有导师学习的k-means方法在多支持向量机中的线性划分及其在石油储层识别中的应用
2015-08-17李诒靖李亚楠郭海湘
李诒靖 ,石 咏 ,李亚楠,郭海湘,b,c,2
(中国地质大学1a.经济管理学院;1b.数字化商务管理研究中心;1c.中国矿产资源战略与政策研究中心,武汉 430074;2.中南大学 商学院,长沙 410083)
支持向量机(Support Vector Machine,SVM)是一种泛化能力很强的分类器,它在解决小样本问题方面表现出了许多特有的优势,是一种非常流行的学习方法,被广泛应用于文本分类[1]、脸谱识别[2]、基因方程预测[3]、机械故障诊断[4]以及预测[5]等方面。在运用SVM解决问题时,需要提前考虑的是选择全局学习方法还是局部学习方法。全局学习方法中主要有非线性SVM(SVM直接划分非线性分类边界),局部学习方法中主要有线性SVM(将非线性分类边界拆分为若干线性边界,从而进行线性划分)。运用非线性的SVM处理问题主要是通过构造复杂的核函数实现,其优点是直接,但缺点是具体的非线性变换是未知的,因此容易过学习,并且相关参数对具体问题有依赖性。相对而言,线性SVM鲁棒性强,但分类精度低,所以通常采用多个线性SVM来保证一定精度并同时提高泛化能力,这就是多支持向量机。由于多支持向量机只训练局部的训练集,故其也被称为局部SVM。
现有的局部SVM算法很多,最简单的方法是对每一个测试样本用一个线性SVM来学习。Zhang等[13]提出了一种基于KNN的SVM-KNN算法,该算法首先找到测试样本在训练集中的k个近邻,将样本与其k个近邻的距离矩阵转化为核矩阵,再分别用SVM进行分类。与SVM-KNN不同,Blanzieri等[15]提出的k NNSVM直接在核空间内寻找测试样本的k个近邻,相比SVM-KNN更为简洁直观。Cheng等[16]只采用线性核变换,通过计算测试样本与训练集中每个样本的相似度选取k个相似度最高的样本,为测试样本构造SVM模型来分类,Cheng等提出的算法称为LSVM,并有2个变种:SLSVM和HLSVM。上述3种局部支持向量机算法都需要对每一个测试样本构造SVM模型,当测试样本非常多时,采用上述方法就变得不实际,缺乏实用性。为了克服该问题,许多学者提出了局部SVM的改进算法,基本思想都是将训练集中的样本依据一定的原则划分为若干类并找到类中心,对每个类中心构造一个SVM模型。之后,在对测试样本进行测试时,选择离测试样本最近的中心所构造的SVM进行分类。如图1所示。改进的多支持向量机中每个SVM的训练数据都是通过聚类方法对训练数据进行划分而形成的训练子集,Cheng等提出的PSVM算法,利用加入了平衡正负样本因子的Mag Kmeans聚类算法对训练集进行聚类;Segate等[14]在其提出的k NNSVM的基础上,提出了FaLK-SVM算法,在训练集上采用最小覆盖集的方法来寻找k个中心;Gu等[12]在每个聚类中心构造的SVM的目标函数中加入了全局支持向量来控制每个子线性SVM的支持向量与全局支持向量保持一致,通过这种变化,他们提出的CSVM能很好地克服子SVM中的过拟合问题。

图1 multi-SVM结构图
在改进的多支持向量机算法中,聚类方法肯定能确保每一个样本都归属到某一簇中,但该方法无法从分段线性角度来确保最优划分[6]。上述一些改进的多支持向量机算法能够提高多支持向量机的时间复杂度,但在对训练集聚类时,只有PSVM考虑了如何划分子集的问题。事实上,如何划分子集会直接关系到多支持向量机的表现。子集的划分至少要考虑两点:①子集包含的训练样本是否同时来自不同的2个类,若训练子集中只包含同一类的样本,那么构造的SVM分类器就不能很好地学习到另一类的信息,学习的效率降低。PSVM中加入的样本平衡因子就是为了保证所构造的子训练集中正负样本的平衡性。②子集的中心尽量靠近不同类别的分离边界,这是因为,当子集的聚类中心越靠近边界,子集中包含的正负样本数会越平衡,这一点在不均衡数据分类时尤其重要。在不均衡数据中,少数类样本数量本来就较少,只有子集中心靠近边界才能尽可能更靠近少数类样本,从而训练子集才能最大限度地包含较多的少数类样本。基于这种背景,本文提出了有导师学习的k-means聚类方法,即在传统k-means方法的基础上加入指导信息,从而尽量满足子集划分所要考虑的两点。
1 支持向量机
支持向量机(SVM)是在统计学习理论基础上发展起来的一种新的机器学习方法,它是基于结构风险最小化原则的[7-8],在解决小样本、非线性、高维及防止过学习模式识别问题中表现出许多特有的优势[9]。在SVM中,有{X,yi},Xi∈Rn,i=1,2,…,N。Xi为 第i个输入向量,yi是类别标签(+1或—1)。输入的数据集分为2个不同的类别A和B,对应的输出为+1和—1。支持向量为A的{X∈},支持向量为B的{X∈。在非线性数据集中需要将数据从低维转向高维。高维空间用映射函数φ(x),构造的边界线为
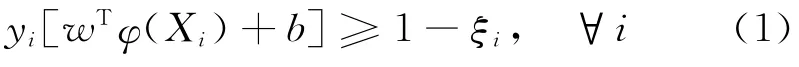
优化边界的问题变成一个最优化问题:

式中:C为可以调节的参数,称为惩罚因子;ξ为松弛变量。将式(2)表示优化问题通过拉格朗日优化方法转化为其对偶问题:

式中,αi为拉格朗日乘 子,这里K(Xi,Xj)=φ(Xi)T—φ(Xj)是核函数。训练后,得到拉格朗日乘子α。如果αi≠0,则对应的样本i就是一个支持向量。SVM的决策值可以定义为

式中:Xi为训练数据中的样本;X为输入向量。当f(X)S为正值时,样本X属于正类,反之属于负类。SVM也可以用一种网络结构进行表达,如图2所示。
2 k-means聚类方法
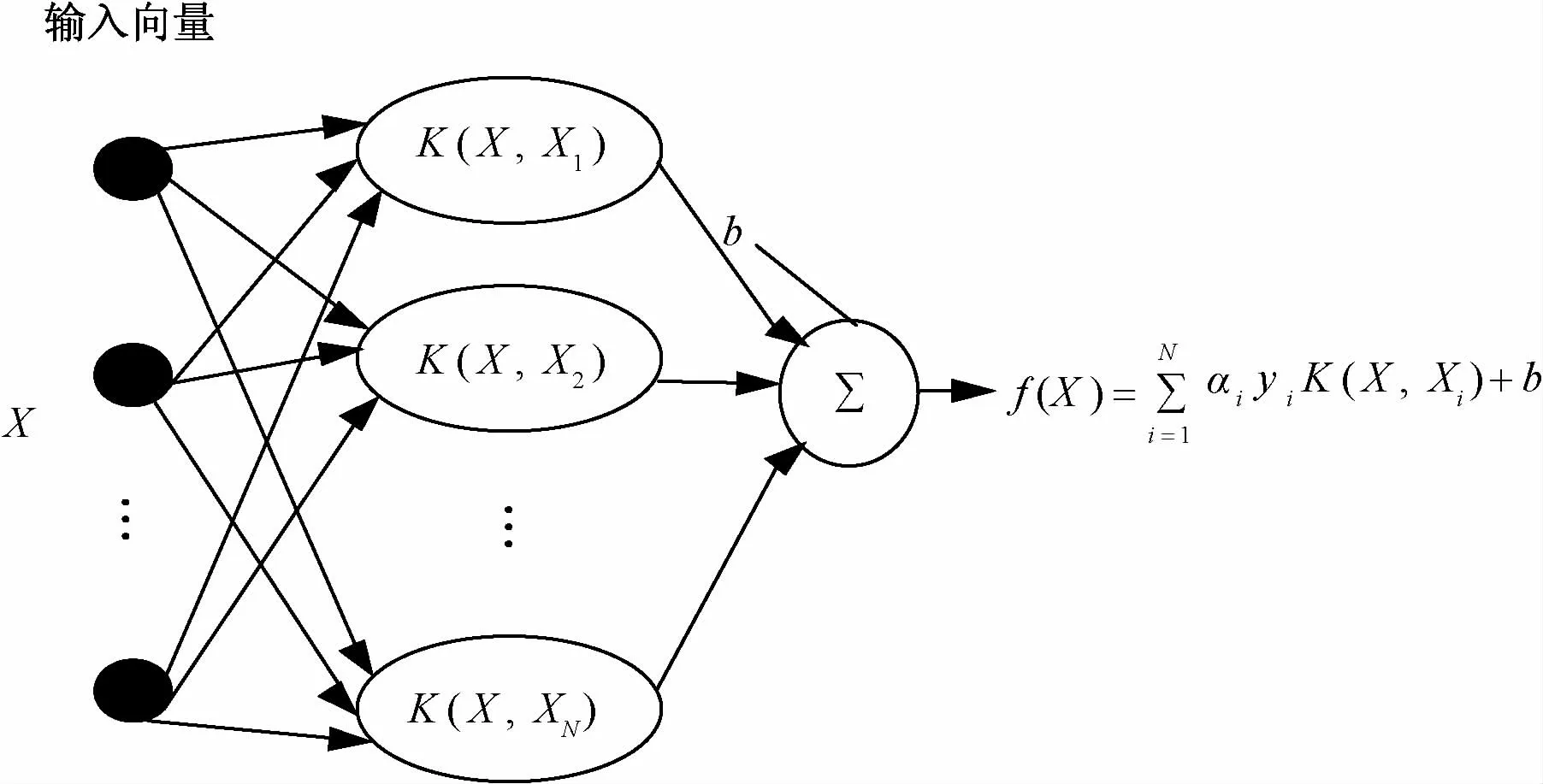
图2 SVM网络结构表达
k-means聚类算法是一种硬聚类方法。即在n维的欧几里得空间将n个样本数据分为k类。首先,由用户确定所要聚类的准确数目k,并随机选择k个对象(样本),每个对象称为一个种子,代表一个类的均值或中心,对剩余的每个对象,根据其与各类中心的距离将它赋给最近的类。然后重新计算每个类内对象的平均值形成新的聚类中心,该过程重复进行,直到收敛为止。考虑到n个样本(x1,x2,…,xn),每一个样本都是d维向量,k-means聚类的目的就是将n个样本划分为k个集合(k≤n)S={S1,S2,…,Sk},最小化类中距为

式中,mi为第i个聚类集合中所有样本的平均值,即类中心。在迭代过程中考虑2个步骤:
(1)样本分配。分配样本到最近类中心的所属类别,即
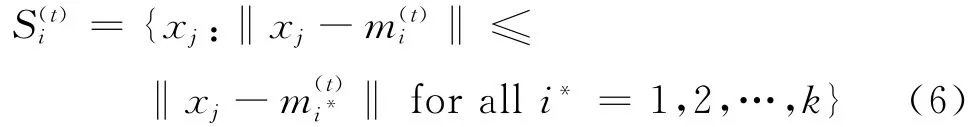
(2)更新。计算聚类样本集合新的均值,即

3 有导师学习的k-means聚类方法
由以上介绍可见,传统的k-means聚类方法只考虑了类中距,这导致在SVM分类学习中,同类的样本通常会划到同一类别集合[10],即该类别集合里的样本标签都为+1,或都为—1,如图3所示。图3(a)表示有2类样本,红色(+1),蓝色(—1),图3(b)通过传统k-means聚类方法进行的划分,很显然,黑色和绿色样本点的划分分别来自同一类,这种划分导致SVM的学习会出现过学习的问题。
本文提出的有导师学习的k-means方法是在传统k-means的基础上不仅考虑类中距,而且还增加了一些指导信息,这些指导信息的引入能够保证样本集合的划分尽量满足集合中的样本来自不同的类别(见图3(b)中,红色样本点集合划分所示)和划分集合的中心尽量靠近分界线。

图3 同类的样本划到同一类别集合的例子
传统的k-means主要考虑类中距目标,即

式中:Xi为第i个样本;Cj为第j个聚类的类中心;Z为样本隶属于各个聚类的隶属度矩阵。本文的方法就是加入指导参数部分放入式(8)中,即

式中:Yi为向量Y(该向量就是对应样本的类别标签)的第i个元素;λ1>0。隶属度矩阵Z如表1所示,向量Y如表2所示。在表1中 数字0和1表示向量Y是否属于类别C。数字0表示向量Y不属于类别C。反之,数字1表示向量Y属于类别C。表2中可以看到数字—1和1,表示向量Y的类别标签,—1表示向量Y是负的,1表示向量Y是正的。

表1 隶属度矩阵Z

表2 向量Y
目标方程式(9)的第1部分
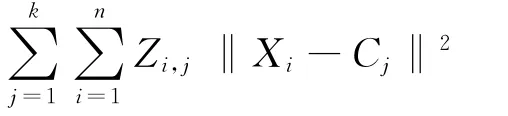

图4 基于式(9)的k-means划分模拟图
由图5可见,表示正样本和负样本的点基本相同,但是在局部区域不均衡,左边红色样本点多于蓝色样本点,中间基本无差,右边蓝色样本点多于红色样本点。运用有导师学习基于式(9)的k-means方法后,仿真图5变为图6。样本划分为3个部分用3种不同的颜色基本上划分正确,但是每一个子集的中心用黑点表示,可以清楚地发现,左、右边子集的中心点并不靠近分离边界。导致这种原因就是样本不均衡。

图5 某区域样本不均衡例子
为了解决该问题,需要附加另一种有导师信息,使得划分的子集不仅考虑类别标签的信息,而且考虑中心的信息。①用标签均衡的改进的k-means进行划分类别(即基于式(9));②测量每个子集中心和对立样本的最短距离,然后最小化该距离。这保证每个类在最近正负样本之间,目标方程为

图6 基于式(9)的k-means划分后

式中:Dj为每个子集到最近的对立样本的距离;λ2>0。
图7(a)为不均衡数据分布图,图7(b)为运用k-means方法对不均衡数据基于式(8)的仿真图,图7(c)为基于式(9)的仿真图,图7(d)为基于式(10)的仿真图。

图7 基于式(10)的k-means划分过程图,不均衡样本
4 仿真实验及性能分析
本文选用UCI数据库[17]中5组不同的二分类数据集进行实验,分别为Heart、Breast、Liver、Ionosphere和Tic-tac-toe数据集,各数据集的具体信息如表3所示。实验选用数据集中60%的样本作为训练集,40%样本作为测试集,并将本文方法所得的分类正确率与采用RBF核函数的标准SVM算法和常用的SVM-KNN[13]、Fa LKSVM[14]以 及CSVM[12]3种局部SVM算法进行对比,结果如表4所示。
表3反映出选用的5组数据集都存在一定的正负类样本数不均衡的情况,而由表4可以看出,4种multi-SVM算法相比SVM在对这5组数据进行分类时分类正确率上均有不同程度的提高,说明采用muiti-SVM的思想可以在一定程度上提高SVM分类器的精度并增强分类器的泛化能力。在4种multi-SVM算法中,本文提出的SkSVM在5组实验中都能得到与其他3种算法相当或更优的精度,尤其是在数据集不均衡程度较高的情况下(如Breast和Tic-tac-toe数据集),SkSVM相比其他3种算法所得的分类正确率要高,说明本文采用有导师学习的k-means对训练集进行划分在不均衡数据分类时有很好的效果。

表3 测试数据集详细信息

表4 5种不同SVM算法的分类正确率对比 %
5 实例研究
5.1 样本数据
收集江汉油田某区块oilsk81井、oilsk83井及oilsk85井的测井数据如表5~7所示(只列出了部分数据,详细数据参见文献[11])。oilsk81油井数据集是江汉油田鄂深8井区的生产井,2001-12-19开钻,完钻日期2002-04-17,完钻井深3 580 m。数据集有31个样本,其中,非油层16个样本,油层15个样本。oilsk83油井数据集是鄂深8井区的生产井,2002-11-08开钻,完钻日期2003-02-11,完钻井深3 558 m。数据集有50个样本,其中,非油层31个样本,油层19个样本。Oilsk85油井数据集是鄂深8井区的开发井,数据集有65个样本,其中,非油层48个样本,油层17个样本。由表中可知,储层含油性识别的测井属性集合大小为6,即声波时差(AC)、中子(CNL)、深测向电阻率(RT)、孔隙度(POR)、含油饱和度(So)和渗透率(PERM)。在该属性集合中到底哪个子集(核属性或者关键属性)是用来识别该油区含油性最优且最简单的属性组合,运用GA-FCM进行属性约简[5],将GA和FCM进行嵌套,GA负责遍历各种属性组合,而FCM根据相对应的属性组合进行识别,识别结果与目标结果进行比较,用识别正确率来评价每个属性组合的优劣,从而可以得到对该油区进行含油性识别的最核心属性组合为声波时差(AC)和含油饱和度(So)。本文即选择声波时差和含油饱和度为输入数据,输出数据为油层(标签为+1)与非油层(标签为—1)。

表5 oilsk81井测井解释成果表(只列出部分数据)

表6 oilsk83井测井解释成果表(只列出部分数据)
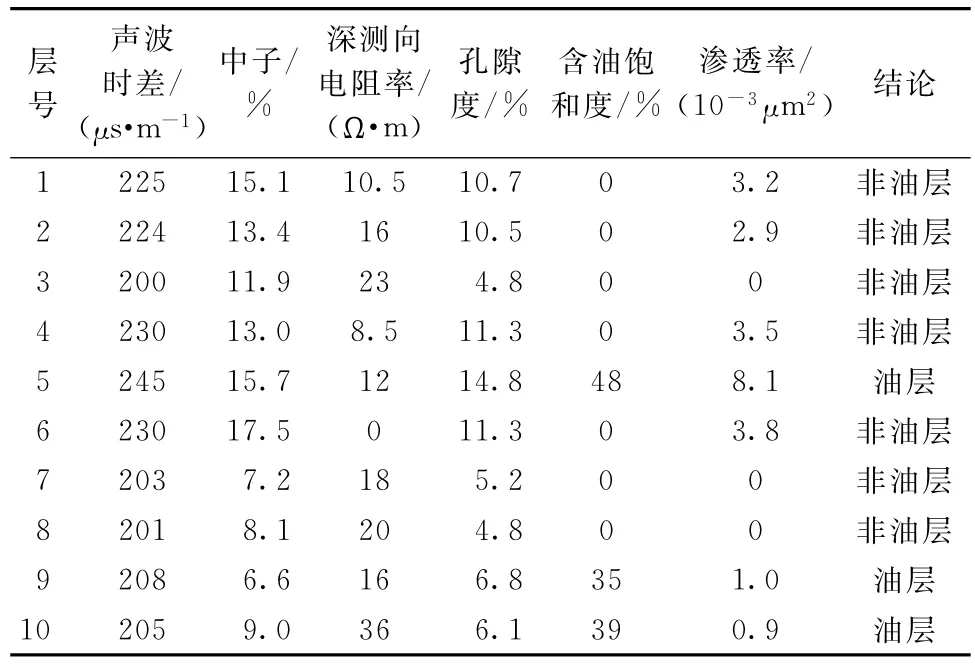
表7 oilsk85井测井解释成果表(只列出部分数据)
5.2 分类结果
本文用有导师学习的k-means方法的SkSVM、k-means以及SVM分类方法对江汉油田oilsk81,oilsk83和oilsk85三口井的数据进行油层和非油层的识别比较,其中,oilsk81井中随机选择20个样本作为训练数据,11个样本作为测试数据,oilsk83井中随机选择30个样本作为训练数据,20个样本作为测试数据,oilsk85井中随机选择45个样本作为训练数据,20个样本作为测试数据。k-means+all采用所有属性作为输入进行k-means分类,k-means+core采用核属性(声波时差和含油饱和度)进行k-means分类,其余方法的表达依此类推。实验所有的结果均为50次重复实验的平均值。由表8可见,本文提出的SkSVM方法无论是在所有属性作为输入还是核属性作为输入的条件下,对三口井的油层和非油层的识别率都是100%,充分说明了Sk SVM方法的鲁棒性和容错性比单独使用k-means和单独使用SVM要好,一定程度上避免了过学习的问题。
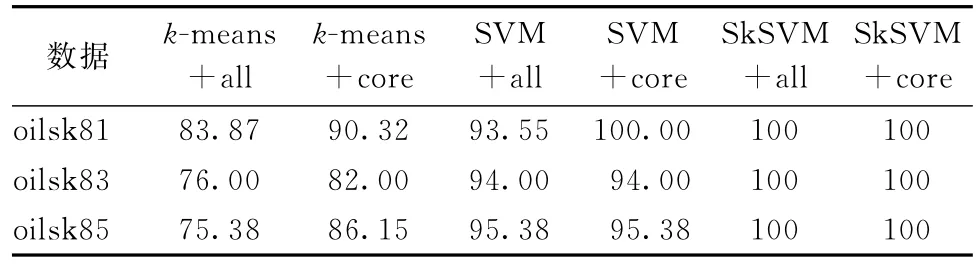
表8 对oilsk81,oilsk83,oilsk85三口油井的油层和非油层识别比较 %
6 结语
本文用一种容错性好、具有全局优化功能、带有指导信息的有导师学习的k-means方法对数据样本进行划分,针对每个划分建立线性SVM,将一个复杂的非线性问题分解为若干线性子问题进行求解,从而可以尽量避免过学习。SkSVM方法不仅拓展了SVM优化理论,同时也丰富了SVM的应用范畴。后续的研究将k-means的划分替换为KNN的划分、AP的划分以及FCM的划分等,然后进行深入的分析和比较。
