一种对移动Web访问日志中层次数据的提取方法
2015-09-16高丽峰高丽萍李梦颖
高丽峰,高丽萍,李梦颖
一种对移动Web访问日志中层次数据的提取方法
高丽峰1,高丽萍2,李梦颖1
(1.四川大学计算机学院,成都610065;2.北京南瑞智芯微电子科技有限公司,昌平102200)
提出一种基于可视分析的层次数据提取方法,实现对移动Web访问日志中层次数据的精确高效提取。通过数据样本建立数据字典,确保没有信息遗漏,并根据字典统计样本并记录相关数据,建立数据网络权重图。可视化该网络,并以可视分析的方法确定数据间的层次结构,并以此构建数据层次结构有向图,结合结点权重进行拓扑排序,使用得到的拓扑序列更新数据字典。将待提取日志与数据字典中的关键词依次进行正则匹配,并保存提取结果。对移动Web访问日志中User-Agent域中的浏览器信息进行数据提取,实验表明该方法能够很好地确定层次数据间的层次关系,实现数据的精确提取。
数据提取;可视分析;层次数据;移动Web访问日志;User-Agent
四川省科技厅项目(No.2013GZ0015)
0 引言
随着大数据的迅速发展,日志文件得到越来越多人的青睐。通过对日志文件的分析,可以挖掘出用户的若干行为,统计分析用户的爱好、习惯等属性,以及这些属性的地域性、时域性等。从而可以帮助开发者针对用户喜好开发对应的软件,使得生活更便捷;帮助设备提供者设计更多人性化的设施。
日志文件有如下特点:实时性,日志文件随着用户访问不断产生,存在明显的时空局域性;异构性,日志文件结构不规范,数据多呈半结构化或无结构;高内涵,日志文件包含用户一次访问以及所使用设备的所有相关信息。此外,移动Web访问日志文件的属性相对更多,主要表现在IP、User-Agent等域。该域中,涉及到移动访问设备的品牌、操作系统,以及浏览器等信息。
然而,一些域中的一条记录可能会出现代表某一属性的若干字段;这些同时出现的字段相互联系,又有一定的从属关系;真正代表该记录该属性的字段只有其中一个。我们定义有从属关系的同一属性数据为层次数据,而如何从这些层次数据中提取出具有代表性的数据这一问题亟待解决。其中典型代表就是User-Agent域中浏览器数据的提取。通过移动Web访问日志中的User-Agent域来精确识别移动设备,尤其是明晰该设备使用的浏览器,对于网页适配、市场调研等具有重要意义。浏览器信息提取需要考虑:若干浏览器使用同一个搜索引擎;双核浏览器的开发使得同一个浏览器可能在不同情况下对应不同的搜索引擎;为了更好的兼容性,浏览器之间经常相互伪装,使得在一条User-Agent域中往往会出现多个浏览器信息。
基于上述分析,对于层次数据(如User-Agent域中浏览器信息)的提取难点在于确定数据(浏览器)间的层次结构及提取顺序。本文提出基于可视分析的层级数据提取方法来解决上述问题,该方法同样适应其他领域层次数据的提取。首先,统计样本中所有字段信息,建立相关数据字典;其次,通过数据字典对样本数据进行重新提取,并记录数据间的相关关系和出现频次,生成对应的网络权重图,即可视分析模型;再次,对网络权重图进行分析,完成数据层级结构有向图;结合权重,对数据层级结构有向图进行拓扑排序,以最终排序结构更新数据字典;最后,将要提取记录与数据字典依次对应,进行数据提取。
1 相关工作
本文以层次数据——User-Agent域中浏览器信息的提取为例,介绍对移动Web访问日志中层次数据的提取方法,即基于可视分析的层次数据提取方法。本节主要对User-Agent、数据提取、可视分析背景知识进行介绍。
1.1User-Agent
User Agent,即用户代理,简称UA,是HTTP协议中的一部分,属于头域的组成部分[1~2]。它是一个特殊字符串头,是一种向访问网站提供访问者所使用的浏览器类型及版本、操作系统及版本、浏览器内核等信息的标识。浏览器的UA字串的标准格式[3]:浏览器标识(操作系统标识;加密等级标识;浏览器语言)渲染引擎标识版本信息。移动Web访问日志文件中的User-Agent域,还包括了使用设备的品牌以及相关型号等信息,如下:
MQQBrowser/2.8(Nokia5235;SymbianOS/9.1Series60/ 3.0)
MQQBrowser/2.8:浏览器类型及版本;
(Nokia5235;SymbianOS/9.1 Series60/3.0):该浏览器运行系统的详细信息,包括设备品牌及其型号、操作系统及其型号
User-Agent还可以进行伪装,如下程序,导致当前User-Agent比较混乱,这对于浏览器的识别以及提取相关数据提出了挑战。
Mozilla/5.0(Windows;U;Windows NT 5.2;en-US)AppleWebKit/534.10(KHTML,like Gecko)Chrome/8.0.558.0 Safari/534.10
Mozilla/5.0:用以指示与Mozilla排版引擎的兼容性
(Windows;U;Windows NT 5.2;en-US):浏览器所运行于的系统详细信息
AppleWebKit/534.10:浏览器所使用的平台(即搜索引擎及其版本号)
(KHTML,like Gecko):浏览器平台的细节(即希望得到为KHTML编写的网页,同时“像Gecko”那样的)
Chrome/8.0.558.0:浏览器及其版本号
Safari/534.10:伪装为Safari浏览器,以增加兼容性
1.2数据提取
数据提取是大多数计算机工作的基础,包括数据挖掘、机器学习等。数据来源范围广泛,但现在更多集中于电子信息,包括电子病历[4]、网页等[5],而提取工具[6]以及提取方法也层出不穷,如DEBy[7]、FiVaTech[8]、CTVS[9]、ViDE[10]等。而大多数提取方法都是针对固定格式或者标准格式文件中的数据进行提取的,例如HTML文档、XML文件、JSON文件等。在进行数据提取的过程中,需要结合文本标签或者特定的结构格式,如果数据文件存在缺项、漏项的现象,则在提取过程中通过建立DOM tree,或者Hidden Markov Model[11]来解决。
移动终端Web访问日志文件不是标准的HTML文件,没有定义相关标签,而且数据信息是杂糅在一起,没有明确的界限和顺序,同时还有噪声,使得数据文件不能很好地转化为XML文件,因此上述方法并不能适用。此外,User-Agent域中的信息还存在各种兼容现象,对数据提取提出了更大的挑战。
本文通过建立数据字典,独立于程序之外,方便随时修改,能够更好地适应市场需求。同时通过可视分析将数据间的层次结构确定下来,则能够解决浏览器伪装等问题。
1.3可视化与可视分析
可视化,即使用图像来进行信息交流[12],其目的是洞悉蕴含在数据中的现象和规律,较传统方式更加直观。可视化技术可以很好地表示层次和网络数据,其中关键是图的绘制,常用的布点算法有经典的力导引算法,如弹簧模型[13]、KK算法[14]、FR算法[15]、ODL[16~17]算法等,以及多尺度布局算法[18]。
网络可视化作为一类重要的信息可视化技术,充分利用人类视觉感知系统,将网络数据以图形化方式展示出来,快速直观地解释及概览网络结构数据,可以辅助用户认识网络的内部结构,以挖掘隐藏在网络内部的有价值信息。
可视分析是信息可视化与科学可视化领域发展的产物,它借助于人类直觉的艺术和科学的数学推导,使用交互式用户界面进行模式挖掘、知识发现,以及分析推理等[19]。可视分析技术为我们数据提供了一种直观有效的方法,它将复杂的数据通过可视化的方式直观地展示出来,并支持对结果的交互式筛选和浏览等操作,从而对数据进行进一步分析。
目前,可视分析已在天气预报、数字城市、金融安全、社会网络等国民经济和国防安全的各个领域得到应用,如移动日志文件的可视分析[20],城市交通数据的可视分析[21~22],蛋白质相互作用的可视分析[23]等。
2 层次数据提取
每当移动终端访问网络的时候,Web服务器都会将该终端的相关信息进行记录,以类似超文本传输协议的文本格式进行存储,形成Web访问日志,如下程序。其中,每条记录以代表时间的长整型数字开始,包含若干的域,且每条记录域的个数和种类都不相同,可见移动Web访问日志文件数据呈非结构化。
1333967945[10.99.29.15:2157-〉10.99.192.13:2158] 10.138.150.32-〉10.0.0.172
GET/comm/v2/result.jsp?sid=AeJBkJkfNNG5_0KWIOb5v -CE&activeId=12&aId=5678&answer=1 HTTP/1.1
accept:application/vnd.wap.xhtml+xml,application/xml, text/vnd.wap.wml,text/html,application/xhtml+xml,image/jpeg;q= 0.5,image/png;q=0.5,image/gif;q=0.5,image/*;q=0.6,video/*,audio/*,*/*;q=0.6
user-agent:MQQBrowser/3.1/Adr(Linux;U;2.1-update1; zh-cn;GT-I5503 Build/ERE27;240*320)
referer:http://sq8.3g.qq.com/comm/v2/result.jsp?sid=Ae-JBkJkfNNG5_0KWIOb5v-CE&activeId=12&aId=5582&answer= 3
cookie:sd_userid=48481328000295684;sd_cookie_crttime=1328000295684;qq_mb_adv_special=-344946998| 1328187419173;pt=2;mtt_cache_ck=20120215191046; stock_uin=wi+MQ0+2xt47xQXiDr0YnyZ6ECM2EYfG;3g_last-LoginQq=907995;3g_csp=1333254835;info_lau=907995; appsd_mid=1904;softdown_mid=1904;match_mid=-1;softdown_pid=14;g_ut=2;info_index_att=1;icfa=content_rela;
其中User-Agent域中包含移动终端设备品牌及型号、终端操作系统详细信息,以及该次访问使用的浏览器及其细节。
数据提取主要包含4个模块,分别为:①建立数据字典,形成数据网络;②实现可视分析模型,辨析数据层次结构;③结合权重进行拓扑排序,更新数据字典;④根据数据字典从日志文件中进行数据提取,并将提取结果保存。处理流程如图1所示,其中前三个模块是数据提取的前期过程,也是重要组成部分。
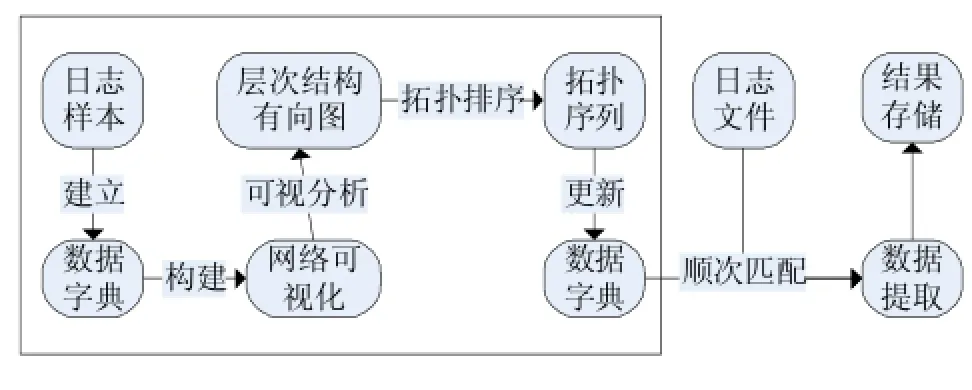
图1 数据提取流程
2.1构建数据网络
为了提取User-Agent域中的浏览器数据,需要建立关于浏览器信息的数据字典,数据字典独立于程序之外,可以方便修改,能够更好地适应浏览器市场变化,具有更好的鲁棒性。数据字典的建立和数据网络的形成步骤如下:
(1)随机收集足够的移动Web访问日志文件中的User-Agent域,形成User-Agent样本数据,如下程序:
Mozilla/5.0(Linux;U;Android 2.3.7;zh-cn;HTC Wildfire S Build/GRI40)UC AppleWebKit/530+(KHTML,like Gecko)Mobile Safari/530
JUC(Linux;U;2.3.4;zh-cn;GN205;480*800)UCWEB7.9.3.103/139/32702
5233/SymbianOS/9.1 Series60/3.0
MQQBrowser/2.8(Nokia5250;SymbianOS/9.1Series60/ 3.0)
MAUI WAP Browser
Nokia2010/2.0(11.21)Profile/MIDP-2.1 Configuration/ CLDC-1.1
E63/SymbianOS/9.1 Series60/3.0
Mozilla/4.0(compatible;MSIE 6.0;Windows NT 5.1)
Lenovo-P50/S045 LMP/LML Release/2010.03.08 Profile/ MIDP2.0 Configuration/CLDC1.1
(2)提取样本数据中的浏览器信息,并将提取到的信息写入数据字典,具体过程如下:
Input:sample file of User-Agent
Output:data dictionary of browser
while((record=sample.readLine())!=null){
//the sample file is not scanned over and the current lineis marked as record
if((b instanceof browser)&&(record.contains(b))&&(!Dictionary.contains(b))){
//there is some information about browser in record while it is not in the dictionary
dictionary.add(b);
}
}
(3)依据数据字典,对样本数据中的每一条记录进行重新提取,如表1所示。
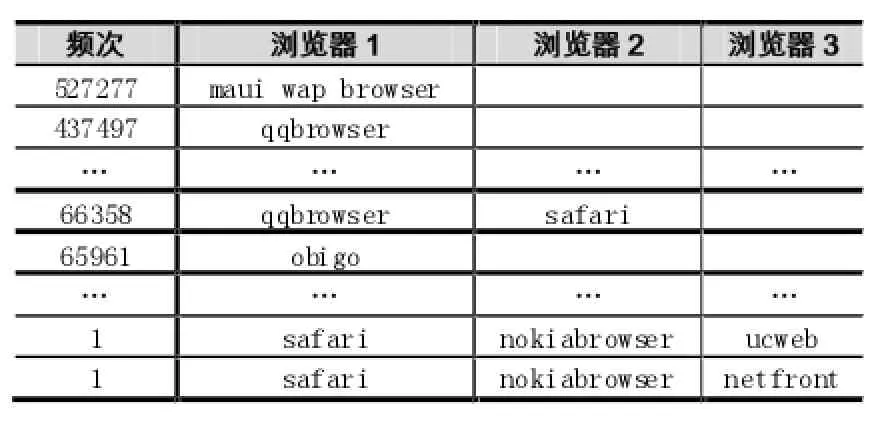
表1 User-Agent域中浏览器信息统计表
将出现的浏览器作为结点n,将出现在同一条记录中的点(n1,n2,…,nm)连线作为边(e12,e13,…,e1m,e23,…,e(m-1)m),将其出现的次数映射成边的权重w,建立数据网络邻接表T,如表1所示。浏览器的频次是指在样本中该浏览器出现的次数t;边数指的是从该点出发有多少条边,也就是和该浏览器有兼容等关系的浏览器的个数;边的权重指的是该条边出现的次数。
2.2辨析数据层次结构
(1)数据网络可视化
根据生成的网络邻接表,使用圆形布局生成网络可视化视图,如图2(a)所示。圆形布局实现简单,能够体现网络节点间的层次关系,但是对于其他网络拓扑结构特征表现力度不强,适合我们初步观察层次数据结构。将边的粗细映射成边的权重,由于边的权重变化范围为1≤w≤527277,因此采用分段映射。在882193条边中,出现4次以下的边总共有23条,这些边被认为是噪声点,去掉后如图2(b)所示,可初窥其层次结构。
(2)可视分析数据层次关系
在图2中存在一些孤立的点,即度为0的结点,这些点所代表的浏览器与其他浏览器并无兼容关系,可以直接提取;考察分布在圆形外围的结点,这些结点度为1,而且确实是剩余结点中层次最低的点,可以去掉。随着点的减少,层次布局逐渐显示其优势,可以更方便地观察数据间的层次结构,整个层次关系的分析类似于“拓扑排序”,但当前的数据网络图是无向的,而且有环存在,这个过程需要人工干预,将层次低的点依次去掉,如图3所示。在倒数第二步判断中,由于safari出现次数t(nsafari)=765384,t(esafari-msie)=13,t(nsafari)·t(esafari-msie),因此我们认为esafari-msie为噪声,忽略不计,同时,eopera-maui-wapbrowser做类似处理。数据层次关系分析完毕。
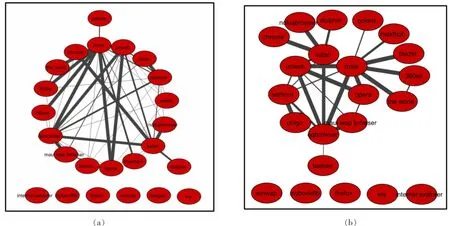
图2 数据网络图展示

表2 数据网络邻接表(部分)
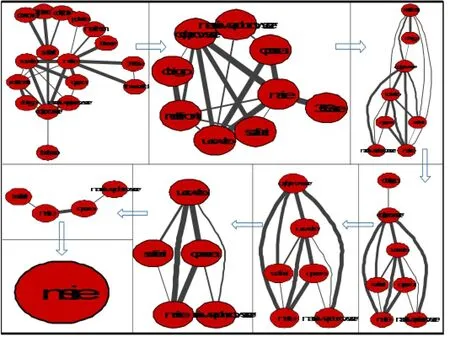
图3 数据层次关系可视分析
2.3更新数据字典
将已知的层次关系结构绘制成有向的层次结构网络图,如图4所示。其中从上往下代表层次由低到高,并将浏览器出现的次数t映射其颜色透明度。此时对整个网络图进行拓扑排序,优先选取出现频次高的结点,这样使得拓扑序列中频次高的结点在前,频次低的结点在后,可以在之后的数据提取中有效提升提取效率。
使用排序好的拓扑序列更新数据字典,作为后续数据提取的依据,如图5所示。
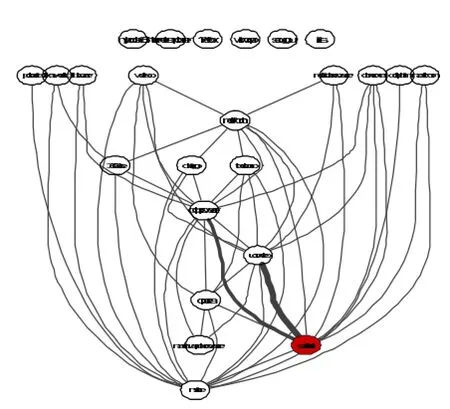
图4 层次结构有向图

图5 拓扑排序结构
2.4保存提取结构
从数据字典中读取拓扑排序结果,依次取字典中的元素与待提取的日志文件中User-Agent域进行正则匹配,当匹配成功时,即返回当前关键词,即所需提取结果,将该结果保存到数据库中,如图6所示。对于提取不成功的字段,我们将在统一分析后,丢弃或者更新数据字典,这在之前的工作中着重介绍,本文不再赘述。
3 实验结果
根据更新的数据字典,能够较为精确地对User-A-gent域中的浏览器信息进行提取,如表3所示。
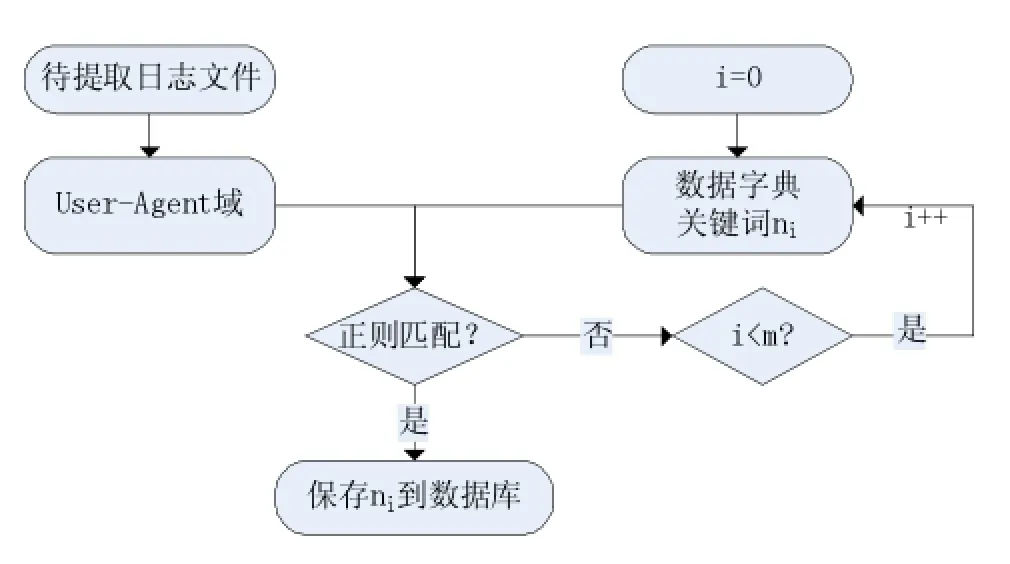
图6 数据提取过程

表3 数据提取结果展示
观察表3,在第一条记录中,User-Agent域中出现表示浏览器信息的关键字有UC、Safari,通过本文的提取方法,则能够将数据层次结构中较低层次的UC提取到,结果为ucweb。其他例子同样很好地证明了该方法的实用性。
如果仅仅辨析数据间的层次结构,而不进行根据权重设定优先级的拓扑排序,直接更新数据字典,数据提取结果仍然正确,但是效率较低。通过实验,相同任务下,经过带权重的拓扑排序后数据提取时间为未排序时提取时间的90.6%。
4 结语
针对移动终端设备众多,参数、性能各异,对网页配置等带来的困难,本文提出了一种基于可视分析的层次数据提取方法。该方法提取移动Web访问日志样本文件中所有相关数据,将数据关系以可视化的形式展示出来,通过一系列交互对数据进行拓扑排序,其中人工干预排序过程,包括网络去环、特殊指定等。同时在排序过程中记录每层的数据,排序结束后,将记录的数据构建层次结构有向图,并根据对应的权重进行拓扑排序,以所得的排序结果更新数据字典,并以该数据字典为依据进行数据提取。
对移动Web访问日志进行数据提取,结果表明该方法可以很好地解决User-Agent域中浏览器信息的兼容问题。
在未来工作中,将在现在提取方法上进行扩展,完成对层次数据提取的可视分析系统,将数据字典的建立、数据层次辨析、数据提取结合起来,对该类数据进行一次性提取,并将其作为开源平台,服务更多的人群。
[1]J.Rosenberg,H.Schulzrinne,G.Camarillo,A.Johnston,J.Peterson,R.Sparks,et al.,"SIP:Session Initiation Protocol,"RFC 3261, Internet Engineering Task Force,2002
[2]C.Lindsey.Netnews Article Format,2009
[3]R.Fielding,J.Gettys,J.Mogul,H.Frystyk,L.Masinter,P.Leach,et al..Rfc 2616,Hypertext Transfer Protocol-HTTP/1.1,1999.URL http://www.rfc.net/rfc2616.html,2009.
[4]M.Martinell,J.St?lhammar,J.Hallqvist.Automated Data Extraction-A Feasible Way to Construct Patient Registers of Primary Care Utilization.Upsala Journal of Medical Sciences,2012,117:52~56
[5]G.Shi and K.Barker.Thematic Data Extraction from Web for GIS and Applications.in Spatial Data Mining and Geographical Knowledge Services(ICSDM),2011 IEEE International Conference on,2011:273~278
[6]A.H.Laender,B.A.Ribeiro-Neto,A.S.da Silva,J.S.Teixeira.A Brief Survey of Web Data Extraction Tools.ACM Sigmod Record, 2002,31:84~93
[7]A.H.Laender,B.Ribeiro-Neto,A.S.da Silva.DEByE-Data Extraction by Example.Data&Knowledge Engineering,2002,40:121-154
[8]M.Kayed,C.H.Chang.FiVaTech:Page-Level Web Data Extraction from Template Pages.Knowledge and Data Engineering,IEEE Transactions on,2010:249~263
[9]W.Su,J.Wang,F.H.Lochovsky,Y.Liu.Combining Tag and Value Similarity for Data Extraction and Alignment.Knowledge andData Engineering,IEEE Transactions on,2012,24:1186~1200
[10]W.Liu,X.Meng,W.Meng.Vide:A Vision-Based Approach for Deep Web Data Extraction.Knowledge and Data Engineering,IEEE!Transactionson,2010,22:447~460
[11]刘亚清,陈荣.基于隐马尔可夫模型的Web信息抽取.计算机工程,2009,35
[12]M.Ward,G.Grinstein,D.Keim,Interactive Data Visualization:Foundations,Techniques,and Applications:AK Peters,Ltd.,2010
[13]E.P.A Heuristic for Graph Drawing.Congressus Nutnerantiunt,1984,42:149~160
[14]T.Kamada,S.Kawai.An Algorithm for Drawing General Undirected Graphs.Information Processing Letters,1989,31:7~15
[15]T.M.Fruchterman,E.M.Reingold.Graph Drawing by Force-Directed Placement.Software:Practice and Experience,1991,21:1129~1164
[16]D.-M.Chan,K.S.Chua,C.Leckie,A.Parhar.Visualisation of Power-Law Network Topologies.in Networks,2003.ICON2003.The 11th IEEE International Conference on,2003:69~74
[17]C.Walshaw.A Multilevel Algorithm for Force-Directed Graph Drawing.in Graph Drawing,2001:171~182
[18]J.B.Kruskal.Nonmetric Multidimensional Scaling:a Numerical Method.Psychometrika,1964,29:115~129
[19]J.Thomas,P.C.Wong.Visual Analytics,IEEE Computer Graphics and Applications,2004,24:0020~21
[20]T.Liang,Y.Cao,M.Zhu,B.Zhou,M.Li,Q.Gan.A Mobile Log Data Analysis System Based on Multidimensional Data Visualization.in Database Systems for Advanced Applications,2014:543~546
[21]H.Guo,Z.Wang,B.Yu,H.Zhao,X.Yuan.TripVista:Triple Perspective Visual Trajectory Analytics and Its Application on Microscopic Traffic Data at a Road Intersection.in Pacific Visualization Symposium(PacificVis),2011 IEEE,2011:163~170 [22]Z.Wang,M.Lu,X.Yuan,J.Zhang,H.v.d.Wetering.Visual Traffic Jam Analysis Based on Trajectory Data.Visualization and Computer Graphics,IEEE Transactions on,2013,19:2159~2168,2013
[23]S.Barlowe,Y.Liu,J.Yang,D.R.Livesay,D.J.Jacobs,J.Mottonen,et al..WaveMap:Interactively Discovering Features From Protein Flexibility Matrices Using Wavelet‐based Visual Analytics,"in Computer Graphics Forum,2011:1001~1010
Data Extraction;Visual Analysis;Hierarchical Data;Mobile Web Access Log;User-Agent
An Extraction Method of Hierarchical Data in Mobile Web Access Log
GAO Li-feng1,GAO Li-ping2,LI Meng-ying1
(1.School of Computer Science,Sichuan University,Chengdu 610064;2.Beijing Nari Smartchip Microelectronics Company Limited,Beijing 102200)
Proposes an effective extraction method for hierarchical data in mobile Web access log files based on visual analysis.Builds a data dictionary to ensure that no information is missing.Records the correlations and frequency of data to build a weighted network from the sample file based on the data dictionary.Visualizes the network,which accelerates the analysis about the hierarchical structure.Following the analyzing result,hierarchical structure digraph grows and topological sequence with weight priority can be gained to update the data dictionary.Saves data,which is extracted from the log files with the updated date dictionary by regex matching.The experimental results show that the proposed method can address the following goals:analyzing the hierarchical structure among hierarchical data;effective extraction for mobile Web access log;can be popularized in other hierarchical data.
1007-1423(2015)12-0047-07
10.3969/j.issn.1007-1423.2015.12.011
高丽峰(1988-),女,硕士研究生,研究方向为可视化、可视分析、数据挖掘
高丽萍(1982-),女,河北人,硕士,中级工程师,研究方向为电力系数数据分析、嵌入式开发
李梦颖(1987-),女,河北人,硕士,学生,研究方向为信息可视化
2015-03-17
2015-04-15
