中小企业税务稽查投影寻踪建模与实证分析
2015-06-06楼文高楼际通宋雷娟王浪庆
楼文高,楼际通,宋雷娟,王浪庆
(1. 上海商学院 财经学院,上海 200235;2. 北卡罗来纳大学教堂山分校, NC 27514 )
中小企业税务稽查投影寻踪建模与实证分析
楼文高1,楼际通2,宋雷娟1,王浪庆1
(1. 上海商学院 财经学院,上海 200235;2. 北卡罗来纳大学教堂山分校, NC 27514 )
从上海市某区386家中小企业申报的15项税收指标数据中筛选出对判定企业纳税情况具有重要影响的10个评价指标,并将全部386个样本分成性质相似的建模样本和测试样本(其中测试样本个数占45%),建立了基于投影寻踪分类(PPC)技术的税务稽查评价模型.与多元线性回归(MLR)、判别分析(MDA)、Logistic和支持向量机(SVM)模型相比,PPC模型的识别错误率最低,建模样本和测试样本的平均分类错误率低于6%,改进型PPC模型包含的评价指标少,两类错误率很接近,非常适用于实际企业的税务稽查评估研究和实践.对339家待判断企业纳税情况的判定结果研究表明,建立的改进型PPC模型具有很好的泛化能力和鲁棒性.
税务稽查;投影寻踪分类技术;分类错误率;样本分组
1 引 言
中小企业在国家创新经济发展模式和解决就业问题中占有越来越重要的位置,量大面广,给基层税务稽查和纳税评估工作带来了很大的风险.因此,建立实用性强和可靠的税务稽查评价模型,既能帮助企业提高涉税风险的防控能力,又能帮助税务部门足额征收税款,日益受到政府有关部门(税务局等)和学界的重视[1,2].楼文高等[3]对Tobit模型、层次分析法(AHP)、主成分法(PCA)、判别分析(MDA)、Logistic模型和多元线性回归(MLR)等传统统计模型以及新兴的多层感知器神经网络(BPNN)、概率神经网络(PNN)、支持向量机(SVM)、自组织神经网络(SOM)等数据挖掘技术与传统统计模型的组合模型[1-2, 4-8]的优缺点、适用情况以及现有文献存在的问题等进行了详细的评述,并应用广义回归神经网络(GRNN)和多重交叉检验法,建立了适用于小样本情况的税务稽查GRNN模型,分类错误率10%左右,明显低于传统统计模型和SVM模型,取得了较好的效果.但是,由于GRNN建模过程中确定合理的光滑因子值是相当繁琐的,而且GRNN模型是隐性模型[3, 9-10],无法显性地直接揭示出企业纳税情况与各个评价指标之间的非线性关系,给后续的税务稽查工作(判定、研究企业纳税情况)以及企业如何制定合理的纳税策略、降低涉税风险带来不便.
另一方面,投影寻踪分类(Projection Pursuit Clustering,简称PPC)技术是一种适用于高维、非线性、非正态分布数据处理的新兴统计建模方法[11-14],不仅数学意义清晰,而且是显性模型,便于对样本和评价指标的重要性进行排序和分类研究.本文首次将PPC技术引入到企业税务稽查研究中,212个建模样本和174个测试样本(占45%)的平均分类错误率低于6.00%,低于MLR、MDA、Logistic等传统统计模型和SVM模型,建立了更加简洁、实用、可靠和有效的税务稽查模型,应优先用于中小企业的税务稽查研究和实践中.
2 建立中小企业税务稽查评价指标体系
本课题组选取上海某区税务局管辖的木制家具制造中小企业增值税纳税情况进行研究,共有2 000多家企业,考虑到数据的真实可靠性,选取一般纳税人作为研究对象.在2010~2012年度有较完整财务数据和增值税纳税申报数据的正常经营企业有725家(次),成立时间短则1年多,长则16年多.笔者查阅了40多篇有关税务稽查(纳税评估等)的文献和文件,先后被采用过的评价指标有180多个.在比较研究的基础上,笔者根据现有企业财务数据和增值税纳税申报表可获得数据两个方面,建立了由如下15个指标组成的企业增值税税务稽查评价指标体系:全部收入税负率(x1)、成本费用税负率(x2)、销售毛利率(x3)、成本费用利润率(x4)、销售利润率(x5)、总资产收益率(x6)、销售费用率(x7)、管理费用率(x8)、财务费用率(x9)、流动资产周转率(x10)、总资产周转率(x11)、流动比率(x12)、速动比率(x13)、现金比率(x14)和资产负债率(x15).经区税务局多位经验丰富的同志和课题组税务学方面专家共同研究和认真、仔细的甄别,在上述725家企业中,判定211家企业进行了诚实纳税,175家企业没有诚实纳税,对其他339家企业的纳税情况进行初步判定,希望借助本课题组建立的模型进行辅助稽查判断.
3 投影寻踪分类(PPC)建模原理
Friedman等[11]于1974年提出了一种适用于非线性、高维和非正态分布数据处理的新兴统计建模方法——投影寻踪分类(PPC)模型,即把高维数据投影到低维(1~3维)子空间上,通过分析低维子空间上的数据规律以达到揭示高维数据特征的目的.由于在常用的一维PPC模型建模过程中须确定合理的窗口半径R值,而如何确定合理、有效的R值,迄今还缺乏理论依据和指导[11-14],并且不同的R值,往往得到不同的建模结果.因此,为避免出现PPC模型结果的不确定性和非唯一性,消除R值对建模结果的不利影响,本文采用另一种投影寻踪目标函数型式.
根据税务专家的先验知识和经验,已经事先判定了部分企业的纳税情况y(i)(即诚实纳税或非诚实纳税).因此,根据要使所有样本点尽可能形成若干个团(类)(诚实纳税类或非诚实纳税类),类与类之间尽可能分散和类内样本点尽可能密集的要求,可以构建如下投影寻踪目标函数[12]:
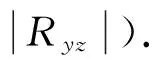
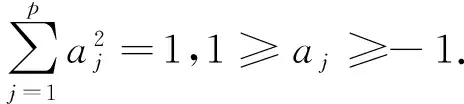
(1)
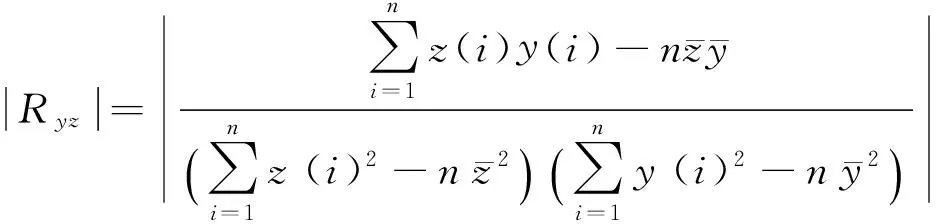
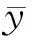
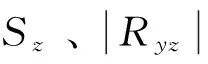
4 建立中小企业税务稽查PPC模型
4.1 输入数据归一化预处理和模型输出期望值的设定
为了消除各指标量纲不同对建模结果的不利影响,应对各评价指标的输入数据进行线性归一化预处理,转化为 [0, 1]区间内的值.考虑到分类要求的对称性,笔者设定诚实纳税和非诚实纳税样本的模型理论期望输出值分别为-0.5和0.5.
4.2 筛选出对税务稽查具有重要影响的评价指标
大量研究表明,如果模型中包含不重要的(或者称为不相关的)指标,不仅不能提高模型的精度(性能),反而会降低模型的精度,并无畏增加建模和收集样本数据的成本,可以说是有害无益的[1, 3,4,6 , 15,16].本文采用简单、实用和有效的灵敏度分析法来筛选重要评价指标[6, 15,16],借助于Statsoft公司出品的商品化软件STATISTICA Neural Network (以下简称SNN)软件GRNN模型的灵敏度分析功能[6, 9],删除了x13、x8、x9、x12和x14共五个指标,即从15个指标中筛选出了对税务稽查具有重要影响的10个评价指标.
4.3 把样本数据进行合理分组提高模型的泛化能力和鲁棒性
建立的模型是否可靠和有效,必须用非建模样本(或称测试样本)的性能(精度和有效性)来衡量,因此,必须把样本数据分成建模样本和测试样本.如果样本数量足够多,无论采用什么方法,随机抽取就能确保各组样本具有相似(同)的性质(即均值和方差基本相等),但如果样本数量不是很多,随机分组就可能出现偏差,这样建立的模型很可能就是无效和不可靠的.因此,国外文献早在1960年代就开始研究如何分组才能确保各组样本具有相似的性质,其中SOM方法分组效果较好,也便于实现[6,15,16].为此,本课题组选用SNN的SOM方法进行样本分组.一般地,模型的内插性能总是好于外插性能,即要求建模样本必须包含每个指标的最大值和最小值(包括诚实纳税和非诚实纳税两种情况).对于本例,包含10个诚实纳税样本和10个非诚实纳税样本.据此,将上述386个样本分成了具有相似性质的建模样本和测试样本(174个,约占45%),数据特征值如表1所示.
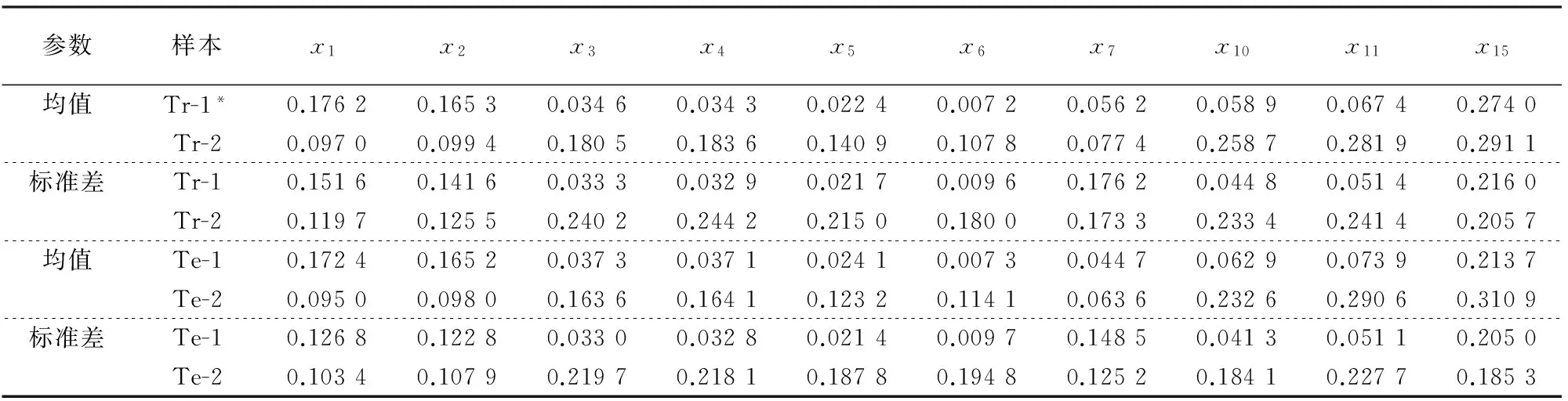
表1 用SOM方法进行分组的两类样本的均值和标准差
*注:“1”和“2”分别表示诚实纳税和非诚实纳税样本,Tr和Te分别指建模样本和测试样本;诚实纳税样本211个,其中Tr和Te分别为117和94个,非诚实纳税样本175个,其中Tr和Te分别为95和80个.
4.4 建立中小企业税务稽查PPC模型
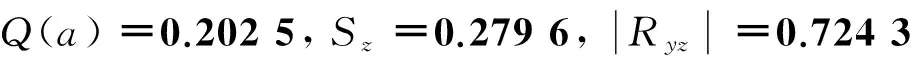
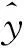
(2)
再次调用笔者编制的最优化程序,求得全局最优解,目标函数值Q(b)=16.378 6,b1=1.233 1,b2=-6.229 3.
5 结果与分析
5.1 PPC建模结果及其样本属性的判定(诚实纳税或非诚实纳税)
PPC模型每个样本的输出值是一个实数,因此,必须采用某种规则来判定每个样本究竟属于诚实纳税还是非诚实纳税.对于结果基本服从(右半支)正态分布N(μ1,σ1)(诚实纳税样本),和(左半支)正态分布N(μ2,σ2)(非诚实纳税样本)的两类样本来说,区分他们的分界值μF可用下式确定[12]:
(3)
因此,如果模型输出值小于分界值μF,就可判定该样本为诚实纳税,离分界值越远,诚实纳税的概率就越大,反之为非诚实纳税.根据上述判断准则,可以判定本例212个建模样本和174个测试样本属性,其I类、II类和平均分类错误率如表2所示.
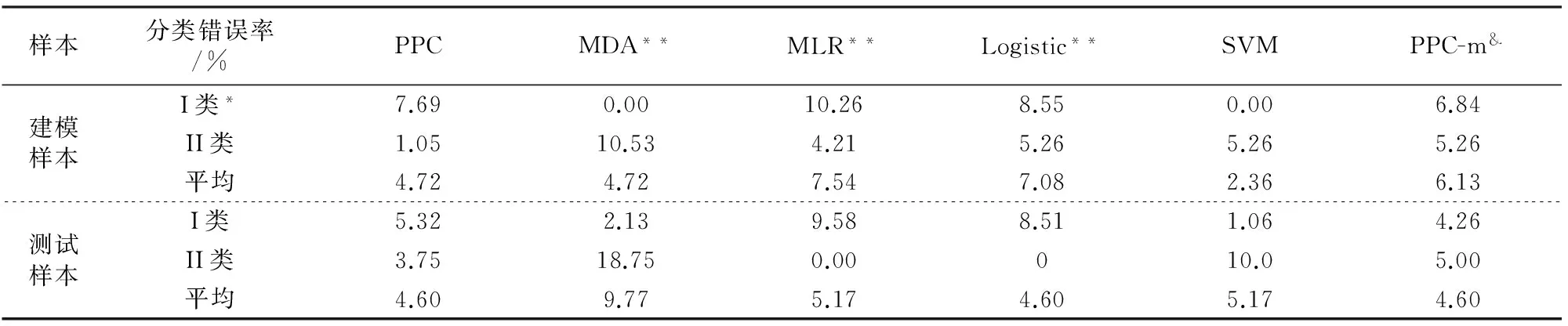
表2 不同建模方法得到的两类样本的分类错误率
注:*I类错误率是指把诚实纳税的样本判定为非诚实纳税的百分率,反之是II类错误率;**采用MDA、MLR和Logistic建模时,删除了共线性变量x1、x3、x7、x10和x15;&为改进型PPC模型的结果.
从PPC模型建模样本和测试样本的I类和II类错误率可以看出,本例的样本分组是合理和有效的.如果分组不合理,就会导致建模样本和测试样本的分类错误率相差很大,从而导致模型没有泛化能力和实用价值.
5.2 与MLR、MDA、Logistic和SVM等模型计算结果的对比
针对上述两类样本数据,笔者也建立了MDA、MLR、Logistic和SVM模型,其I类、II类和平均分类错误率也列于表2中.
由表2可知, PPC模型的分类错误率最低,MDA、MLR和SVM模型的分类错误率都出现了大于10%的情况,尤其是MDA和SVM模型的II类错误率较高,危害更大.PPC模型的分类错误率与Logistic模型基本相当.但从原理上讲,MDA、MLR、Logistic和SVM模型只有对服从正态分布规律数据的建模结果才具有较好的可靠性,否则可靠性难以保证.显然,本例的各个评价指标数据都不服从正态分布,因此,这些传统统计模型是否能用于企业实际纳税情况的判定,还有待进一步研究分析.
犯II类错误的危害性(即把非诚实纳税企业判定为诚实纳税,将导致税收流失)远远大于犯I类错误.因此,II类错误率低于I类错误率的模型较为合理.
5.3 其他339家木制家具制造企业纳税情况的判定
根据前述,另有339家企业的纳税情况还有待判定.339家企业各个指标的均值和方差如表3所示,作为对比,上述212个建模样本及其诚实纳税样本与非诚实纳税样本的均值和方差也列于表3中.显然,这339家企业的均值与建模样本中诚实纳税样本和非诚实纳税样本的均值都相差较大,说明这339家企业中肯定既有诚实纳税的,也有非诚实纳税的.为此,把上述339家企业10个评价指标的归一化数据导入上述建立的PPC模型,得到了PPC模型的输出值,其中190家企业的输出值小于分界值μF(-0.096 2),这些企业被判定为诚实纳税,另外149家企业被判定为非诚实纳税.为了进一步验证PPC模型的有效性、泛化能力和鲁棒性,表3也列出了339家企业中被判定为诚实纳税和非诚实纳税企业的各个指标的均值和标准差.从表3可以看出,对于指标x1、x2、x7和x15来讲,339家企业与212个建模样本的性质是矛盾的(如339家企业中,诚实纳税样本x1的均值显著大于非诚实纳税样本,而212个建模样本的情况,则正好相反).
5.4 建立税务稽查改进型PPC模型
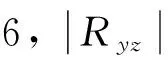
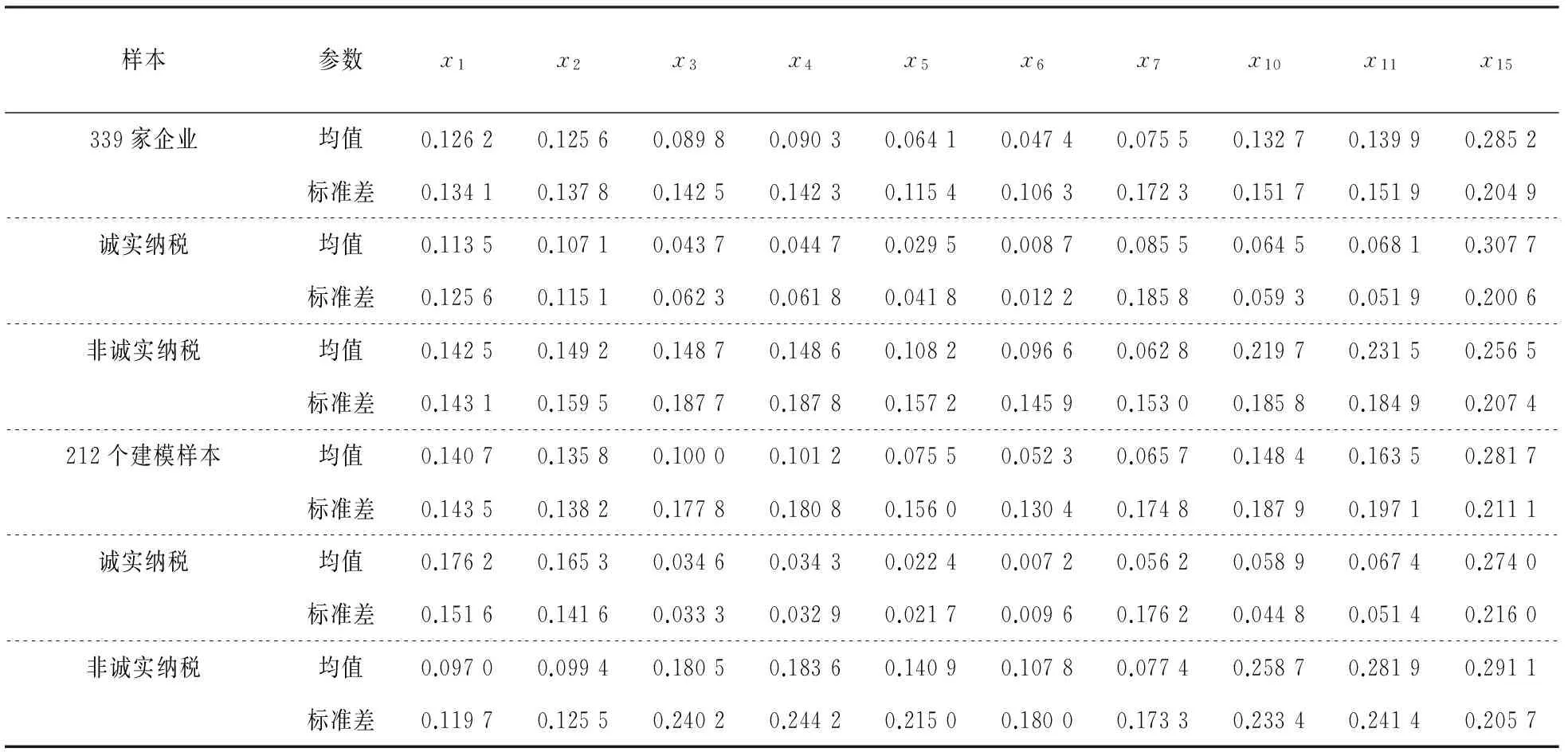
表3 建模样本和339家企业及其被PPC模型判定为诚实纳税、非诚实纳税样本各个评价指标的均值和标准差
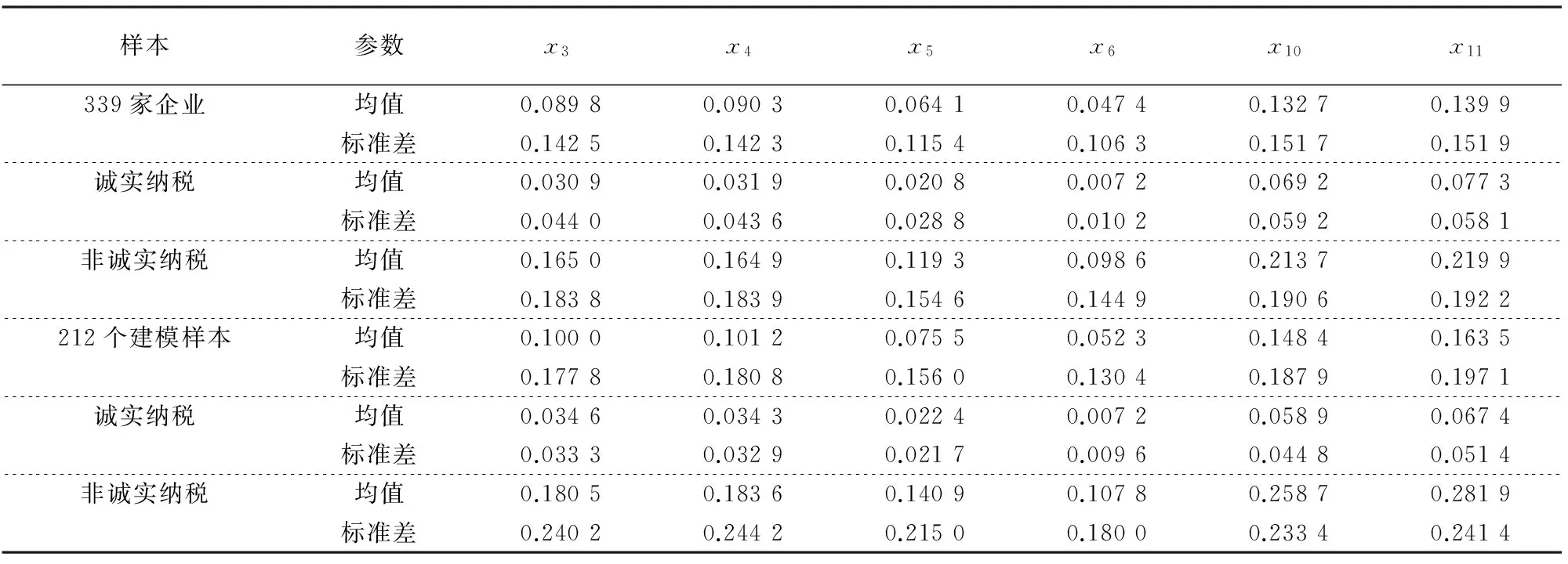
表4 建模样本和339家企业及其被改进型PPC模型判定为诚实纳税、非诚实纳税样本指标的均值和标准差
5.5 各个评价指标的重要性排序和分类
从公式(1)和(2)可知,权重越大的指标对纳税情况的影响就越显著,在这六个指标中,x11最重要,其次是x10,然后依次是x4、x3、x5,x6最不重要,这些指标的数值越大,改进型PPC模型的输出值越大,即企业存在非诚实纳税的可能性也越高.因此,在判断研究企业纳税情况时,首先要重点考察其总资产周转率数据是否过高,其次是考察流动资产周转率数据是否过高,然后是依次考察成本费用利润率、销售成本率、销售利润率及其总资产收益率等指标数据是否过高.根据各个指标的权重大小,也可以对他们的重要性进行分类,由于x11和x10的权重大于0.50,其属性可以归为“最重要”一类,x4、x3和x5的权重在[0.3, 0.4]范围内,其属性可以归为“重要”一类,x6的权重小于0.30,其属性可以归为“次重要”一类.
6 结束语
针对上海市某区386家木制家具制造企业纳税申报的15项指标数据,首先采用灵敏度分析方法筛选出对企业纳税情况具有重要影响的10个指标,再采用SOM方法把样本分成具有相似性质的建模样本和测试样本(174个,约占45%),以确保后续建模的鲁棒性和泛化能力.
采用可用于非线性、高维、非正态分布数据处理的投影寻踪分类(PPC)技术,针对212个建模样本,建立了求得真正全局最优解的PPC模型,建模样本和测试样本的平均分类错误率仅为4.72%和4.60%,均低于MLR、MDA、SVM等模型.同时发现,对339家实际企业纳税情况的判定表明,有4个指标的性质是相互矛盾的,为此建立了删除该四个指标后仅包含六个指标的改进型PPC模型,建模样本和测试样本的平均分类错误率分别为6.13%和4.60%,而且与339家实际企业诚实纳税和非诚实纳税样本的评价指标性质完全一致,说明建立的改进型PPC模型具有很高的精度、泛化能力和鲁棒性,而且模型包含的评价指标更少,实用性更强,可用于实际企业纳税情况的判定.
采用MLR、MDA和SVM方法建模,不仅模型的平均识别错误率高于PPC模型,而且两类错误率差异也较大,说明模型存在一定的偏态性,再者,从原理上讲,在数据不服从正态分布规律时,无法保证这些模型的可靠性和鲁棒性.
PPC模型采用一维连续实数输出方式,便于研究两类不同样本输出值的分布规律,从而为分析、判定真实样本属性提供便利,可同时完成样本的分类和排序研究.改进型PPC模型建模过程简捷,意义清晰,无须人为确定某些参数的合理值,可最大程度规避人为因素的影响.
[1]RSWU,CSOU,HYLIN,etal. Using data mining technique to enhance tax evasion detection performance [J]. Expert Systems with Applications, 2012, 39(10): 8769-8777.
[2] 何辉, 侯伟. 我国纳税评估存在的问题与路径选择[J]. 税务研究, 2013,29(2):75-77.
[3] 楼文高, 娄元英, 尹淑平. 基于广义回归神经网络的税务稽查选案实证研究[J]. 广东商学院学报, 2013, 28(6):74-80.
[4] J ALM. Measuring, explaining, and controlling tax evasion: lessons from theory, experiments, and field studies [J]. International Tax Public Finance, 2012, 19(1):54-77.
[5] 叶艺勇. 基于支持向量机和领域知识的纳税评估预警模型[J]. 数学的实践与认识, 2014, 44(1):72-77.
[6] P C GONZALEZ, G D VELASQUEZ. Characterization and detection of taxpayers with false invoices using data mining techniques [J]. Expert Systems with Applications, 2013, 40(5):1427-1436.
[7] C LIN, I LIN, C WU,etal. The application of decision tree and artificial neural network to income tax audit: the examples of profit-seeking enterprise income tax and individual income tax in Taiwan [J]. Journal of the Chinese Institute of Engineers, 2012, 35(4):401-411.
[8] 夏辉, 李仁发. 基于SVM与SOM的税务稽查选案模型研究[J]. 科学技术与工程, 2009, 9(11):4027-4031.
[9] STATSOFT Inc. Electronic Statistics Textbook [EB/OL].Tulsa ( http://www.statsoft.com/textbook ) , 2011.
[10]D F SPECHT. A generalized regression neural network [J]. IEEE Transactions on Neural Networks, 1991, 2(6):568-576.
[11]J H FRIEDMAN, J W TUKEY. A projection pursuit algorithm for exploratory data analysis [J]. IEEE Transactions on Computers, 1974, 23(9):881-890.
[12]楼际通, 楼文高, 于秀荣. 商业银行个人信用风险评价的投影寻踪建模及其实证研究[J]. 经济数学, 2013, 30(4):27-33.
[13]H CAUSSINUSS, A RUIZ-GAZEN,G GOVAERT. Exploratory projection Pursuit [C]// G GOVAERT.Data Analysis,London: ISTE Ltd,2009:67-92.
[14]楼文高, 乔龙. 投影寻踪聚类建模理论的新探索与实证研究[J]. 数理统计与管理, 2015, 34(1):47-58.
[15]W WU, R J MAY, H R MAIER,etal. A benchmarking approach for comparing data splitting methods for modeling water resources parameters using artificial neural networks [J]. Water Resources Research, 2013, 49(11):7598-7614.
[16]R J MAY, H R MAIER, G C DANDY. Data splitting for artificial neural networks using SOM-based stratified sampling [J]. Neural Networks, 2010, 23(2):283-294.
Tax-Checking Assessment of Small and Medium-Sized Enterprises Applying Projection Pursuit Clustering Technique and Its Positive Research
LOU Wen-gao1,LOU Ji-tong2,SONG Lei-juan1, WANG Lang-qing1
(1.Faculty of Fiscal and Financial, Shanghai Business School, Shanghai 200235,China; 2. The University of North Carolina at Chapel Hill, NC 27514,USA)
Based on the 15 variables’ (indexes’ ) tax-reporting data of 386 wooden-furniture manufacturing small- and medium-sized enterprises (WFMSMEs) located in some districts of Shanghai city, the ten variables mainly influencing the tax-checking situation (tax evasion or compliance) of the 386 WFMSMEs were obtained by applying sensitivity analysis method (SAM) for selecting input variables. The modelling set data and testing set data (about taking up 45%) with similar characteristics - similar mean values and variance-were divided using self-organizing map (SOM) approach. The practical, feasible and effective projection pursuit clustering (PPC) model for tax-checking assessment was thus established. Compared with the multivariate linear regression (MLR), the multivariate discriminant analysis (MDA), Logistic and the support vector machine (SVM), the established PPC model possesses the most accurate and the lowest classification-error percentage (CEP) of the models. The mean CEP of modelling set data and the testing set data is lower than 6%. The improved PPC model including fewer variables is thus suitable to tax-checking assessment and research. The tax-checking situation of the other 339 WFMEs was also assessed and judged, and the results show that the established improved PPC model possesses high generalization and robustness.
tax-checking assessment; projection pursuit clustering (PPC) model; classification-error percentage; samples splitting
2015-07-02
上海高校知识服务平台“上海商贸服务业知识服务中心”建设子项目“税收风险管理信息系统设计及开发”(ZF1226);上海地方本科院校“十二五”内涵建设上海商学院重点学科专业建设“金融学人才培养模式改革与创新”;2013年国家大学生创新创业训练计划项目(CXGJ-13-002)资助
楼文高(1964—), 男,教授,博士
E-mail: wglou@sbs.edu.cn;wlou64@126.com
TV139.1; N945.12
A
