改进粒子群算法在数据聚类中的应用
2015-06-12王金永董玉民
王金永, 董玉民
(1.青岛理工大学 计算机工程学院,山东 青岛 266033;2.青岛理工大学 网络中心,山东 青岛 266033)
1 粒子群算法和聚类分析的研究背景
1995年,Eberhart和Kennedy在长期观察鸟群、鱼群觅食行为规律的启发下,提出了粒子群算法(Particle Swarm Optimization,PSO),该算法是一种基于群智能(Swarm Intelligence)的优化算法[1]。鸟群在觅食行为遇到危险信号时,每一只鸟通过合作与竞争产生强大的力量来尽快地取得食物、避开危险。该算法可以根据当前的搜索情况,动态调整其搜索策略。由于算法收敛速度快,全局搜索能力强,需要设置参数少,近年来提出了许多改进算法来增强跳出局部极值的能力,受到学术界的广泛重视[2]。
由于粒子群算法的优良特性,在很多相关领域引起了对这一新生事物的迅速关注。首先是在1997年,由Eberhart R C[3]等提出了二进制粒子群算 法。随 后,Shi Y[4-5]和Eberhart R C[6]在1998年对速度项引入了惯性权重参数,提高了算法的收敛性,并在程序运行过程中不断动态地调整惯性权重来调节算法的收敛速度,该方程被称之为标准的PSO算法[7]。为了改善算法的收敛性,1999年,Clerc等引入了收缩因子,提出了带收缩因子的CF-PSO算法[8-9]。
聚类分析(cluster analysis)简称聚类(clustering),是将数据观测对象逐步划分成子集的过程,每个子集是一个簇(cluster),通过聚类,结果是每一个簇中的对象彼此相似,并且与其他簇中的对象不相似。由于簇是数据对象的集合,因此数据对象的簇可以看作隐含的类。在这种意义下,聚类有时又称为自动分类。聚类可以自动地发现大量数据的分组,这是聚类分析的突出优点。对聚类分析的算法研究也就成为研究的热点。为了很好地处理分类属性数据,文献[10]提出一种加权粗糙聚类算法,该算法聚类结果不受数据样本输入顺序的影响,根据粗糙集理论中的信息增益概念自适应地更新聚类过程,来获取全局最优的聚类权重和聚类划分。近几年对数据聚类的研究越来越多,出现了一些新型聚类算法,如张莉[11]等提出了基于样本预处理的核聚类算法,王顺久[12]等提出了基于样本的投影寻踪聚类算法,王娜[13]等提出了基于流行距离的迭代优化聚类算法等。
2 粒子群算法的原理与数学描述
粒子群算法的基本思想来源于自然界中的鸟群觅食行为,在算法中,每一个优化问题的解看作搜索空间中的一只鸟,即“粒子”。算法开始时,首先在可行解空间中随机初始化一群粒子,即随机生成初始种群,并且根据目标函数计算出每一个粒子的适应度值。每个粒子在空间中飞行的方向和距离由运动的速度决定,一般情况下,就像鸟儿追随离食物最近的鸟群一样,粒子也会追随离最优粒子距离最近的粒子群周围搜索。在每一次的迭代中,粒子将根据两个极值来不断更新迭代,一个是粒子自身经历过的最优位置,也就是自身最优解,另外一个是整个种群经历过的最优位置,也就是全局极值。
为了将粒子群算法实现,需先将算法用数学形式描述:假设由n个粒子组成的种群Z={Z1,Z2,…,Zn},其中问题的一个解用每一个粒子的位置Zi={zi1,zi2,…,ziD}来表示,D表示粒子的空间搜索维数。种群中的每一个粒子通过不断调整自己的位置Zi来搜索更新解。在搜索过程中,每一个粒子都能记住自己经历过的最好位置,即搜索到的自身最好解,记做pid,以及整个粒子群经历过的最好的位置,即目前搜索到的群体最优解,记做pgd。除了用位置表示粒子信息外,用速度来表示粒子的运动方向,记做Vi={vi1,vi2,…,viD},当pid和pgd都找到后,粒子的速度更新情况见式(1),位置更新情况见式(2)[14]。
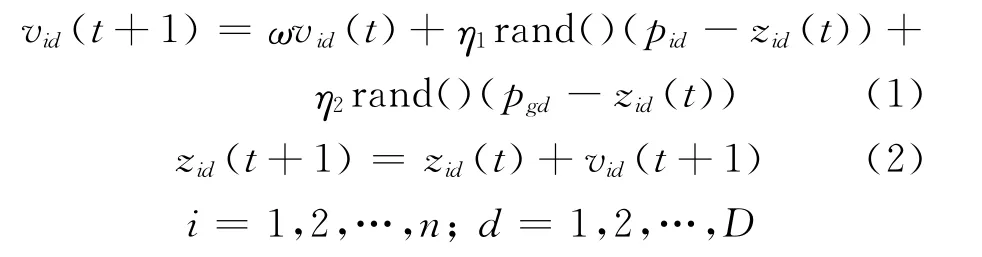
式中:vid(t+1)——第i个粒子在第t+1次迭代中第d维上的速度;
ω——粒子运动的惯性权重;
η1,η2——加速常数;
rand()——0~1之间的随机数。
搜索运动过程中,为了防止粒子的运动速度过大,即算法收敛速度过快,可以设速度上限vmax,当vid(t+1)≥vmax时,vid(t+1)=vmax;当vid(t+1)≤-vmax时,vid(t+1)=-vmax。
从粒子速度更新式(1)和位置更新式(2)可以看出,粒子的运动方向由3部分影响因素决定:自己原有的速度vid(t)、粒子当前位置与自身最佳位置的距离pid-zid(t)、粒子当前位置与群体最佳位置的距离pgd-zid(t),并分别设置每一部分的权重来表示相对重要性,分别由权重系数ω,η1,η2表示,当找到足够好的最优解或达到最大迭代次数时,算法结束。影响粒子运动方向的3部分影响因素的加权求和示意图如图1所示。
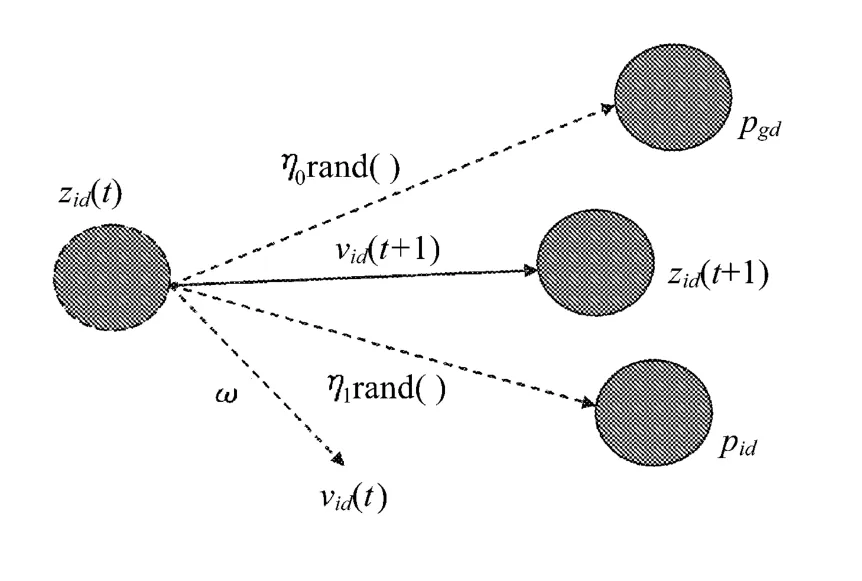
图1 3种移动方向的加权求和示意图
3 粒子群算法的流程描述
经过了解粒子群算法的概念、基本原理和数学描述,下面介绍粒子群算法的基本流程,如图2所示。

图2 算法流程图
从粒子群算法流程图可以看出,粒子群算法参数相对较少,数学原理简单,迭代循环简单易懂,算法易于实现。为了描述算法流程,需要先定义几个参数和函数,先假定粒子群种群规模为n。
设Zi={zi1,zi2,…,ziD}表示第i个粒子的位置;
fitness(Zi)表示求第i个粒子的解,也就是适应度函数;
Vi={vi1,vi2,…,viD}表示第i个粒子的速度向量;
pid表示自身搜索到的最优解,即第i个粒子经历到的最优位置;
pgd表示全局搜索到的最优解,即种群中适应度最高的最优位置。
下面对算法流程图2做详细说明:
第1步:初始化粒子群。
1):随机初始化种群,随机初始化粒子位置Zi={zi1,zi2,…,ziD};
2)随机初始化粒子速度Vi={vi1,vi2,…,viD};
3)计算适应度函数fitness(Zi),并令pid=zid,i=1,2,…,n;d=1,2,…,D;
4)初始化全局最优解pgd,选择种群中的适应度函数值最高的粒子的位置向量初始化pgd,i=1,2,…,n。
第2步:按照下面步骤算法循环迭代,直到满足算法结束的条件为止。
1)选择恰当的速度惯性因子ω;
2)计算群体中所有粒子的适应度函数值fitness(Zi),当出现个体适应度函数值大于当前个体最优适应度函数值时,即fitness(zid)>fitness(pid),令pid=zid;
3)当种群中个体最优值pid大于当前群体最优值 时,则 更 新pgd的 值,即fitness(pid)>fitness(pgd),令pgd=pid;
4)依据式(1)和式(2)不断更新每一个粒子的速度和位置,即更新vid和zid的值。
4 粒子群算法的参数分析
在基本粒子群算法的数学描述中(见式(1)和式(2)),主要有3个影响决定粒子速度和位置的参数,分别是速度惯性权重ω、速度调节参数η1,η2,参数的选择对粒子群算法的性能和效率有很大的影响,ω表示粒子从当前时刻到下一时刻保持的运动惯性,η1,η2表示粒子向自身当前最优位置pid和群体当前最优位置pgd运动的加速权重。下面分析3个系数表示的意义:如果惯性权重ω=0,那么说明粒子的运动速度没有惯性,不受当前运动速度的影响,粒子群将收敛到当前的全局最优位置,不会再去搜索更优解。如果参数η1=0,那么说明不会追随自身最优位置,粒子失去“自我认知”能力,只具有“社会认知”能力,此时粒子群收敛速度很快,同时容易陷入局部极值。如果参数η2=0,那么说明粒子失去“社会认知”能力,只具有“自我认知”能力,这时候相当于多个粒子各自独立搜索,很难搜索收敛到全局最优解。通过分析得知,3个参数都会影响算法的搜索效率,针对不同的问题,选择适合的参数才能取得更好的收敛速度和稳定性,根据大量实践经验,令ω取0~1之间的随机数,η1,η2分别取2,可以取得较好的效果。
5 粒子群算法在数据聚类中的应用
设N个样品构成的样品集X={Xi,i=1,2,…,N},其中Xi为n维特征向量,用表示第j个聚类的中心,用表示样品Xi到对应的聚类中心的欧氏距离,聚类问题就是要找到一个划分ω={ω1,ω2,…,ωM},使得总的类内离散度和J达到最小[15]:

聚类准则函数J即为各类样品到对应聚类中心的距离的总和。
当聚类中心确定时,可以由最近邻法则决定聚类的划分。即对样品Xi,若第j类的聚类中心满足,就是样品Xi与聚类中心之间的距离是所有样品与聚类中心距离的最小值,见式(4),则样品Xi属于聚类ωj。


在用粒子群优化算法求解聚类问题时,每一个粒子就是问题的一个可行解,所有的粒子组成粒子群(也就是解集)。根据对聚类结果理解的不同,对解集的描述可以有两种形式:第1种是类ω1,ω2,…ωM为解集,也就是聚类结果;第2种是以中心集合(j=1,2,…,M)为解集,即聚类结果。论文中采用第2种形式,用基于聚类中心集合作为聚类问题的对应解,也就是说解集是由M个聚类中心组成的,M是已知的聚类数目。
根据粒子群算法的数学描述式(1)和式(2),可以得到粒子i的速度和位置更新公式:

根据已经定义好的粒子群结构,采用粒子群聚类算法便可以求得聚类问题的最优解。通过刚才介绍粒子群聚类算法的原理、算法描述和算法实现步骤,通过编写程序,并且在MATLABR2013a编程环境写运行,可以观察分析粒子群算法的具体应用。首先给出粒子群聚类算法的核心代码,第一大模块是根据式(5)和式(6)更新粒子的位置和速度代码[16]:
第二大模块是利用距离的平方和的平方根来度量粒子之间的距离,具体代码如下:
第三大模块是求粒子的适应度,根据粒子群聚类算法的粒子适应度更新条件,适应度取欧式聚类的倒数,程序代码如下:


下面对某地区的煤层地质条件数据,应用粒子群优化算法进行聚类分析,根据不同煤层块段的特征:平均厚度、煤层倾角、离差系数、煤层合格标准、含矸系数等进行分类,聚类后的数据可以用于指导煤矿的开采,提高煤矿开采的安全性和效率。
各煤层块段的特性指标值见表1。

表1 各煤层块段的特性指标值
程序中设定样本数据的聚类数目为K=3,维数D=5,通过运行程序,pso聚类的全局最优位置、函数适应度如下,并且绘制了函数适应度曲线。
实验目的:对上述实验数据应用粒子群聚类算法,在MATLABR2013a编程环境下运行聚类算法程序,观察聚类效果。
实验的适应度函数是:result=dis;%适应度函数。
粒子群聚类算法中“函数适应度-迭代次数”曲线如图3所示。


图3 粒子群聚类算法中“函数适应度-迭代次数”曲线
1)当迭代次数MaxDT=100时,迭代次数-适应度值曲线见图3(a)。
最后结果是:ans=3.240801487577032e-04。
2)当迭代次数MaxDT=200时,迭代次数-适应度值曲线见图3(b)。
最后结果是:ans=1.617915530278782e-04。
3)当迭代次数MaxDT=500时,迭代次数-适应度值曲线见图3(c)。
最后结果是:ans=6.465458242701003e-05。
实验结果分析:由于“w=1-t/MaxDT”,即惯性因子与迭代次数有关,进而影响粒子速度更新公式“v(i,:)=w*v(i,:)+c1*rand*(y(i,:)-x(i,:))+c2*rand*(pg-x(i,:));”,也就影响了粒子的位置“pos(i,:)=x(i,:)+v(i,:)”,最终也会影响粒子之间的欧氏距离,也就是实验的适应度函数是:“result=dis;%适应度函数”,所以图3中的3幅图像的初始适应度有差别,但是随着迭代次数的增加,都在不断的减小。从3次(迭代次数分别是100、200、500)程序运行情况可以得出:适应度ans即result代表样品和聚类中心的欧氏距离,随着迭代次数越大,函数的适应度ans越小,最终趋于零。说明样品与聚类中心的距离不断减小,当迭代次数大约为500时,适应度测量函数欧式距离趋于零,数据的聚类效果越好。
6 K-均值聚类算法思想
粒子群优化算法的缺点是易陷入局部极值点;全局搜索能力强,但是搜索精度不高;PSO算法同时记忆位置和速度信息,高效的信息共享机制可能导致粒子寻优时都移向某个全局最优点。粒子群算法的优点是收敛速度较快;全局搜索能力强,能够有效避免早熟;粒子群中多个粒子同时搜索,具有并行性;需要设置的参数较少,因此算法简单,易于实现。
K-均值算法思想简单易行,是一种传统的聚类分析方法,但是当数据中存在离群点时,K-均值聚类效果会更不理想,K-均值的聚类结果受初始聚类中心的选择影响较大,如果初始聚类中心选择不当,算法可能收敛于一般结果。认识到粒子群算法和K-均值聚类算法各自的优缺点之后,可以设想将两种算法都进行改进结合,充分利用各自的优点,避开两种算法的缺点,融合并利用全局搜索能力较强的粒子群优化算法和局部寻优能力较强的K-均值聚类算法,提出了一种基于K-均值的粒子群优化聚类算法,该算法充分优化了K-均值聚类算法,提高了局部搜索和全局搜索的能力,加快了算法的收敛速度[17]。
K-均值聚类基本思想是:首先初始化数据,随机选择K个聚类中心,然后按照欧氏距离紧邻原则,根据每一个样品与初始聚类中心的相似程度重新划分聚类;计算该类所有元素的平均值,重新确定新的聚类中心;逐步依次迭代,直到聚类中心不再变化。假设模式样本集为X={Xi,i=1,2,…,n},其中Xi为D维模式向量,聚类问题就是要找到一个划分ω={ω1,ω2,…,ωm},满足下式

并且使得总的类间离散度和式(8)达到最小:


J——各类样本到对应聚类中心的欧氏距离的总和。
7 基于K-均值的粒子群聚类算法流程及其应用
算法首先需要根据近邻法则,确定粒子的位置编码和各类的聚类中心;然后根据聚类划分,按照式(8)计算类内离散度和J;最后计算粒子的适应度函数之和fitness,当适应度越大,说明聚类效果越好。所以基于K-均值的粒子群聚类算法描述如下:
1)初始化种群。在初始化粒子群时,现将每一个样品随机对应于某一类,并作为初始划分,计算初始粒子的位置编码,即计算各类的聚类中心;初始化粒子的速度;计算粒子的适应度;反复进行N次,生成N个初始化的粒子群。
2)将粒子现在的适应度值和经历过的最好位置pid的适应度值进行比较,及时更新pid的信息。
3)将粒子现在的适应度值和种群经历过的最好位置pgd的适应度值进行比较,及时更新pgd的信息。
4)根据式(1)和式(2)不断调整粒子的速度和位置。
5)对新个体进行K-均值聚类优化,按照下面两步进行K-均值优化:
①根据最近邻法则,按照粒子的聚类中心编码,确定对应粒子的聚类划分;
②更新粒子的适应度值,计算新的聚类中心,更新原来的粒子编码。由于K-均值聚类具有较强的局部搜素能力,此时引入K-均值优化后的粒子群聚类算法可以得到很好的改善,提高了算法的收敛速度和搜索效率。
6)不断迭代,如果达到最大迭代次数或者聚类中心不再发生变化,则算法结束,否则转到步骤2)继续迭代。
基于K-均值粒子群优化算法的核心代码如下[16]:
%更新粒子的速度和位置

对表1中的数据,输出的适应度-迭代次数可以形象的表示随着迭代次数的增加,聚类效果的变化过程如图4所示。


图4 基于K-均值粒子群优化算法运行图
实验结果:
1)当迭代次数为50次时(见图4(a)),实验结果如下:
fpclu=3 2 1 3 3 1 1 1 1 3 1 3 1 3 1 3 1 3 1 1
说明在s20×5数据中,第1、4、5、10、12、14、16、18行数据归为一类;第2行数据归为一类;第3、6、7、8、9、11、13、15、17、19、20行数据归为一类。输出的适应度值为:
kfitness=2.158006918671278e-04。
2)当迭代次数为200次时(见图4(b)),实验结果如下:
fpclu=2 2 3 2 2 3 3 3 3 2 3 2 3 2 3 2 1 2 1 3
说明在s20×5数据中,第1、2、4、5、10、12、14、16、18行数据归为一类;第3、6、7、8、9、11、13、15、20行数据归为一类;第17、19行数据归为一类。输出的适应度值为:
kfitness=1.412634231439157e-04。
3)迭代次数为300次时(见图4(c)),结果如下:
kpclu=1 1 2 1 1 2 3 3 3 1 2 3 2 1 2 1 2 1 2 3
说明在s20×5数据中,第1、2、4、5、10、14、16、18行数据归为一类;第3、6、11、13、15、17、19行数据归为一类;第7、8、9、12、20行数据归为一类。输出的适应度值为:
kfitness=5.077943793714523e-05。
从图4可以看出,输出的适应度-迭代次数的增加,聚类结果不断得到优化,但是相对于粒子群聚类,改进后的聚类算法能够在较少的迭代次数内完成聚类,说明基于K-均值的粒子群聚类算法更加优秀。在前面介绍的粒子群聚类算法中(见图3),需要经过大约500次的迭代,聚类结果相对稳定,才满足程序结束条件;而在基于K-均值的粒子群聚类算法中,在较少的迭代次数内(大约300次)就达到聚类结果的稳定,程序结束,较好地完成了数据聚类。
8 结 语
阐述了粒子群算法的原理,以及在数据聚类中的应用。通过分析和论述,可以看到虽然粒子群算法出现的相对较晚,在短短的20年发展历程中,展现出强大的生命力和研究潜力,但是算法自身存在一些缺点,比如容易陷入局部极值、对离散的问题处理不佳等原因,后期出现了很多对基本粒子群算法的改进。粒子群算法是一种仿生算法,自身具备的一些优秀的进化特点使其成为智能优化领域的一个研究热点。但是由于粒子群算法的数学基础相对薄弱,对这个新兴的智能优化算法的研究需要长期的不断完善的过程。
[1] 赵志刚,常成.简化的自适应粒子群优化算法[J].广西大学学报:自然科学版,2010,5(5):793-798.
[2] 段晓东,王存睿,刘向东.粒子群算法及其应用[M].沈阳:辽宁大学出版社,2007.
[3] Eberhart R C,Kennedy J.A discrete binary version of particle swarm algorithm[C]//Proceedings of the IEEE International Conference on System,Man,and Cybernetics,1997:4104-4108.
[4] Shi Y,Eberhart R C.A modified particle swarm optimizaerf[C]//Proceedings of the IEEE International Conference on Evolutionary Computation,1998:69-73.
[5] Shi Y,Eberhart R C.Fuzzy adaptive particle swarm optimization[C]//Proceedings of the Congress on Evolutionary Computation,2001:101-106.
[6] Eberhart R C,Kennedy J.Swarm intelligence[M].[S.l.]:Morgan Kaufmanns,2001.
[7] Shi Y,Eberhart R C.Parameter Selection in Particle Swarm Optirnization[C]//Proceedings of Annual Conference on Evolutionary Programming,1998:591-600.
[8] Clerc M,Kennedy J.The particle swarm optimization:Explosion,stability,and convergence in multi-dimensional complex space[J].IEEE Transaction on Evolutionary Computation,2002,6(1):58-73.
[9] Shi Y,Eberhart R C.A modified particle swarm optimization[C]//Proceedings of IEEE International Conference on Evolutionary Computation,1998:69-73.
[10] Jian Fu,Jian Yin.Weighted Rough Clustering on Categorical Data[C]//International Conference on Computer Science and Service System(CSSS),Nanjing,2011:939-944.
[11] 张莉,周伟达,焦李成.核聚类算法[J].计算机学报,2002,25(6):587-590.
[12] 王顺久,倪长健.投影寻踪动态聚类模型及其应用[J].哈尔滨工业大学学报,2009,41(1):178-181.
[13] 王娜,杜海峰,王孙安.一种基于流形距离的迭代优化聚类算法[J].西安交通大学学报,2009,43(5):76-79.
[14] 黄太安,生佳根,徐红洋,等.一种改进的简化粒子群算法[J].计算机仿真,2013,2(2):327-330.
[15] 杨淑莹.模式识别与智能计算[M].北京:电子工业出版社,2008:337-346.
[16] 程序员联合开发网(programmers united develop net)[EB/OL].[2015-08-15].http://www.pudn.com.
[17] 陈小全,张继红.基于改进粒子群算法的聚类算法[C]//.2011年第17届全国信息存储技术大会(IST),2011.
