改进的主成分分析法对拟南芥基因的分析*
2015-11-10代晓琳马学强王甜甜
代晓琳 ,马学强 ,,王甜甜
(1.山东师范大学 信息科学与工程学院,山东 济南 250014;2.山东省分布式计算机软件新技术重点实验室,山东 济南 250014)
0 引言
在生物信息学中,基因[1]和环境控制着生物的性状,为了研究基因对生物的影响,先从拟南芥的幼苗中提取出来基因,然后对这些基因进行分析。因为幼苗受到盐胁迫的程度不同,所以基因的多变量问题会频繁出现,一旦变量增多,问题的复杂性和难度也会随之增加,在实际问题中,这些变量之间也具有一定的关系。为了能够从中选出少数的几个指标,使它们尽可能地包含原始变量的所有信息,又可以达到用较少的指标去体现原来基因的信息,因此可以用主成分分析方法进行分析,它能够比较客观地反映样本间的现实关系。
1 拟南芥幼苗的处理和基因的提取
1.1 拟南芥幼苗的处理
(1)对种子进行灭菌并且调制1/2MS培养基配方。
(2)种完后,用封口膜包好,防止染菌。在4℃的冰箱中放置3天,然后放到培养箱中竖直培养7天,等长出2片真叶后,移到 NaCl浓度为50 mM、200 mM的1/2MS培养基上。
(3)不作任何处理,50 mM和200 mM盐浓度处理植株的取材时间分别为7天、48 h和12 h。
1.2 RNA的提取和RNA-SEQ检测
对拟南芥幼苗进行3种条件处理:正常未处理(cd0)、50 mM 盐溶液处理(cd1)、200 mM 盐溶液[2]处理(cd5)。cd0取两个株系,即 cd0WT1、cd0WT2;cd1取 3个株系:cd1WT0、cd1WT1、cd1WT2;cd5 取 3 个株系 cd5WT0、cd5WT1、cd5WT2。将上述株系提取它们的RNA送给公司进行RNA-SEQ数据分析。
因为DNA到RNA(即转录)的后期对RNA前体的加工方式(即剪接方式)的不同而造成了不同的剪接本,所以幼苗表现的性状会有所不同。实验对1 280条染色体上的基因进行了数据的分析,下面选一条拟南芥第5条染色体上的基因AT5G43280对实验做全面的概述。AT5G43280这条基因匹配的数据最符合实验生物最终结果,它有AT5G43280.1和AT5G43280.2两种剪接本形式。
将提取到的RNA通过技术转换成cDNA,这些cDNA被随机打碎成90 bp的片段,将大批量的随机打碎的片段 (每个株系从192段到400片段不等)与AT5G43280.1和AT5G43280.2进行对比,计算出仅与AT5G43280.1匹配的基因片段所占比率、仅包含在AT5G43280.2的比率以及同时包含在这两种基因的片段的比率,通过对数据进行分析做出数据的表格如表1所示,极差归一化和直方图如图1所示。

表1 AT5G43280基因对比后的数据

图1 AT5G43280数据对比的直方图
表1中,0代表打乱的每一个 90 bp与AT5G43280.1和AT5G43280.2都不匹配;1代表只存在于AT5G43280.1的片段数;2代表只存在于AT5G43280.2的片段数;3代表既包含在AT5G43280.1,又存在于AT5G43280.2中的片段数。
从AT5G43280数据分析可以得出:对未处理的(cd0)的拟南芥 DNA到 RNA(即转录[3-4])的后期对 RNA前体的加工方式大部分是AT5G43280.1剪接本形式,50 mM盐处理 (cd1)、200 mM盐处理 (cd5)的拟南芥DNA到RNA(即转录)的后期对RNA前体的加工方式大部分为AT5G43280.1剪接本形式。通过对这些基因数据进行分析得出:盐胁迫对拟南芥DNA到RNA(即转录)的后期对RNA前体的加工方式没有太大的影响。
2 利用改进的主成分分析方法对基因数据再次进行分析
在实际应用中,为了消除变量量纲的影响,往往对原始数据标准化,但是标准化在消除量纲或数量级影响的同时,也抹杀了各指标变异程度的差异信息。传统的主成分分析法[5]基于相关系数矩阵进行数据标准化处理,将数据间方差化为1,消除了数据量纲[6]和数据级影响的同时,也忽略了数据指标间的变异程度。因此本文采用中心化对数比进行原始数据变换。
2.1 改进的主成分分析方法步骤
(1)假定有n个样本,每个样本共有 p个变量,构成一个n×p阶的数据矩阵X。
(2)对数变换法
采用中心化对数比进行原始数据变换,一是可以处理数据的非线性特征,二是可以充分反映数据间的变异性信息。

(3)求解主成分
求解主成分时可以从样本协方差矩阵出发,也可以从样本相关系数矩阵出发。
计算相关系数矩阵:

其中,rij(i,j=1,2,3,…,p)为变量 yi与 yj的相关系数,rij=rji其计算公式为:

(4)计算特征值[7]与特征向量
①解特征方程|λI-R|=0,求出特征值,并使其按大小顺序排列(λ1≥λ2≥λ3…λP≥0),分别求出对应于特征值λi的特征向量。
②计算主成分贡献率[8]及累计贡献率。
贡献率:

累计贡献率:

累积贡献率[9]反映了前m个主成分综合原始变量信息的能力,通常是取较小的m,而且累积贡献率υ达到一定的数值(85%)时,累积方差贡献率越大,这就表示前面的几个主成分包含的信息就越丰富。对于含有m个主成分的数据来说,每一个主成分都可以表示为:
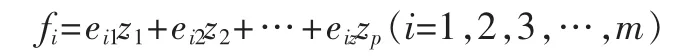
因此综合评价为:

2.2 主成分的指标分成强、中、弱三部分
在对基因的分析中发现,各列(指标)之间的相关性高低影响着评价指标权重系数的分配,权重系数会明显地倾向于相关系数较高的变量,不同的研究者使用的评价标准不同,得到的结果也会有差距。又因为在不同盐浓度处理下幼苗提取的基因的数据量大,为了使最后得到的综合评价函数能够合理,可以把主成分的指标分成强、中、弱3部分,将相关性较强的指标分入到 s1中,相关性较弱的指标分入到s2,剩下的分到相关性为中的s3中,s1+s2+s3=A(A为基因数据指标元素总体),所以相关性较强的指标得到函数f11,相关性为中的指标得到函数f22,相关性较弱的指标得到函数 f33(在这 3项中指标个数不一定相同),最终的综合函数为:F=f11+f22+f33。
3 实例分析
实验对拟南芥很多条染色体上面的基因作了研究,对从这些植株中提取的数据进行分析,目的是探讨用不同浓度的盐处理拟南芥幼苗,是否对DNA到RNA的转录方式有变化,导致拟南芥幼苗外形的变化。
(1)首先对这些数据采用中心化对数比进行原始数据变换,然后利用MATLAB求出数据的相关系数矩阵R:

从计算出的相关系数矩阵可以看出,第1列、第2列、第 4列的相关性比较强,第 6列、第7列、第 8列的相关性为中,第3列和第5列之间的相关性最弱。根据相关性强弱将它们分到 s1,s2,s3中。求出 R的特征值、差值、特征向量、贡献率和累积贡献率,进而求得主成分与变量之间的关系如表2所示。

表2 主成分与标准化变量之间的关系
第一主成分对所有主成分的贡献率为76.389 5%,而01所占的比重最大,因指标1表示由DNA到RNA的转录方式选择的是第一种剪接本,因此标准变化量为0、1、3时,这 3个指标值比较大时,第一主成分的贡献率也就越大。第二主成分对所有主成分的贡献率为17.155 0%,而2所占的比重比较大,指标2表示的是DNA到RNA的转录方式选择的是第二种剪接本,因此标准变化量为 0、1、2、7时,这 4个指标值比较大,第二主成分的贡献率也就越大。前两个主成分的累积贡献率达到了93.544 5%,因此可以只用前3个主成分进行后续的分析,后面主成分对总体的贡献率比较小,分别为5.6%、0.6%和0.1%,可以不对它们做出任何解释。
第一主成分分量的计算公式为:

第二主成分分量的计算公式为:

综合评价函数为:F=a1f1+a2f2+…+amfm
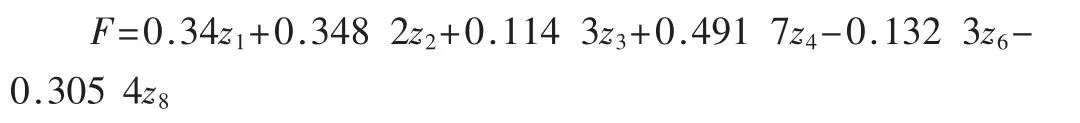
又因为把主成分的指标分为强、中、弱3部分,所以最终的综合评价函数为F=f11+f22+f33。由f11=0.369 5z1+0.4z2+0.612 6z4,f22=0.050 2z3,f33=-0.230 2z6-0.522 2z8,可得:

由综合函数可以得到,s1中包含的指标 0、1、3的相关性较强,改进的主成分分析方法使得相关性较强的集合更加明显,相关性较弱的集合相应地减弱,更容易分析盐胁迫对拟南芥基因的影响。由于0、1、3指标的意义,明显可以得到不同的盐浓度下DNA到RNA的转录方式基本都是选择第一种剪接本,拟南芥的幼苗在浓度越高的环境下生长的叶子黄而且小,主要是外界环境的作用,盐浓度对基因的改变不大。
4 结论
主成分分析方法在很多领域得到广泛的应用,一般来说,当研究的问题涉及很多变量时,变量间相关性明显,并且包含的信息有所重叠时,可以考虑用主成分分析方法。本文经过对PCA进行改进,更容易抓住事物的主要矛盾,使问题得到解决,通过对拟南芥基因数据的分析,预测的结论和实验得到的结果一致。在实际的评价中,应当从样本的客观性出发,兼顾主观客观两方面,分析不同的数据应当使用不同的PCA改进方法,以达到所需要的目的,并且能够更加准确地分析数据。
[1]王素平,郭世荣,李璟,等.盐胁迫对黄瓜幼苗根系生长和水分利用的影响 [J].应用生态学报,2006,17(10):1883-1888.
[2]郭丽红,王定康,杨晓虹,等.外源乙烯利对干旱胁迫过程中玉米幼苗某些抗逆生理指标的影响 [J].云南大学学报(自然科学版),2004,26(4):352-356.
[3]SAKUMA Y,MARUYAMA K,OSAKABE Y,et al.Functional analysis of an Arabidopsis transcription factor,DREB2A,involved in drought-responsive gene expression[J].The Plant Cell Online, 2006,18(5):1292-1309.
[4]SHINOZAKI K,YAMAGUCHI-SHINOZAKI K.Gene networks involved in drought stress response and tolerance[J].Journal of Experimental Botany, 2007,58(2):221-227.
[5]王正群,邹军,刘风.基于集成主成份分析的人脸识别[J].计算机应用,2008,28(1):120-124.
[6]王晓伟,闫德勤,刘益含.基于随机矩阵变换的快速PCA算法[J].微型机与应用,2013,32(20):83-86.
[7]盛骤,谢式千,潘承毅.概率论与数理统计(第4版)[M].北京:高等教育出版社,2008.
[8]冯德俊,李永树,兰燕.基于主成分变换的动态监测变化信息自动发现[J].计算机工程与应用,2004,38(3):199-202.
[9]赵鹏,白振兴,范文同.基于主成分分析的快速图像匹配研究[J].电子技术应用,2010,4(11):132-134.
