多媒体云计算下的大规模数据流调度方法研究
2015-10-26安海涛
安海涛
摘 要: 传统的多媒体数据流调度方法在云平台环境下,未考虑服务器信息调度的差异性,容易形成数据调度冲突,调度效率低。为了解决上述分析的问题,通过构建多媒体云计算下数据流调度平台,实现对多路大规模多媒体数据流的合理调度,利用多级分层结构将多媒体云计算下的多服务器大规模数据流调度过程划分成管理层面、控制层面以及数据层面,可确保将数据包均匀的分配给各个服务器,充分发挥云计算下的多服务器可并行处理的特性,增强数据流的调度质量。对调度平台的软件框架进行了详细的描述,依据该软件框架的多层次实现大规模数据流调度优化,分析了大规模数据流调度的具体实现过程,并给出大规模数据流调度平台软件代码的设计。实验结果表明,所提方法增强了多媒体云计算下的大规模数据流调度的并发性能,提高数据流调度质量。
关键词: 多媒体; 云计算; 大规模数据流; 调度方法
中图分类号: TN911?34 文献标识码: A 文章编号: 1004?373X(2015)20?0154?04
Research on massive data stream scheduling method under the condition of
multimedia cloud computation
AN Haitao
(Inner Mongolia Electronic Information Vocational Technical College, Hohhot 010010, China)
Abstract: The traditional multimedia data stream scheduling method does not consider the difference of the server information scheduling in the cloud environment, and is easy to form the data scheduling conflict, which may result in low scheduling efficiency. In order to solve the problem of the above analysis, by constructing the data stream scheduling platform under the condition of multimedia cloud computation to achieve rational scheduling of multi?channel large?scale multimedia data stream, the massive data stream scheduling process of multiple servers in multimedia cloud computation is divided into management level, control level and data level by using multi?stage stratified structure, so as to ensure that the data packet is evenly assigned to each server, give full play to the parallel processing features of multiple servers in cloud computation, and enhance the scheduling quality of data stream. The software framework of dispatching platform is described in detail. According to the multi?level feature of software framework, the scheduling optimization of large?scale data stream is realized. The specific implementation process of massive data streams scheduling is analyzed. The design of the software code for massive data streams scheduling platform is given. The experimental results indicate that the proposed method has enhanced the concurrent performance of massive data flow scheduling under the condition of multimedia cloud computation and improved the scheduling quality of data stream.
Keywords: multimedia; cloud computing; large scale data flow; scheduling method
0 引 言
随着计算机以及网络技术的快速发展,多媒体数据的应用领域逐渐扩展。由于多媒体业务具有较高的计算复杂度,因而在云计算平台上部署这些业务具有较强的必要性[1?3]。云计算下的多媒体视频数据流具有实时性、随机性、数量多等特征,而多媒体应用要求支撑多媒体服务的云计算环境能够提供高质量的服务,而实现服务质量的关键是有效处理数据拥塞问题,因此寻求有效的大规模数据流调度方法[4?6],确保云计算环境下多媒体信息的正常运行,受到了相关学者的关注。endprint
当前,主流的云平台多媒体数据流调度方法主要如下:文献[7]提出的依据神经网络算法的调度方法。该方法较为简便,但容易出现调度冲突问题,调度效率大大降低;文献[8]分析了依据优化微粒群算法的调度方法,该方法虽然具有较高的调度效率,但是未充分考虑云计算下多服务器间的差异性,导致数据流调度结果存在较大的偏差;文献[9]分析的依据免疫遗传算法的调度方法,但是由于多媒体云计算下的数据流调度系统缺少变异过程,容易陷入局部最优,不能获取最佳的调度结果;文献[10]提出了最早结束标志优先调度算法,该种算法无法确保为每个任务提供端端延迟保证,具有较高的运算复杂度。
1 多媒体云计算下大规模数据流调度平台系统
框架
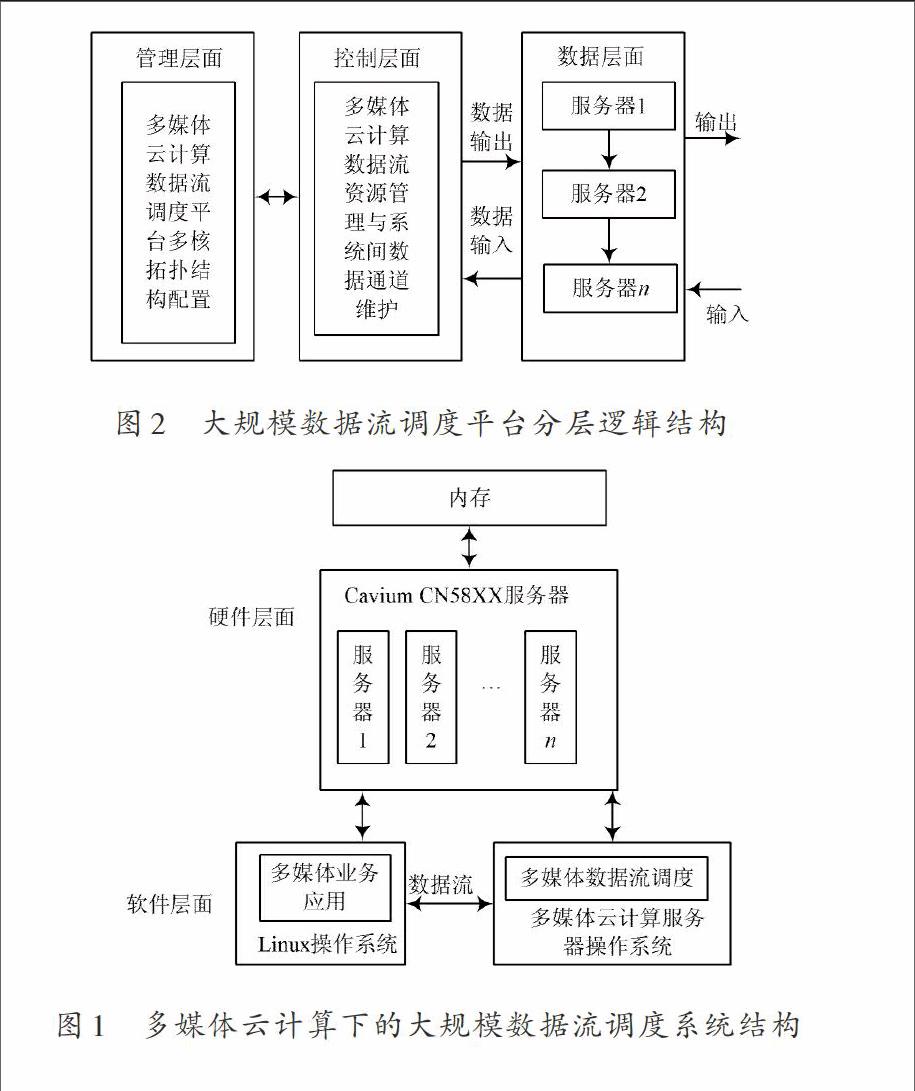
将CaviumCN58XX服务器当成多媒体云计算下大规模数据流调度平台的实现基础。CN58XX服务器中集成了14个同构服务器,各处理核具有独立的输入包分类以及加解密等协处理器单元,拥有高速多媒体数据流处理、转发性能,能够满足多媒体云计算下大规模数据流调度平台的性能需求。
基于CN58XX服务器的硬件结构,本文划分多媒体云计算环境下的底层硬件资源,塑造多媒体云计算下大规模数据流调度平台与硬件资源映射关系,获取调度平台在硬件层面的系统结构图如图1所述。
图1 多媒体云计算下的大规模数据流调度系统结构
分析图1可以看出,在数据流调度系统中,多媒体云计算下的资源包括两个部分,一部分服务器需要执行Linux操作系统,确保用户能够在Linux操作系统上运行多媒体视频流化的应用,产生流化数据,也就是多媒体数据流;另一部分服务器用来搭建多媒体云计算服务器操作系统,该系统可对调度平台的管理层面、控制层面和数据层面进行统一调控。
其中管理层面和控制层面对多媒体云计算系统的硬件资源进行调控,同时调度系统间的信令和数据的沟通。数据层面用于塑造大规模数据流调度,完成多媒体云计算下的大规模数据流的有效传递。Linux操作系统与多媒体云计算服务器操作系统都具备独立的硬件资源,两个系统间通过控制层面维护的数据通道实现信息的沟通,数据流通道将传递流化后的视频数据流,通过大规模数据流调度平台完成定时发送。
2 大规模数据流调度
多媒体云计算平台通过多个服务器完成大规模数据流的传递,数据流在服务器间进行并行处理时,容易出现资源冲突问题,导致出现服务器资源浪费以及数据流调度滞后等问题,所以应在云计算下的多服务器之间调度数据流,合理分配服务器资源。
云计算下的多个服务器间的数据包调度,是多媒体云计算下大规模数据流调度需要考虑的重要问题。因此,本文利用多级分层结构将多媒体云计算下的多服务器大规模数据流调度过程,划分成如图2所示的分层逻辑模型。该大规模数据流调度分层逻辑模型由管理层面、控制层面和数据层面组成,该模型可确保将数据包均匀的分配给各个服务器,充分发挥云计算下的多服务器可并行处理的特性。
图2 大规模数据流调度平台分层逻辑结构
管理层面:部署大规模数据流调度平台在数据层面的拓扑结构,对多媒体云计算环境中的硬件资源的分配进行调控。
控制层面:管理大规模数据流调度平台中的硬件资源,为每条数据流分配相应的硬件资源,对进入大规模数据流调度平台的数据流进行实时操作。控制层为Linux操作系统与多媒体云计算服务器操作系统间提供数据传递通道,确保数据流可通过Linux操作系统上的应用程序,传输到多媒体云计算服务器操作系数中的大规模数据流调度平台中。
数据层面:依据管理层面设置的拓扑结构,调控大规模数据流调度平台中的服务器,接收控制层面反馈的数据,确保大规模数据流的实时传输。
3 多媒体云计算下数据流调度软件设计
在塑造大规模数据流调度模型时,还应依据软件框架充分利用云计算平台中多服务器的硬件资源,实现大规模数据流的高效调度。
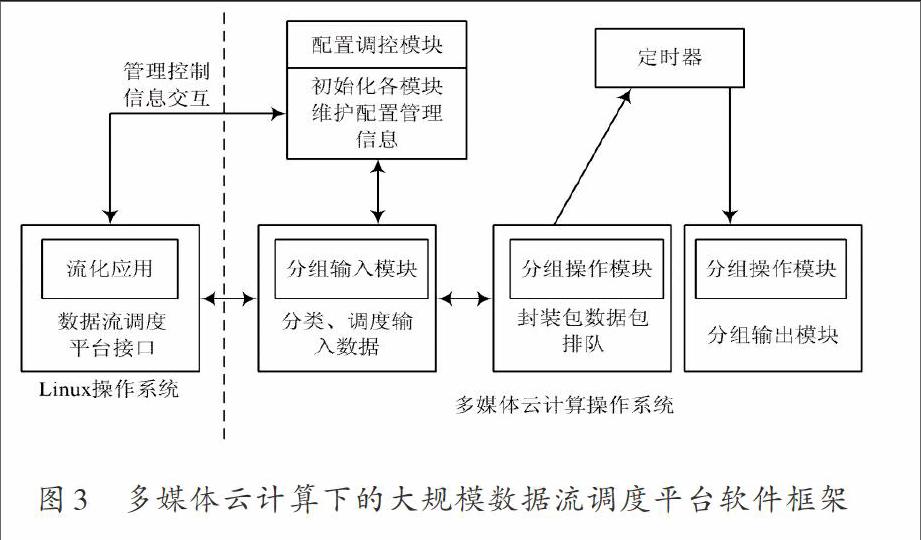
3.1 大规模数据流调度平台软件框架设计
根据分层结构塑造多媒体云计算下的大规模数据流调度平台的软件模型,并假设多媒体云计算下的网络使用视频点播系统流化数据,流化后的数据流具有严格的发送时间限制,则构建的大规模数据流调度平台软件框架,如图3所示。
图3 多媒体云计算下的大规模数据流调度平台软件框架
如图3所示,Linux操作系统与多媒体云计算操作系统并行运行于多媒体云计算环境中。在Linux操作系统上执行Dalwill多媒体视频点播系统,通过该系统流化后的视频数据采用大规模数据流调度平台接口,反馈到大规模数据流调度平台。
本文设计的大规模数据流调度平台主要由以下的软件模块组成:
配置调控模块对大规模数据流调度平台进行初始化设置,同时对节目流资源进行调控。分组输入模块采集多媒体云计算环境中的数据,并对数据进行分类过滤处理,再将处理后的数据传递到流化应用,分组输入模块接收流化应用反馈的RTSP和IP分组数据,并将数据传递到分组操作模块。
分组操作模块采集分组输入模块传输的数据,并在配置管理模块对应的内存中搜索节目流信息,将该信息当成数据包封装IP包头和以太网包头,生成以太网数据报,同时将数据报传递给分组输出模块;分组输出模块采集分组操作模块传递的以太网数据报,依据各数据包的发送时间将数据包传递到相应的网络端口。
大规模数据流调度平台中还包括定时器,大规模数据流调度平台需要将数据包传递给定时器,定时器在数据包到达发送时间后,将数据包传输到输出模块。
分组输出模块用于大规模数据流调度平台专用接口的流化应用以及实现大规模数据流调度中数据和信令间的交互。信令交互是实现ID申请/释放信息的交互,流化应用在开始发送一路新的节目流前,应通过大规模数据流调度平台专用接口申请新ID,流化应用基于新ID提交数据,区分不同的节目流。
3.2 软件代码设计
本文设计的多媒体云计算下的大规模数据流调度模型,采用全对称并行的体系结构,在每个云计算下的服务器上都部署相同的任务。在大规模数据流调度平台中这些任务包括数据流的预处理、协议栈加速和数据包发送等。全部服务器都能够接收流化后的数据,并对数据进行处理,再发送到指定的HMD上。本文采用伪代码描述各服务器上执行的任务流程:
while(l)
{
//数据包预处理过程
In_data?get_stream_data; //接收流化应用提交的数据包
If in data!=NULL //从流化应用接收到数据包
{
handle_data(i_data): //对数据包进行预处理
insert_data(in_data); //将数据包插入待加速队列,
//等待为数据包进行协议栈加速
}
//数据包协议栈加速过程
//轮询各HMD上的第Flow_stack个待加速队列
Flow_stack=Flow_ stack+l;
fo:i?1toHMD_num //依次轮询全部HMD上的待加速队列
{
//查询第i个Nlc上的Flow_quetle队列中是否存在需要加速数据
Paek_data=get_Flow_data(i,Flow_stack);
If Flow_data!=NuLL //获取需要加速数据包
{
//对数据包进行协议栈加速
Flowing_data(Flow_data);
//将各数据包插入待发送栈,伺机传递数据包
insert_data(Flow_data);
}
//数据包定时发送过程
//顺序查询各HMD上的第send_stack个待传递栈
send_stack=send_stack+1;
for1=1 to HMD_num //顺序查询全部HMD中的待传递栈
{
//查询第i个HMD上的send_stack队列中是否有待加速数据
send_data=get_send_data(i,send_stack);
if send data!=NULL //采集需要加速数据包
{
if send data //到达传递时间或者接近传递时间
{
//定时发送数据包
sending_data(send_data);
}
}
}
}
4 实验结果及分析
为了验证本文方法的有效性,塑造一个仿真实验系统进行验证。
4.1 实验参数设置
仿真系统由3个云计算下的服务器构成,各服务器采用3级流水线结构设置多媒体云计算下的多服务器拓扑结构。设置数据包在服务器间传递的时间消耗为8。实验使用由http://fown.uew.esr.edu/fownstck.html提供的实际影片数据帧信息,采用该影片模拟多媒体数据流。
4.2 实验结果
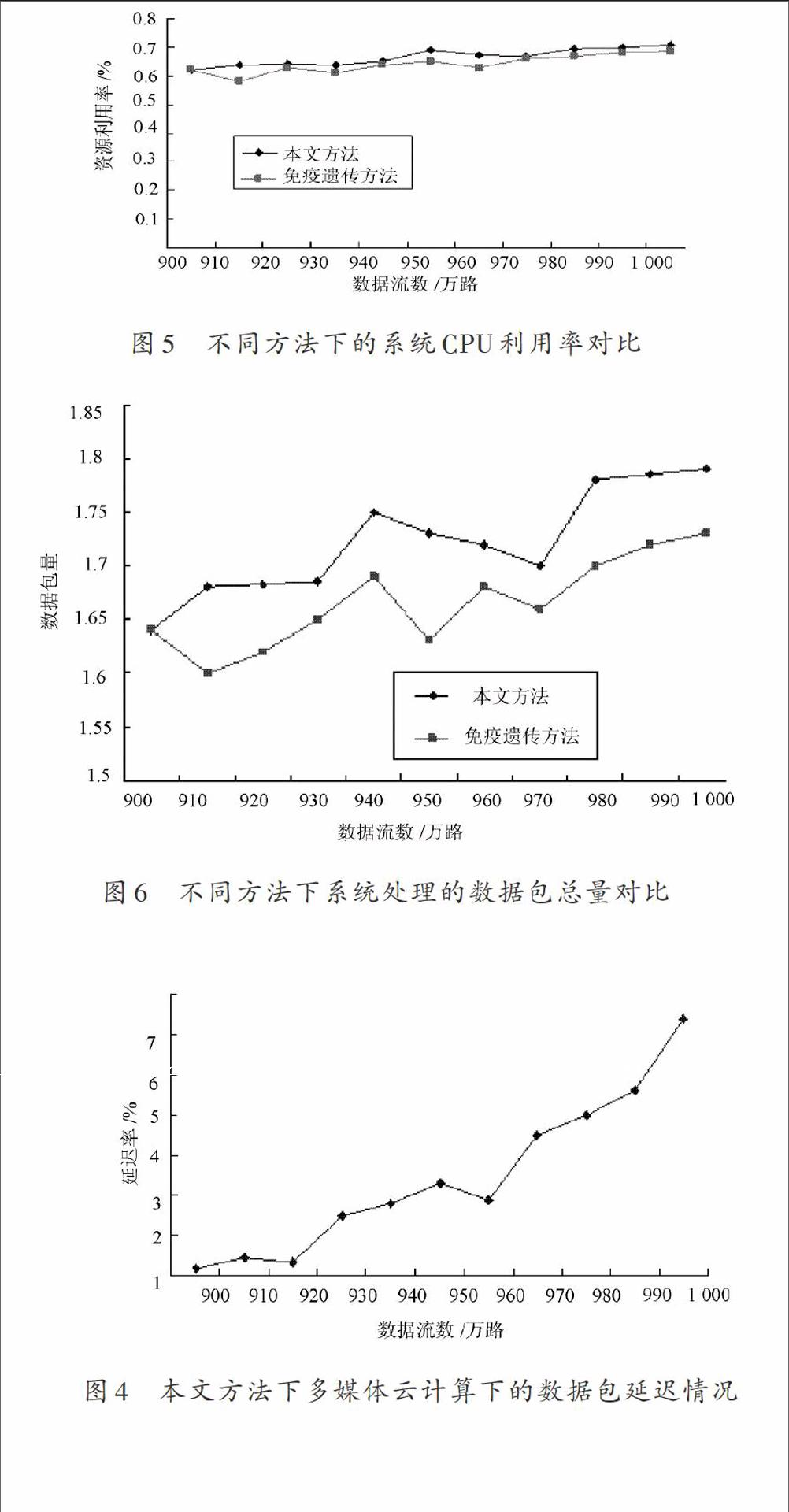
(1) 数据包延迟分析。本文方法对实验数据包发送延迟的影响,结果如图4所述。
图4 本文方法下多媒体云计算下的数据包延迟情况
分析图4可以发现,采用本文方法调度多媒体云计算下的大规模数据流过程中,数据包平均延迟率随着系统服务的数据流数量增加而升高,因为实验采用的影片信息流化后是多路数据流,导致系统服务器上的负载发生大幅度波动,容易形成数据包延迟发送问题。当系统中总数据流数少于950万路时,几乎没有数据包延迟发送,而当数据流数高于950万路低于1 000万路时,延迟发送的数据包增多,但是整体的数据包延迟率仍然较低,说明采用本文方法增强了多媒体云计算下大规模数据流调度的并发性能,提高数据流调度质量。
(2) CPU资源利用率。对比分析免疫遗传方法和本文方法下的多媒体云计算下的大规模数据流调度系统资源使用情况,如图5所示。图5中随着多媒体云计算系统中服务的数据流数量的不断增加,本文数据流调度方法下的多媒体云计算环境下的资源总体利用率在绝大部分情况下明显高于免疫遗传算法的整体利用率。
(3) 数据包调度总量。图6描述了免疫遗传方法和本文方法下系统调度数据包的总量对比,可以看出本文方法下系统调度数据包的总量明显高于免疫遗传方法,采用本文方法可有效地提高系统处理数据包的总数,增加多媒体云计算系统的并发量,提高系统的服务能力。
图5 不同方法下的系统CPU利用率对比
图6 不同方法下系统处理的数据包总量对比
5 结 论
本文通过构建多媒体云计算下数据流调度平台,实现对多路大规模多媒体数据流的合理调度,利用多级分层结构将多媒体云计算下的多服务器大规模数据流调度过程,划分成管理层面、控制层面和数据层面,确保将数据包均匀的分配给各个服务器,充分发挥云计算下的多服务器可并行处理的特性,增强数据流的调度质量。对调度平台的软件框架进行了详细的描述,依据该软件框架的多层次实现大规模数据流调度优化,分析了大规模数据流调度的具体实现过程,并给出大规模数据流调度平台软件代码的设计。实验结果说明,所提方法增强了多媒体云计算下的大规模数据流调度的并发性能,提高数据流调度质量。
参考文献
[1] 佚名.2013年中国互联网络发展状况统计报告[EB/OL].[ 2013? 01?08]. http://www.360doc.com/content/14/0604/09/9073112_383465777.shtml
[2] HARRINGTON Peter. Machine learning in action [M].北京:人民邮电出版社,2013.
[3] WANG Z, BAO Y, GU Y, et al. A BSP?based parallel iterative processing system with multiple partition strategies for big graphs [C]// Proceedings of 2013 IEEE International Congress on Big Data. [S.l.]: IEEE, 2013: 173?180.
[4] LAM Chuck. Hadoop in action[M].北京:人民邮电出版社,2013.
[5] 李伟卫,赵航,张阳,等.基于MapReduce的海量数据挖掘技术研究[J].计算机工程与应用,2013,49(20):112?117.
[6] 王元卓,靳小龙,程学旗.网络大数据:现状与展望[J].计算机学报,2013,36(6):1125?1138.
[7] 覃雄派,王会举,李芙蓉,等.数据管理技术的新格局[J].软件学报,2013,24(2):175?197.
[8] 陈崇成,林剑峰,吴小竹,等.基于NoSQL的海量空间数据云存储与服务方法[J].地球信息科学学报,2013,15(2):166?174.
[9] SAKR S, LIU A, FAYOUMI A G. The family of MapReduce and large scale data processing systems [J]. ACM Comput Surv, 2013, 46(1): 11?19.
[10] KANG U, FALOUTSOS C. Big graph mining: algorithms and discoveries [J]. ACM SIGKDD Explorations Newsletter, 2013, 14(2): 29?36.endprint
