基于密度聚类的K近邻法在储层流体识别中的应用
2015-10-17卢一凡李宗杰柳建华
赵 军,卢一凡,李宗杰,柳建华
(1.西南石油大学地球科学与技术学院,四川成都610500;2.中石化西北油田分公司,新疆乌鲁木齐830013)
基于密度聚类的K近邻法在储层流体识别中的应用
赵 军1,卢一凡1,李宗杰2,柳建华2
(1.西南石油大学地球科学与技术学院,四川成都610500;2.中石化西北油田分公司,新疆乌鲁木齐830013)
针对传统储层流体识别方法识别精度低、运算量大、过于依赖个人经验的缺点,提出基于密度聚类的K近邻法,根据待测层段测井数据的空间分布规律,将样本按相对密度聚类成数据簇,并利用K近邻投票获得各簇所属类别。将该方法应用在某油田奥陶系鹰山组碳酸盐岩储层识别中。结果表明,较之其他常用识别方法,该算法识别精度高,泛化性和鲁棒性强,在处理大数据分类问题时具有明显优势,且在识别常规方法难以识别的油水同层时取得了较好的效果,具有良好的应用前景,为利用数据挖掘方法解决油田勘探开发中的复杂问题提供了新思路。
测井解释;流体识别;K近邻法;相对密度聚类;数据挖掘
利用测井资料对储层流体进行精确识别是储层评价工作的重要任务。常规测井解释中,流体识别一般采用曲线重叠法[1-2]和交会图法[2-4],识别依据为测井曲线重叠时线间距的变化或测井数据交会分析建立的图版,识别结果过于依赖经验判断,分类标准因人而异,精度难以保证,而目前对上述方法的改进仅限于判别因子与阈值的优化[5-8],并未从实质上解决这一问题。现有的机器学习法,如Fisher判别法[9-11]、神经网络[12-15]等,亦存在一定缺陷:前者依据组间与组内均方差之比最大的原则,寻找将多维数据点投影为一维数值的线性函数建立图版进行识别,但由于地下结构复杂,测井数据往往线性不可分,此时算法精度难以保证;后者通过某种算法构建参数间的映射模型[15]以实现流体识别,但该算法学习效率固定,网络参数由个人经验或反复试验确定而缺乏理论指导,处理速度慢,且结果值得商榷。笔者根据测井数据结构,利用局部相对密度将待测样本点聚类成簇,并利用K近邻投票获得各簇所属类别。
1 原理方法
基于密度聚类的K近邻法(density clustering based K-nearest neighbor method,DCBKNN),是对相对密度聚类和K近邻法的综合,其主要思想是,利用相对密度聚类将待测样本中杂乱分布的数据点简化成为数据簇,之后只需利用K近邻投票判断每个簇的核心点所属的类别即可实现储层流体类型的识别。
1.1相对密度聚类算法构建数据簇
聚类分析(clustering analysis)是一种根据数据结构特征的相似性将数据集划分成若干个小组的数理分析方法,其中每个数据组均是由一系列隶属于同一类别的数据点构成的集合,称为数据簇(data cluster)[16-19]。
基于密度的聚类方法认为整个数据空间由若干分布稠密的数据区域和零星分布的数据点构成,这些高密度区域构成的数据簇被分散数据点构成的稀疏空间所分隔,而算法的目的就是根据全局密度的差异找出这些数据簇。
常用的密度聚类法中最典型的是DBSCAN算法[18-19],其核心参数为邻域半径Eps和邻域内最少元素数量minPts。通过检索找出若干个高密度区域的核心点并扩展形成数据簇,要求簇内每个元素在半径Eps内都能至少包含minPts个点。该方法存在一些难以克服的缺点。首先,聚类参数Eps和minPts的敏感性过强,即使是细微的改变也能造成巨大的偏差。图1显示了不同的聚类参数对聚类结果的影响。当Eps和minPts的设置合理时,图中分布紧密的数据能准确地聚类成两个簇,如图1(a)所示。此时略增大minPts,使簇Ⅱ中元素数量达不到minPts的要求,机器会对聚类结果进行自动修改,造成将簇Ⅰ和簇Ⅱ误分成一类的结果,如图1(b)所示。其次,聚类参数的选择往往基于个人经验,且根据问题的不同,取值也往往大相径庭,很难给出一个完善的参考区间,这在处理一些复杂问题时给使用者造成了极大的不便。最后,该算法在核心点的提取和扩展过程中,繁冗的计算和储存过程会大量占用内存[18]。可见,该方法在处理数据量大、结构复杂的储层流体识别问题时,实用价值很有限。
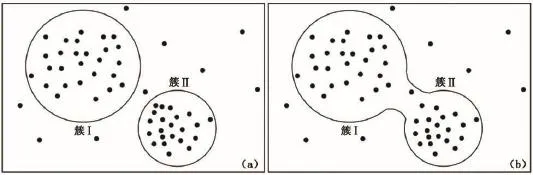
图1 不同的聚类参数对聚类结果的影响Fig.1 Distinct influence to clustering result when selecting different parameters
为了弥补DBSCAN的上述缺点,本文中引入K近邻相对密度以替换全局密度,不再使用Eps和minPts这两个参数,而是通过设置阈值对簇的范围进行控制,按照相对密度的高低,将分布相对疏松的点排除出簇,达到了较好的聚类效果。
对于储层流体识别问题,首先需选择适当的测井识别因子。测井解释中一般选择GR(自然伽马)、RD(深侧向电阻率)、RS(浅侧向电阻率)、AC(声波时差)、DEN(密度)、CNL(补偿中子)、SP(自然电位)等常规测井参数及其衍生参数作为识别因子。根据测试资料,提取流体类型已知的数据点构建参考样本集,提取待识别的数据点构成待测样本集。由于识别因子的取值范围差异较大,有时甚至相差多个数量级,因此需对参考样本集和待测样本集采取标准化处理以消除样本量纲不同造成的误差。
其次,选择一个合适的K值,对标准化后的待测数据集中所有元素依次检索其K个最近邻,并计算其平均K近邻距离nnad(xi),选择出nnad(xi)最小的点作为核心点,将核心点与其K近邻作为初始簇。
对于K值的选择,可以通过选择一个较小的初值,再根据参考样本集进行交叉验证得到最优值[20]。具体操作为,从参考样本集中随机抽取部分数据作为训练集而将剩余数据作为测试集,根据训练集元素的类别和分布确定初始K值,在测试集中进行验证,并根据需要对其进行适当修改,多次重复交叉验证过程,以得到最优K值。为了保证K近邻投票结果不会出现“平票”的情况,应尽量保证K为奇数。
数据集中某一点x*与其K近邻集合中各元素的平均K近邻距nnad(xi)的计算公式为
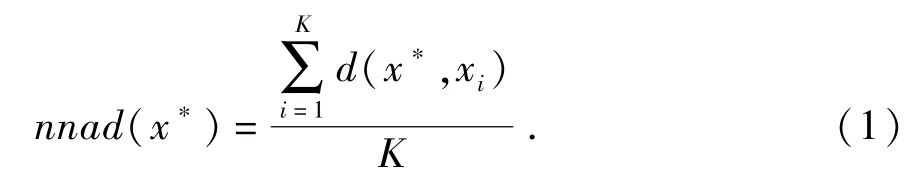
其中
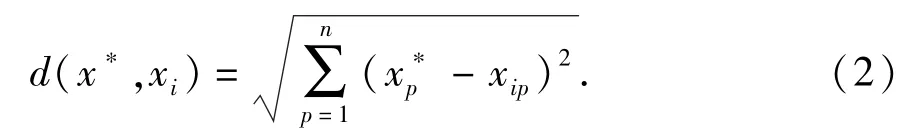
式中,d(x*,xi)为欧氏距离;分别为点x*与xi的第p个测井参数对应的数值。
再次,根据参考样本集选定一个合理的阈值λ,根据核心点在簇中的相对密度对初始簇进行扩展,得到目标簇。
对于核心点为xcore的初始簇C,采用如下方法进行扩展。首先计算xcore在C中的相对密度rden(xcore),观察其相对密度是否满足条件rden(xcore)≥λ。若不满足该条件,则将在C之内与xcore距离最远的点剔除出簇,直到满足条件为止;若满足该条件,则将在C之外与xcore距离最近的点加入C,直到不满足条件为止。通过扩展得到的簇即为目标簇。其中xcore在C中的相对密度[21]的计算公式为

λ为一个不大于1的无量纲常数,其选择须根据样本的数据结构而定。一般方法是首先选择一个接近于1的初始值,利用已知从属类别的参考样本对该初始值进行反复验证,直到达到预期聚类效果时为止。λ的取值仅影响簇的范围和数量,取值过小会造成误判,取值过大仅会造成运算量的增大,对判别结果影响不大,因此λ的选择应秉承“宁大勿小”的原则。
最后,将聚类完毕的目标簇中数据提取出来,并对剩余数据重复进行上述聚类步骤,直到剩下的点无法纳入任何簇内为止。将这些点分别当作单点构成的簇来看待。
1.2加权K近邻投票法识别待测样本
式中,ωi为权重系数;ni为第i类中的样本数量;n为所有类别中样本的总数。
经过加权K近邻投票,可以得到每个数据点所对应的流体类别,用“1、2、3、4”分别代表“干层、油层、油水同层、水层”,可以绘制出流体指示识别曲线,并依此识别各层段流体类别。
1.3算法实现流程
DCBKNN算法的实现流程如图2所示。
对每个簇的核心点,分别与参考样本集中的元素计算加权距离,寻找其K个最近邻居进行投票,将核心点归类于其中占优势的类别,并将各簇元素归类于其核心点所属类别。
在测井解释工作中,由于试油、录井及其他资料的限制,各类别参考样本的容量很难做到完全一致,加之地质结构错综复杂,传统的K近邻分类法的计算精度很难得出令人满意的结果。针对上述问题,在K近邻法的基础上,引入权重系数对近邻距离的计算值进行加权,从而有效地减小了由样本容量的差异导致的误差,实现了提高识别精度的目的[23]。
待测样本集X*中某一点x*m与参考样本X中属于第i类的样本点xn之间的加权距离为

其中

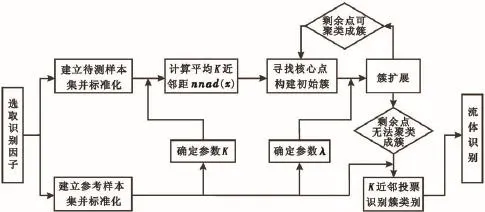
图2 DCBKNN算法实现步骤流程Fig.2 Flow-chart of DCBKNN algorithm
2 应用效果分析
选取深侧向电阻率(RD)、浅侧向电阻率(RS)、声波时差(AC)、密度(DEN)、补偿中子(CNL)、自然伽马(GR)等6条常规测井曲线作为识别因子,应用某油田奥陶系鹰山组碳酸盐岩地层24口井共42个试油层段的测试结果,将流体识别类型分为干层、油层、油水同层和水层等4类。
从各层段中提取最能体现该层段流体性质的特征点作为参考样本集。通过对样本集的交叉验证和反复测试,选定适合本问题的参数K=13和λ=0.92。
采用上述的DCBKNN算法对待测样本进行判别。首先将标准化后的2209个待测样本点聚类为117个数据簇,其中包括单点构成的簇79个。利用加权K近邻投票对这117个簇的核心点进行识别,得到的结果即为各簇元素的类别。应用结果表明,DCBKNN算法识别准确度高达90.48%,如表1所示,说明该算法在面对数据量大、结构复杂的储层流体识别问题时,亦能保证较高的识别精度。
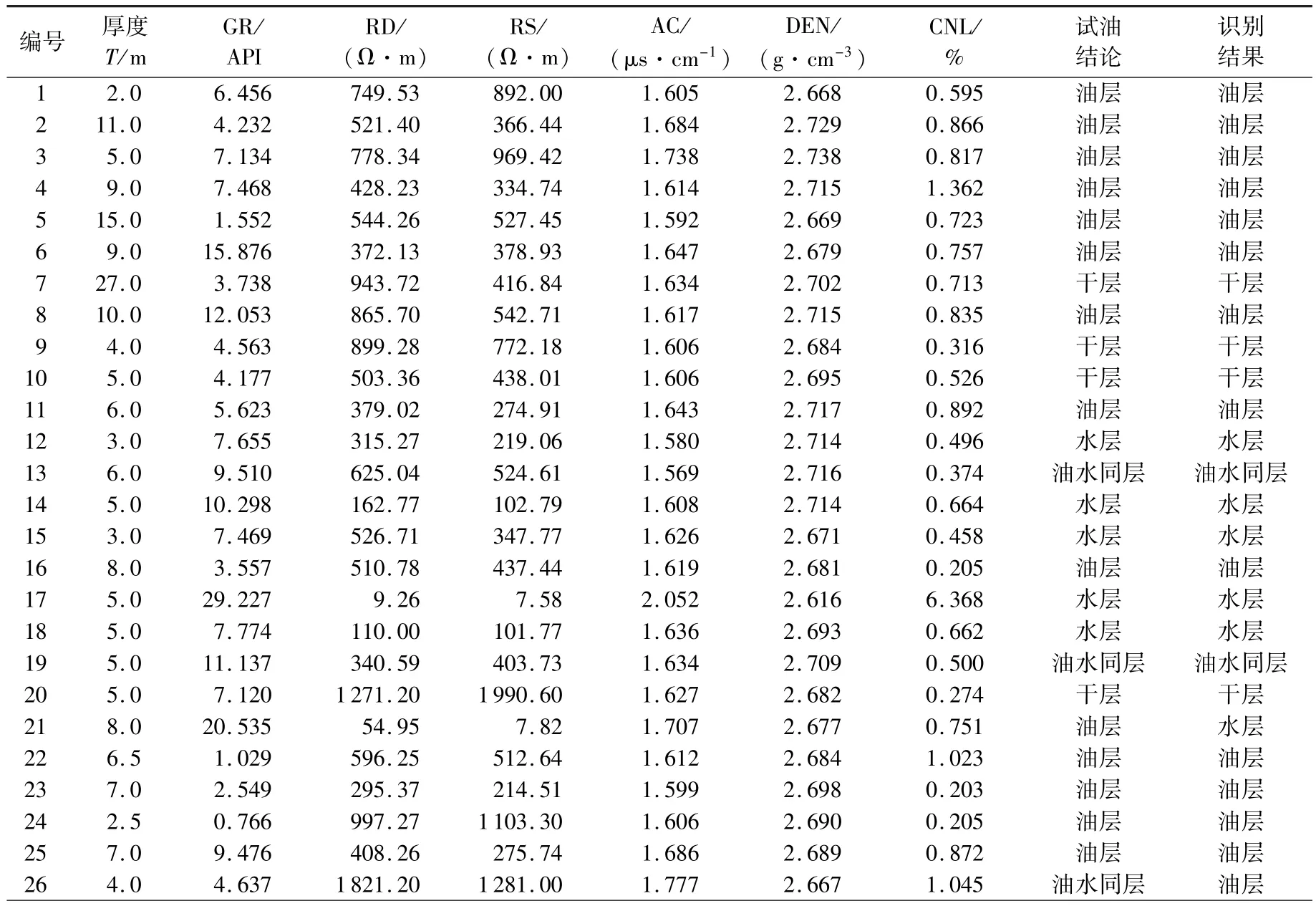
表1 DCBKNN算法识别结果统计Table 1 Identification result statistics of DCBKNN algorithm
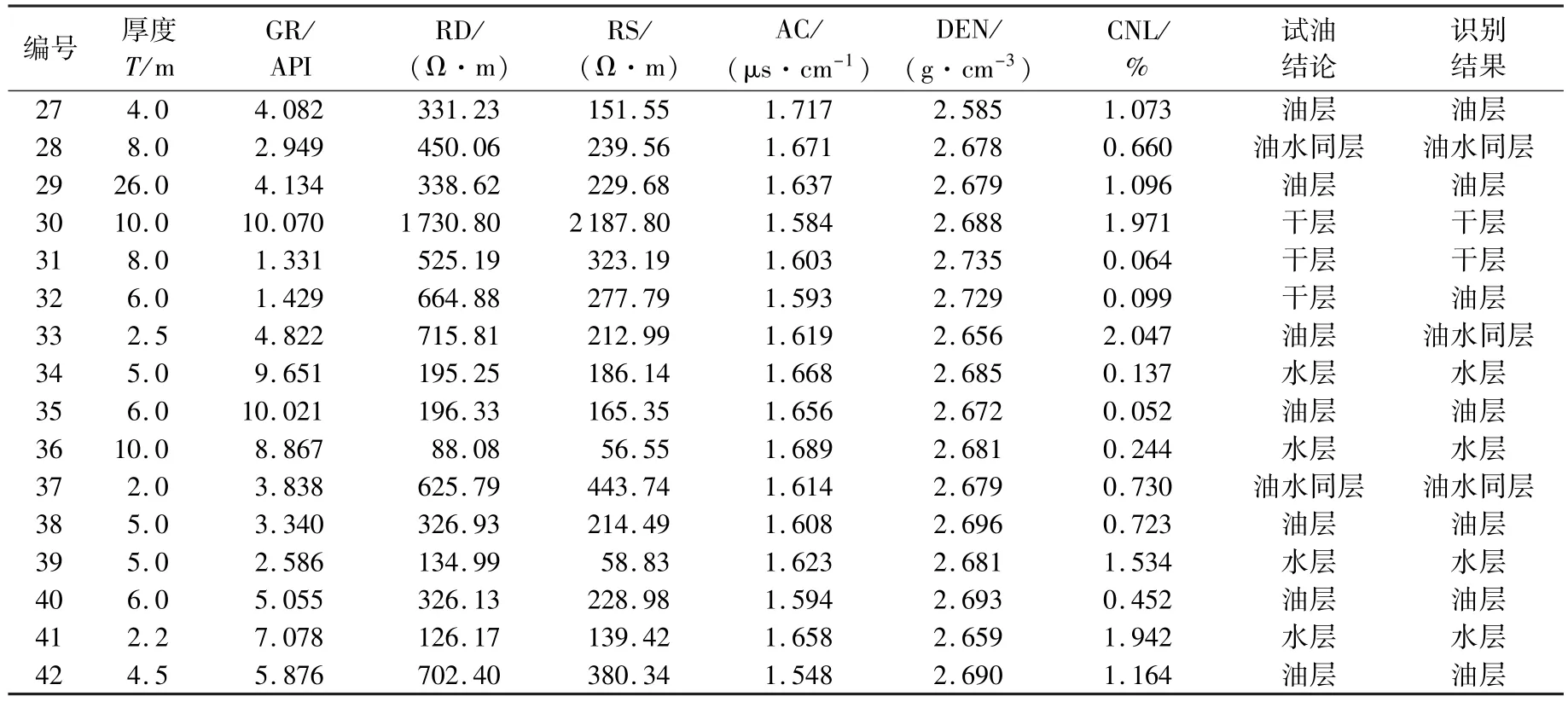
续表

图3 DCBKNN在层段28、29的识别结果Fig.3 Identification results of DCBKNN on interval 28 and 29
此外,在识别其他方法难以准确识别的油水同层方面,DCBKNN算法仍具有一定的优势。在参与测试的42个层段中,有油水同层段5个(层段13、19、26、28、37),其中仅有1个层段判断错误(层段26),识别正确率达80%。以同一口井中的层段28、29为例进行说明,见图2。从测井响应来看,层段28(图3中层段1)平均深侧向电阻率为450.06 Ω·m,具有小幅正差异,声波、中子曲线小幅升高,密度曲线小幅降低,整体表现为油水同层特征;层段29(即图3中层段2)平均深侧向电阻率为328.62 Ω·m,具有较大幅度正差异,声波、中子曲线升高幅度和密度曲线降低幅度均十分明显,整体表现为油层。DCBKNN算法的结果用“1、2、3、4”分别代表“干层、油层、油水同层、水层”,通过运算得出的识别曲线,判断层段28、29分别为油水同层和油层,与试油结论完全吻合。由此可见,DCBKNN算法在识别油水同层等复杂储层时具有较好的效果。
3 结 论
(1)基于密度聚类的K近邻法是对K近邻法和密度聚类算法的改进,引入权重函数以减小样本比重对K近邻法的影响,引入相对密度以弥补密度聚类算法参数敏感性过高的缺点。利用相对密度聚类对K近邻法的数据加以简化,提高了运算效率,在处理数据量大、结构复杂的问题时,亦能保证较高的识别精度。
(2)基于密度聚类的K近邻法是一种非参数的识别方法,既能有效解决传统识别方法过于依赖个人主观经验的问题,又能克服其他常用的数据挖掘和模式识别方法精度低、运算慢、易产生过拟合的缺点,提高了算法的泛化性和鲁棒性。
(3)基于密度聚类的K近邻法能更好地识别其他常用算法难以识别的油水同层、油气同层等复杂层段,具有良好的应用前景,为利用数据挖掘方法解决油田勘探开发中的复杂问题提供了新思路。
[1] 赵克超,陶果,王天波,等.泌阳凹陷深层系低孔低渗油气层测井识别技术[J].石油大学学报:自然科学版,2005,29(6):27-31. ZHAO Kechao,TAO Guo,WANG Tianbo,et al.Hydrocarbon identification of the deep-seated reservoirs with low porosity and low permeability from well logs in Biyang sag[J].Journal of the University of Petroleum,China(Edition of Natural Science),2005,29(6):27-31.
[2] 司马立强,郑淑芬,罗宁,等.川东地区石炭系储层流体性质测井判别方法适应性分析[J].天然气工业,2012,22(6):45-48. SIMA Liqiang,ZHENG Shufen,LUO Ning,et al.A-daptability analysis of discriminating the property of fluids in carboniferous reservoirs in east Sichuan by logging methods[J].Natural Gas Industry,2012,22(6):45-48.
[3] 徐德龙,李涛,黄宝华,等.利用交会图法识别国外M油田岩性与流体类型的研究[J].地球物理学进展,2012,27(3):1123-1132. XU Delong,LI Tao,HUANG Baohua,et al.Research on the identification of lithology and fluid type of foreign moilfield by using the crossplot method[J].Progress in Geophys,2012,27(3):1123-1132.
[4] 邹文,贺振华,陈爱萍,等.定量交会图技术及其在流体识别中的应用[J].石油物探,2008,47(1):45-48. ZOU Wen,HE Zhenhua,CHEN Aiping,et al.Application of quantitative crossplot technique in fluid identification[J].Geophysical Prospecting for Petroleum,2008,47(1):45-48.
[5] 陈刚.一种新的识别低电阻率油层的交会图及其应用[J].中国石油大学学报:自然科学版,2008,32(3):36-39. CHEN Gang.A new cross plot for identifying low resistivity reservoirs and its application[J].Journal of China U-niversity of Petroleum(Edition of Natural Science),2008,32(3):36-39.
[6] 陈钢花,张蕾,宋国奇,等.测井资料在地层不整合纵向结构研究中的应用[J].中国石油大学学报:自然科学版,2010,34(1):50-54. CHEN Ganghua,ZHANG Lei,SONG Guoqi,et al.Application of logging data to unconformable vertical structure research of stratum[J].Journal of China University of Petroleum(Edition of Natural Science),2010,34(1):50-54.
[7] 袁宇,高楚桥,邹雯,等.基于交会图和全概率公式的流体识别方法[J].石油天然气学报,2013,35(5):79-82 YUAN Yu,GAO Chuqiao,ZOU Wen,et al.Method of fluid identification based on crossplot and total probability formula[J].Journal of Oil and Gas Technology,2013,35(5):79-82.
[8] 李梅,赖强,黄科,等.低孔低渗碎屑岩储层流体性质测井识别技术:以四川盆地安岳气田须家河组气藏为例[J].天然气工业,2013,33(6):34-38. LI Mei,LAI Qiang,HUANG Ke,et al.Logging identification of fluid properties in low porosity and low permeability clastic reservoirs:a cases study of Xujiahe Fm gas reservoirs in the Anyue Gas Field,Sichuan Basin[J]. Natural Gas Industry,2013,33(6):34-38.
[9] 樊家琨.应用多元分析[M].开封:河南大学出版社,1993:135-144.
[10] 罗德江.基于核Fisher判别的碎屑岩储层流体识别[J].地球物理学进展,2013,28(4):1919-1924. LUO Dejiang.The method on the fluid identification of rock elastic properties by Fisher discriminant analysis infragmental rock[J].Progress in Geophys,2013,28(4):1919-1924.
[11] 黄烈林,侯健,陈月明,等.Fisher判别法在聚合物驱替潜力评价中的应用[J].石油大学学报:自然科学版,2002,26(1):49-51. HUANG Lielin,HOU Jian,CHEN Yueming,et al.Application of Fisher discrimination method to potential evaluation of polymer flooding[J].Journal of the University of Petroleum,China(Edition of Natural Science),2002,26(1):49-51.
[12] 刘立峰,孙赞东,韩剑发,等.量子粒子群模糊神经网络碳酸盐岩流体识别方法研究[J].地球物理学报,2014,57(3):991-1000. LIU Lifeng,SUN Zandong,HAN Jianfa,et al.A carbonate fluid identification method based on quantum particle swarm fuzzy neural network[J].Chinese Journal of Geophysics,2014,57(3):991-1000.
[13] 岳文正,陶果.地球物理测井多参数综合识别储层流体类型的新型神经网络[J].石油大学学报:自然科学版,2004,28(3):30-42. YUE Wenzheng,TAO Guo.A new neural network applied to comprehemsive recognition of reservoirs fluid type using geophysical well logging parameters[J]. Journal of the University of Petroleum,China(Edition of Natural Science),2004,28(3):30-42.
[14] 李学慧.苏北盆地低电阻率油层的识别及其分布[J].中国石油大学学报:自然科学版,2008,32(5):1-6. LI Xuehui.Identification of the low resistivity reservoir and its distribution in Subei Basin[J].Journal of China University of Petroleum(Edition of Natural Science),2008,32(5):1-6.
[15] 孟庆民,张士诚,王莉,等.数据挖掘技术在气田压裂效果评价中的应用[J].中国石油大学学报:自然科学版,2008,32(5):165-169. MENG Qingmin,ZHANG Shicheng,WANG Li,et al. Application of data mining to postfracture response evaluation in gas field[J].Journal of China University of Petroleum(Edition of Natural Science),2008,32(5):165-169.
[16] 潘和平,樊政军,马勇.基于信息熵识别油气层和水层的聚类方法[J].石油大学学报:自然科学版,2004,28(6):31-34. PAN Heping,FAN Zhengjun,MA Yong.Clustering method for identification of oil(gas)-bearing formation and water-bearing formation based on information entropy[J].Journal of the University of Petroleum,China(E-dition of Natural Science),2004,28(6):31-34.
[17] 印兴耀,叶端南,张广智.基于核空间的模糊聚类方法在储层预测中的应用[J].中国石油大学学报:自然科学版,2012,36(1):53-59. YIN Xingyao,YE Duannan,ZHANG Guangzhi.Application of kernel fuzzy C-means method to reservoir prediction[J].Journal of China University of Petroleum(E-dition of Natural Science),2012,36(1):53-59.
[18] 赵杰,杨柳.聚类分析的dBscan的改进与实现[J].微电子学与计算机,2009,26(11):189-192. ZHAO Jie,YANG Liu.The improvement and implementation of dBscan clustering algorithm[J].Microelectronics&Computer,2009,26(11):189-192.
[19] 冯少荣,肖文俊.DBSCAN聚类算法的研究与改进[J].中国矿业大学学报,2008,37(1):105-111. FENG Shaorong,XIAO Wenjun.An improved DBSCAN clustering algorithm[J].Journal of China University of Mining&Technology,2008,37(1):105-111.
[20] 李航.统计学习方法[M].北京:清华大学出版社,2012:37-44.
[21] 孙凌燕,杨明,任建斌.一种基于相对密度的快速聚类算法[J].微电子学与计算机,2009,26(12):109-116. SUN Lingyan,YANG Ming,REN Jianbin.A fast density-based clustering algorithm[J].Microelectronics& Computer,2009,26(12):109-116.
[22] 王淑盛,徐正光,刘黄伟,等.改进的K近邻方法在岩性识别中的应用[J].地球物理学进展,2004,19(2):478-480. WANG Shusheng,XU Zhengguang,LIU Huangwei,et al.The advanced k-nearest neighborhood method used in the recognition of lithology[J].Progress in Geophysics,2004,19(2):478-480.
[23] 曹根,葛孝堃,杨丽琴.基于K-近邻法的局部加权朴素贝叶斯分类算法[J].计算机软件与应用,2011,28(9):267-291. CAO Gen,GE Xiaokun,YANG Liqin.Locally weighted naive Bayes classification algorithm based on K-nearest neighborhood[J].Computer Applications and Software,2004,19(2):478-480.
(编辑 修荣荣)
Application of density clustering based K-nearest neighbor method for fluid identification
ZHAO Jun1,LU Yifan1,LI Zongjie2,LIU Jianhua2
(1.School of Geoscience and Technology,Southwest Petroleum University,Chengdu 610500,China;2.Sinopec Northwest Oilfield Branch,Urumqi 830013,China)
Reservoir fluid identification is an indispensable link in logging interpretation.In order to remove the defects of traditional approaches,such as unsatisfying accuracy,excessive computation,undue dependence on personal experience,a density clustering based K-nearest neighbor method was proposed.According to the spatial distribution of the interval logging data under test,data clusters are formed based on relative density.And then with K-nearest neighbor voting method,the categories of all clusters become available.Comparing with other commonly used identification methods,tested on the carbonate reservoir of Ordovician Yingshan Formation in an oil field,this approach shows a high accuracy,strong generalization and robustness,as well as better effects on oil-water layer identification which is usually difficult for the compared methods.The method has a good application prospect and provides a new thought on solving complex problems in oilfield exploration and development with data mining methods.
logging interpretation;fluid identification;K-nearest neighbor method;relative density clustering;data mining
P 631.84;TE 122.2
A
1673-5005(2015)05-0065-07
10.3969/j.issn.1673-5005.2015.05.009
2015-03-24
国家“十二五”重大专项(2011ZX05049-001-001)
赵军(1970-),男,教授,博士,研究方向为油气测井、地质。E-mail:zhaojun_70@126.com。
引用格式:赵军,卢一凡,李宗杰,等.基于密度聚类的K近邻法在储层流体识别中的应用[J].中国石油大学学报:自然科学版,2015,39(5):65-71.
ZHAO Jun,LU Yifan,LI Zongjie,et al.Application of density clustering based K-nearest neighbor method for fluid identification[J].Journal of China University of Petroleum(Edition of Natural Science),2015,39(5):65-71.
