基于组织协同进化的软件缺陷预测方法*
2015-06-23常瑞花
常瑞花
(武警工程大学科研部,西安 710086)
基于组织协同进化的软件缺陷预测方法*
常瑞花
(武警工程大学科研部,西安 710086)
针对传统有标识软件度量元数据存在软件缺陷预测精度低的问题,首先对比选择合适的离散化方法,然后将组织协同进化分类算法引入并应用到航天软件缺陷预测领域,给出了一种基于组织协同进化的软件缺陷预测方法。该方法根据预测目标将离散后的软件度量元数据划分为不同种群,在各种群内部形成进化个体(组织)。组织在增减算子、交换算子、合并算子和组织选择机制的作用下不断进化,并基于属性重要度协同进化的方式进行适应度函数的计算,实现了有标识软件度量元数据缺陷预测精度的提高。最后通过两组仿真实验,验证了基于组织协同进化航天软件缺陷预测方法的有效性。
软件缺陷,预测,度量元,协同进化
0 引言
研究表明普遍存在的软件缺陷,已成为制约航天软件可靠性的瓶颈。而当前常用的检验、验证手段往往难以发现并排除所有的软件缺陷。为此,软件缺陷预测技术应运而生,成为当前国内外研究的热点[1-4],并相应提出了许多软件缺陷预测方法,例如,分类回归树,决策树,人工神经网络等等。然而有标识软件度量元数据的缺陷预测问题依然没有得到彻底解决,存在预测精度不高的问题。
近年来为了提高遗传算法的性能,兴起一个新的研究热点——协同进化算法[5]。它与传统进化算法的区别在于:协同进化在进化算法的基础上,考虑了种群与环境之间、种群与种群之间在进化过程中的协调。由于协同进化算法的优越性,自提出以来便引起了许多学者的重视,在文本分类、生产调度等领域[6-8]得到广泛的应用,然而协同进化算法在软件缺陷预测领域中的研究还很少。
文献[9]提出了组织协同进化分类(Organizational Co-Evolutionary algorithm for Classification,OCEC)算法,该算法与现有遗传分类算法的运行机制不同,它从数据本身出发采用“自上而下”的进化机制,进化操作直接作用于数据,避免了进化过程中产生无意义的规则,而且进化个体不需要编码,个体以组织的形式在三种组织进化算子以及组织选择机制下协同进化,同时基于属性重要度的协同进化完成适应度函数的计算。该算法在UCI数据集、遥感图像和雷达图像识别上,与现有基于遗传和非遗传的分类方法进行了比较,获得了很好的分类结果。之后,许多学者在该算法的基础上展开研究。例如:文献[10]针对该算法进化算子参数恒定不符合实际情况的问题,改进了进化算子,并将其应用到Web日志挖掘中。文献[11]将该算法应用于遮挡点恢复,提出一种组织进化的遮挡点恢复算法,较好地恢复了遮挡点的位置。
鉴于组织协同进化分类算法良好的性能,例如没有复杂的计算,运算效率比较高,同时针对传统有标识软件度量元数据缺陷预测精度有待进一步提高的问题,并结合软件度量元数据的特点,本文首先对比选择一种适用于软件度量元数据的离散化方法,然后将该算法引入并应用于软件缺陷预测领域中,给出了一种基于组织协同进化的软件缺陷预测方法,同时将该方法与基准的软件缺陷预测方法进行对比,分析该方法的优缺点。
1 基于组织协同进化的软件缺陷预测方法
下面给出基于组织协同进化的软件缺陷预测方法的结构图,如图1所示。
在基于组织协同进化的软件缺陷预测方法中,首先需要对软件度量元和缺陷数据集进行离散化处理,通过本文后面的实验可以发现,合理的离散化是一个重要的过程,离散的结果直接影响着组织协同进化分类算法的性能。在基于组织协同进化的软件缺陷预测方法中,本文从三种常用的离散化方法中对比选择出类-属性相依性最大方法(Class-Attribute Interdependence Maximization,CAIM)用于软件度量元数据的离散化处理。经过离散化处理后,根据软件缺陷预测目标将软件度量元和缺陷数据划分为有缺陷(Defective)和无缺陷(Non-Defective)两个种群。在每个种群的进化过程中,数据个体形成进化个体组织,组织在三种进化算子(合并算子、增减算子和交换算子)以及相应的选择机制下不断进化。适应度函数是基于组织的属性重要度计算的,各属性的重要度不是提前赋予的固定值而是不断进化的,且属性重要度的进化指导和影响着缺陷和无缺陷两个种群的进化,最后使得两个种群共同达到一个最优的状态。在属性重要度的计算过程中,同时进行着有用属性的计算和标记。在该方法中,组织是进化的个体,组织不需要编码,进化结束后可以从组织中提取出预测规则。
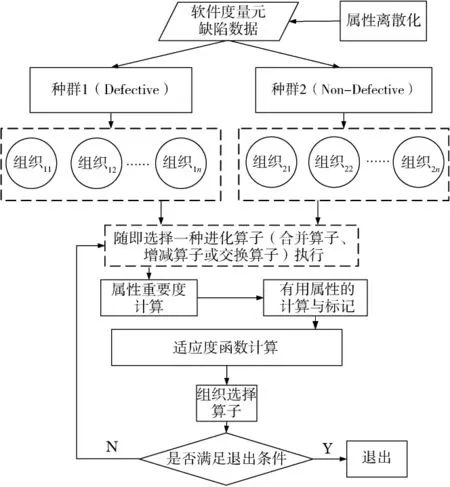
图1 基于组织协同进化的软件缺陷预测方法
需要指出的是,在软件缺陷预测的过程中,由于不同组织所含的软件度量元和缺陷数据个数是不相同的,有的多有的少。因此,在组织进化的增减算子和交换算子计算的过程中,如果按照文献[9]的方法,则为一常数且只能取规模最小的组织所含对象的个数,通常为1,这在许多情况下是不符合实际情况的。鉴于此,本文采用文献[10]的方法,即将N定为当前组织所含个数与一个百分数的乘积取整,最小为1,这样当组织规模变化时,组织参与进化操作的对象个数也是自适应动态变化的,在软件缺陷预测的过程中,将该百分比设定为20%。
另外,在软件缺陷预测过程中,当种群中只剩下一个组织时,不再进行上述三种进化算子,该组织个体直接进入下一代。否则,通过组织选择机制从上述三种进化算子产生的子代与父代中选择最优个体进入下一代。
2 仿真实验与分析
实验用机配置为:Pentium(R)3.2 G CPU、1G DDR内存、Windows XP操作系统,本文方法在Mat-Lab 7.0环境下运行。软件缺陷预测方法运行之前,首先对所选的软件度量元数据集进行其他必要的预处理,包括数据类别数值化即将类别的文字标识(True/False或者Defective/Non-Defective)替换为数值标识(1/0)、以及缺失数据、重复数据和冲突数据的检测和处理。
2.1 仿真实验1
软件度量元数据是连续的,而组织协同进化分类算法仅能处理离散数据,因此,离散化是基于组织协同进化软件缺陷预测方法的一个首要且关键的步骤。为了对比分析离散化过程对该算法性能的影响,下面选择三种常用的典型离散化方法进行对比仿真实验,离散化方法分别为:①等宽离散化(Equal Width Discretization,EWD)方法;②等频离散化(E-qual Frequency Discretization,EFD)方法;③类-属性相依性最大(Class-Attribute Interdependence Maximization,CAIM)方法。
目前,UCI数据库[12]中的机器学习数据集被广泛应用于算法性能的测试。本文选择了两组最常用的Iris和Wine数据集进行仿真实验。
Iris是鸢尾花数据集,包含150个样本,它用萼片的长度、宽度和花瓣的长度、宽度4个连续的条件属性来区分3种不同的花,每种花的比例均为1/3,其中有两个条件属性与分类结果相关性较强;Wine是葡萄酒数据集,包含178个样本,分为3类,共13个属性。
算法参数设置如下:最大运行代数E设置为500,N=20,在等宽和等频离散化方法中,区间数K=4。采用准确率(%)和标准方差对算法性能进行评测,准确率指标Accuracy=N1/N2,其中,N1为正确分类的样本数,N2为全部样本数。为了更准确地衡量算法的性能,实验均采用了十折交叉验证,并给出了算法10次独立运行的平均准确率。仿真结果如表1所示。
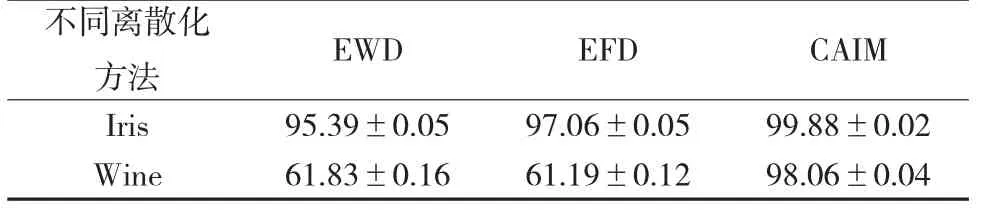
表1 不同离散化处理的分类结果
由上述仿真结果可以看出,在Iris数据和Wine数据上,CAIM离散化方法均是最有效的,组织协同进化分类算法在CAIM离散处理的数据上,具有最高的准确率和最低的标准方差,说明了CAIM离散化方法的高效性和稳定性。
进一步对比和分析这三种离散化方法可以发现,EWD和EFD方法都是无监督离散化方法,实现简单,但需要人为设置划分维数。二者根据给定的参数将各属性的值域等距离或等频率划分为几个离散的区间,忽视了样本分布信息,因而,难以将区间边界设置在最合适的位置上,从而使得离散后的结果没有保障,例如本实验中Wine数据上的分类结果则无法令人满意。CAIM离散化方法与其他两种方法不同,它是在信息熵量度的基础上提出的,是一种全局的、静态的、自下而上的有监督离散化方法,在离散过程中不需要人为输入参数,它以达到类与属性相关度最大化和最少的断点为目标,按顺序对每一个连续属性进行离散化,采用caim离散判别式作为离散标准,迭代过程自动选择离散断点,直到满足停止条件为止。
下面给出经过CAIM离散处理后Iris和Wine数据各属性的属性重要度变化情况。首先对于Iris数据而言,如图2所示。
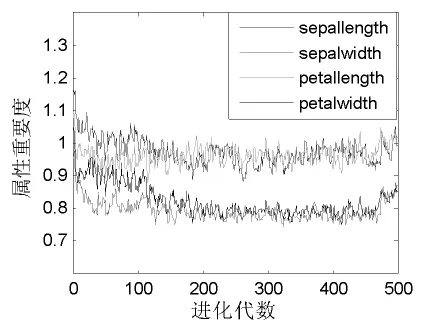
图2 Iris数据属性重要度的进化图
由图2可以看出,Iris数据sepallength的属性重要度值在前150代内明显最高,在后面300多代的进化过程中,其与petallength的属性重要度不分上下。这与主成分分析等方法的判别结果是一致的,即这两个属性与分类结果相关性较强。
图3给出了算法结束后,Iris数据在第500代时各属性的属性重要度。

图3 Iris数据第500代属性重要度
首先需要说明的是,在图3中属性1到属性4,分别对应属性sepallength、sepalwidth、petallength和petalwidth,可以看出属性1和属性3的重要度值较高,为影响分类结果的两个主要属性。
对于Wine数据而言,Wine数据属性较多,而且在仿真实验过程中,发现大部分属性在进化过程中属性重要度的变化范围和变化幅度是相近的,因此,限于篇幅的考虑,仅给出了属性1,2,5,8,12的属性重要度变化图,如图4所示。需要说明的是:这5个属性分别是Wine数据从左到右第1,2,5,8,12位置对应的条件属性。
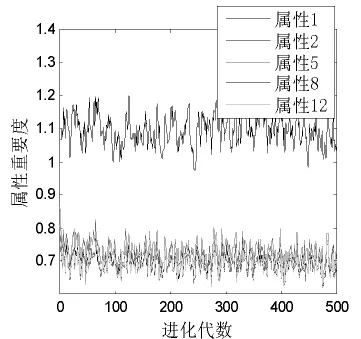
图4 Wine数据属性重要度的进化图
由图4可以看出,属性1的重要度在500代的进化过程都明显高于其他属性,而其他的属性在进化过程中属性重要度的变化范围和变化幅度是相近的。图5给出了进化过程结束后,Wine数据集在第500代各属性的属性重要度值。

图5 Wine数据第500代属性重要度
总之,由图4和图5不难看出,对分类结果影响最大的属性是属性1。
2.2 仿真实验2
为了验证基于组织协同进化的软件缺陷预测方法的有效性,在公开的Promise[13]数据库中随机选择7组航空航天数据,与文献[14]即软件缺陷预测的基准方法(即朴素贝叶斯方法)进行对比,当前国内外的许多文献均选择与朴素贝叶斯方法对比,进行方法优劣的判断。这7组数据的基本特征如表2所示,软件度量元特征如表3所示。

表2 软件数据集
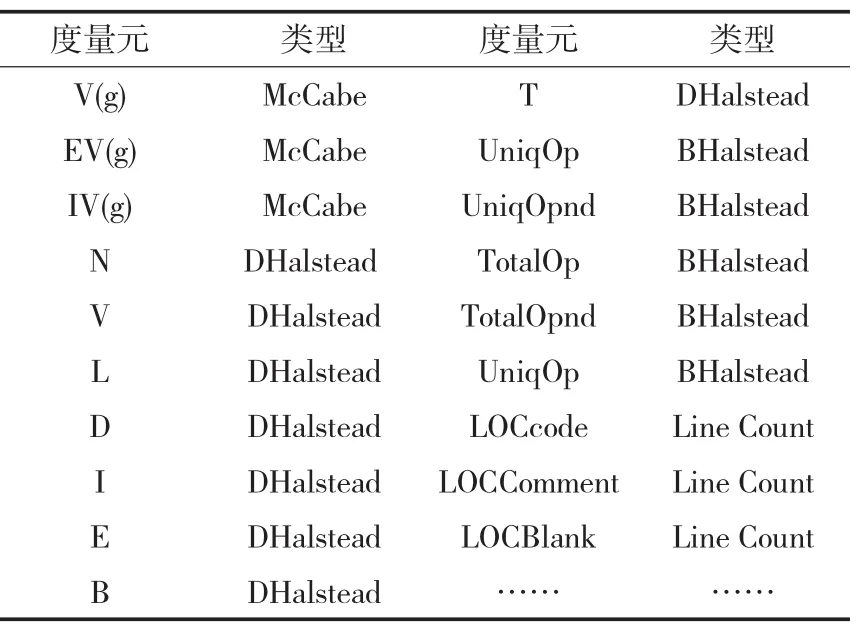
表3 软件度量元
在文献[14]中,预测算法的评价指标为(PD,PF,Balance),为了便于对比,本文也给出在该组评价指标下的预测结果,下面首先给出二维混淆矩阵,并由此推导出该指标,具体如下。

表4 二维混淆矩阵

对于PD和PF指标而言,PD值越高且PF值越低,则认为该预测模型越好,然而精确率PD值的增加,往往会导致虚警率即PF值的增加,而Balance值可以实现二者的折中,因此,本文给出三者的仿真结果。
在该实验中,基于组织协同进化的软件缺陷预测方法的参数设置如下:CAIM离散化方法,最大进化代数为500,N=20,采用十折交叉验证方法,并给出了算法10次独立运行的平均值。仿真结果如表5所示。
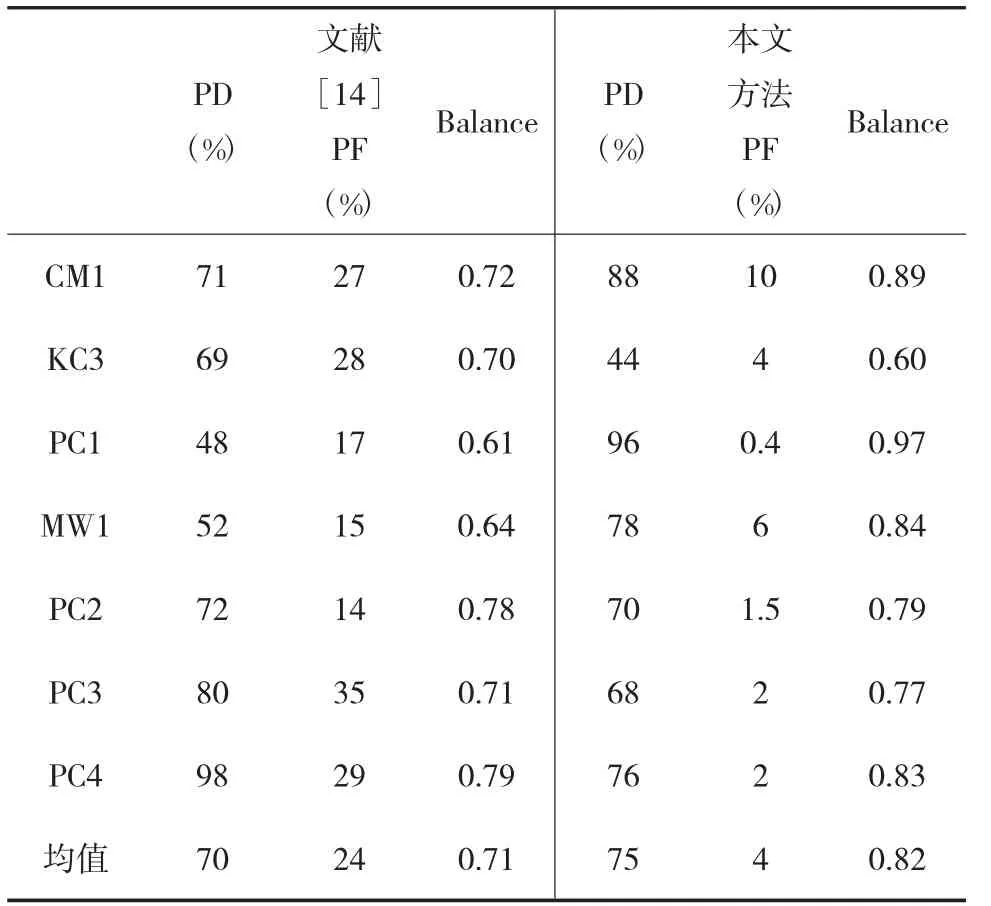
表5 结果对比
在表5中,左侧为对比算法文献[14]的预测结果,右侧为本文方法的仿真结果。首先从表5中可以看出,对于数据PC2、PC3和PC4而言,文献[14]取得了较高的PD值,但其PF值也很高,导致Balance值均低于本文基于组织协同进化的软件缺陷预测方法。对于数据CM1、PC1和MW1而言,与文献[14]相比,本文基于组织协同进化的软件缺陷预测方法在提高PD值的同时降低了PF值,因此,大大提高了Balance值。但对于KC3数据而言,本文基于组织协同进化的软件缺陷预测方法仅降低了PF值,PD值低于文献[14],导致Balance值也低于文献[14]。
但从总体上看,本文基于组织协同进化的软件缺陷预测方法在这7组数据上获得了较高的PD平均值(75),较低的PF平均值(4)和较高的Balance平均值(0.82),远远优于对比算法:PD平均值(70),较低的PF平均值(24)和较高的Balance平均值(0.71),因此,从总体上看将组织协同进化分类算法应用于软件缺陷预测领域是可行的。
2.3 实验结果分析
对上述的仿真实验结果分析,首先由仿真实验1可以看出,文献[9]算法仅能处理离散数据,而且算法性能易受离散化结果的影响,因此,对于连续的软件度量元数据选择合适的离散化方法是首要的。
由仿真实验2可以看出,离散化方法CAIM方法与文献[9]算法相结合并应用于软件缺陷预测中是可行的。因为基于组织协同进化的软件缺陷预测方法在大部分软件度量元和缺陷数据集上的预测结果是优秀的,在提高Balance值的同时,降低了软件缺陷预测的虚警率即PF值,大大降低了软件开发和维护的成本。
然而基于组织协同进化的软件缺陷预测方法并不是万能的(例如对于KC3数据)。分析其原因可以发现组织协同进化分类算法在进化过程中,对当前用于模型训练的软件度量元数据样本的要求是很高的,当样本数量不足,或者是样本质量不高时,例如取样不均匀时容易出现过拟合现象。因此,该算法对于大样本或者高质量的软件缺陷数据性能较好,对于小样本数据或噪声数据较多的样本容易出现过学习或过拟合,导致其预测性能的降低。
3 结束语
本文将组织协同进化分类算法引入并应用到软件缺陷预测领域,给出了一种基于组织协同进化的软件缺陷预测方法。首先根据软件度量元和缺陷数据的特点,对比选择了CAIM方法用于度量元数据的离散化,然后将离散后的软件度量元数据以组织的形式表示,在三种组织进化算子和选择机制的作用下协同进化,并在属性重要度协同进化的基础上完成了适应度函数的计算。最后通过两组仿真实验,在不同数据上对基于组织协同进化的软件缺陷预测方法的性能进行分析和对比,仿真结果表明,该方法进一步提高了航空航天软件缺陷预测的精度,为传统有标识软件度量元缺陷预测问题的解决提供了新的思路。
[1]Parag C P.Exhaustive and Heuristic Search Approaches for Learning a Software Defect Prediction Model[J].Engineering Application of Artificial Intelligence,2010,23(1):34-40.
[2]Daniel R,Roberto R,Jose C R,et al.A Study of Subgroup Discovery Approaches for Defect Prediction[J].Information and Software Technology,2013,55(10):1810-1822.
[3]Jin C,Jin S W.Software Reliability Prediction Model Based on Support Vector Regression with Improved Estimation of Distribution Algorithms[J].Applied Software Computing, 2014(15):113-120.
[4]Chen Y,Shen X H,Wang A B,et al.Application of Probabilistic Relational Model to Aerospace Software Defect Prediction[J].Optics and Precision Engineering,2013,21(7):1865-1872.
[5]Potter M A.The Design and Analysis of a Computational Model of cooperative Co-evolution[D].Washington:George Mason University,1997.
[6]Zhu F M,Guan S U.Cooperative Co-evolution of GA-based Classifiers Ba sed on In put Increments[J].Engine ering Applications of Artificial Intelligence,2008,21(8):1360-1369.
[7]Wu K J,Lu H W.PCEGA Used to Solve Text Feature Selection[J].Systems Engineering-Theory&Practice,2012,32(10):2215-2220.
[8]罗书强,赵鹏,张根保.车间生产调度中动态小生境协同进化算法[J].重庆大学学报,2011,12(34):96-101.
[9]Liu J,Zhong W C,Jiao L C.An Organizational Evolutionary Algorithm for Numerical Optimization[J].IEEE Trans.On System,Man,and CyberneticsPartB,2007,37(4):1052-1064.
[10]Cai X J.Organization Co-evolutionary Algorithms for Web Log Mining[D].Xi’an:Xidian University,2005.
[11]Peng Y L,Liu F.Organization Evolutionary Algorithm for Occlusion Recovery[J].Journal of Xidian University,2013,40(4):137-141.
[12]Blake C,Merz C.UCI Repository of Machine Learning Databases[DB/EL].http://www.ics.uci.edu/~mlearn/ML Repository.html,2014.
[13]Sayyad S J,Menzies T J.The Promise Repository of Software Engineering Database[EB/OL].Canada:University of Ottawa,http://promise.site.uottawa.ca/SERepository,2014.
[14]Menzies T,Greenw A L D J,Frank A.Data Mining Static Code Attributes to Learn Defect Predictors[J].IEEE Transactions on Software Engineering,2007,33(1):2-13.
Software Defect Prediction Based on Organizational Co-evolutionary Algorithm
CHANG Rui-hua
(Institute of Department of Scientific Research,Engineering University of Armed Police Force,Xi’an 710086,China)
Aiming at the problem of low software defect prediction accuracy for common labeled software metrics datasets,the software defect predictor based on organization co-evolutionary algorithm is presented.Firstly,an appropriate discretization method is chosen by compared with others.Then organizational co-evolutionary algorithm for classification is introduced and applied into the fields of aerospace software defect prediction.In this method,according to the prediction target,the discrete metrics datasets are divided into different species groups.Inside each species group,new evolutionary individual (organization)is formed.And organizations evolve through add and subtract operator, exchange operator,unite operator and a selection mechanism.Meantime,fitness function is calculated based on co-evolutionary importance of attribute.It improves software defect prediction accuracy of labeled software metrics.Finally,two case studies are used to validate the method,and the results show that this method is effective.
software defect,prediction,software metrics,co-evolutionary
TP311
A
1002-0640(2015)07-0126-05
2014-04-24
2014-06-25
国家自然科学基金(No.61309022);陕西省自然科学基金(No.2013JQ8031);武警工程大学基础研究基金资助项目(No.WJY201315)
常瑞花(1982- ),女,山西清徐人,博士,工程师。研究方向:信息处理和信息安全。
