基于用户兴趣模型的Nutch个性化搜索引擎研究
2015-10-21蒋翀费洪晓张啸
蒋翀 费洪晓 张啸
摘 要: 针对目前主流搜索引擎个性化程度低的问题,通过分析用户的浏览行为和浏览内容来获取用户的兴趣类别以及关键词,用一组带权重的关键词组成的向量集来表示用户兴趣模型,利用更新算法对模型进行更新与优化。将用户兴趣模型与开源搜索引擎Nutch相结合,加入中文分词组件IKAnalyzer,实现了个性化搜索引擎。进行了传统搜索和个性化搜索对比实验,结果证明,Nutch个性化搜索引擎结果更符合用户兴趣。
关键词: 用户兴趣模型; 个性化; 搜索引擎; Nutch
中图分类号:TP393 文献标志码:A 文章编号:1006-8228(2015)09-26-03
Research of personalized search engine based on user profile
Jiang Chong1, Fei Hongxiao2, Zhang Xiao2
(1. Modern Education Technology Center, HunanWoman's Vocational University, Changsha, Hunan 410004, China;
2. School of Software, Central South University of China)
Abstract: In order to improve the degree of personalization for popular search engine, the user's interest categories and keywords were got by analyzing user's browsing behavior and content. User profile was represented by a vector set which consisted of a set of weighted keywords and updated by correlated algorithm. By embedding in user profile and IKAnalyzer, Nutch became a personalized search engine. Comparative experiments were carried out with the traditional search and the personalized search. The results show that, the personalized search engine got more relevant result with user interest than traditional research engine and was proved to be effective.
Key words: user profile; personalized; search engine; Nutch
0 引言
飞速发展的互联网在带给人们海量信息的同时,也产生了难以让用户快速准确获取有效信息的问题[1]。目前,占市场主导地位的搜索引擎查询结果仅仅跟用户输入的关键词有关,并未考虑在相同关键字中所隐藏的用户个性化需求。这一类的搜索引擎以自动抓取信息和自动排序查找为主要特征[2]。目前,主流的搜索引擎均未实现面向客户需求和兴趣的个性化搜索。在这种情况下,个性化搜索引擎的研究和发展逐渐兴起。在这一代的搜索引擎中,公认的应该具备的特征是个性化和智能[3]。
为了根据用户需求和兴趣产生搜索结果,搜索引擎需要以用户兴趣模型的构建为基础。本文中采用隐式反馈的方式,通过分析用户的浏览行为和浏览内容,获取用户的兴趣类别和关键词,用一组带权重的关键词组成的向量集表示用户兴趣,利用更新算法对模型进行优化,使用户模型的构建能在指导的条件下进行,实现智能化的搜索。在个性化搜索引擎的实现部分,以Lucene为基础,使用Nutch实现了个性化搜索引擎,以此为实验平台,验证了用户兴趣模型的有效性。
1 用户興趣模型的建立和应用
通常来说,个性化搜索引擎的结果取决于用户兴趣模型的表示,所以,用户兴趣模型的构建在个性化搜索引擎研究和实现中十分关键[4]。
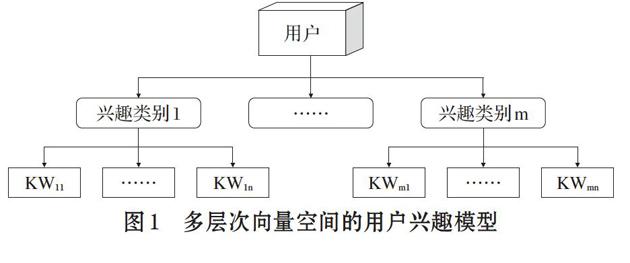
本文在传统向量空间的基础上,使用一种改进的多层次向量空间模型表示用户兴趣。由于用户兴趣的多样性,对用户的兴趣进行类别划分,可有效减少不同类别之间的相互干扰,提高检索的准确度。具体来说,就是“用户→兴趣类别→兴趣词条”的层状树型结构,如图1所示。
[用户][兴趣类别1][KW11][……][KW1n] [……][兴趣类别m] [KWm1][……][KWmn]
图1 多层次向量空间的用户兴趣模型
在图1中,第一层是用户,第二层是兴趣的类别,第三层由用户兴趣的词条组成。假设有m个领域是用户感兴趣的,那么兴趣模型(Interest Profile)也可以用以下向量来表示:
IPro={(C1,H1,Q1,T1),(C2,H2,Q2,T2),…,(Cm,Hm,Qm,Tm)}
其中,(Ck,Hk,Qk,Tk)是用户的第k类兴趣的节点,Ck表示兴趣类别的名称;Hk表示类别的权重,是对Ck类的所有样本的兴趣程度的乘积。Qk表示的是样本的数量,Tk表示的是兴趣词条的列表。
如果Ck 类有n个兴趣的词条,那么Tk可以表示为:
Tk={(KWk1,WTk1),……(KWkn,WTkn)}
其中,(KWkn,WTkn)是第n个词条,KWkn是关键词,WTkn是它的权重。
用户兴趣模型构建之初,需要主动输入一些兴趣类别,这部分主要是用户的稳定兴趣。在使用过程中,搜索引擎需要具备隐式获取用户兴趣的能力,自动处理用户兴趣模型的更新。根据人类的行为和心理特征,将用户兴趣分为实时兴趣和稳定兴趣,分别指代用户短期内和长期不变的兴趣倾向。
用户实时兴趣主要从用户短期内所访问的页面获取。假设用户在一天内访问了w个页面,那么可以使用m维的向量Ptd来描述这一天的兴趣:
ptd=(,,…… ,)
其中,每一项可表示为:
=
用户的稳定兴趣可以通过用户n天内的访问历史来获取,在本文中,将n的值作为天数窗口尺度,定义了Sj为用户在前j天浏览的页面数,其中s0表示的是用户当天浏览的页面数。在此基础上,通过设置窗口的尺度n来构造用户的稳定兴趣模型,在这里将n定义为60。与构造Ptd相类似,用一个m维的向量来表示用户的稳定兴趣,具体表示如下:
psd=(,,…… ,)
根据以上分析,公式中每一项可表示为:
=
其中,是衰减因子,表示稳定兴趣的遗忘速率,正如人的大脑会遗忘事情一样,用户稳定兴趣中的元素权值也会随着时间的流逝而有所下降,所以说用户模型中的衰减因子的应用保证了模型的时间可靠性。在此遗忘因子中,hl是生命周期参数,根据经验,人所接受的新知识一般都在一周后便开始遗忘,所以将hl的值设置为7;din表示关键词t(k)第一次出现的日期,d表示当前日期,d-din表示的就是关键词tk在模型中存储的天数,也就是用户对其感兴趣的天数。最后,由于用户每天访问的页面数量不等,通过每天访问的页面总数Sn对其规范化。
随着用户访问网络时间的累积,所访问页面数量的持续增加,用户稳定兴趣模型会自动进行更新。结合用户实时兴趣,可构成用户的兴趣模型,表示如下:
P= a×ptd+c×b×psd
其中,a+b=1,c是一个常量,定义如下:
其中,dur表示用户花费在每个关键词上的平均时间,通过初步实验分析研究,本文确定阈值Th=0.317。
Web页面与用户兴趣模型一样,都可以用向量空间表示,所以也就能运用向量的相似度计算来对它们进行统一处理。假设页面ri是使用搜索引擎查询到的第i个页面,用户兴趣模型P与ri的向量形式的相似度计算方法公式表示如下:
利用这个公式可计算出搜索引擎查询到的页面ri 与用户兴趣模型P之间的相似度。也就是说,搜索引擎得到一般搜索结果后,可以按照相似度大小对检索结果进行降序排列并显示,从而达到个性化搜索的目的。
2 基于Nutch的个性化搜索引擎实现
与一般的搜索引擎类似,Nutch最主要的两大功能是爬取跟查询。Nutch中爬虫的主要职责是从网络上爬取web页面并且建立数据结构良好的索引。查询则是根据用户的查询关键词返回符合要求的网页[5]。由于Nutch的中文分词采用默认的单字切分,这会直接影响到检索结果的排序和检索的效率,以及準确度,所以本文在Nutch中加入了IKAnalyzer中文分词组件。
个性化搜索引擎的关键就是高质量、高精度的用户兴趣模型应用到普通的搜索引擎中去[6]。引擎匹配模块就是基于此原理来发挥作用的,计算用户搜索到的网页文本跟用户的兴趣的相关度,并且进行排序。本文编写了Java代码实现了用户兴趣模型中用户兴趣的提取。具体来说,首先构建一个对象,实现映射,打开建立好的索引文件,新建爬虫对象,得到最基本的用户兴趣类别;然后根据用户的输入关键词,得到匹配结果链表,返回与查询关键词相匹配的兴趣类别;接着对得到的兴趣类别赋予权值,得到兴趣类别的关键词链表,并输出;最后,返回提取的用户兴趣。
个性化搜索引擎的接口界面是提供给用户检索并且返回查询结果的地方,也是直接给用户提供服务的地方,所以简洁、方便是最基本的要求。最后实现的个性化搜索引擎界面采用Nutch系统自带的页面,如图2所示。
图2 个性化搜索引擎界面
3 实验结果
实验中需要先根据用户兴趣模型得到用户兴趣类别。通过索引得到的文本文档存放在/nutch-1.2/vipcrawl下,vipcrawl是通过nutch自带的爬虫爬取同一目录下的vipurls.txt得到的。vipurls.txt中存放了一百个左右网页比较多的网站的链接,爬取深度为2,得到的页面具有代表性。分析了用户的浏览行为和内容之后,对网页进行文本分类的结果如表1。
表1 对网页进行文本分类的结果
[主题类别\&文档总数T\&查准数N1\&查错数N2\&查准率P\&足球\&300\&245\&55\&0.817\&IT\&800\&756\&44\&0.945\&手机\&200\&175\&25\&0.875\&旅游\&600\&564\&36\&0.940\&]
表1中,P=N1/T。完成了对文本的分类之后,所分成的主题类别就是用户的兴趣类别所在。由于网页的兴趣度已经计算出来了,所以可以根据公式得到用户每个兴趣类别的权重,计算出的结果如表2。
表2 用户兴趣类别及权重
[用户兴趣的类别\&权重\&足球\&0.32\&IT\&0.26\&手机\&0.17\&旅游\&0.09\&]
由此可以得到具体用户的兴趣模型,模型的形象化表示如图3所示。
[用户][足球(0.32)][英超
10.85][德甲
5.65][西甲
3.26] [IT(0.26)][手机(0.17)] [苹果
12.36][三星
8.36][小米
6.32]
图3 用户兴趣模型的图形表示
图3中,在每个兴趣类别下,有若干个兴趣词条,是用“关键词(其权重)”来表示的。从图3模型中可以看出,用户最感兴趣的三个领域分别是“足球”、“IT”、“手机”。其中在“足球”这个类别中,描述用户兴趣的关键词分别是“英超”、“德甲”、“西甲”,关键词“英超”所占的比例又是最大的。
在实验中,输入的关键词与预期的与用户兴趣相关的内容如表3。
表3 预期的用户兴趣相关的搜索结果
[关键词\&预期的与用户兴趣相关的内容\&安德森\&与英超球员安德森相关的内容\&苹果\&与苹果产品和公司相关的内容\&小米\&与小米公司和产品相关的内容\&小跳蚤\&与巴萨球星梅西(绰号小跳蚤)相关的内容\&]
分别根据以上四个关键词进行个性化搜索和百度搜索,根据表3,统计每个关键词每次搜索结果的前30个页面是否与用户兴趣相关,得到的搜索结果对比如图4所示。
图4 百度搜索与Nutch个性化搜索结果对比
从图4结果对比可以看出,基于用戶兴趣模型的Nutch个性化搜索引擎获得了更多的符合用户兴趣的搜索结果。在百度搜索的前30个结果中,符合用户兴趣的分别占到了10%,30%,96.7%和10%;在Nutch个性化搜索的前30个结果中,符合用户兴趣的分别占到了60%,60%,100%和100%。通过实验证明,个性化搜索引擎能够在一定程度上提供更符合用户兴趣的搜索结果。
4 小结
本文以用户兴趣模型的构建作为切入点和研究重点,建立了分层的向量空间模型表示用户兴趣,构建了Nutch个性化搜索引擎,实现了引擎匹配模块与搜索接口模块。在实验中,使用百度搜索引擎和Nutch个性化搜索引擎,针对相同的关键字分别进行页面搜索,根据预期的用户兴趣相关内容,对搜索结果进行分析和比较。实验结果证明,构建的用户兴趣模型可以在一定程度上达到个性化搜索的目的,验证了用户兴趣模型的有效性。但是,在研究过程中,还存在着一些需要改进和完善的方面。这主要包括:用户兴趣模型中信息的隐式获取需要更高效的方式;搜索结果的个性化程度还需要进一步提高;用户兴趣更新的有效性需要更长期和频繁的实验来证明。所以,在下一步的工作中,将针对所发现的问题,对个性化搜索引擎的核心——用户兴趣模型进行优化,设计和进行更长期、更高频次的实验,对用户兴趣更新的有效性进行验证,进一步提升搜索引擎的个性化程度。
参考文献:
[1] 费洪晓,莫天池,秦启飞等.社交网络相关机制应用于搜索引擎的研究综述[J].计算技术与自动化,2014.33(1):1-9
[2] Lu D, Li Q. Personalized search on Flickr based on searcher's preference prediction[C]//Proceedings of the 20th international conference companion on World wide web. ACM,2011:81-82
[3] 袁柳,张龙波.个性化搜索中的用户特征模型研究[J].计算机工程与应用,2011.47(15):19-24
[4] 李清华,康海燕,苑晓姣等.个性化搜索中用户兴趣模型匿名化研究[J].西安交通大学学报,2013.47(4):131-136
[5] 丁兆贵,金敏.基于Lucene的个性化搜索引擎研究与实现[J].计算机技术与发展,2011.21(2).
[6] Kim H N, Rawashdeh M, Alghamdi A, et al. Folksonomy-basedpersonalized search and ranking in social media services[J]. Information Systems,2012.37(1):61-76
