信息采集系统将会为教育技术理念的同步、更新、科学研究等方面提供方便有效的即时检索,能为用户的网络自主学习带来极大的便利。在数据挖掘技术的应用基础下,网络信息采集系统的主要功能包括网页源信息采集、信息分析、数据库保存、自动化分类整理以及动态监测信息采集内容等。[3][4]
很多教育技术新闻网站所包含的信息较为繁杂,甚至包含很多冗余的广告信息、因此在利用这些权威教育技术网站进行信息技术知识的学习或相关教育新理念的学习时,会受到一定程度上的困扰。在日益更新的教育技术网络信息面前,如何有效利用知识信息,更为全面地、及时地掌握信息的动态,了解信息技术和新的教育技术理念的发展动态,不仅对于促进学科教师的学习具有重大价值意义,而且对于教育技术的持续发展具有一定的推动作用。文章所设计的面向教育技术新闻的网络信息采集系统旨在给用户提供一个有力的工具对所选教育技术的权威网站进行深度挖掘,及时把握教育技术新动态,更为直观、快捷地保存自己想要的信息。这对教育技术领域的工作者、学习者和爱好者来说,新知识的获得变得更具有时效性和价值性,节约了用户的时间,在一定程度上促进了学习效率的提高。
二、信息采集系统相关技术
1.获取网页编码
通过编码类型来从网页中获取准确内容,有利于更迅速、有效地使用搜索引擎采集我们需要的信息。信息或字符按照一定的规则在计算机内存中存储,编码的过程实际上就是将字符转换成字节流,而解码的过程就是将字节流解析为字符。在网页编码获取过程中,首先使用GB2312(系统默认的编码类型)从数据流中得到源码,然后利用正则表达式从网页源码中匹配并获取相应的字符编码,一般来说,网页的HTML头文件中都会给出指示C:\Users\zhao\Desktop\检测\htmls\sentence_ detail\33.htmcharset值的一行代码,从这一行代码里可以获取编码信息,再与系统默认编码作对比判断是否一致,如果不同,将再次从数据流里重新获得网页源码。
2.正则表达式过滤信息
正则表达式是指用来表征或匹配一系列契合某个指定规则的字符串的单个字符串。[5]我们通常在Windows操作环境下利用通配符(*和?)进行文件搜寻,例如使用*.Doc来查找某个指定目录下的所有的Word文档。在这里,*会被解释为任意的字符串。与通配符的作用类似,正则表达式也是实现文本匹配的一种有效工具,只不过与通配符的作用相比,它能更精确地描述和表征使用者的需求。在网络信息采集系统中,正则表达式主要有以下两方面的功能:
(1)对URL网址链接进行深层过滤,只提取与特定格式相契合的URL链接;
(2)提取网页内容,如新闻标题、正文等。
三、教育技术新闻网络信息采集系统的实现
1.信息采集系统的工作流程
教育技术新闻大都是在网站的首页或者子版块的首页发布的,这些页面叫做导航型页面或者索引型页面。新闻采集系统的动态调度要研究的就是这些导航型网页的变化规律,通过对网页变化规律的分析,在一定程度上预测网页下次变化的时间,在网页变化后尽可能快地发现新的新闻并进行采集。[6]教育技术新闻网络信息采集系统的详细设计流程如下:[7]
第一步:确定信息采集对象,即由用户自主选取目标网站;
第二步:获取特定信息,即按照目标网站的特定网页格式,获取目标数据,这里的目标数据就是一些教育技术新闻的URL地址、标题、正文等内容;
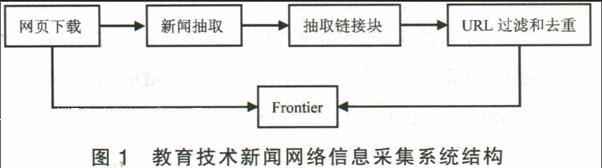
第三步:网络信息获取,即利用工具自动的把页面数据保存到数据库或硬盘。为了降低信息采集系统的复杂性,需要把将URL 动态调度和普通 URL 调度这两个模块集成封装为一个模块,称为Frontier。根据信息采集系统的一般设计步骤,结合权威教育技术新闻网站页面的典型特点,本文设计了符合权威教育技术新闻网站规律的信息采集系统,下面是系统的体系架构,如图1所示。
2.模拟浏览器和保存功能的实现
为了使用户方便、可视化浏览将要抓取的网页,这里可以利用C#中的WebBrowser控件简易制作一个内嵌的网页浏览器效果,具体操作及实现过程如下:
第一步:添加WebBrowser控件到窗口设计页面中;
第二步:添加浏览器启动按钮的单击事件,前往列表框中的url指定的网页;
第三步:添加NewWindow事件,使得用户点击打开新网页时不是从IE窗口弹出;
第四步:添加浏览器后退按钮的的单击事件,实现返回上一个浏览过的网页;
第五步:添加Navigated事件,使combox_url中的文本在用户浏览网页之后能够显示当前网页的url。
此外,利用C#语言中的SaveFileDialog类和Stream-Writer类以字符串格式实现对提取的帖子信息和正文信息的个性化保存,信息可以保存为txt或doc格式。点击正文信息保存按钮会弹出保存对话框,用户可以将自己需要的信息保存在数据库或电脑硬盘中,节省了用户的网络学习时间。endprint
3.测试结果
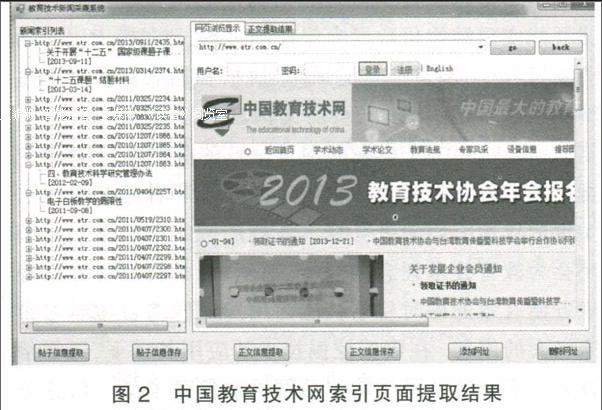
经过对一些教育技术网站的测试,发现本系统已经具有一定的通用性,中国教育技术网、中国教育技术学科网等网站均能测试成功运行,这里以中国教育技术网为例展示最终的运行效果。输入正确的URL地址并点击贴子信息提取按钮,系统运行界面如图2所示。
由图2可以得出:左边提取的结果与右边网页浏览显示的标题、时间一致,因此,索引页面的提取是正确的。点击帖子信息保存实现本地硬盘存储,经对比,存储保存的结果与左侧解析结果一致,说明运行正确。随意选中一个左侧新闻索引列表中的URL地址,并点击正文信息提取,可以实现对正文的提取,这里以“视频云计算在教育资源平衡化中应用的探讨”这则新闻为例进行效果展示,效果如图3所示。
为了检测正文提取的效果,这里给出该则新闻的网页浏览效果,如图4所示。
经过对比,新闻与网页中的格式、内容均保持一致,说明程序运行良好。点击正文信息保存可以实现对正文以txt或者doc的格式进行保存。
四、教育技术新闻网络信息采集系统的应用前景
教育技术新闻网络信息采集系统具有广阔的应用前景,可以广泛地用于以下方面。[8]
1.教育技术数字图书馆建设
建设现代教育技术数字图书馆的一个关键性的问题就是网络教育技术资源的采集和保存问题。教育技术领域网络信息采集系统可以自动从相关门户网站地收集网络信息资源,并将其按照所属类别地存入相应的资源数据库,从而可以为构建教育技术专业门户网站打下基础。
2.企业绩效技术运用
在信息化时代,企业的经济效益往往跟绩效技术挂钩。一个企业若要在高强度的竞争中立足并在行业发展中占据领先地位,离不开对绩效技术的追踪与调查。基于教育技术领域的网络信息采集系统能够依据企业特定的业务需求,实现企业相关新闻或情报的自动化收集,并能够有针对性地作出预测分析等。如此,企业就可以对最新的绩效技术情报进行收集,运用绩效技术提高企业的运营效益。
3.信息资源的积累
对于任何提供电化教育信息服务的部门而言,如何获取大量的、实用性的信息都是一个相当麻烦的问题。网络信息采集系统可以利用数据挖掘技术有针对地进行网络信息资源的采集和整理,并对信息进行按需分类和数据库保存,最终形成知识信息的个性化积聚。
4.“人本化”信息采集
某些专业用户(如教育技术领域的研究人员等)对信息的需求是非常特殊和专业的,网络信息采集系统可以根据他们的个人研究兴趣而进行特定专题的自动化、个性化收集,为他们提供其所在领域的最新信息或研究资讯。
五、总结与展望
网页信息采集工作,归根结底就是一个模式获取的问题,尽管本论文的研究取得了一定的成果,但是还存在一些不足有待改进和完善。文章中所设计系统的设计部分识别机制主要是由程序员总结提供的,并不能实现程序的自动识别获取,此外,部分网站由于URL为相对地址并且格式不尽相同,在一定程度上会导致提取错误,无法有效实现对正文的提取。因此,如何实现用户定制或程序自动获取各种模式,使程序能够通过机器学习的方式自动获取,以适用于不同的教育技术网站,将是未来教育技术新闻网络信息采集面临的一个主要难题。
参考文献:
[1]罗刚.使用C#开发自己的搜索引擎[M].北京:清华大学出版社,2012.
[2]罗刚,王振东.自己动手写网络爬虫[M].北京:清华大学出版社,2010.
[3]邱哲,符滔滔.开发自己的搜索引擎[M].北京:人民邮电出版社,2007.
[4]Winter.中文搜索引擎技术解密:网络蜘蛛[M].北京:人民邮电出版社,2010.
[5]邹涛,张福炎.网络信息搜寻技术与发展[J].计算机工程与科学,2008,20(4):33-36.
[6]贺苏伟.教育新闻采集系统的设计与实现[D].广州:华南理工大学,2012.
[7]Hsin-His Chen,Shih-Chuang Tsai,Jin-He Tsai.Mining Tables from Large Scale HTML Texts.Proceedings of the 18th International Conference on Computational Linguistics[C], University of Saarlandes,July 31-August4 2009,166-172.
[8]朱华.网络信息资源采集技术[J].国家图书馆学刊,2004(2):38-40.
(编辑:杨馥红)endprint
