基于特定领域的加权语义相似度算法研究
2015-08-01高蕾娜史延枫李艳丹
高蕾娜,史延枫,李艳丹
(1.成都大学 机械工程学院,四川 成都 610106;2.华中科技大学 机械学院,湖北 武汉 430074)
0 引 言
自动问答系统的主要功能是让计算机能用自然语言来回答人们所提的问题.近年来,随着网络和信息技术的快速发展,结合人们快速获取信息的愿望更进一步促进了自动问答技术的发展[1].自动问答系统一般包括3 个主要部分:问题分析、信息检索和答案抽取.通过问题分析而得到的关键词集需要提交给信息检索模块来查找相关的文档,检索系统的任务就是在已有的文档库中搜索和关键词集相关的文档.为了保证对任何问题都能找到相关的文档,文档库必须足够大.文档库也可从互联网上下载,此时检索模块返回的是一堆相关的网页.自动问答系统中的信息检索模块所用方法通常是计算候选问题集中每个问句和目标问句之间的相似度,对应的相似度最大的问句就是要找的句子.目前常用的句子相似度计算方法分为2 种[2-4]:一种是基于向量空间模型的词频—逆向文件频率(Term Frequency-Inverse Document Frequency,TF-IDF)方法,一种是基于语义相似度的方法.第一种算法基于词频,没有考虑语义,适用于大规模语料库;第二种算法反映了语义间差异,但通常没有考虑到词语的权重信息.基于此,本研究将两者结合,提出一种基于特定领域的加权语义相似度算法.由于该算法不仅考虑词语语义,还考虑FAQ 库词语在句子中的权重信息,因而由此方法计算得到的相似度更具有合理性,并使查准率有所提高.
1 算法原理
基于特定领域的加权语义相似度计算方法建立在2 个词汇具有一定的语义相似性当且仅当它们在概念间的结构层次网络图中存在一条通路(主要是上下位关系)这一假设的基础上[5-6].分属于不同概念领域的2 个词汇之间不存在交集,因此它们之间的语义距离应为无穷大,其相似度为0.对于位于同一语义树的2 个义原,综合考虑义原树的深度和密度因素的影响,可计算出2 个义原的相似度[7].用户问句中不同词语对于整个问句的贡献是不同的,通常给主要词语赋予较高权重,次要词语赋予较低权重[8].一般而言,一个词在一篇文档中出现的频率越高,其权重越大;文档集中出现该词的文档越多,其权重越小.词语权重的计算公式为,
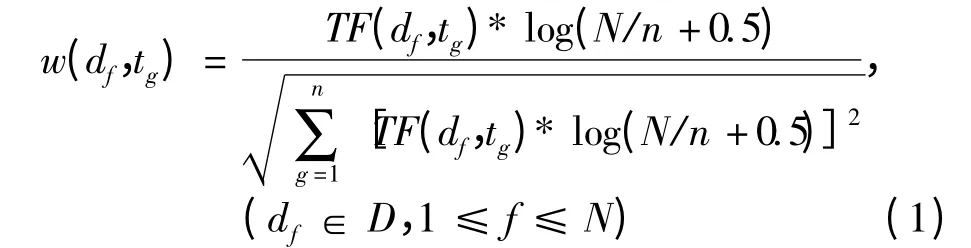
式中,w(df,tg)为文档df中词语tg的权重,TF(df,tg)为文档df中词语tg的词频,N 为文档集的文档数,n 为含有词语tg的文档数,分母为规一化因子,目的是将值限定在[0,1]中.
设用户问句,Q = {q1,q2,…,qm},qi为句子Q含的词语,1 ≤i ≤m;设FAQ 库中任一问句,Q' ={q'1,q'2,…,q'n},q'j为句子Q'的词语,1 ≤j ≤n.根据相关的词语权重计算方法可以得到序列,w ={w'1,w'2,…,w'n},其中w'j为q'j对应的权重.利用基于语义相似度方法,计算Q 和Q'中词qi(1 ≤i ≤m)和q'j(1 ≤j ≤n)之间的相似度用s(qi,q'j)来表示,从而得到一个m × n 的矩阵,
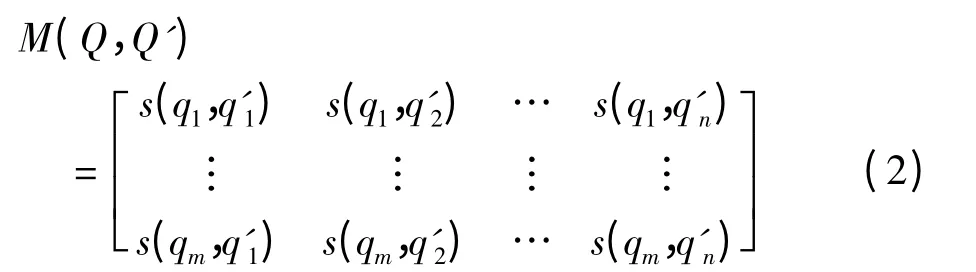
则句子Q 中所有词语与句子Q' 之间的相似度S(Q,Q')为,
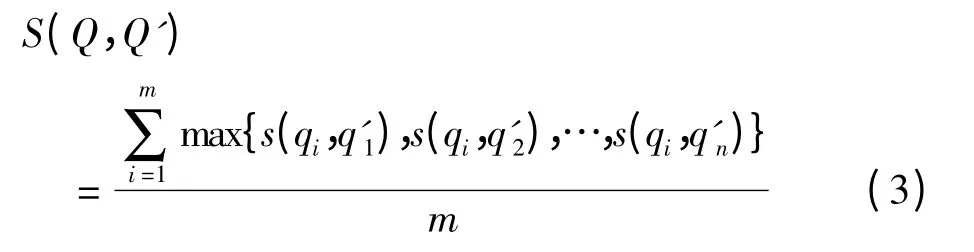
同样,以用户问句Q 为参照,计算Q'和Q 中词q'j(1≤j ≤n)和qi(1 ≤i ≤m)之间的相似度用s(q'j,qi)来表示,从而得到一个n ×m 的矩阵,
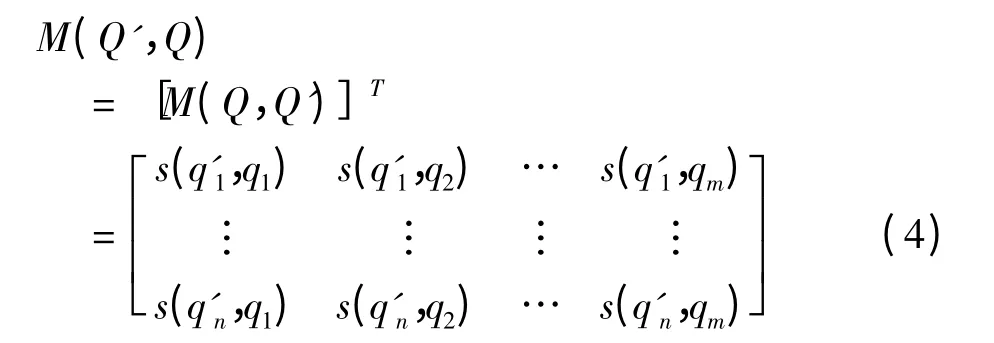
矩阵M(Q',Q)是M(Q,Q')的转置阵,且s(qi,q'j)= s(q'j,qi).句子Q'中所有词语与句子Q 之间的相似度S(Q',Q)为,
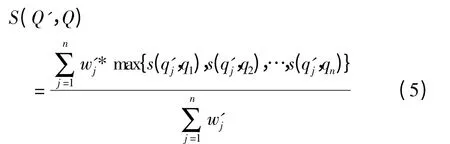
最后将两值求平均就可以得到2 个句子最终的相似度Similarity(Q,Q'),
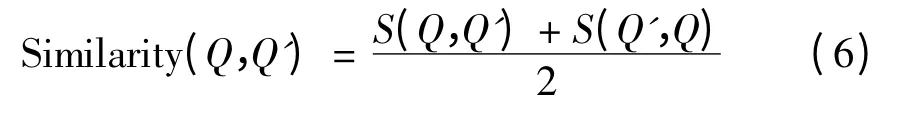
2 实验算例与分析
假设高血压领域FAQ 库中有3 个句子:
d1,高血压每一期的眼底动脉症状有哪些?
d2,高血压导致脑血管破裂造成眼底动脉硬化该怎么办?
d3,高血压对眼底动脉有影响吗?
用户问句Q:高血压分为3 种危险程度,眼底动脉在不同阶段有什么表现?
d1 包含的词有:{高血压,每一,期,眼底动脉,症状,有,哪些};
d2 包含的词有:{高血压,导致,脑血管,破裂,造成,眼底动脉,硬化,该,怎么办};
d3 包含的词有:{高血压,眼底动脉,有,影响};
Q 包含的词有:{高血压,3 种,危险,程度,眼底动脉,不同,阶段,有,什么,表现}.
FAQ 库所有问句包含的所有词有:{高血压,每一,期,眼底动脉,症状,有,哪些,导致,脑血管,破裂,造成,硬化,该,怎么办,影响}.
TF-IDF 和语义相似度计算的详细过程可参考文献[9],对于本研究提出的基于特定领域的加权语义相似度计算方法的具体步骤为:
d1 可表示为向量,

d2 可表示为向量,
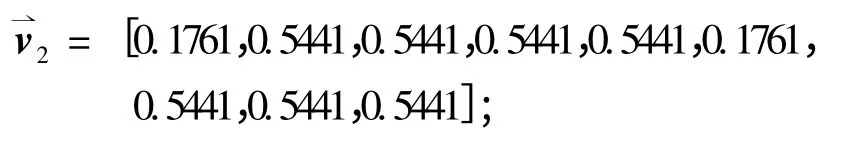
d3 可表示为向量,
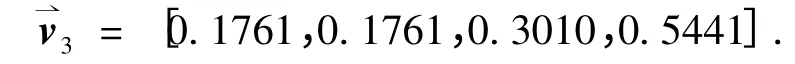
根据式(1)计算得到词语权重,

易知,Q 与d1 的语义相似度为,
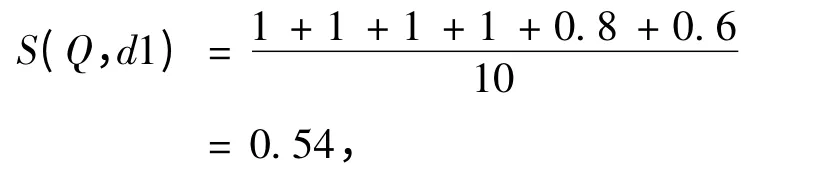
d1 与Q 构成相似度矩阵为,

d1 与Q 的语义相似度为,
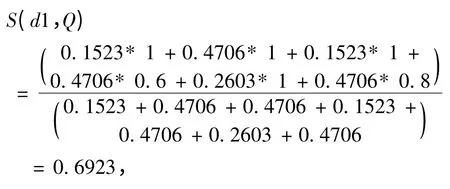
2 个句子最终的相似度为,
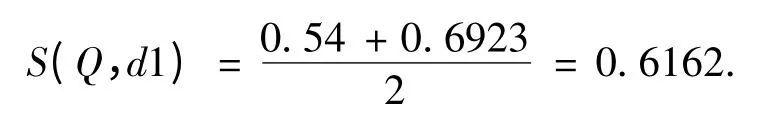
同理,Q 与d2 的语义相似度为,
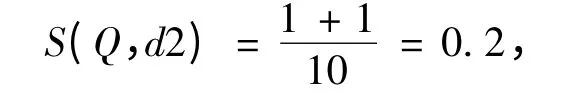
d2 与Q 构成相似度矩阵,
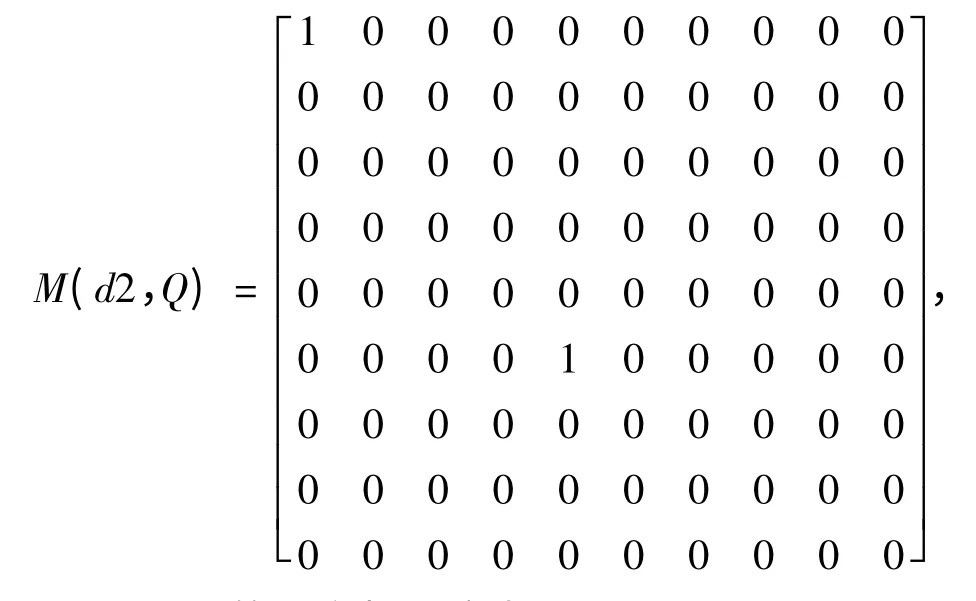
d2 与Q 的语义相似度为,
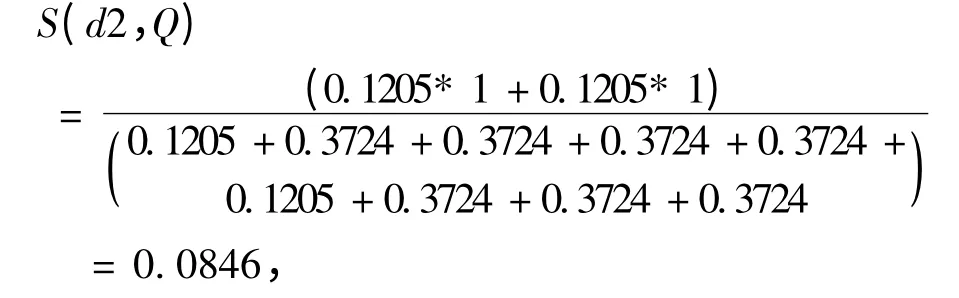
2 个句子最终的相似度为,
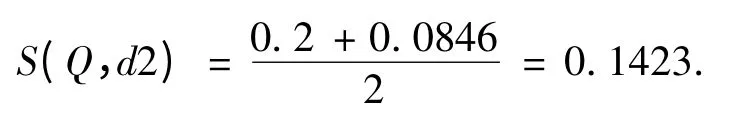
同理,Q 与d3 的语义相似度为,
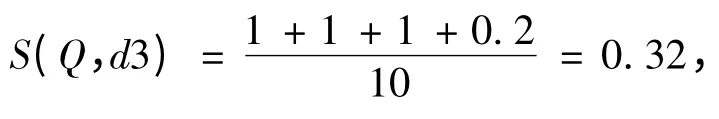
d3 与Q 构成相似度矩阵,
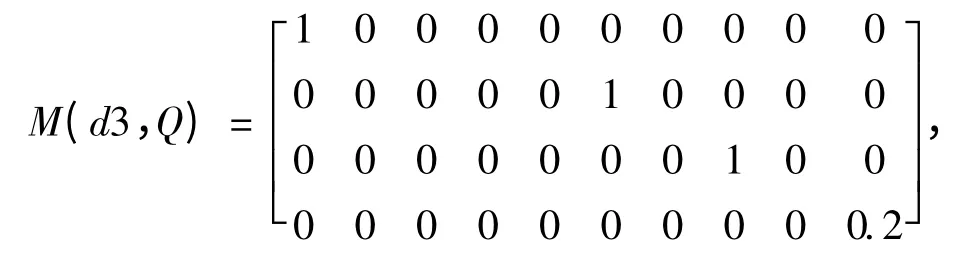
d3 与Q 的语义相似度为,
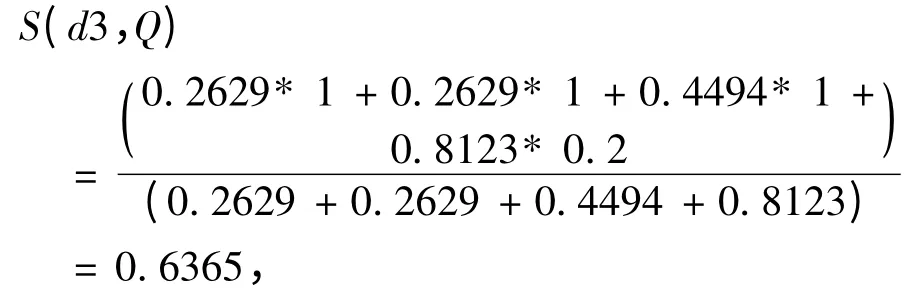
2 个句子最终的相似度为,
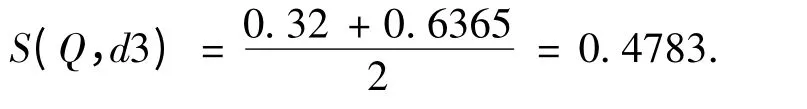
3 种相似度计算方法的结果如表1 所示.
由表1 可以看出,与用户问句Q 最为接近的FAQ 文件应为d1,而在表1 中TF-IDF 方法这一列,Q 与d3 计算的相似度大于与d1 计算得到的结果,显然与实际情况矛盾.对于语义相似度与加权语义相似度方法计算得到的结果符合实际情况,而加权语义相似度相对于前者,提高了与d1 的相似度,而对于不太相关的问题d2,反而减少了其相似度结果.通过上述分析可知,加权语义相似度可获得较为正确的匹配结果.
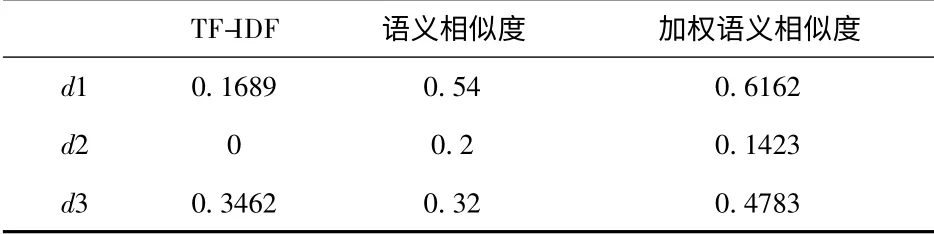
表1 3 种相似度计算方法结果比较
3 结 论
自动问答系统充分利用网络技术和人工智能的优势,使得用户疑问既能够得到及时有效的解答,又能节省时间、提高效率,而相似度匹配算法是信息检索模块的核心.本研究提出的基于特定领域的加权语义相似度计算方法由于考虑了词语语义和权重2方面的信息,因此可获得较好的匹配结果.
[1]郑实福,刘挺,秦兵,等.自动问答综述[J].中文信息学报,2002,16(6):46-52.
[2]王洋,秦兵,郑实福.句子相似度计算在FAQ 中的应用[EB/OL].[2014-03-16].http://ir.hit.edu.cn/phpwebsite/index.php?module = documents&JAS-Document-Manager-op=downloadFile&JAS-File-id=17.
[3]Voorhees E.The TREC-8 question answering track report[C]//Proceedings of the 8th Text Retrieval Conference.Gaithersburg,MD:NIST,2002.
[4]王品,黄广君.信息检索中的句子相似度计算[J].计算机工程,2011,37(12):38-40.
[5]Rada R,Mili H,Bicknell E.Development and application of a metric on semantic nets[J].IEEE Trans Syst Man Cybern,1989,19(1):17-30.
[6]李文清,孙新,张常有,等.一种本体概念的语义相似度计算方法[J].自动化学报,2012,38(2):229-235.
[7]葛斌,李芳芳,郭丝路,等.基于知网的词汇语义相似度计算方法研究[J].计算机应用研究,2010,27(9):2808-2810.
[8]张桂林.中文文本自动分类系统的研究与实现[D].吉林:吉林大学,2007.
[9]高蕾娜.老年慢性病无线监控远程关怀系统关键技术研究[D].武汉:华中科技大学,2009.
