新闻情感倾向性识别算法的研究与应用
2015-11-10周邦定曹海鹏
周邦定,曹海鹏,张 彦
(中国科学技术大学 信息科学技术学院,安徽 合肥 230026)
0 引言
网络上的负面新闻有很高的利用价值,银行、保险和风险投资机构通过分析这些负面新闻来决定是否与该客户或者企业开展合作。
目前主要有两种情感倾向性识别方法:基于统计的方法[1-3]和基于规则的方法[4-6]。 林政等人[1]在设计关键句抽取算法时考虑了3个特征,分别是情感特征、位置特征和关键词特征。这种方法处理结构复杂的句子时容易产生丢失句子信息的情况,比如丢失否定前缀或者丢失程度前缀。刘永丹等人[4]提出一种基于语义分析的方法,从待分析的句子中提取出相应的格,然后通过事先设定好的规则和词表来判定分析单元的倾向性。但是这种方法提取出的格的准确率非常低,而且判断规则的设计也很困难。
本文提出给单个倾向词分配倾向性、强度、极性和标志4个属性,通过人工确定情感词相应属性的值,将一系列情感词制成特定的情感词典。然后,通过依存句法找出情感词之间的依存关系,通过本文提出的情感判定算法得出整个句子的情感值,最后将整篇新闻中关键句的情感值叠加,得到整篇新闻的情感值。
1 倾向词语料库
1.1 倾向词
对人或事表达态度或者情感倾向的语句叫作情感语句。情感语句中体现态度或者情感倾向的词叫作情感词。情感词、否定词和强度词这三类词统称为倾向词。
对真实的负面新闻语料进行分析发现,有些倾向词可以直接判断出情感倾向性,如 “倒闭”、“破产”、“违法”等,这些倾向词称为独立倾向词;有些倾向词单独分析时得不出情感倾向性,只有与搭配词搭配起来,才能表达一定的情感倾向性,如单独分析“净利润”情感倾向性时,它的情感倾向性为中立的,但是当“净利润”与搭配词“下降”搭配时,其表达的情感倾向性即为负面的,这类倾向词称为搭配倾向词。
1.2 倾向词的数据结构
本文给倾向词设定4个属性:倾向性、强度、极性和标志。
(1)倾向性(orientation):指出倾向词是正面的、负面的还是中立的。正面取1,负面取-1,中立取0。
(2)强度(intensity):指该倾向词对情感句子的情感倾向性有增强或者减弱的作用。增强取2,减弱取0.5,既不增强也不减弱取1。
(3)极性(polarity):指该倾向词是否逆转了句子的情感倾向性。一般否定词会逆转句子的情感倾向性。
(4)标志(flag):指出该倾向词是独立倾向词还是搭配倾向词。flag取0代表该倾向词是独立倾向词;flag取正整数i,代表该倾向词是搭配倾向词,该正整数i指出该搭配倾向词的搭配词只能取自搭配词词表的第i类记录中的值。
2 浅层语义分析
2.1 依存句法简介
依存句法由法国语言学家TESNIERE L最先提出。它将句子分析成一棵依存句法树,描述句子内部各个词之间的依存关系[7]。
为了便于本文后续的描述,在此给出3个定义:
定义1节点词:可作为句子某种确定成分 (主/谓/宾/定/状/补)的简单词语或词组。
定义2依存边:如果句子中两节点词g与d之间存在依存关系,其中 g是支配词,d是从属词,则 g与d间构成一个依存对,用一条由从g指向d的有向边l来表示,记为。
图1给出一个包含节点词、依存边的简单的依存语法树示例。由图可知,节点词“净利润”的第一个后继节点是节点词“下降”;节点词“公司”的第二个后继节点是节点词“净利润”,第三后继节点是节点词“下降”。

图1 依存语法树
2.2 依存句法分析器
本文利用复旦大学自然语言处理实验室开发的FNLP对句子进行依存句法分析[8]。使用FNLP对句子进行依存句法分析时,用4个数组表示分析结果:数组words表示句子分词结果,数组pos表示词语对应的词性,数组relations表示词与词之间的依存关系,数组heads表示词语的第一后继节点词的下标。对句子“今年公司的净利润大幅下降。”进行依存句法分析,得到的结果如表1所示。
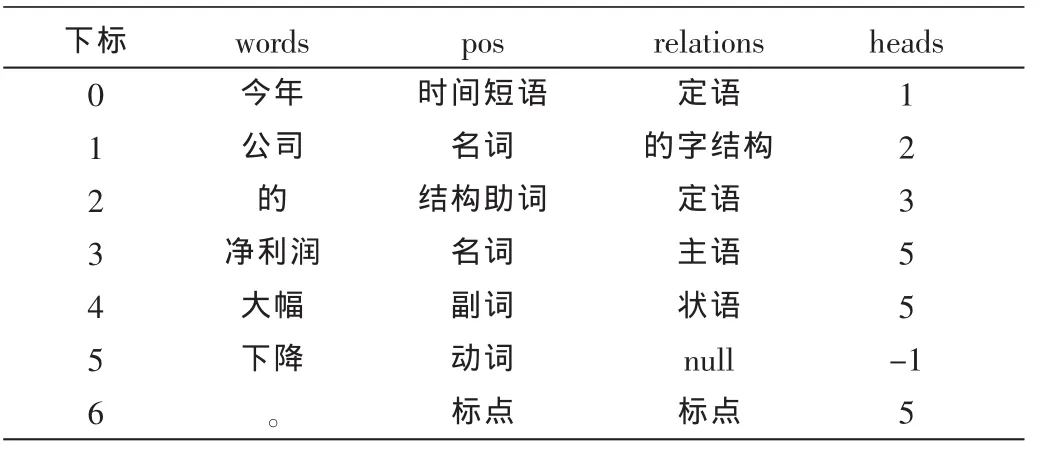
表1 FNLP进行依存句法分析的结果
3 情感识别算法
设 S={x1,…,xn}为句子,xi(1≤i≤n)是句子中第 i个字;K={y1,…,ym}为关键词,yj(1≤j≤m)为关键词的第 j个字,文本中句子与关键词集相似度计算公式如式(1)所示。

其中,⊕的含义是:当 yj与 xi相同,则 yj⊕xi=1;否则,yj⊕xi=0。
当计算出的相似度大于或等于阈值时,该句子就是关键句。新闻文本中所有的关键句构成了关键句群。
设关键句 S中的第i个词为wi,S的情感值为 score,句子对应的倾向性值为ORIENTATION,句子对应的强度值为INTENSITY,句子对应的极性值为POLARITY。如果wi是独立倾向词,则计算式(2)、(3)、(4):

如果wi是搭配倾向词,则通过句子的依存关系寻找词 wi的后继节点词 wj,计算式(2)、(3)、(5):

整个句子所有的情感倾向词扫描完之后,计算式(6):

score的值即为句子的情感值。
设整篇文章的关键群中的句子数为n,整篇文章的情感值为SCORE,则:

score(i)为第i个情感句子的情感值。
具体的算法伪代码如下:
算法1情感倾向性识别主算法

从目标新闻T提取关键句群S;

算法2搭配词查找算法


4 试验及结果
本文实验数据取自某银行2012年度人工收集的2 362条情感倾向性新闻。人工选取了比较有代表性的936条新闻作为训练语料,从这些语料中人工抽取倾向词和搭配词,制成倾向词词典和搭配词词典。另外取1 426条新闻作为测试语料。
使用准确率(Precision)、召回率(Recall)和 F 值(F-measure)作为实验结果的评估指标:

图2给出了算法实验结果的图形展示。

图2 算法实验结果
5 结论
本文以企业新闻的情感倾向性分析为应用背景,利用依存语法分析和通过给倾向词分配属性值为基础,提出了一个识别新闻情感倾向性的算法。实验表明,该方法具有很好的准确率和召回率。但是,该算法的性能与倾向词语料库密切相关,语料库中的语料的存储格式和语料库中语料的丰富程度,都对准确率和召回率有很大的影响。因此,如何构建高性能、完备的语料库值得深入研究。
[1]林政,谭松波,程学旗.基于情感关键句抽取的情感分类研究[J].计算机研究与发展,2012,49(11):2376-2381.
[2]Fan Xinghua, Wang Peng, Zhou Peng.Two step text orientation identification based on feature extension[J].Computer Engineering and Applications, 2012,48(1):162-165.
[3]SAJIB D, VINCENT N.Mine the easy, classify the hard:a semi-supervised approach to automatic sentiment classification[C].Proceedings of the 47th Annual Meeting of the ACL and the4th IJCNLP oftheAFNLP, Singapore,2009:701-709.
[4]刘永丹,曾海泉,李荣陆,等.基于语义分析的倾向性文本过滤[J].通信学报,2004,25(7):78-85.
[5]Ye Qiang, Shi Wen, Li Yijun.Sentiment classification for movie reviews in Chinese by improved semantic oriented approach[C].Proceedings of the 39th Hawaii International Conference on System Sciences, 2006,3:1-5.
[6]曹欢欢.负面新闻判断算法的研究与应用[D].合肥:中国科学技术大学,2014.
[7]邓欣.面向依存文法的汉语语法分析[D].长沙:国防科学技术大学,2000.
[8]Qiu Xipeng, Zhang Qi, Huang Xuanjing.FudanNLP: a toolkit for Chinese natural language processing[C].Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (ACL), Sofia, 2013:49-54.
