基于AssiStudy的形成性评价系统及学生进程监测*
2015-06-04孟凡茂
孟凡茂
(临沂大学 外国语学院,山东临沂 276005)
一 引言
在最近的计算机辅助评价(Computer-Assisted Assessment,CAA)系统中,评价策略是基于每道题的正确答案,该答案在学生答案(Students Answers,SAs)评价中被用作参考答案(Reference Answer,RA)。RA和SAs之间的相似性是根据词的共现,通过传统的信息检索(Information Retrieval,IR)技术来确定,尤其是处理较长文本时,这种方法通常很有效,这是因为相似的长文本往往同现词的频率高。然而,在较短的自由文本答案中,词的同现可能很少或没有,意思却近似。同时,RA不应是唯一的,因为一个问题可能会有多个不同的答案[1]。其次,另外一个负面因素是没有考虑到教师的评价标准,仅仅考虑的是RA和SAs之间的相似度。
为此,我们研发了辅助学习(Assisted Study,AssiStudy)系统作为学生的形成性评价工具,该系统能帮助教师设计和评价考试并监测学生的进展情况。在自动评价答案的过程中,该系统依据单词及其POS标签,对每个问题都自动生成几种RAs,这样,学生所提交的答案就可以与几种RAs进行比对,从而确保了更为准确的判分;通过各种自然语言处理(Natural Language Processing,NLP)技术,AssiStudy先将RA和SAs转换成更易处理的规范形式,通过在RA中搜索SAs的近似词,进行单词匹配运算,并根据SA和RA之间的共有词义,计算出近似得分,这种方法更适合于用来评估内容相似而相同词几乎不共现的简短答案。
二 CAA的方法综述
自20世纪60年代以来,CAA就一直是一个不断发展的开发领域。CAA系统评估论述题答案的方式分为三类:形式、内容或者二者兼有。目前CAA系统中最为重要的方法是统计法(Statistical)、潜在语义分析法(Latent Semantic Analysis,LSA)和自然语言处理法。最初的CAA系统的评价方法主要用来捕捉文本结构的相似性;之后的CAA都基于LSA,超出了对简单共现词的分析,采用两种解决问题的途径,即基于语料库技术和代数法来识别比较两个措辞不同的文本之间的相似性;最近的CAA都是基于NLP技术,能够进行智能分析,捕获自由文本文档的语义信息。但是,绝大多数CAA系统从两个维度评分,而且,这些系统所采用的方法差别很大。最近,教育数据挖掘(Educational Data Mining,EDM)应运而生。EDM具备四项功能:学习建模、辅导、信息存储和评价[2]。为了既支持评价也支持预备基架,通过结合文本回放标记所研发的模型、环境对学生的探究技能做出推论,这种方法能够对学生日志文件和教育数据挖掘迅速地进行人工编码。
以上这些系统都不适于我们的用途,因为它们只能处理英文文本,而且需要学习大量的文本。为此,我们创建了AssiStudy系统,该系统通过广泛应用文本预处理技术和词汇网路(WordNet)数据库,极力减弱对大型语料库的需求,从而公平地评价内容简短的文本答案。
三 AssiStudy系统架构
鉴于服务导向式架构(Service-Oriented Architectures,SOA)[3]的各种优点(如:模块化、互操作性和可扩展性),我们研发了一个以SOA为基础的系统进行形成性评价和终结性评价。该AssiStudy体系结构主要由以下四个层所组成:
客户端应用程序层(Client Application):该层用来处理数据和流程的安全性和隐私;
业务层(Business):该层包含了AssiStudy的主要模块,每一个模块都包含一组可用的核心服务,在不同层级中分离业务逻辑将会使得AssiStudy具有模块化和灵活性;此外,该层能够以一种简易且灵活的方式更新业务逻辑;
服务层(Service):在该层中,可通过服务注册中心直接调用域名Web服务;
资源层(Resource):该层包含了AssiStudy的基础结构资源,即数据库以及与域相关的系统和工具,譬如:学校信息系统和协作学习工具,其中每个系统和资源都有一组Web服务。
AssiStudy作为通用而又灵活的系统得以开发。说它通用是因为它能够应用于任何领域的研究,该系统的创建目的就是处理不同的知识领域;同时,它又是灵活的,因为它既可以作为一个独立系统,也可以通过Web服务,增加新模块或特殊种类的应用程序。图1所描绘的就是该系统架构的概貌。
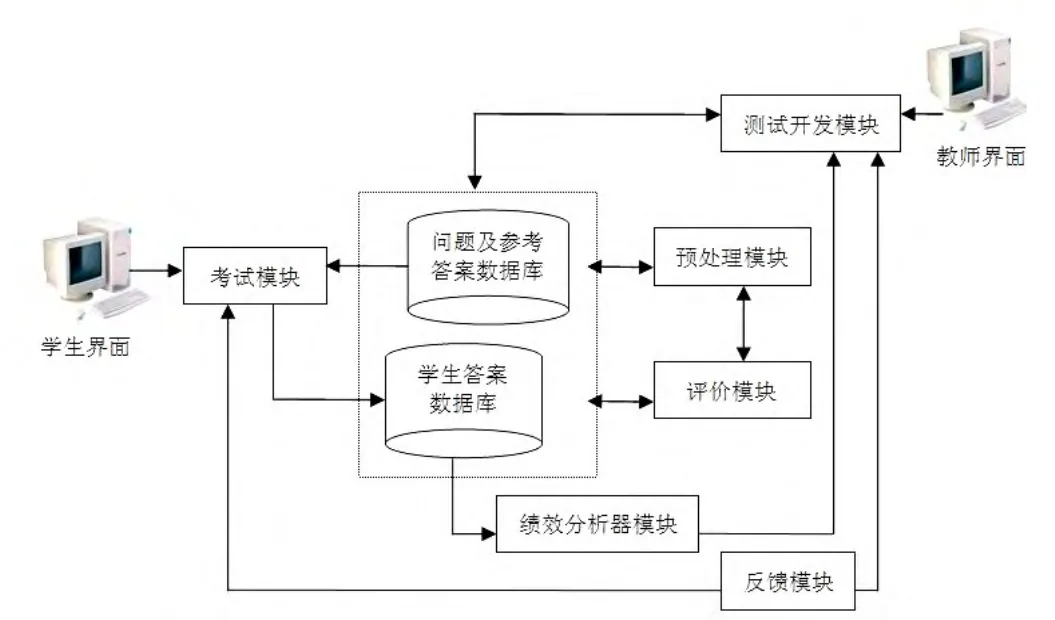
图1 AssiStudy系统体系结构
1 测试开发模块
通过该模块,教师可以查询在以前的考试判分中涉及某一个特定方面的所有问题,这些问题都被存储在问题及RA(Question&RA)数据库中。此外,教师有可能查阅每道题目的难度级别,当然,这种难易度的判别要基于之前的考试中学生的得分情况。再者,对于某个指定的题目,教师对学生所做的所有考题及得分都有访问权限,这样教师在考前就能了解他们要评估的学生对于不同考题内容的准备情况,从而,就能更为恰当地评价每个班级的考试情况。
考试评估由AssiStudy完成,之后老师再进行核查。一个班级的考试评判一旦完毕,其中的问题以及与此相关的所有信息都会被存储到问题及参考答案(Question&RA)的数据库中,在其后的训练考试时就可据此加以说明。SAs都存储在学生答案数据库(Student Answer Repository)中;获得满分的论述题的SAs也存储在Question&RA的数据库中,以便在将来的评价程序中进行应用。Question&RA的数据库非常重要,因为AssiStudy系统中几乎所有模块的成功与否在很大程度上取决于该数据库的优劣。
2 考试模块
根据学生的状况以及教师在先前的模块中所限定的内容,训练考试会从Question&RA库中随机选择考试题目。假如大一新生在第一学期首次考试,该系统将根据学生的档案信息,试题会依据前面所述的五个话题方面的内容自动生成,但其中每个话题的问题数量和难度由AssiStudy界定。学生已做过的试题及得分都被记录下来,并计算出学生对每个话题的定性得分(低、中或高),这些信息都被存储在Student Answer Repository中。另外,Question&RA的数据库中储存了很多试题,除了其他的属性外,每一道题都被标识出其内容归属、难度和分数,根据这些信息和一定程度的随机化,AssiStudy将会自动从Questions&RA库中挑选试题,为每位学生设计出训练试题。评估训练考试仅靠AssiStudy系统完成,纠错则需由反馈模块中所设立的解释来弥补。
3 预处理模块
(1)检测专有名词:在英文文本情况下,检测单词开头首字母是否大写;
(2)删除标点符号:该项任务就是要删除所有特殊字符并将所有字母转换为小写,除非是专有名词。特殊字符是指不属于单词的一些符号(如:标点符号),但单词的重音符号予以保留,以免误认为是拼写错误;
(3)校正单词拼写错误:用来检查拼写错误的校正器是Jspell[4];除了检测错误拼写外,Jspell会提示正确的单词,拼写错误的单词会被正确的单词替换;
(4)删除无用词:无用词与内容无关,删掉它不影响句子的语义;
(5)词干提取:在这个阶段,将个别单词简化为其基本型或词干,一个单词的基本型即是其词根或词元;
(6)文本标记:该项任务就是给单词标注词性(Part of Speech,POS)标签,此项操作也是由Jspell[7]完成;这种分类要求对标注相同POS的单词进行对比;一个单词可能会有多个POS标签,依照其出现的语境而定;正是由于各种不同的可能词性,该Jspell形态分析器会给每个单词标注可能的POS标签;为了避免词性标注的模糊性,在编辑程序中将呈现规范标准的RAs,这样,教师就可以正确地选择每个单词的POS标签,而其他标签会自动删除;
(7)同义词:一个词的同义词列表取决于其POS标签,每一个单词会有一个与其POS标签相关的同义词列表,把涉及该单词的所有同义词以及它们的POS标签添加到RA中,从而完全相同的RA会产生几种解释;一个单词与其每一个同义词之间的匹配得分是通过WordNet.pt词汇数据库[5]分析它们之间的最短路径得出,为了测量两个单词之间的语义关联度,前人已通过语义网络信息研究出了多种测量方法。本研究中,鉴于在WordNet层次结构方面相对较高的计算效率,我们选择了Leacock&Chodorow(L&Ch)的测量方法,L&Ch相似度的计算公式为:
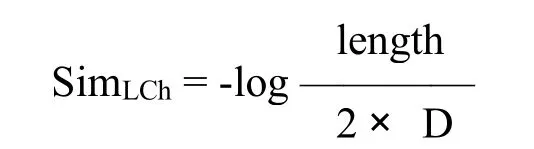
该公式中,length指通过计数节点所得的两个概念之间最短路径的长度,D代表分类的最大深度。
4 评价模块
该模块能够自动得出一个分数,并由此根据规范的RA和 SA的意义显示出这两者之间的相似性,从而胜过简单的词汇匹配。这一目标的实现是在计算出SA和 RA之间总的语义相似度之后,根据相应的RA的语义相似度,构建SA向量。根据SA向量和RA之间的距离,RA就是该单位向量,如图2所示。
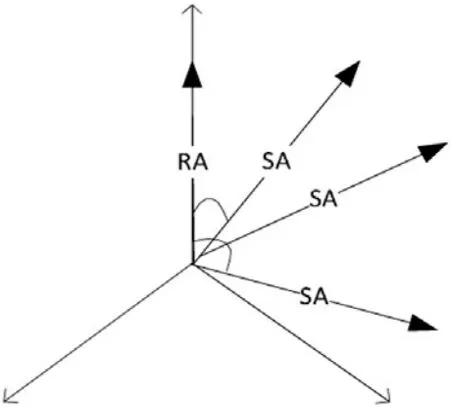
图2 空间向量模型
SA向量和RA向量之间的相似度取决于欧几里得(Euclidean)点积,公式如下:

5 反馈模块
AssiStudy提供的反馈由学生得分和RA中所收集的答案信息构成。为此,SA中遗漏或不完整的要点会在RA中得以搜索,而且相关的分数以及详细的解释会得以呈现。AssiStudy自动反馈的其中一大优点就是学生获知反馈迅捷,即测试提交完毕学生即可获得反馈,如此能促进学生更加深入的学习;而教师能够看到每位学生的答卷及评语,了解学生的得分情况,同时,也能知道全班遗漏的最为重要的知识点,从而能够迅速获悉整个班级的学习情况。
6 表现分析器模块
该模块是基于统计和数据挖掘(Statistics and Data Mining)技术研发,其设计目的是分析有关评判结果的数据。我们研发了几种数据挖掘模式来洞察学生有关训练考试成功与否的情况。最为有用的模式通过k平均聚类算法(Clustering Algorithm K-means)[6]获取,这样就能获悉哪些问题难哪些问题易,并通过信息分析,修改问题的难易度。而使用C4.5分类算法(Classification Algorithm C4.5)[7],对学生训练考试进行分析,就能推断出学生或班级对于即将来临的评价考试的准备状况。另外,通过关联规则Apriori算法(Association Rule Algorithm Apriori)[8],就能发现训练试题与学生最终成绩之间的关系,从而了解学生对哪些问题准备得更好。
四 评价与分析
为了检查AssiStudy系统在提高过关率方面的有效性,我们进行了一次测试。表1显示:使用AssiStudy的学生平均过关率比不使用该系统的学生的过关率高(t=57.65,df=533,p<0.05),因此,通过AssiStudy能提高通过率。
同时,我们也对考试自动评价与教师评价进行了对比。表2显示了2012-2013学年4次考试中教师评分和系统评分情况。

表1 经过AssiStudy训练和没有经过训练的过关学生数量对比
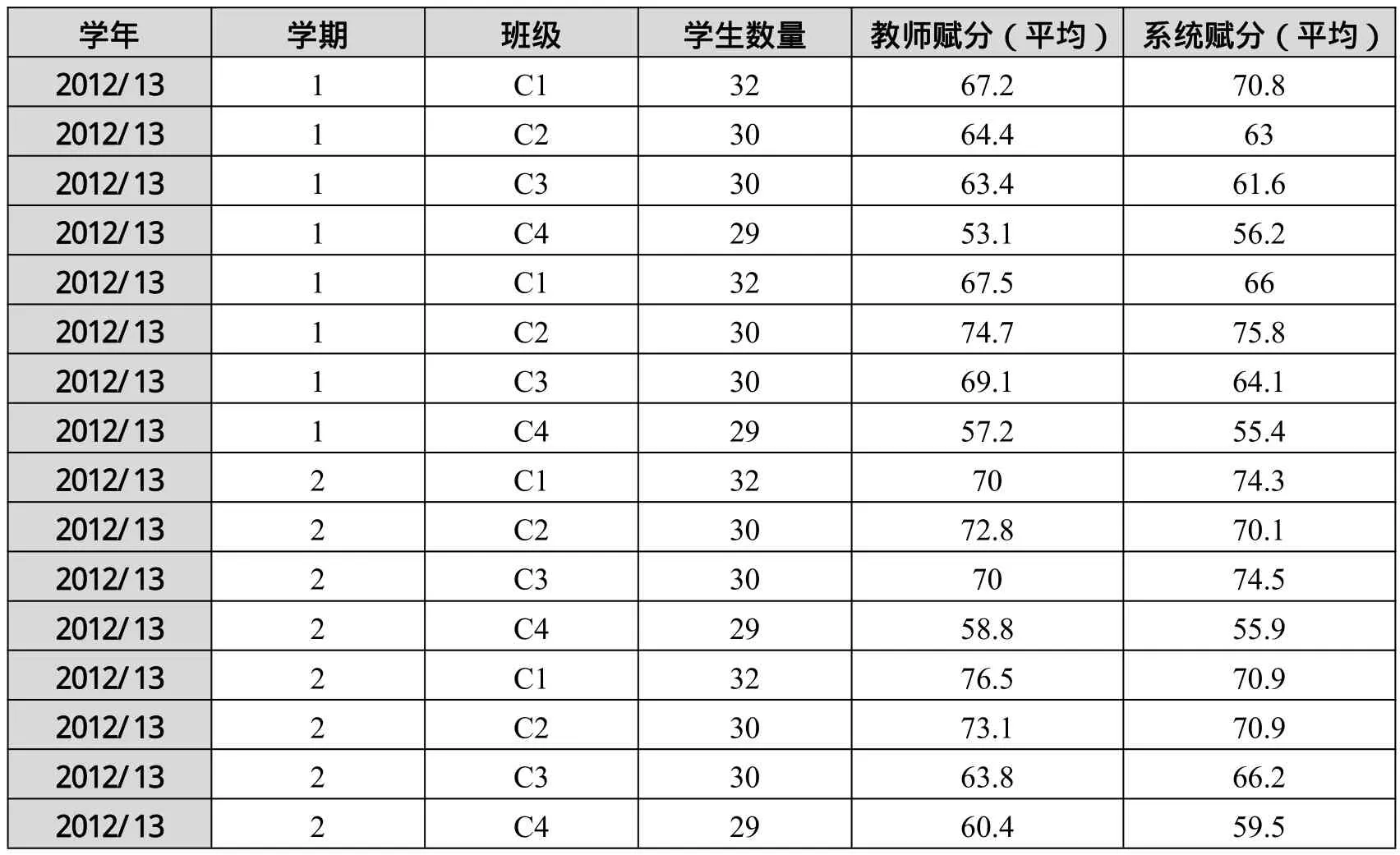
表2 2012-2013学年考试中的分值情况
结果显示:对于不同的考试评分,教师判分与系统判分差别并不太大;教师评判与系统评判之间的皮尔逊相关系数(Pearson correlation)为0.88。
AssiStudy系统的误差分析显示,误差分为两类:漏判(False Negatives,FN)和误判(False Positives,FP)。当考试得分比应得分数低时,就会发生FN;而FP是指判分过高。一般而言,如果系统与教师判分不匹配,通常是因为教师判分略高,这是因为SA太抽象或比RA短少,而在这种情况下,AssiStudy系统判分会比预期的分数低,这是因为系统的判分标准是基于词的匹配,而且,有些SAs在RA中无匹配的格式所致,但是,教师却能根据SAs推断出学生对于所学的理解程度,从而,判分时给出较高的分数,这样就增大了系统评价与教师评价之间的差异;而当学生不知道问题答案,碰巧又写出了一些与RA相匹配的单词时,系统判分最易发生FP。
五 结论
AssiStudy系统不仅可以作为对学生考试的形成性评价工具,也能帮助教师创建并评价考试,还可以监控学生的学习进展状况。实验证明,采用AssiStudy系统进行训练的学生比不参与的学生会获得更高的成绩,考试通过率大大提高;而对于教师而言,该系统的研发非常实用,因其能大大减轻教师阅卷的工作量。
[1]Noorbehbahani F,Kardan A A.The automatic assessment of free text answers using a modified BLEU algorithm[J].Computers&Education,2011,(2):337-345.
[2]Peña-Ayala A.Educational data mining:a survey and a data mining-based analysis of recent works[J].Expert Systems with Applications,2014,(4):1432-1462.
[3]Al-Smadi M,Gutl C.SOA-based architecture for a generic and flexible e-assessment system[A].In Education engineering(EDUCON),2010 IEEE[C].2010:493-500.
[4]Simões A M,Almeida J J.Jspell.pm–a morphological analysis module for natural language processing[A].In Actas do XVII Encontro daAssociação Portuguesa de Linguística[C].Lisbon,2001:485-495.
[5]Marrafa P,Amaro R,Chaves R P,et al.WordNet.PT new directions[A].In Proceedings of GWC.2006,(6):319-320.
[6]Hartigan J A,Wong M A.Algorithm AS 136:a k-means clustering algorithm[J].Journal of the Royal Statistical Society,Series C(Applied Statistics),1979,(1):100-108.
[7]Quinlan J R.C4.5:Programs for machine learning Morgan Kaufmann,1993,(1):235-240.
[8]Agrawal R,Imieli_nski T,Swami A.Mining association rules between sets of items in large databases[J].ACM SIGMOD Record,1993,(2):207-216.
