基于规则引擎与空间聚类分析的多源地震灾情数据清洗策略研究1
2015-10-24郭红梅陈维锋
郭红梅 陈维锋 张 莹 申 源
(四川省地震局,成都 610041)
基于规则引擎与空间聚类分析的多源地震灾情数据清洗策略研究1
郭红梅 陈维锋 张 莹 申 源
(四川省地震局,成都 610041)
通过研究不同来源地震灾情数据汇集处理过程中的数据清洗技术,利用数据挖掘中基于规则引擎与空间聚类分析相结合的方法检测多源灾情数据存在的错误、不完整和重复等问题并进行修正,提高灾情数据质量。以清洗后的灾情数据为基础,运用ArcGIS空间插值对离散灾情点进行总体分析和模拟,从而快速反映并确定地震灾情的总体分布情况,为地震应急救灾工作提供更可靠、形象的灾情分布信息。文中以四川省地震灾情快速上报接收处理系统在四川省芦山“4·20”7.0级强烈地震中,通过多种灾情获取手段获取到的包括主观震感、客观震感、房屋破坏、交通系统破坏等共1330条灾情信息为例进行处理和分析,共检测出不合理灾情数据717条,其中剔除696条,修正21条,清洗后的灾情数据空间分布和模拟结果与实际考察形成的烈度圈吻合度良好。
多源地震灾情信息 数据清洗 规则引擎 信息融合 空间聚类
郭红梅,陈维锋,张莹,申源,2015.基于规则引擎与空间聚类分析的多源地震灾情数据清洗策略研究.震灾防御技术,10(4):892—901.doi:10.11899/zzfy20150407
引言
地震应急工作是一项准军事化行动,成败的关键在于能否在最短的时间内做出科学合理的决策并付诸行动(聂高众等,2012)。科学合理的决策需要正确灾情信息的支撑,因此,地震灾情信息的获取和处理是地震应急工作的关键环节。随着科学技术的发展,震后快速获取海量灾情信息变的可能,但由于灾情信息来源的多样性,获取到的原始灾情信息往往包含了大量的“脏数据”,譬如信息重复、不完整、逻辑错误等(苏桂武等,2003)。如何快速检测出灾情数据中存在的质量问题,提高灾情数据质量,是现阶段地震应急工作中急需解决的关键问题之一(白仙富等,2010)。
数据清洗是指使用一系列的逻辑规则或数据挖掘技术等多种方法从大量原始数据中检测出脏数据,并对脏数据采取修复或丢弃动作,从而提高数据质量的过程。目前,国外对灾害领域数据清洗的研究主要是通过引入数据挖掘方法,如应用聚类方法检测异常记录,模型方法发现不符合现有模式的记录,关联规则方法发现数据集中不符合具有高置信度和支持度规则的异常数据来检测并消除异常及近似重复记录等(王曰芬等,2007)。国内对数据清洗技术的研究起步较晚,针对地震灾情中的数据质量问题,有专家和学者采用了包括统计分析方法、简单的规则库、经典偶然误差处理模型等多种方法进行了部分数据的清理与校验。
四川省地震灾情快速上报接收处理系统的建成,使得在短时间内获得大量灾情信息成为可能(陈维锋等,2014)。本文以四川省地震灾情快速上报接收处理系统在四川省芦山“4·20”7.0级强烈地震中获取的多源灾情信息为例,通过对多源灾情数据存在的质量问题进行分析分类,采用Java规则引擎Drools并结合灾情数据的实际质量问题制定数据清洗规则,对各类灾情信息中的重复、不完整及不规范等记录分别进行初步检测与修正。并以数据量最大、记录覆盖面最广的主观震感为基础,结合在同一地点处的客观震感、房屋破坏、交通系统破坏情况等灾情信息进行多源灾情数据融合,分析它们之间的逻辑关系,制定业务规则,修正主观震感中的错误记录。本文中主观震感是指地震发生时人对震动的感觉。客观震感是指地震造成某一区域房屋破坏的总体概况。房屋和交通系统破坏是指房屋和交通系统的具体破坏情况。在此基础上,应用密度聚类分析方法对空间离散点进行聚类分析,弥补关联规则难以检测孤立点的不足,进一步检测并修正多源灾情数据中存在的错误,使其满足应急指挥决策分析对灾情数据质量的要求。最后,将修正后的空间离散灾情点投射到地图上,通过ArcGIS插值展示出灾情的总体空间分布情况,为应急救灾工作提供更可靠、形象的多源灾情信息支撑。
1 基于Java规则引擎的多源地震灾情数据清洗
以往基于规则的数据清洗方法通常将业务规则编译好后嵌入到系统代码中的不同位置,随着数据量及其复杂性的增大,需要回到需求阶段重新制定新的业务规则并重新编译,难以适应数据多源化的趋势(包从剑,2007)。而规则引擎可将业务逻辑从系统代码中分离出来,使规则可独立于系统进行灵活的配置和更新(郭志懋等,2012)。结合多源地震灾情信息中存在的质量问题,采用开源Java规则引擎Drools对其进行数据质量的检测及清洗。
1.1 Java规则引擎Drools工作机制
Drools是一个开源的业务规则引擎框架,以高效的模式匹配算法Rete为核心构建,实现了逻辑与数据的分离,提高了规则执行的效率(叶舟等,2011)。其通过检索提交到引擎的数据对象,如主观震感、客观震感、房屋破坏等,根据对象的当前属性值和它们之间的关系,从加载到引擎的规则文件中发现符合条件的规则,创建规则的执行实例,使实例在引擎接到执行指令时依照某种优先顺序依次执行。基本工作机制如图1所示。
工作区中存放被规则引擎引用的数据集,将事先编译好的业务规则导入静态规则区,规则执行队列将不断存储被激活的规则执行实例,当工作区中的数据对象发生改变后,引擎会迅速对规则执行队列中的执行实例做出调整和更新(潘巍等,2011;Payne等,2010),以适应数据多源性与多变的特点。
在进行数据质量检测时,Drools规则引擎通过调用规则文件来判断记录是否是脏数据,并做出保留、剔除或修正数据的动作,规则文件主要构成框架Java代码如下:

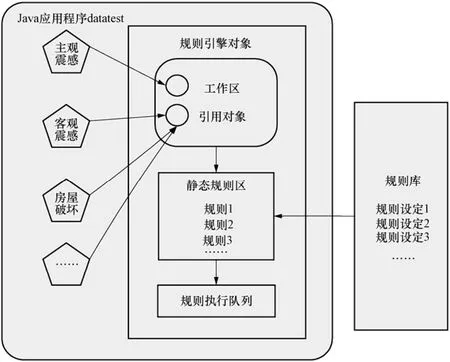
图1 Drools数据清洗工作机制Fig.1 Data verification mechanism of Drools
其中,规则集用<rule-set>标记,一个规则集可以包含多条规则<rule>,每个规则都有一个ID号和相应的清洗动作类型ruleTyPe。此外,规则中还定义了很多用<java:condition>标记的逻辑条件,这些逻辑条件之间是“与”或者“或”的关系。Drools规则引擎将根据这些逻辑条件动态地构建最优匹配树,高效地检测由<parameter>标记的数据是否符合逻辑条件,如果符合则触发<java:consequence>标记中的Java代码,不符合则不触发(曹永亮,2008)。在上述示例代码中,定义了记录被封装到Data 类中data表的ID字段如果不为空,即可通过data.setFlag(1)方法判定为初步干净的数据;反之,如果为空则应被剔除。可见,规则文件中包含了数据必须满足的清洗规则,每条规则由定义好的检测和清洗动作构成。
1.2 多源地震灾情数据清洗规则的制定
对应急指挥决策而言,灾情数据质量主要包括适用性和正确性两方面,其中灾情数据的适用性包括关键字段值完整、灾情记录不重复等。通过对各种来源的灾情信息可能存在的质量问题进行分析,可发现在正确性方面主要存在字段值不符合灾区实际受灾情况等错误,而在适用性上主要问题为缺少必要的字段值导致记录不可用、字段值不完整、重复记录等,需要分别制定业务规则进行检测和修正,形成规则文件后加载到规则引擎中运行。
(1)针对适用性的初步清洗规则
针对适用性方面的问题,对不同来源的灾情数据可分别制定独立的逻辑规则进行数据质量初步检测与清洗,下面以四川省地震灾情快速上报接收处理系统在芦山“4·20”7.0级强烈地震中获取的记录条数最多且具有代表性的主观震感进行规则制定示例。在主观震感(subtrem)中提取出了五个关键字段,分别是灾情发生地(area)、经度(longtitude)、纬度 (latitude)、震感级别(tremlevel)和时间(time)。其中,灾情发生地和经度(longtitude)、纬度(latitude)都是表示灾情的位置信息,灾情发生地字段完整或经度(longtitude)、纬度 (latitude)字段完整的就表示该条灾情的位置信息完整。主观震感数据质量初步检测与清洗规则如下:
①关键字段值缺失记录清洗规则
主观震感可用的前提是震感级别、位置信息和时间都完整。若某一条记录中震感级别、位置信息和时间中任一字段值缺失,该条记录就失去了实际应用价值,这种情况的记录应经过检测后剔除,以减少应用的复杂程度。程序结构框如图2所示。
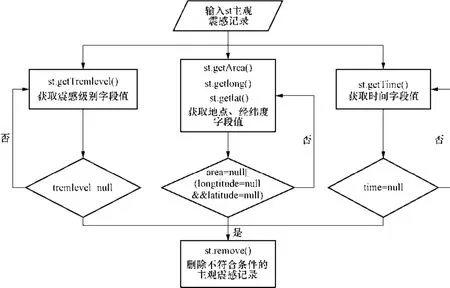
图2 关键字段值缺失记录清洗过程示例Fig.2 An example of verifying record due to missing of key characters
②关键字段值不完整记录清洗规则
主观震感灾情信息的震感级别和灾情发生地经纬度字段中还存在信息不完整和不规范的问题。例如在震感级别中只有对震感的主观性描述,没有按规范格式进行量化表示,不便于对震感级别的理解和归类,对于这类记录应将缺失的信息补充完整。而在灾情发生地经纬度字段中有一些明显超出四川省经纬度范围的记录,不符合规范,应根据灾情发生地字段的值修正到合理范围内。以震感级别不完整记录为例的清洗规则程序框图,如图3所示。
③重复记录清洗规则
主观震感记录中存在不少重复记录,主要是同一地点存在若干条震感信息。主要原因是部分灾报员不仅仅报了主震的震感,而且每次余震都上报了震感。这既造成数据量巨大,又影响对震感的总体判断。针对这种情况,对该次震害事件,只保留主震的震感信息,余震的震感信息剔除。由于四川省灾情快速上报接收处理系统震害事件的创建以主震为起点,不含前震,因此震感重复记录清洗的具体规则是根据时间轴,取该点第一次上报的震感信息。
(2)针对正确性的灾情数据清洗规则
在四川省地震灾情快速上报接收处理系统中,客观震感根据多位具有丰富现场灾评经验的专家经验设置,分为6个等级,具体描述如下:i看不到房屋破坏;ii房屋破坏不容易看到,要人带领;iii大部分房屋未倒塌,房屋破坏可以看到;iv少数房屋倒塌,房屋破坏很容易见到;v土木房一片废墟;vi砖房一片废墟,其中ii-vi级分别对应烈度VI-X。主观震感分为5个等级,分别描述如下:i无震感;ii仅仅有感;iii震感强,可行走;iv站立不稳,行走困难;v被地震摔倒。学校和医院房屋破坏分为3个等级,分别描述如下:i为完好,即墙体有少量裂缝或无破坏;ii为部分破坏,即房屋墙体有很多裂缝;iii为毁坏,即房屋倒塌或部分倒塌。
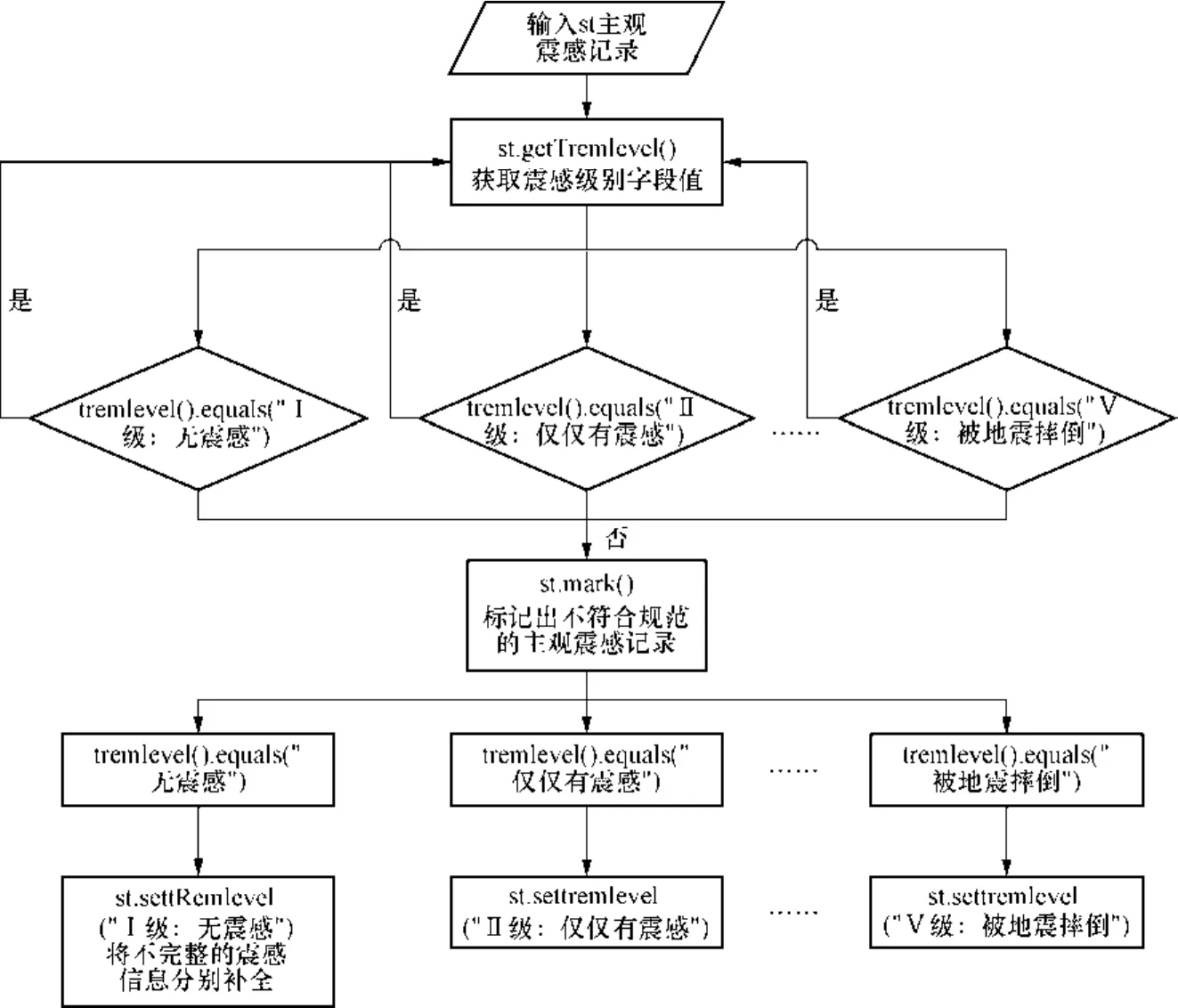
图3 关键字段不完整记录清洗过程示例Fig.3 An example of verifying record due to incompletion of key characters
农村房屋和城镇房屋破坏分级一致,具体描述如下:i完好,无房屋破坏或有少部分房屋被震裂;ii部分破坏,很多房屋被震裂或少量房屋倒塌;iii毁坏,很多房屋倒塌。交通系统破坏分三个等级,具体如下:i通行;ii通行困难;iii中断。根据GB/T 17742-2008《中国地震烈度表》中的人的感觉、房屋震害和其他震害现象的描述,主观震感对应烈度表中人的感觉一栏;学校、医院以及城镇房屋对应烈度表中的C类建筑物;农村房屋对应烈度表中的B类建筑物;交通系统破坏根据烈度表中其他震害现象的描述来对应。依据烈度表对地震烈度信息的具体描述,获得这几类灾情信息横向和纵向逻辑对应关系如表1所示。
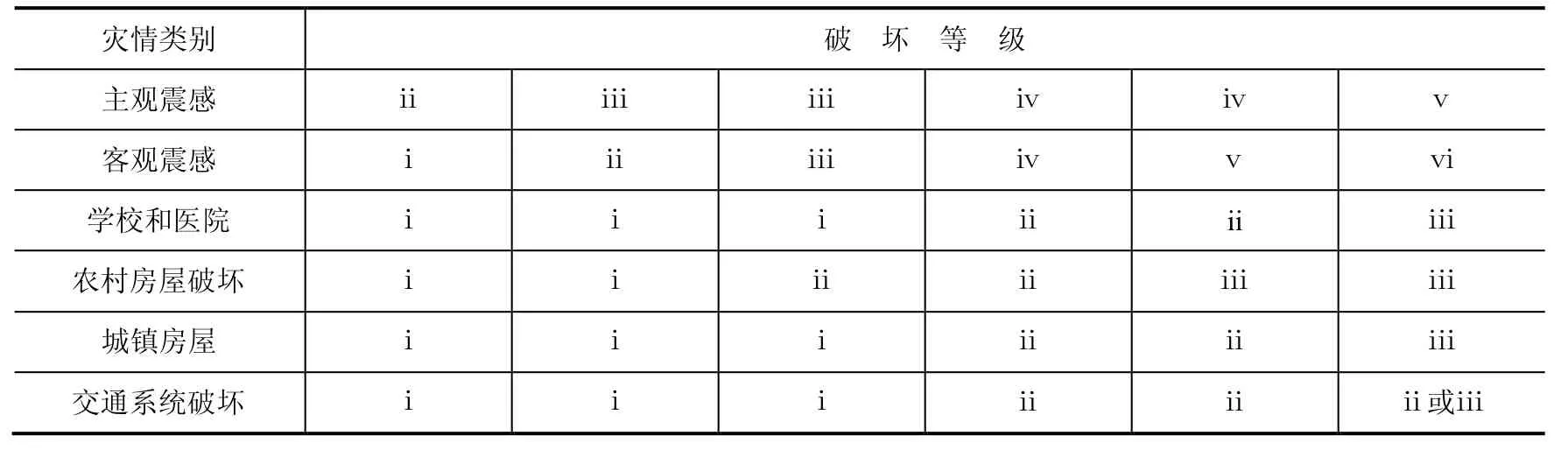
表1 多源地震灾情信息对应关系表Table 1 Correlation of multi earthquake hazard information
在表1中,各类灾情信息的破坏等级之间形成了纵向上的对应关系,本文选取主观震感为基准进行灾情数据初步清洗后的信息融合,即当同一地点的客观震感(objtrem)、房屋破坏(houbroken)、交通系统破坏(trabroken)等破坏等级满足其中某一列的条件时,即可通过规则制定。利用融合后的数据检测主观震感的错误,当主观震感的级别值缺失时还可以进行填充。例如若某一灾情发生地的客观震感为ii级,农村房屋破坏、城镇房屋破坏、交通系统破坏和学校医院破坏等级均为i级,那么该地的主观震感的合理取值应为iii级,该清洗规则程序结构框图,如图4所示。
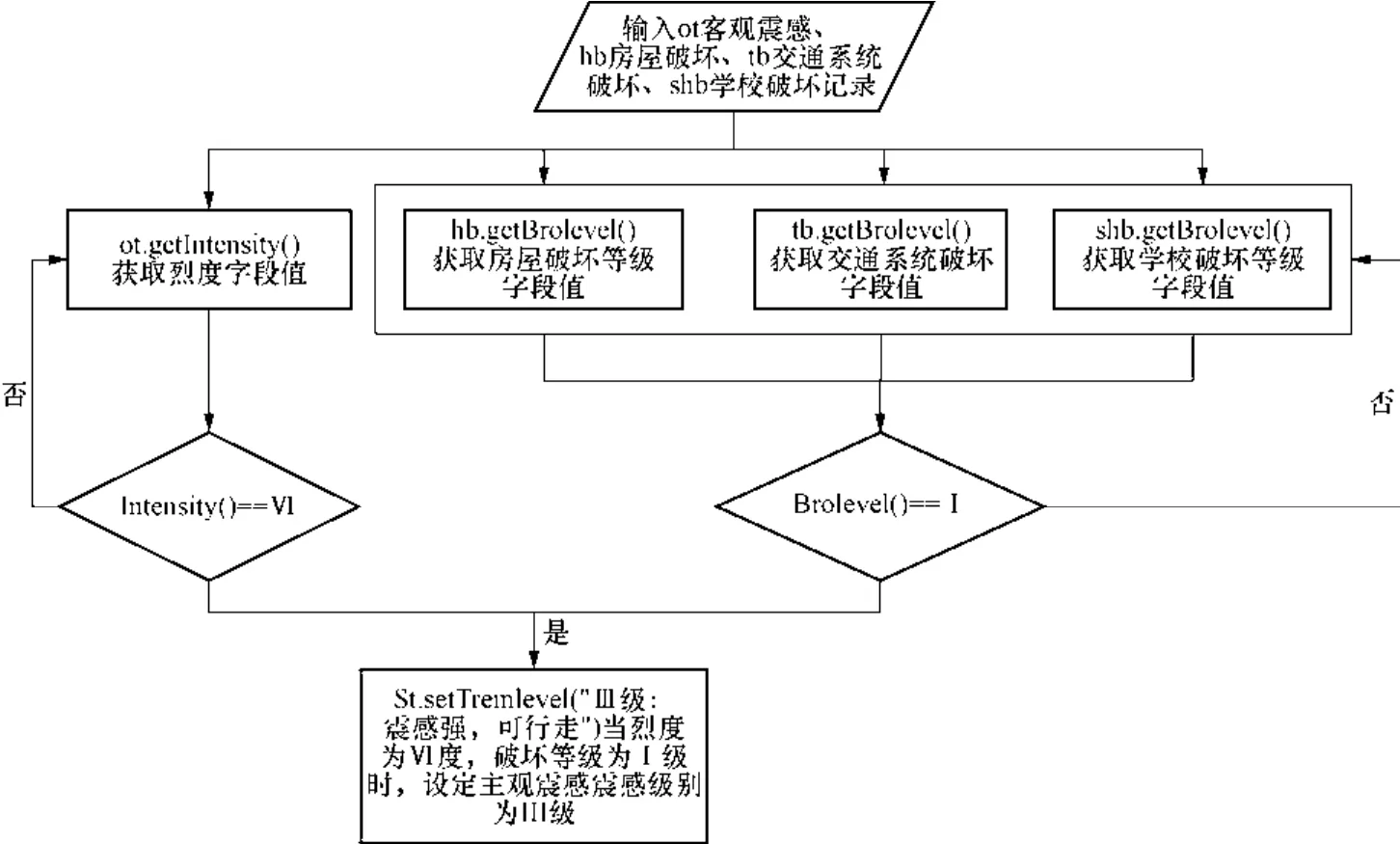
图4 利用几类灾情数据融合针对震感正确性的清洗过程示例Fig.4 An example of verifying record by using multi hazard data sources
将清洗规则集成为规则文件后,加载到Drools规则引擎中即可快速运行配置好的规则文件,初步检测和修正多源灾情数据中的质量问题。
2 基于空间聚类技术的多源灾情数据修正
上述使用的关联规则方法不易受数据分布的影响,虽能检测出多源灾情数据中大部分的异常记录,实验证明具有强壮性,但很难发现一些孤立点存在的异常,而聚类算法在这方面具有较好的检测效果(Ester等,1996)。因此,考虑相关联的几类灾情信息之间的逻辑或约束关系,建立一种适合空间离散点灾情信息的聚类分析算法,可进一步检测经过规则筛选的灾情数据,剔除异常点。
2.1 空间聚类算法原理与改进
聚类分析是依据样本间度量标准将其自动分成几个群组,且使同一群组内的样本相似,不同群组的样本相异的一种数据分析方法(程显洲等,2013)。在各类地震灾情信息中都包含了灾情发生地及其经纬度的空间信息,所以,利用聚类分析法进行数据清洗时必须考虑这些空间属性。而密度聚类DBSCAN是最常用的空间聚类算法,在其执行过程中定义一个空间半径Eps和一个密度阈值MinPts,如果某个空间对象p的Eps邻域内点密度超过MinPts,则将p作为群组中心,然后不断搜索从p到直接密度可达的点,将寻找到的点加入该群组中,当没有新的点可以被添加到任何群组时聚类结束,未被归入任何群组的点即为噪声点(聂跃光等,2008;鲁小丫等,2012)。
基于上述原理,可在空间聚类的过程中加入与灾情属性密切相关的烈度值为参照,将烈度椭圆作为空间搜索半径,改进DBSCAN算法,对包含空间信息的离散点灾情属性进行检测与修正。根据中国地震烈度区划中的烈度回归模型,可得出西南地区地震烈度衰减关系:
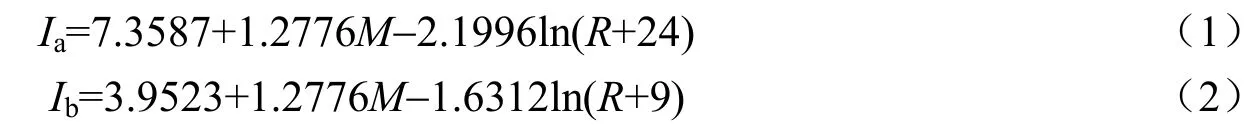
式中,M是震级;R是震中距;I是烈度;a、b分别为椭圆长轴方向和短轴方向。
将DBSCAN的空间邻近Eps扩充为长轴邻近Eps1和短轴邻近Eps2,分别对应与烈度衰减关系相应的烈度椭圆长轴和短轴:
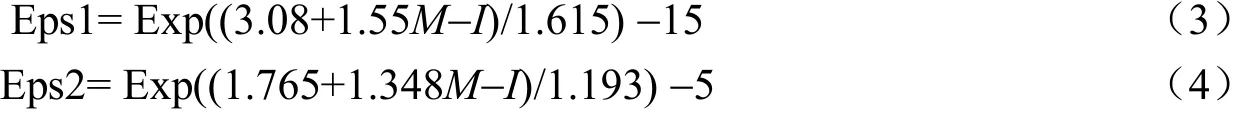
改进后的算法过程如图5所示。

图5 改进后的空间聚类算法流程图Fig. 5 Flow chart of improved spatial clustering algorithm
2.2 多源灾情数据清洗空间聚类算法实现
根据算法流程,在编程实现算法的过程中为防止出现循环判定核心点和噪声点,需从任意对象开始根据MinPts和Eps1、Eps2值判断其邻域内是否存在核心点时,将经过此步骤判断的所有对象标记为“已使用”。此外,在聚类过程中只考虑对象Eps1-2邻域内点的数目,简化了密度定义。改进后的空间聚类算法部分核心代码如下:

算法执行后,可输出地震灾情数据的聚类分析结果,获得更准确的灾情信息。
3 实验结果及对比
本文以四川省地震灾情快速上报接收处理系统在四川省芦山“4·20”7.0级强烈地震中,通过多种灾情获取手段获取到的包括主观震感、客观震感、房屋破坏、交通系统破坏等共1330条灾情信息为例进行处理和分析,其中,采用基于Java规则引擎的多源灾情数据清洗方法通过初次规则筛选共剔除“脏数据”696条,其中主观震感剔除660条,客观震感剔除17条,学校破坏剔除3条,医院破坏剔除2条,城镇房屋破坏剔除7条,农村房屋破坏剔除5条,交通系统破坏剔除2条。
将经过初次清洗的多源灾情信息以主观震感为基准,结合客观震感、房屋破坏、交通系统破坏和学校医院破坏等灾情信息进行基于规则的数据融合,修正主观震感信息18条,补充主观震感信息3条。以四川省雅安市天全县城厢镇为例,该镇各类灾情信息如表2所示,根据各类灾情信息间的逻辑关系,制定规则检测出上述记录主观震感的震感级别信息是有误的,应为Ⅵ级。为此,通过对多源灾情信息的融合,利用规则引擎进一步对以主观震感为基础的灾情信息中有误的记录进行了检测和修正。

表2 城厢镇各类灾情信息列表Table 2 List of earthquake hazard information of Chengxiang town
针对孤立点存在的异常,通过执行改进后的基于密度的空间聚类算法结果如图6所示。
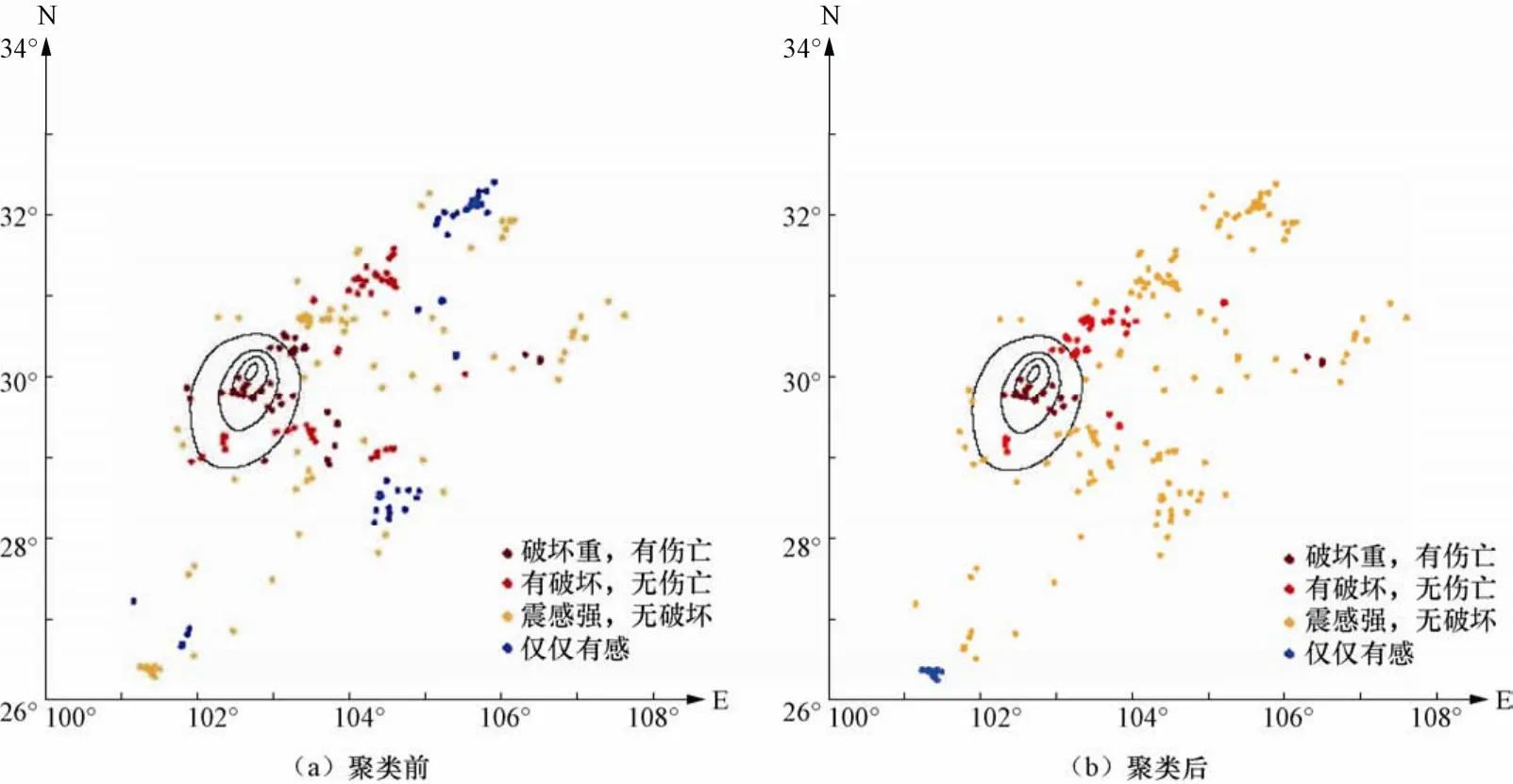
图6 震感信息空间聚类图Fig.6 Spatial clustering result of feeling information
为了便于宏观灾情分布的描述,此处将主观震感的级别描述进行了映射,即“iii 震感强,可行走”映射成“震感强,无破坏”;“iv站立不稳,行走困难”映射成“有破坏,无伤亡”;“v被地震摔倒”映射成“破坏重,有伤亡”。经过规则筛选后,未进行空间聚类的主观震感分布如图6(a)所示,空间聚类后的分布如图6(b)所示,比较两次结果可发现,通过空间聚类分析,灾情点的分布更符合中国地震局发布的“4·20芦山7.0级”地震烈度图(中国地震局,2013)中烈度圈的走向和范围,结果与实际受灾情况更加吻合。
为更直观地展现清洗前后的灾情分布情况,对灾情进行了总体分析和模拟,利用ArcGIS空间分析中的Delaunay三角插值对原始的主观震感信息和经过清洗后的灾情信息离散点分别进行空间插值(帅向华等,2009),结果如图7所示。
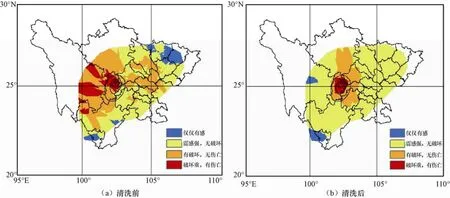
图7 灾情信息空间分布插值对比图Fig.7 Comparison of hazard information spatial distribution after interpolation
从图7可以看出,原始灾情数据在表达实际的受灾程度方面存在一些错误,而经过清洗后的灾情数据能更好地反映实际的受灾情况,在数据不足时,可通过插值拟合出基本符合实际的地震灾情分布。
4 结论
本文应用规则引擎与空间聚类相结合的方法分阶段清洗了四川省芦山“4·20”7.0级强烈地震的原始多源灾情数据。通过规则引擎对各类灾情信息进行了初步检测与修正,并将多源灾情信息融合后,利用同一地点的其他灾情信息辅助判断其主观震感的正误;加入烈度信息,改进了密度聚类算法,进一步修正了原始灾情信息中的错误,使结果更准确地反映出实际受灾情况。今后的研究将更加注重多源灾情信息的实时性,通过增量式检测等手段提高算法效率及准确度。
白仙富,李永强,陈建华等,2010.地震应急现场信息分类初步研究.地震研究,33(1):111—118.
包从剑,2007.数据清洗的若干关键技术研究.南京:江苏大学.
陈维锋,郭红梅,张翼等,2014.四川省地震灾情快速上报接收处理系统.灾害学,2(29):110—116.
曹永亮,2008.基于Java规则引擎的动态数据清洗研究与设计.武汉:武汉理工大学.
程显洲,肖兰喜,董翔,2013.基于烈度衰减椭圆阈值空间散点聚类研究.灾害学,10(28):205—208.
郭志懋,周傲英,2012.数据质量和数据清洗研究综述.软件学报,13(36):105—108.
鲁小丫,宋志豪,徐柱,2012.利用实时路况数据聚类方法检测城市交通拥堵点.地球信息科学学报,12(6):775—779.
聂高众,安基文,邓砚,2012.地震应急灾情服务进展.地震地质,4(3-4):782—791.
聂跃光,陈立潮,陈湖,2008.基于密度的空间聚类算法研究.计算机技术与发展,8(8):91—94.
潘巍,李战怀,聂艳明等,2011.一种有效的多数据源RFID冗余数据清洗技术.西北工业大学学报,29(3):435—442.
苏桂武,聂高众,高建国等,2003.地震应急信息的特征、分类与作用.地震,23(3):27—35.
帅向华,侯建盛,刘钦,2009.基于地震现场离散点灾情报告的灾害空间分析模拟研究.地震地质,31(2):321—332.
王曰芬,章成志,张蓓蓓等,2007.数据清洗研究综述.现代图书情报技术,(12):50—56.
叶舟,王东,2011.基于规则引擎的数据清洗.计算机工程,6(33):51—54.
中国地震局,2013.四川省芦山“4·20”7.0级强烈地震烈度图.[EB/OL] http://www.cea.gov.cn
Ester M., Krigel H., Sander J. and Xu X.A., 1996. Density-based algorithm for discovering clusters in large spatial databases with noise. KDD-96 Proceedings, 226—231.
Payne H. and Knoel H., 2010. Development and testing of incident-detection algorithm. Research Methodology and Detailed Results, FHWA-RD-06-20.
Multi-source Earthquake Disaster Data Verification Strategy Based on Rules Engine and Spatial Clustering Analysis
Guo Hongmei, Chen Weifeng, Zhang Ying and Shen Yuan
(Earthquake Administration of Sichuan Province, Chengdu 610041, China)
In order to improve the quality of multi-source earthquake disaster data, the rules engine and spatial cluster analysis combined method of data mining is used to detect mistakes such as error, incomplete and repeated in multi-source earthquake disaster data. After that, ArcGIS spatial interpolation is applied to the overall analysis and simulation of discrete earthquake disaster points, so that we can determine the general distribution of earthquake hazard rapidly, and provide reliable hazard distribution information for earthquake emergency relief work. In this paper we processed and analyzed 1,330 multi-source earthquake disaster items of data including subjective feeling,objective feeling, houses damage, transportation system damage and so on, which were obtained immediately after“4·20 Lushan MS7.0 strong earthquake” by the Sichuan Earthquake Quickly Receiving and Processing System. Totally 717 unreasonable disaster items were selected by the multi-source earthquake disaster data cleaning strategy,in which 696 items was eliminated and 21 items were corrected. The spatial distribution and simulation results of verified data shows to fit well with the actual seismic intensity regions determined from field investigation.
Multi-source earthquake disaster information; Data verification; Rules engine; Information fusion; Spatial clustering
2015年度地震科技星火计划项目(XH15039Y)
2015-02-03
郭红梅,女,生于1984年。硕士,工程师。主要从事地震应急和灾情信息处理研究。E-mall:115453242@qq.com
