基于主题的中文微博情感分析
2015-11-04王永恒
韦 航,王永恒
(湖南大学信息科学与工程学院,长沙410082)
基于主题的中文微博情感分析
韦 航,王永恒
(湖南大学信息科学与工程学院,长沙410082)
传统的微博情感分析一般忽略结构化的语义信息,使得分类准确率不高,同时还忽略情感表达的具体对象,以与主题无关的形式进行情感分析,容易造成错误的分析结果。为此,采用对语法树进行剪枝的方法实现基于主题的情感分析,使用支持向量机中的卷积树核函数获取语法树结构化特征,通过建立本体和句法路径库对语法树进行基于主题的剪枝,去除无关评价的干扰。实验结果表明,该方法在2个不同主题的数据集上准确率分别达到86.6%和86.0%。
中文微博;情感分析;语法树;树核函数;剪枝策略;支持向量机
1 概述
微博是一种通过关注机制分享简短实时信息的广播式社交平台,是Web2.0时代最流行的应用之一,用户可以通过网页、移动终端等各种客户端,发表最多140字的文字信息并实现与他人共享。微博自问世以来,吸引了大量用户在微博上记录生活、讨论热点话题、表达和分享观点,已成为挖掘人们观点与情感的重要资源[1],为用户满意度调查、舆情监测、社会学研究等应用提供有效的数据支持。微博上信息繁多且增长速度很快,仅靠人工浏览的方法难以应对海量信息的收集和处理工作。情感分析技术能够自动将文本中表达的情感倾向进行正负面的分类,很大程度上解决微博上信息杂乱的现象,方便用户快速准确定位所需信息。微博文本与传统文本相比,具有篇幅较短、存在错别字和语法错误等噪声、存在大量网络词汇和口语词汇等特点[2],给情感分析任务提出了新的挑战。
现有的微博情感分类方法通常以一种主题无关的方式操作,但是微博文本存在主题发散性[3],即一条微博可能涉及对多个有关或无关实体的评价,而现有的方法将所有情感特征当成是针对单一主题的评价,容易造成错误。基于此,本文提出一种基于主题的中文微博情感分析方法,对微博句子进行语法分析得到语法树,根据语料库中频繁出现的名词构建领域本体,并通过该本体识别句子中与主题无关的实体,基于句法路径的情感评价单元识别方法,找出与主题无关的评价单元,将其从语法树中剪除,从而去除无关实体及其评价词对分类的干扰。最后,采用基于复合核函数的支持向量机分类器,将剪枝后的语法树特征与平面特征单字(unigram)结合,共同作为分类特征。
2 相关工作
2.1 主题无关的情感分析
主题无关的情感分析指的是对指定文本给出情感极性,而不关心该情感极性所描述的对象[3]。目前的微博情感分析方法大多是主题无关的,主要分为基于情感词典和基于机器学习2种方法。
基于情感词典的方法需要利用包含正面情感词和负面情感词的情感词典,通过统计文本中正负面情感词的数量来判断倾向性。文献[4]使用了3种不同的计分策略进行微博分类,包括正负面情感词差值法、词频-反向文档频率(Term Frequency Inverse Document Frequency,TF-IDF)和潜在狄利克雷分配(Latent Dirichlet Allocation,LDA)。文献[5]应用点互信息量对已有的情感词典进行扩展,构建面向中文微博的情感词典,并对否定词、程度副词、感叹句、反问句以及表情符号做相应分析处理,用加权和的方式取得整条微博的情感分值。由于情感词典法无法解决未登录词的问题,微博中又含有大量网络词汇、口语词等不存在于现有情感词典中的情感词语,单纯使用情感词典进行分类效果不佳,易造成低召回率的问题。
基于机器学习的分类将情感分析问题当成一个特殊的文本分类问题,使用大量已标注的文本对机器学习模型进行训练,再使用训练好的分类模型对未知极性的文本进行分类。文献[6]首次提出用机器学习方法进行文本分类,提取unigram、二元(bigram)、词性标注以及词的位置作为分类特征,选用朴素贝叶斯(Naïve Bayesian)、最大熵(Maximum Entropy)、支持向量机(Support Vector Machine,SVM)3种模型作为分类模型。文献[7]利用微博中特有的标签和表情符号作为情感标签抽取训练样本,训练一种类似KNN的分类器进行细粒度的情感分类。文献[2]除了考虑微博本身的内容特征,还考虑了当前微博与其他微博之间的关系、微博发布者与其好友之间的相互影响等上下文特征,将2种特征结合起来共同作为分类特征。文献[8-9]将情感词典法与机器学习法相结合,用情感词典法抽取文本作为分类器的训练集,无需人工标注训练集。
2.2 主题相关的情感分析
主题相关的情感分析考虑文本中针对某一主题的情感倾向,而非文本的整体情感倾向。已有的方法主要是基于规则的方法和基于特征的方法。
在基于规则的方法中,文献[10]将最靠近主题词的情感词作为针对该主题的有效情感指示词,文献[11]则将句子中所有的情感词按照与主题词的距离远近进行加权和,得到针对该主题的情感分值。文献[12]通过语法分析找出情感词与主题词之间的关系,并将这些关系与人工制定的规则进行匹配以判断其极性,但是这种方法需要人工制定规则,不能处理新出现的未涵盖情况。
在基于特征的方法中,文献[13]选取了7种基于主题的特征,通过浅层语法分析得到文中的这些特征,但该方法需要人工制定特征提取规则,且这些特征是符合英文语法规则的,不能直接用在中文领域;文献[3]则进行了主题相关句子的筛选,去掉与主题无关的句子,但筛选方法不够准确,且不能处理句子中包含多个实体的情况。
3 基于语法树的结构化特征
大多数机器学习情感分类方法采用的是一种bag-of-features特征表示方法,抽取文中一系列平面特征,将文本表示为特征向量形式,不考虑特征的出现顺序以及特征之间的关系,这些平面特征通常包括词的n-gram及其出现频率、词性、情感词、否定词等。然而,平面特征忽略了句子的语义信息以及词语之间的结构化关系,也无法捕获远距离的情感信息。
为了克服平面特征存在的问题,通过句子的语法树获取文本的结构化特征。语法树是句子结构的图形表示,它代表了句子的推导结果,有利于理解句子语法结构的层次。例如句子“这台相机很好用”可表示为如图1所示的树形结构。

图1 语法树结构
3.1 卷积树核函数
语法树能够捕获句子的结构化语义信息,将语法树作为特征交由支持树核函数的SVM进行训练,就能得到一个自动获取语法树中结构化信息的分类系统。采用卷积树核函数(Convolution Tree Kernel,CTK)来获取结构化特征,它通过计算2棵树之间相同子树的数目来衡量其相似度[14-15],即2棵语法树T1和T2的相似度KC(T1,T2)按下式计算:

其中,N1和N2分别表示T1和T2的节点集;Δ(n1, n2)为以n1和n2为根节点的子树中相同子树的数量,由以下递归方法计算:
(1)若n1和n2的产生式不同,则Δ(n1,n2)=0,否则转(2);
(2)若n1和n2都是叶子节点的前一个节点(即词性标注),则Δ(n1,n2)=λ,否则转(3);
(3)递归计算:

其中,nc(n1)表示n1的子节点个数;ch(n,j)表示节点n的第j个子节点;λ(0<λ≤1)是用于防止子树的相似度过度依赖于子树大小的衰减因子。
3.2 复合型核函数
微博文本由于存在字数限制,包含的信息量较少,缺少上下文信息,需要更多的特征来进行情感分类。卷积树核函数能够有效抽取结构化特征,平面特征则需要基本核函数获取,包括线性核函数、多项式核函数等。多个核函数之和仍是有效的核函数,并能兼顾各个单核的优点,因此,将卷积树核函数与基本核函数复合,能够同时获取结构特征和平面特征。复合核可表示为λK1+τK2。其中,K1表示卷积树核;K2表示基本核,通过调整λ和τ的值,可以获取卷积树核和基本核各自的贡献度。
平面特征方面,文献[6]发现unigram能取得最佳效果,所以也采用unigram特征。为了对特征空间进行降维去噪,采用CHI方检测对特征进行筛选。CHI方检测通过测量特征与类别之间的依赖性进行特征的选取[16],CHI越大表示相关性越大,计算公式如下:

其中,A表示含有特征t的ci类样本数;B表示含t的非ci类样本数;C表示不含t的ci类样本数;D表示不含t的非ci类样本数;N表示样本总数。将unigram特征按照CHI值降序排序,取前n个特征作为分类特征,去掉剩下的CHI较小的特征。
4 基于主题的语法树剪枝
语法树能够提供丰富的结构化信息,但是一棵完整的语法树含有较多噪音,分类的开销也较大,故需要进行剪枝操作。文献[14]分别基于形容词和情感词进行语法树剪枝,通过滑动窗口大小确定剪枝范围;文献[15]对依存树进行基于情感词的剪枝,去掉与情感词之间的依存关系出现不频繁或对分类无益的节点。本文研究基于主题的情感分析,提出一种基于主题的语法树剪枝策略,将与主题无关的信息从语法树中去掉。
4.1 领域本体的构建
本体是共享概念模型明确的形式化规范说明[17],可以用来捕获领域知识,对领域中的概念以及概念之间的关系进行建模。
形式概念分析(Formal Concept Analysis,FCA)是一种数学数据分析理论,常用于知识表示和信息管理[18],能够从一系列实体及其属性中建立本体模型。FCA的基本构件是概念,由2个集合来描述:外延(extension)和内涵(intension),其中,外延指属于这个概念的对象的集合;内涵指这些对象所共有的属性集。文献[18]采用FCA方法人工构建领域本体,针对产品的某一属性进行评分。本文采取一种半自动的FCA方法构建领域本体:
(1)统计与主题词共同出现的名词,按照其出现频率排序;
(2)从频繁出现的名词集合中选取实体和属性,分别加入实体集和属性集;
(3)由实体集抽取出概念,实体集作为概念的外延,属性集中的概念共有属性作为概念的内涵,某些实体的特有属性单独取出作为特有属性集,与该实体相连。
步骤(2)、步骤(3)需手动完成。图2给出了一个手机领域本体,其中“手机”为概念,上方为其内涵,即手机具有“屏幕”、“软件”、“硬件”等属性,下方为其外延,如χ、y等具体品牌的手机。其中,“WP8系统”等属性属于χ所特有的属性,作为χ的特有属性集与其相关联。值得注意的是,在商品或服务领域,同一个概念外延中的各个实体,是存在竞争关系的实体,如χ与y、z等。

图2 手机领域本体示例
4.2 情感评价单元识别
在一条微博消息句子中,可能含有多个评价对象和评价词语,情感评价单元识别就是将评价词语及其所修饰的评价对象作为一个评价单元抽取出来。文献[19]提出基于句法路径的情感评价单元识别方法,其基于一个假设:评价词语与其修饰的评价对象之间的句法路径是具有一定规律的、可总结的。采取类似方法识别评价单元,为下一步基于主题的剪枝提供依据。
评价对象与评价词语之间的句法路径,指的是在语法树上链接评价对象与评价词语两节点之间的句法结构,如图1所示的语法树中,“相机”为一个评价对象,“好用”为一个评价词语,两节点之间的句法路径(箭头所示)为:NN→NP→NP→IP→VP→VP→VA。在较大规模语料库中进行统计,能够发现句法路径存在一定的规律,正确的句法路径出现频率应较多,而错误的句法路径出现较少。
评价对象一般为名词,通过词性标注可以获取,而评价词语可以通过情感词典获取。获取评价对象与评价词之间的句法路径之后,可进行一步泛化处理,使得只存在细小差别的句法路径合并为一个具有代表性的句法路径,方法是将句法路径中连续的相同成分合并,如上面的句法路径NN→NP→NP→IP→VP→VP→VA泛化为NN→NP→IP→VP→VA。将句法路径按照出现频率排序之后,根据事先定义的阈值thP,选择前thP个句法路径构成句法路径库,去掉出现频率不高的句法路径。
4.3 基于主题的语法树剪枝策略
构建了领域本体和句法路径库之后,就可以进行基于主题的语法树剪枝,基本思路是,一个微博句子中可能含有对多个对象的评价,有些对象与主题无关,则将这样的无关对象及其评价词从语法树中剪除,从而实现针对主题的情感分析。
剪枝的具体流程如下:
(1)通过词性标注和查询情感词典,获取句子中的名词集合和情感词集合;
(2)查询领域本体,在名词集合中识别不存在本体中、与主题词无关的实体加入待修剪名词集合;对于存在于本体中,但与主题词存在竞争关系的实体,也加入待修剪集合,且如果该实体之后存在该实体的属性,也需要将其加入待修剪集合;
(3)针对待修剪集合中的实体,获取语法树上这些实体与情感词之间的句法路径,通过匹配句法路径库,识别对其进行修饰的情感词;
(4)根据第(3)步中识别出的主题无关评价单元中评价对象和评价词在语法树上对应的节点位置,找出其共同父节点,将父节点下方含有该评价词和评价对象的子树剪除,若剪枝后该父节点下没有任何子树,则将该父节点也剪除。
下面列出2个句子的剪枝过程加以说明。设a为感兴趣的主题词。句子1:a还不错,差评是给b的。该句子中的评价对象为{a,b};评价词语为{不错,差评}。查询本体发现b是与主题无关的实体,加入待修剪集合。句子的语法树结构如图3所示,b与“不错”之间的句法路径为NN→NP→VP→IP→CP→IP→VP→VA,与“差评”之间的句法路径为NN→NP→VP→IP→NP→NN。

图3 句子1的语法树剪枝示例
搜索句法路径库发现第1个句法路径不存在库中,而第2个句法路径存在库中,则可判断“差评”是b的有效评价词。在语法树中找到这2个节点的共同父节点“IP”,将以该父节点为根节点的子树中含有b和“差评”的子树剪除,此时该父节点下已无子树,则将该节点也剪除。
句子2:早知道就不买c了,流量消耗特别快,还比不上d呢。评价对象为{c,流量消耗,d},评价词为{快},查询领域本体发现c是与d存在竞争关系的实体,“流量消耗”属于手机的共有属性且出现在c之后,则将其当成c的属性,待修剪集合为{c,流量消耗}。通过匹配句法路径库发现“快”是对“流量消耗”的评价词,故将这部分剪除,如图4所示。

图4 句子2的语法树剪枝示例
5 实验结果及分析
5.1 情感评价句法路径库构建
根据4.2节介绍的句法路径库构造方法构建情感评价句法路径库。采用NLPIR汉语分词系统进行微博分词和词性标注,用Stanford Parser进行语法分析,采用的情感词典是台湾大学NTUSD中文通用情感词典,包含2 810个正面词和8 276个负面词,同时为了处理微博中包含大量网络词汇的问题,加入了常用的网络情感词语,如表1所示。

表1 常用网络情感词语
对含有36 042条腾讯微博消息的语料库进行句法路径统计,该语料库涵盖汽车、手机、购物网站等多个领域。表2列出出现最为频繁的5条句法路径及其出现次数。

表2 出现最频繁的5种句法路径
5.2 微博情感分析实验数据集
分类实验中使用的数据来自腾讯微博。选取了2个关键词作为情感分类的主题:{e,f}。根据主题词,分别从腾讯微博上获取包含该主题词的微博消息。经过人工标注,分别得到正面情感和负面情感2类微博,数据集信息如表3所示。

表3 实验数据集统计信息
5.3 微博情感分析实验结果
本文使用SVM-light-TK作为分类工具,在SVM-light的基础上加入了对卷积树核函数的支持。给出一条微博示例,说明复合特征的输入格式,分为类别标签、语法树特征(包含开始标志“|BT|”、结束标志“|ET|”)和平面特征3个部分。其内容为“××的f网站怎么打不开了?其他的就能打开,oo!”;分句为“句子1:××的f网站怎么打不开了?”,“句子2:其他的就能打开,oo!”;复合特征输入格式为“-1|BT|(ROOT(CP(IP(FLR(IJ××))(NP(NN f)(NN网站))(VP(ADVP(AD怎么))(VP(VV打)(VP(ADVP(AD不))(VP(VV开))))))(SP了)))|BT|(ROOT(IP(NP(DNP(DP(DT其他))(DEG的)))(VP(VP(ADVP(AD就))(VP(VV能)(VP(VV打开))))(PU,)(VP(VA oo)))))|ET|56:1.0 235:1.0 244:1.0 258:1.0 500:1.0 536:1.0 549:1.0 721:1.0 728:1.0 841:1.0 944:1.0 947:1.0 965:1.0 1058:0.0”。
对4种情感分类方法进行了分类效果的比较,分别是:(1)只采用unigram平面特征,并用CHI检测进行特征筛选,分类时选用线性核函数;(2)只采用语法树特征;(3)采用复合核函数,将语法树和unigram相结合;(4)将语法树进行基于主题的剪枝之后,再使用复合核函数分类。SVM-light-TK中提供了可以对树核函数在复合核函数中的贡献进行调整的参数r,复合核函数K表示为:

其中,r的默认值为1,并对应于λK1+τK2式中的参数λ(树核函数K1的贡献参数),则通过调整r值可以调整复合核函数中树核函数的贡献程度,实验中调整r的值(即λ的值),而参数τ(基本核函数K2的贡献参数)则固定为1。针对2个主题词进行实验,评价指标为查准率、召回率、F值和准确率,实验结果如表4所示,表中涉及复合核函数的部分,仅列出在r取不同值的情况下,获得的最佳分类效果。
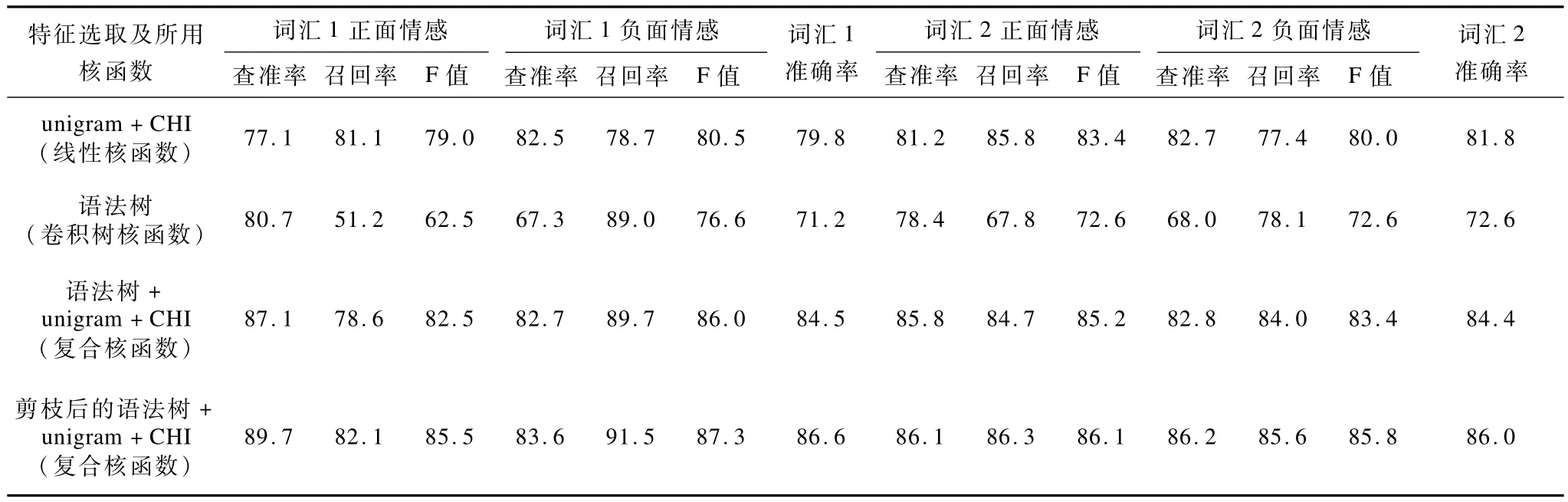
表4 微博情感分类结果%
通过观察表4中的实验结果发现:(1)如果仅使用语法树特征进行分类,分类的总体效果与平面特征相比有较大程度的下降,这是由于语法树特征仅能捕捉语义特征,而忽略了平面特征对分类的贡献;(2)采用复合核函数的方式将平面特征与语法树特征相结合,弥补了上述问题,分类效果有了较大提高,说明复合核函数能够利用结构化的语义特征和平面特征两者的优势,提升分类性能;(3)采用基于主题的剪枝方法对语法树进行剪枝之后,分类的效果得到进一步的提升,这说明本文提出的基于主题的剪枝策略能够在一定程度上去掉无关评价单元的干扰,对分类起到积极作用。
实验中,复合核函数中树核函数贡献参数r的取值也会对分类效果产生一定的影响,图5显示了r的不同取值对分类准确率的影响。

图5 树核函数贡献参数r对分类准确率的影响
通过观察发现,针对不同的数据集,取得最佳分类准确率时r的取值有所不同,其中e主题样本在r=0.2时准确率取得最大值,而f主题样本在r= 0.05时准确率取得最大值。表4列出的是该最佳分类结果,在实际应用中可以把r设置在0.05~ 0.20之间。
6 结束语
现有的微博情感分类方法大多采用主题无关的方式进行,当句子中含有多个评价实体时容易出现错误。本文采用基于卷积树核函数的方法,从句子的语法树中抽取结构化的语义特征,与平面特征相结合,共同作为分类特征;特别地,对句子中出现多个评价单元的情况,应用领域本体和统计句法路径方法,识别出与主题词无关的评价单元,并将其从语法树中剪除,以排除无关评价单元对分类的干扰,从而实现了基于主题的微博情感分类。实验结果表明,结构化语义特征与平面特征结合,能明显提升分类效果,而采用基于主题的剪枝策略对语法树进行剪枝,分类效果得到了进一步的提升。
由于本文的评价单元识别过程依赖情感词典,对于不含有情感词语的句子无法进行剪枝,现有的情感词典涵盖范围有限,微博上又常出现新词,并且剪枝方法对于一些较为复杂的句子,如比较句、转折句等处理得不够理想,还存在一定的局限性,因此,在今后的工作中将进一步研究网络新词发现、情感表达识别等问题,并改进对复杂句子的处理方法。
[1] Alexander P,Patrick P.Twitter as a Corpus for Sentiment Analysis and Opinion Mining[C]// Proceedings of the 7th International Conference on Language Resources and Evaluation.Valletta,Malta:ELRA Press,2010:1320-1326.
[2] Fotis A,George P,Konstantinos T,et al.Content Vs. Context for Sentiment Analysis:A Comparative Analysis over Microblogs[C]//Proceedings of the 23rd ACM Conference on Hypertext and Social Media.New York,USA:ACM Press,2012:187-196.
[3] 谢丽星,周 明,孙茂松.基于层次结构的多策略中文微博情感分析和特征抽取[J].中文信息学报,2012,26(1):73-83.
[4] Jinan F,Osama M,Sabah M,et al.Opinion M ining over Twitterspace:Classifying Tweets Programmatically Using the R Approach[C]//Proceedings of the 7 th International Conference on Digital Information Management.Washington D.C.,USA:IEEE Press,2012:313-319.
[5] 陈晓东.基于情感词典的中文微博情感倾向分析研究[D].武汉:华中科技大学,2012.
[6] Pang B,Lee L,Shivakumar V.Thumbs up?Sentiment Classification Using Machine Learning Techniques[C]//Proceedings of Conference on Empirical Methods in Natural Language Processing.New York,USA:ACM Press,2002:79-86.
[7] Dmitry D,Oren T,Ari R.Enhanced Sentiment Learning Using Twitter Hashtags and Smileys[C]//Proceedings of the 23rd International Conference on Computational Linguistics.Berlin,Germ any:Springer,2010:241-249.
[8] Songbo T,Yuefen W,Xueqi C.Combining Learn-based and Lexicon-based Techniques for Sentiment Detection Without Using Labeled Exam ples[C]//Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development Information Retrieval. Singapore:[s.n.],2008:743-744.
[9] Zhang Lei,Ghosh R,Dekhil M,et al.Combining Lexicon-based and Learning-based Methods for Twitter Sentiment Analysis,HPL-2011-89[R].HP Laboratories,2011.
[10] Minqing H,Bing L.Mining and Summarizing Customer Review s[C]//Proceedings of the 10th ACM SIGKDD International Conference on Know ledge Discovery and Data Mining.Seattle.New York,USA:ACM Press,2004:168-177.
[11] Ding Xiaowen,Liu Bing.The Utility of Linguistic Rules in Opinion Mining[C]//Proceedings of the 30 th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.New York,USA:ACM Press,2007:811-812.
[12] Tetsuya N,Jeonghee Y.Sentiment Analysis:Capturing Favorability Using Natural Language Processing[C]// Proceedings of the 2nd International Conference on Know ledge Capture.New York,USA:ACM Press,2003:70-77.
[13] Jiang Long,Yu Mo,Zhou Ming.Target-dependent Twitter Sentiment Classification[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics.Portland,USA:[s.n.],2011:151-160.
[14] Zhang Wei,Li Peifeng,Zhu Qiaom ing.Sentiment Classification Based on Syntax Tree Pruning and Tree Kernel[C]//Proceedings of the 7th Web Information System s and Applications Conference.Washington D.C.,USA:IEEE Press,2010:101-105.
[15] Li Peifeng,Zhu Qiaom ing,Zhang Wei.A Dependency Tree Based Approach for Sentence-level Sentiment Classification[C]//Proceedings of the 12th ACIS International Conference on Software Engineering,Artificial Intelligence,NetW orking and Parallel/ Distributed Computing.Washington D.C.,USA:IEEE Press,2011:166-171.
[16] 刘志明,刘 鲁.基于机器学习的中文微博情感分类实证研究[J].计算机工程与应用,2012,48(1):1-4.
[17] 黄美丽,刘宗田.基于形式概念分析的领域本体构建方法研究[J].计算机科学,2006,33(1):210-212.
[18] Efstratios K,Christos B,Theologos D.Ontology-based Sentiment Analysis of Twitter Posts[J].Expert System with Applications,2013,40(10):4065-4074.
[19] 赵妍妍,秦 兵,车万翔,等.基于句法路径的情感评价单元识别[J].软件学报,2011,22(5):887-898.
编辑顾逸斐
Sentiment Analysis of Chinese Micro-b log Based on ToPic
WEIHang,WANG Yongheng
(School of Information Science and Engineering,Hunan University,Changsha 410082,China)
Micro-blog attracts a large number of users to publish and share opinions on it,making it an important data resource for opinion mining and sentiment analysis.The traditional methods always ignore structured semantic information,which leads to the low accuracy.They also tend to ignore the topic of the sentimental expressions and adopt the topic-independent strategy,which results in somemistakes.This paper proposes amethod of pruning the syntax tree to implement the topic-dependent sentiment analysis.It uses the convolution kernel of Support Vector Machine(SVM)to obtain the structured information from syntax tree,and adopts the topic-dependent syntax pruning according to the domain ontology and syntactic paths library,then eliminates the inference of irrelevant appraisal expressions.Experimental results on two corpus with different topics show that the accuracy can reach 86.6%and 86.0%.
Chinese micro-blog;sentiment analysis;syntax tree;tree kernel function;pruning strategy;Support Vector Machine(SVM)
韦 航,王永恒.基于主题的中文微博情感分析[J].计算机工程,2015,41(9):238-244.
英文引用格式:Wei Hang,Wang Yongheng.Sentiment Analysis of Chinese Micro-blog Based on Topic[J].Computer Engineering,2015,41(9):238-244.
1000-3428(2015)09-0238-07
A
TP393
10.3969/j.issn.1000-3428.2015.09.044
国家自然科学基金资助项目(61371116);湖南省自然科学基金资助项目(13JJ3046)。
韦 航(1990-),女,硕士研究生,主研方向:文本分析,数据挖掘;王永恒,讲师、博士。
2014-07-30
2014-10-14 E-m ail:756877026@qq.com
