语音驱动人脸动画研究综述
2015-09-18王慧慧新疆大学信息科学与工程学院乌鲁木齐830046新疆多语种信息技术实验室乌鲁木齐830046
王慧慧,赵 晖(1.新疆大学信息科学与工程学院,乌鲁木齐830046;2.新疆多语种信息技术实验室,乌鲁木齐830046)
语音驱动人脸动画研究综述
王慧慧1,2,赵晖1,2
(1.新疆大学信息科学与工程学院,乌鲁木齐830046;2.新疆多语种信息技术实验室,乌鲁木齐830046)
对语音信息的理解除了听觉信息,视觉信息也非常重要。在给出语音的同时,如果能给出相应的人脸动画,会提高人们对语音信息的正确理解,这正是语音驱动的人脸动画要达到的效果。语音驱动的人脸动画系统使计算机模拟人类语音的双模态,为人机交互提供可能性。简述语音驱动人脸动画的发展和语音驱动的人脸动画核心技术。
语音驱动的人脸动画;音视频映射;人脸模型
国家自然科学基金(No.61261037)
0 引言
语音驱动的人脸动画合成就是当给出语音信息时,如果能相应地给出视频信息,可以大大提高对信息的理解。这里所说的语音信息是指说话所产生的声波,而视觉信息就是说话者的可视发音器官,如嘴唇、下巴、舌头、面部肌肉等。语音信息和视觉信息都是由发音器官的作用产生的,发音器官包括声带、舌头、嘴唇、下腭、鼻腔等。由于某些发音器官是外部可以看得见的,所以语音信息和视觉信息之间有着必然的内在联系。由于并不是所有的发音器官是可见的,所以语音信息和视觉信息之间不是存在简单的一对一的关系。
近年来,语音驱动人脸动画成为研究热点,研究者在语音驱动的人脸动画方面取得了一定的成果,主要集中在语音驱动人脸动画中,对音视频映射模型的探索和人脸模型的探索中。随着计算机科学技术的发展,对准确性的要求越来越高,音视频映射模型和人脸模型继续成为研究的热点。
目前,音视频模型主要集中在矢量量化的方法(VQ)、神经网络(Neural Network,NN)、高斯混合模型(Gaussian Mixture Model,GMM)、隐马尔可夫模型(Hidden Markov Model,HMM)和动态贝叶斯模型(Dynamic Bayesian Network,DBN)的探索,而人脸模型主要集中在基于图像的模型、基于2D模型和基于3D模型的探索。本文将对现流行的音视频映射模型和人脸模型的优缺点进行分析概括总结。
1 语音驱动人脸动画
语音驱动的人脸动画是根据语音信息得到相应的人脸动画通,能帮助用户理解语音内容,提高人机交互的便捷性和友好程度。语音驱动的人脸动画技术的核心技术包括:音视频映射、人脸动画合成,人脸动画合成的关键是人脸模型的建立。语音驱动的人脸动画的基本框架图如图1所示。音视频映射就是找到音频和视频之间的关系,音视频转换就是根据语音信息得到相应的视频信息,人脸动画合成就是根据音频信息得到的相应的视频信息合成会说话的人脸。
1.1音视频映射
获得音视频映射的前提是先对音频特征和视频特征进行提取,然后通过模型训练学习,找到音视频之间的关系。由于语音信息和视觉信息不是存在简单的一对一的关系[1],所以有许多不同的方法用来研究语音信息和视觉信息的映射。
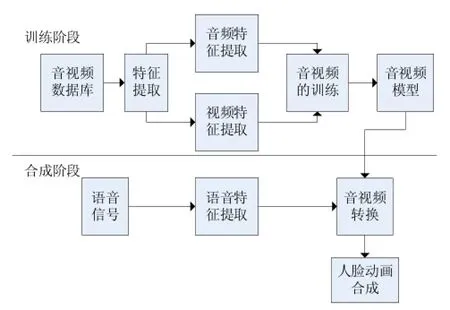
图1 语音驱动人脸动画合成的基本框架
传统的矢量量化的方法、神经网络的方法很直接并且很容易实现的方法,但是结果往往不准确或者不连续,这是由于语音序列存在复杂的协同发音现象。另外,由于人们的发音习惯不同,相同的音节在不同的语音样本中可能具有不同的长度和频谱特征,即使同一个人对同一句话所录制的多个语音样本,其特征也会有较大差异。这导致了矢量量化的方法和神经网络的方法难以合成出令人满意的视频序列。但是加以改进,也能达到我们所需的效果,如贾熹滨[2]以矢量量化的思想为基础,建立语音特征空间到视觉语音特征空间的粗耦合映射关系。为加强语音和视觉语音的关联性,系统分别根据语音特征与视觉语音特征的相似性两次对样本数据进行自动聚类,构造同时反映语音之间与视觉语音之间相似性的双层映射码本,取得了较满意的效果。
高斯混合模型是模拟音视频向量的连接概率分布向量作为混合高斯模型的值。给出语音特征,每个高斯混合组件对视觉特征产生线性评估,评估的混合组件通过增加权重来产生最终的视觉特征的评估。这种方法能产生比VQ平滑性更好的动画,但是这种方法很容易陷入过度平滑。由于高斯混合模型能更好地模拟协同发音,所以很多研究者还是在高斯混合模型的基础上做一些改进来实现主要达到的目的。Deena[3~4]采用高斯混合模型实现可视化语音转换,通过对面部动作和语音建模并使用共享的高斯混合模型之间的映射关系来合成脸部表情动画。高斯混合模型被Chang Wei Luo[5~6]使用于音频到视觉的转换,为了克服没有考虑以前视觉特征对目前视觉特征的影响和GMM的训练和转换不一致的问题。我们提出了整合以前视觉特征入转换,并提出了一个最小的转换误差为基础的方法来改进GMM参数。改进后的方法可以准确地转换音频功能融入视觉特征。蔡莲红[7~8]等人使用高斯混合模型进行情感语音到视频的转换,开发了一种会说话的虚拟人系统,该虚拟说话人能很好地理解情感。
隐马尔可夫模型模型在解决动态时序问题上具有独特优势,表现为状态转移灵活、上下文信息表述清晰,因而HMM模型近年来被广泛应用于高精度的实时语音动画、音视频映射中并成为研究的热点。Tao[9]使用由音频构成的HMM模型和视频构成的HMM模型通过EM算法训练,音频最好的隐含状态通过Viterbi得到,耦合参数就能确定,也就实现了音频到视频的映射。从Lucas Terissi[10]使用A-V HMM模型训练音视频数据达到音视频流的映射。马娥娥[11]使用IOHMM预测视频序列,不再是音素到视位的映射。Xie lei[12]提出来双层的HMM(CHMM)通过条件概率有两条与HMM链相连,这允许链的异步任务。进一步训练多流HMM模型(MSHMMs)使用音频和视频功能,其中建立声视听语言清晰度之间的对应关系[13]。赵晖[14]提出了基于HMM模型语音状态、基于HMM模型音频和视频混合参数、基于双层HMM模型的方法。HMM模型是一个双重的随机过程,描述了时间轴上语音和视频的状态变化情况,利用HMM得到的合成结果连续,跳变的情况少。但是它需要大量的原始数据实现训练,并且计算量大。虽然隐马尔可夫模型(HMM)在音视频进行映射中已经相当成熟,但是在这个模型中,音频信息只是语音信息,没有考虑发音的异步特征、发音器官对发音的影响、录入数据库个体的差异。
电力企业安全风险管控体系的构筑…………………………………………………………………………高 萍,于克栋(1.86)
动态贝叶斯模型(DBN)是一个处理时序数据的随机概率模型,并且在国外的研究也处于刚刚起步,国内的研究也比较少,但是语音驱动人脸动画领域也有一定的研究。突出者是清蒋冬梅教授的实验室,吴鹏[15]构建一种基于发音特征的音视频双流动态贝叶斯网络(DBN)语音识别模型(AF_AV_DBN),定义节点的条件概率关系,使发音特征状态的变化可以异步。张贺[16]提出了一种基于主动外观模型(AAM)特征和异步发音特征DBN模型(AF_AVDBN)的逼真可视语音合成方法。在AF_AVDBN模型训练中,以42维感知线性预测(PLP)特征为音频特征,视频特征为嘴部图像的80维AAM特征。实验结果表明,考虑音视频的异步性,会增加合成嘴部动画与语音之间的一致性。蒋冬梅[17]将此方法扩展到语音驱动的人脸动画中来,合成清晰逼真的人脸动画。与HMM相比,动态贝叶斯模型(DBN)具有更强的计算能力,并且考虑到发音特征的影响,能更准确地找到音频和视频的映射关系。然而对动态贝叶斯模型(DBN)的研究还处于一个探索阶段,需要更进一步的研究。
1.2人脸动画的合成
基于语音驱动的人脸动画系统中人脸模型的建立是关键,在现在的研究中人脸模型可以分为以图像为基础的人脸模型、2D人脸模型和3D人脸模型。基于3D模型的方法无论是从在光照条件下,还是在不同的角度观察,都比基于图像模型的方法更灵活,但是实时性较差,然而基于图像模型的方法却弥补了这个不足。
(1)图像为基础的人脸模型
基于图像的人脸动画方法生成的动画纹理直接来源于采集的人脸图像,具有很高的纹理真实感,也不像基于3D模型的人脸那样要进行人脸的重构。1988年,Pighin[18]第一次使用一些图片适合给定面部三维模板网结构,然后通过混合不同的姿势得到人脸动画,并且在第二年他使用这项技术解决从图像中得到真实的人脸模型和动画问题,从此,以图像为基础的人脸动画成为研究的热点。这种方法在语音驱动人脸动画中主要使用单元选择技术[19]进行人脸动画的合成。虽然基于图像的人脸动画方法能够获得高逼真度的人脸动画,但是需要很大的数据库,采集大量的图像信息,这给工作造成一定的难度。并且在合成时很难实现个性化的人脸图像。
(2)2D人脸模型
2D人脸模型可以从录取的数据库创建,这样就可以大大减少对数据库量的要求,所使用的最常见的二维模型是主动外观模型(AAM)。这种模型是线性的形状和外观,AAM表示使用网格顶点的位置代表形状,使用RGB代表纹理。主动外观模型(AAM)是一种统计模型,广泛应用于人脸图像的分析、特征点跟踪和合成等领域。AAM通过对样本集进行主成分量分析得到样本的均值与变化模式;然后再用这些提取出来的变化模式线性组合出新样本。这种做法消除了训练样本间的冗余,生成的模型更加紧凑,表示人脸时也更加有效。Mattheyses[20~21]解释了主动外观模型(AAM)以形状和纹理表示图像信息,并把主动外观模型(AAM)应用到视觉语音合成系统中,实现了流畅自然的视觉输出语音。Benjamin Havell[22]使用主动外观模型(AAM)代表图像信息,结合HMM合成语音驱动的人脸动画。研究者蒋冬梅,谢磊,Salil Deena从音视频数据库训练AAM模型,代表图像信息。但是训练AAM往往需要大量的训练数据,要针对所有的表情动作采集相关训练数据,因此它们多用于合成单幅人脸图像。
基于三维模型的人脸动画方法,以三维人脸模型作为动画基础来实现人脸动画。通过三维人脸模型对脸部的外观和动作模式进行建模,利用不同的函数或者参数的变化控制合成不同的人脸动作和表情。三维人脸模型的设计选取决定了人脸动画的效果、实现的难易程度以及动画效率。基于三维模型的人脸动画一般分为建模和合成两个阶段。
在建模阶段,根据已知的人脸结构、形状等先验知识建立三维模型所需要的各种条件、参数、数据等要求,对输入的图像或是图像序列进行图像分析和处理,以获得相应的模型参数。合成阶段是在一定的动画规则的基础上,根据所需要的动画要求给出控制三维模型动画所需要的函数表达或形状纹理参数,以驱动模型获得动画图像。因此基于三维模型的人脸动画方法要解决两个方面的问题:三维人脸建模和动画驱动。
(1)三维人脸建模方法建立
建立人脸的三维模型需要获取稠密的人脸三维信息,包括人脸的几何信息和纹理信息。Parke提出了最早的3D人脸几何模型[23],这些三维信息可以利用复杂精细的设备,只经过一般的配准和立体视觉求解获取,也可以通过普通的图像获取设备采集图像或图像序列。有些研究者[22]借助于高精度的3D扫描仪来构造精确的3D人脸模型。将这一技术与3D纹理映射技术配合,就可得到一个真实感很强的3D人脸模型。但3D扫描仪很昂贵,并在有些场合难以应用。因此,人们仍然致力于寻找其他更为方便的构造3D人脸模型的方法。有些研究[24]者依据商业用途的运动捕捉系统使用8台数码相机追踪人脸特征点,Shunya Osawa[25]使用两台计算机,建立人脸模型。李冰锋[26]使用FaceGen工具生成原始3D头的模型。
(2)三维人脸模型驱动方法
三维人脸模型驱动方法包括基于插值的、基于变形的以及基于参数的人脸动画方法。
基于插值的人脸动画方法是一个直观常用的人脸动画方法,通常情况下,插值函数在归一化时间区内在指定极端位置的两个关键帧之间平滑地运动。Lucas Terissi[10]使用插值的方法合成语音驱动的人脸动画。虽然插值的方法的动画生成的速度快,容易生成原始脸部动画,但是生成的表情受到了关键帧的限制,不可能生成关键帧插值范围之外的人脸动作。因此,这种方法适用于根据关键帧产生表情很少的人脸动画。Ning Liu[27]使用变形的方法合成语音驱动的人脸动画,虽然变形方法能够很好地模拟人脸形状的变化。但是忽略了纹理,这样就不能合成逼真的人脸动画。
基于参数的人脸动画,能很好地描述人脸的几何形状和纹理构成,通过不同的参数的变化和组合可以产生不同的人脸表情动作,最常用的就是MPEG-4标准的FAP参数。一些研究者[28]使用这些参数合成语音驱动的人脸动画系统。这种标准规定了两个高级参数:视位和表情,及66个低级参数,这样就大大减少了研究者的工作量,提高了工作效率。
2 结语
在人与计算机的交流过程中,不再是以文本与计算机交流,而是以语音与计算机交流,将大大提高计算机工作的效率。本文就语音驱动人脸动画合成的两大技术给予了概括和总结。
近年来关于语音驱动的人脸动画的研究虽然已经取得了一些成就,但是这并没有实现研究者的愿望,如:只能在安静的环境中与计算机交流,并且现在的研究还只是单一对一种语言的研究,一旦系统做好,不能识别第二种语言。在可见的未来,语音驱动的人脸动画这一技术将改变人们与计算机的交流方式,多种语言,并且能在吵杂的环境中很好地与计算机交流这将成为语音驱动人脸动画的一个趋势。
[1]Wesley Mattheyses,Lukas Latacz,Werner Verhelst.Comprehensive Many-to-Many Phoneme-to-Viseme Mapping and Its Application for Concatenative Visual Speech Synthesis[J].Speech Communication,2013,55(7-8):857~876
[2]贾熹滨,尹宝才,孙艳丰.基于双层码本的语音驱动视觉语音合成系统[J].计算机科学,2014,41(1):100~104
[3]Salil Deena,Shaobo Hou,Aphrodite Galata.Visual Speech Synthesis Using a Variable-Order Switching Shared Gaussian Process Dynamical Model[J].Multimedia,IEEE Transactions on,2013,15(8),1755~1768
[4]Salil Deena,Shaobo Hou,Aphrodite Galata.Visual Speech Synthesis by Modelling Coarticulation Dynamics Using a Non-Parametric Switching State-Space Model[C].ICMI-MLMI'10:International Conference on Multimodal Interfaces and the Workshop on Machine Learning for Multimodal Interaction,2010
[5]Changwei Luo,Jun Yu,Xian Li,ZengfuWang.Real Time Speech-Driven Facial Animation Using Gaussian Mixture Models[C].2014 IEEE International Conference on Multimedia and Expo Workshops(ICMEW)2014:1~6
[6]Changwei Luo,Jun Yu,Zengfu Wang.Synthesizing Real-Time Speech-Driven Facial Animation[C].2014 IEEE International Conference on Acoustics,Speech and Signal Processing(ICASSP),2014:4568~4572
[7]Jia Jia,Shen Zhang,Fanbo Meng,Yongxin Wang,Lianhong Cai.Emotional Audio-Visual Speech Synthesis Based on PAD,IEEE Transactions on AUDIO,Speech,and Language Processing,VOL.19,No.3,MARCH 2011
[8]Shen Zhang,Jia Jia,Yingjin Xu,Lianhong Cai.Emotional Talking Agent:System and Evaluation.2010 Sixth International Conference on Natural Computation(ICNC 2010)
[9]Jianhua Tao,Member,IEEE,Li Xin,Panrong Yin.Realistic Visual Speech Synthesis Based on Hybrid Concatenation Method.IEEE Transactions on AUDIO,Speech,and Language Processing,VOL.17,No.3,MARCH 2009
[10]Lucas Terissi;Mauricio Cerda;Juan C.Gomez.Animation of Generic 3D Head Model Driven by Speech[C].2011 IEEE International Conference on Multimedia and Expo(ICME),2011:1~6
[11]马娥娥,刘颖,王成儒.基于IOHMM的语音驱动的唇动合成系统[J].计算机工程,2009,35(18):283~285
[12]Lei Xie,Zhi-Qiang Liu.Speech Animation Using Coupled Hidden Markov Models[C].Pattern Recognition,2006.ICPR 2006.18th International Conference on,2006:1128~1131
[13]Lei xie,Naicai Sun,Bo Fan.A Statistical Parametric Approach to Video-Realistic Text-Driven Talking Avatar[J].Multimedia Tools and Applications,2014,73(1):377~396
[14]赵晖.真实感汉语可视语音合成关键技术研究.国防科学技术大学,2009
[15]吴鹏,蒋冬梅,王风娜,Hichem SAHLI,Werner VERHELST.基于发音特征的音视频融合识别模型[J].计算机工程,2011,37(22): 268~272
[16]张贺,蒋冬梅,吴鹏,谢磊,付中华,Hichem Sahli.基于AAM和异步发音特征DBN模型的逼真可视语音合成[C].第十一届全国人机语音通讯学术会议,西安:2011
[17]Dongmei Jiang,Yong Zhao,Hichem Sahli.Speech Driven Photo Realistic Facial Animation Based on an Articulatory DBN and AAM Features[J].Multimedia Tools and Applications,2014,73(1):397~415
[18]F.Pighin,J.Hecker,D.Lischinski,R.Szeliski,D.Salesin.Synthesizing Realistic Facial Expressions from Photographs[C].SIGGRAPH !98 Conference Proceedings,1998:75~84
[19]Ying He,Yong Zhao,Dongmei Jiang.Speech Driven Photo-Realistic Face Animation with Mouth and Jaw Dynamics[C].2013 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference(APSIPA),2013:1~4
[20]Mattheyses W,Latacz L,Verhelst.Active Appearance Models for Photorealistic Visual Speech Synthesis[C].Proc.Interspeech 2010,2010:1113~1116
[21]Mattheyses W,Latacz L,Verhelst V.Optimized Photorealistic Audiovisual Speech Synthesis Using Active Appearance Modeling[C]. In:Proc.Internet.Conf.on Auditory-Visual Speech Processing,2010:148~153
[22]Benjamin Havell.A Hybrid Phoneme Based Clustering Approach for Audio Driven Facial Animation[C].2012 IEEE International Conference on Acoustics,Speech and Signal Processing(ICASSP),2012:2261~2264
[23]F.I.Parke,Computer Generated Animation of Faces[C].Proc.of ACM National Conference,1972:451~457
[24]Kaihui Mu,Jianhua Tao,Jianfeng Che,Mianghao Yang.Real-Time Speech-Driven Lip Synchronization[C](IUCS),4th International Universal Communication Symposium,2010:378~382
[25]Shunya Osawa,Guifang Duan,Masataka Seo,Takanori Igarashi,and Yen-Wei Chen.3D Facial Images Reconstruction from Single Facial Image[C].Information Science and Service Science and Data Mining(ISSDM),2012 6th International Conference on New Trends in,2012:487~490
[26]李冰锋,谢磊.实时语音驱动的虚拟说话人[C].第十一届全国人机语音通讯学术会议,西安:2011
[27]Ning Liu,Ning Fang,Seiichiro Kamata.3D Reconstruction from a Single Image for a Chinese Talking Face[C].TENCON 2010,2010: 1613~1616
[28]尹宝才,王恺,王立春.基于MPEG-4的融合多元素的三维人脸动画合成方法[J].北京工业大学学报,2011,37(2):266~271
Speech-Driven Facial Animation;Audio and Video Mapping;Face Model
Survey of Speech-Driven Facial Animation
WANG Hui-hui1,2,ZHAO Hui1,2
(1.College of Information Science and Engineering,Xinjiang University,Urumqi 830046;2.Xinjiang Laboratory of Multi-Language Information Technology,Urumqi 830046)
In addition to voice information for the understanding of auditory information,visual information is also very important.In the speech given at the same time,if given the appropriate facial animation,will raise awareness of the correct understanding of the voice message, which is a speech-driven facial animation to achieve the effect.Speech-driven facial animation system allows a computer simulation of human speech bimodal,offers the possibility for human-computer interaction.Summarizes the development of speech-driven facial animation and speech-driven facial animation core technologies.
王慧慧(1988-),女,河南沈丘人,硕士研究生,研究方向为人工智能、模式识别
赵晖(1972-),女,云南昆明人,博士,教授,研究方向为人工智能、图像处理
2015-04-07
2015-05-10
