一种基于文本聚类的web军事情报挖掘系统设计与实现
2015-06-23宋佳庆
傅 畅,宋佳庆
(1.中国电子科学研究院,北京 100041;2.电子科技大学,成都 611731))
工程与应用
一种基于文本聚类的web军事情报挖掘系统设计与实现
傅 畅1,2,宋佳庆1,2
(1.中国电子科学研究院,北京 100041;2.电子科技大学,成都 611731))
为了解决在海量web资源中提取出有用军事情报的问题,本文在分析军事情报和互联网信息特点的基础上,设计并实现了一个包括采集、处理、存储与检索的web军事情报挖掘模型,然后提出了一种面向军事情报应用的文本聚类方法,最后通过实验对聚类效果进行了评估,实验结果表明该方法在聚类纯度、准确率、召回率、F-score指标上有不同程度的提升。
军事情报;web信息;网络爬虫;k-means算法,文本聚类
0 引 言
军事情报是指运用在军事用途上的情报,属于情报活动的一种。军事情报包括一国的军队编制、训练、武器装备数量、武器类型、军事部署、作战计划、该国相关科技产业的技术水平以及该国的生产力等。收集军事情报的目的在于提供大量有用的资讯,并加以分析建议,以辅助决策者制定军事战略。
开源情报是指从公开可获得的来源收集信息,对这些信息进行开发并及时传递给特定用户以满足其情报需求的工作[1]。根据相关研究,目前西方发达国家的国家情报40%到95%都是以开源情报的形式获取的[2]。国内近年来也开展了许多相关的研究[3,4]。
随着互联网的发展,特别是社交网的发展,web逐渐成为了人们最重要的信息来源,Web中蕴含了大量的商业[5]、军事、行为等方面的信息,成为了最重要和最大的开源情报来源[6],同时数据挖掘技术的发展使得人们从海量web数据中寻找有用的信息成为了可能,特别是社交网的挖掘[7]成为了当前研究的热点。在这些web资源之中,蕴含了大量的军事情报相关信息,例如武器实验、武器装备部署等。文献[8]与[9]指出了大数据在情报中的作用。
聚类是数据挖掘中的一个重要主题,聚类算法被用来在给定数据集中发现相似项,并自动聚集成簇。为了实现聚类,人们提出了很多算法,这些算法大致可以分为基于划分的方法、层次聚类、基于网格的方法和基于密度的聚类方法等[10]。K-means是最著名的划分聚类算法,算法的简洁与高效使得它成为了使用最广泛的聚类算法。
为了解决在海量web资源中搜集有用军事情报的问题,本文设计了基于web的军事情报挖掘系统,同时本文通过改进k-means聚类算法,得到了更好的挖掘效果。本文第2节介绍了文本处理和网络爬虫的相关技术,第3节设计了一个web军事情报挖掘系统模型,第4节结合军事情报的特点,提出了一种针对军事情报的改进k-means算法,第5节对系统进行了实现并对聚类算法效果进行了实验评估。
1 W eb信息处理相关技术简介
Web信息分布在大量的网页之中,为了实现对web情报的挖掘,首先需要采集这些网页,然后对得到的数据进行统一处理。这些采集到的网页是半结构化或非结构化数据,所以不能直接用于挖掘,需要先对文本进行预处理,该过程包括文本分词、去停用词、特征提取、统计词频、建立向量空间模型等,文献[11]对相关主题做了详尽的介绍。下面简单介绍web信息处理所涉及的相关技术。
1.1 网络爬虫
网络爬虫,也叫网络机器人、网络蜘蛛,是自动下载网页的程序。在对web数据进行挖掘时,首先需要对web数据进行采集。网页之间的链接关系形成一个巨大的图,因此网页抓取就是对这个图进行遍历,基本算法是广度优先遍历与深度优先遍历。目前有非常多的优秀开源网络爬虫框架,如Nutch、scrapy、Heritrix等。根据爬虫的用途不同,可以分为通用爬虫、限定爬虫与主题爬虫[12]等。
1.2 文本向量空间模型
Gerard Salton[13]提出了文本向量空间模型(vector spacemodel,VSM),该模型成为了信息检索中的基本模型,其主要思想是将每一篇文档映射到向量空间中的一个向量。
对每一篇文档Di,用文档中的词项与对应的权重可以得到一个向量:
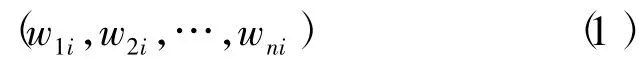
其中wki为词项k在文档Di中的权重分量。计算权重的经典算法是tf-idf,定义如下:

tf指的是词项频率(term frequency),表示t在文档中出现的次数,idf指的是逆文档频率(inverse document frequency),表示词项的区分能力,定义如下:

因此,一个高频词的idf相对较低,低频词的idf相对较高。这样,文档就能处理成一个向量的形式。而N篇文档的文档集合则可以看成是M×N词项-文档矩阵,矩阵的每一行代表一个词,每一列代表一篇文档。
1.3 文档相似性度量
为了计算文档之间的相似性,需要引入相似性的计算方法,常见的方法是采用余弦相似度:
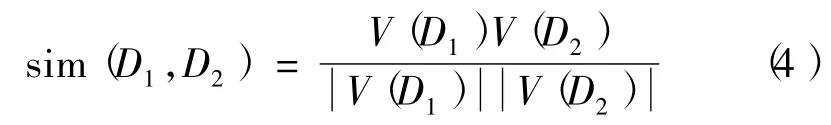
2 面向军事情报的web挖掘系统设计
根据军事情报的定义与作用,军事情报针对国家与军队的战略目标需要而收集,要求资讯内容的客观、分析判断的精准、报告推理的正确。
由于web信息来源广泛,且web信息没有经过严格的筛选,所以在目的性与准确性上相对于传统情报较低,必须经过一定的处理,因此,可以设计出如下流程的一个web情报挖掘模型,如图1所示。

图1 web情报处理流程
2.1 web情报采集模块设计
Web情报的采集模块是情报的来源,主要通过网络爬虫从军事门户、军事论坛、wiki百科等相关网站构建军事情报数据源[14],提出一个挖掘wiki的工具。在本文研究中,基于Scrapy构建了一个自动采集环球军事、网易军事、超级大本营论坛等相关网站的网络爬虫,并用环球军事对聚类效果进行了评价。情报的采集模块如图2所示。
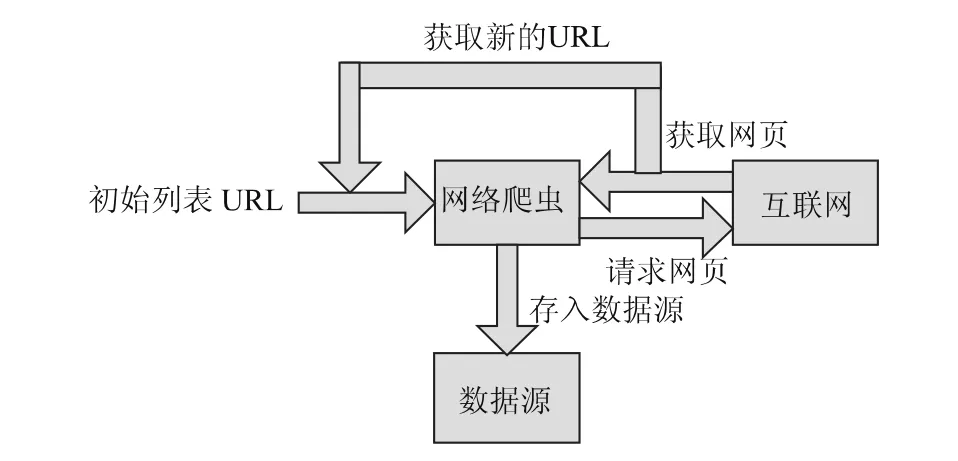
图2 web情报采集模块设计
2.2 情报信息处理模块设计
在通过网络爬虫采集到数据源之后,就要针对文本进行集中处理、挖掘,主要过程如图3所示。
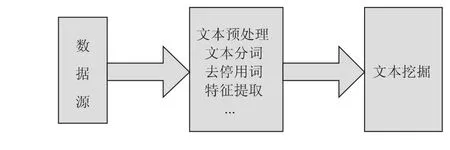
图3 web情报信息处理模块设计
2.3 情报信息存储与检索模块设计
经过处理之后的情报需要进行存储与检索,以供情报分析人员使用,由于web数据是非结构或半结构化的信息,所以本系统采用面向文档的数据库MongoDB,MongoDB可以对文档进行灵活的存储,同时MongoDB提供丰富的数据库访问的接口,在构建系统的时候可以将低级的数据库操作封装成更友好的API,方便针对不同应用场景进行二次开发,如图4所示。
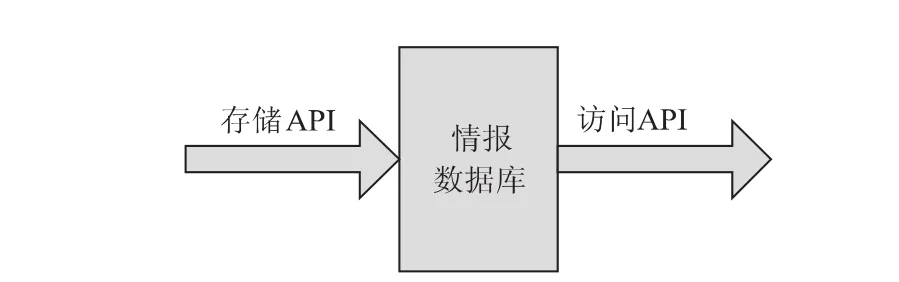
图4 web情报信息存储与检索模块设计
3 面向军事情报的文本聚类算法设计
3.1 k-means算法简介
K-means算法的思想是在一个数据集中选择k个对象作为初始的聚类中心,然后每次将其他对象划分到离其最近的中心中,形成k个簇,然后针对k个簇,计算簇中所有点的均值,作为新的聚类中心,直到目标函数收敛,完成聚类。K-means算法的主要优势在于它的简洁和效率,其时间复杂度为O(kn),由于k一般远小于n,因此它被认为相对于数据点数目是线性的。
具体算法过程如下:

3.2 改进文本聚类算法设计
传统文本挖掘算法中没有考虑同义词之间的关系,而军事情报中存在大量的同义或近义词,特别许多中英文名词实际上表示同一个事物,例如“F-22”又叫做“猛禽”,“LGM-30 Minuteman”与“民兵3”表示同一导弹型号。同时传统聚类算法由于随机选择初始中心,容易陷入局部最优,影响聚类效果,文献[15]针对该不足提出了一种选取初始中心的方法来改进聚类效果,文献[16]则通过检测聚类的形状、密度、大小来改进了k-means。本文通过调查多个军事网站发现,web军事情报在经过处理之前可以得到一些先验知识,例如“南海”与“美国”、“日本”等相关度较高,而“东风5B将亮相9·3阅兵,能直接打击美国全境”与“朝鲜超百万青年入伍集体练枪”这两则情报消息则不属于同一类别,但是在网站中可能属于同一版块,本文通过事先人工分析一些先验知识,从而改进初始聚类中心的选取与聚类效果。
根据以上分析,本文采取以下策略改进聚类效果:
首先构建一个军事同义词转换表,在文本分词之前将同义词替换为一个统一的词项,再计算tf-idf权重,该方法不仅可以提高聚类效果,而且缩减了词项规模。
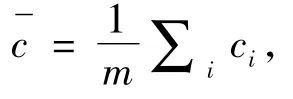
4 系统实现与效果评估
本文通过使用开源工具,实现了系统的关键代码,对上述模型的关键部分进行了实现。
4.1 网络爬虫模块构建
目前网上已经有了很多开源的网络爬虫工具,本文实现基于Scrapy框架,这是基于twisted异步网络通信框架的一个高性能网络爬虫框架,支持自定义抓取规则、数据库以及抓取策略等功能。
以环球军事为例,抓取其8月份军事新闻标题与正文,抓取核心代码如下:

以mil.huanqiu.com限定域名,并以此为初始URL,用户也可以通过rules自定义更多的域名与抓取规则,例如可以加入网易军事、铁血论坛等网站。通过VMware虚拟机中的Debian系统运行该网络爬虫,抓取8月1日至23日新闻耗时1小时,通过RockMongo管理抓取得到的数据库,发现web数据已经存入数据库。
4.2 文本预处理
首先将文本中的同义词替换成为同一个词,然后用结巴中文分词工具对中文文本进行切分、去停用词,通过tf-idf算法构建出词项文本矩阵。

在分词与计算tf-idf时,用到了jieba与sklearn两个扩展包,由于代码量较大,仅列出计算部分代码如下:

其中corpus是存储文档集合的列表。
4.3 聚类算法实验结果
4.3.1 实验结果评价指标
在评价聚类质量时,纯度是一个简单、清晰的评价指标。纯度反应了正确分类的精度,较差的聚类结果将会得到接近于0的纯度,而最好的结果纯度为1。纯度的定义为:
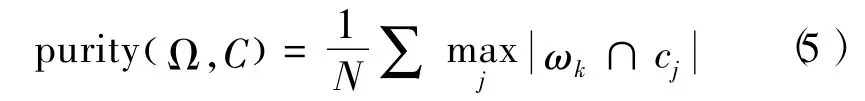
其中Ω=(ω1,ω2,…,ωK)是指聚类的结果,即文档簇,而C={c1,c2,…,cJ}是类别集合。
另一个常用的评价指标是准确率P与召回率R,分别定义为:

其中TP表示将相似文档归入相同簇,TN表示将不相似文档归入不同簇,FP表示将不相似文档归入相同簇,FN表示将相似文档归入不同簇。
F-score综合了准确率与召回率,定义为二者的调和平均:
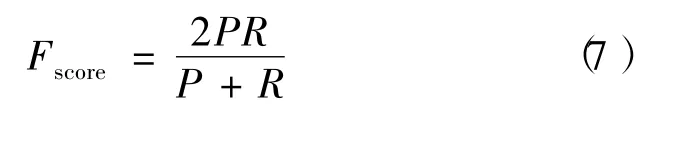
4.3.2 实验结果与分析
分别抓取环球军事网站上中国军事、国际军事、军事评论、兵器库、战略与格局、航空航天六个栏目一个月的数据,并存入MongoDB数据库中,按照栏目分类作为正确标注结果,然后将其混合在一起,进行文本聚类实验。
本文通过四十次实验,分别计算纯度、准确率、召回率、F-score的平均值,对比了原始k-means算法、文献[11]中提出的基于“最大最小”选取初始中心的k-means算法(以下简称“最大最小”算法)与本文提出的改进算法的聚类效果,得出结果如表1所示。
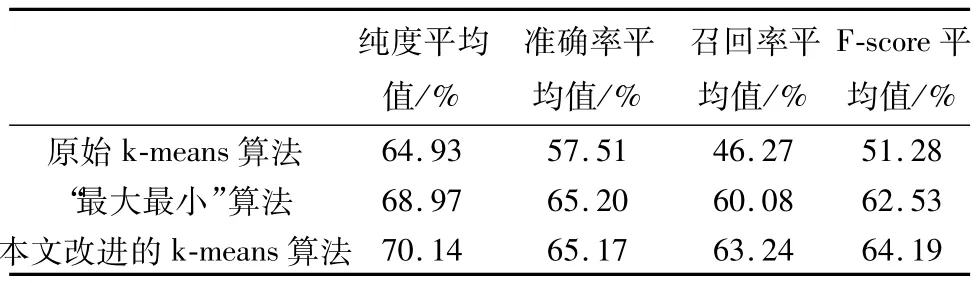
表1 实验结果对比表
通过实验结果可以看出,本文改进的k-means算法在纯度指标上比原始k-means算法高8%,比“最大最小”算法提高了1.7%;在准确率上相对于原始算法提高13.3%,相对于“最大最小”算法有小幅降低;在召回率上相对于原始算法提高了36.7%,相对于“最大最小”算法提高了5.3%;F-score相对于原始算法提高了23.3%,相对于“最大最小”算法提高了2.7%。
进一步分析,纯度指标上本文算法改进不明显,这是因为纯度指标在簇的数目变大时会提高,所以在簇数目较多的时候不宜用纯度来衡量聚类效果。而在更准确的衡量指标上,虽然准确率相对于“最大最小”略有降低,但是在准确率和召回率的综合效果即F-score上,本文提出的算法有一定的提升。由此可知,本文提出的算法在针对web军事情报的挖掘上有较好的实验结果。
5 结 语
本文在结合军事情报与web信息的基础上,设计和实现了一个web军事情报挖掘模型,然后通过构建军事同义词表、分析军事情报先验信息,提出了一种针对军事情报的k-means聚类改进算法。本文最后对系统进行了实现并对聚类算法效果进行了实验评估,实验结果表明该方法在聚类效果上具有一定的提升。
[1] 国外开源情报工作的发展与我国的对策研究,丁波涛,情报资料工作,2011年6期.
[2] 王飞跃.开源情报与网络时代的国家安全[J].科学新闻,2007,(3):9-9.
[3] 唐超.基于开源情报的风险监测-预警-决策系统构建[J].情报杂志,2013,32(1):145-149.
[4] 张恒.基于开源情报的情报处理系统模型构建[J].情报杂志,2014(3).
[5] Chau M,Xu J.Business intelligence in blogs:Understanding consumer interactions and communities[J].MIS Quarterly:Management Information Systems,2012,36(4):1189-1216.
[6] Clark R M.Intelligence analysis:a target-centric approach[M].CQ press,2012
[7] Russell M A.Mining the SocialWeb:Data Mining Facebook,Twitter,LinkedIn,Google+,GitHub,and More[M].“O’Reilly Media,Inc.”,2013.
[8] 陈奇伟,代科学,计宏亮,等.关于联合情报体系建设的几点认识[J].中国电子科学研究院学报,2015,10(1):1-5.
[9] 张春磊,杨小牛.大数据分析(BDA)及其在情报领域的应用[J].中国电子科学研究院学报,2013(1):18-22.
[10]《web数据挖掘(第2版)》,Bing Liu著,清华大学出版社.
[11]Manning C D,Raghavan P,Schütze H.Introduction to information retrieval[M].Cambridge:Cambridge university press,2008.
[12]Menczer F,Pant G,Srinivasan P.Topicalweb crawlers:Evaluating adaptive algorithms[J].ACM Trans.on Internet Technologies,2003.
[13]Salton G,Wong A,Yang C S.A vector spacemodel for automatic indexing[J].Communications of the ACM,1975,18(11):613-620.
[14]Milne D,Witten IH.An open-source toolkit for mining Wikipedia[J]. Artificial Intelligence,2013,194:222-239
[15]一种基于改进k-means的文档聚类算法的实现研究,岑咏华等,现代图书情报技术,2008年12期。
[16]Lin Y,Luo T,Yao S,et al.An improved clustering method based on k-means[C]//Fuzzy Systems and Knowledge Discovery(FSKD),2012 9th International Conference on.IEEE,2012:734-737.

傅 畅(1991—),男,重庆人,电子科技大学在读硕士研究生,主要研究方向为通信与信息系统;
E-mail:fc500110@163.com
宋佳庆(1991—),男,河北唐山人,电子科技大学在读硕士研究生,主要研究方向为信号与信息处理。
Design and Realization of W eb M ilitary Intelligence M ining System Based on Document Clustering
FU Chang1,2,SONG Jia-qing1,2
(1.China Academy of Electronics and Information Technology,Beijing 100041,China;2.University of Electronic Science and Technology of China,Chengdu 611731,China)
In order to extract the usefulmilitary intelligence from massiveweb resources and based on the analysis ofmilitary intelligence,characteristics of Internet information,this paper designs and realizes a web miningmodel ofmilitary intelligence including acquisition,processing,storage and retrieval.Then we put forward a kind of text clusteringmethod which orientedmilitary intelligence application and evaluated the clustering effect by experiments ultimately.The experiment results demonstrated that thismethod have improved the purity of clustering,accuracy,recall rate and F-score index to different extent.
Military intelligence;web Information;web crawler;k-means;document-clustering
TP311
A
1673-5692(2015)05-541-05
10.3969/j.issn.1673-5692.2015.05.016
2015-07-13
2015-09-30
