面向云存储的非结构化数据存储研究
2015-05-30王存宇等
王存宇等


摘 要: 云存储是网格、并行和分布式计算等众多技术发展和延伸,云存储实现了存储的完全虚拟化,提供更强大的存储及共享功能[1]。非机构化数据包括文本、图像、音频、视频、PDF、电子表格等。非结构化数据的存储通常有两种方式,一种是使用文件系统以文件的方式存储,将文件的路径或者链接存储在关系型数据库表中;另一种是将这些数据存储在传统的数据库表的大对象字段中。文章主要研究非结构化数据的存储方式,结合非结构化数据的特点,云存储的优势以及MongoDB的数据存储特性,提出非结构化数据云存储的必要性。
关键词: 云存储; 非结构化数据; MongoDB
中图分类号:TP399 文献标志码:A 文章编号:1006-8228(2015)05-13-03
Abstract: Cloud storage is the development and extension of a number of technologies, such as grid, parallel and distributed computing. The storage virtualization has been completely realized to provide more powerful storage and sharing functions. Unstructured data is including text, image, audio, video, PDF, spreadsheet, etc. Typically, there are two ways to store unstructured data, the first way is to store it as a file, and store the path or the link to the file in the table of relational database, and the other way is to store it in the Blob field in table of traditional relational database. This paper mainly studies the ways to store unstructured data, combined with the characteristics of unstructured data, the advantages of cloud storage and the storage characteristics of MongoDB, proposes the necessity of storing unstructured data in cloud.
Key words: cloud storage; unstructureddata; MongoDB
0 引言
随着社会信息化进程的不断加快,网络中的数据量变得庞大,原有的数据处理方式已经不能满足现阶段人们对于数据处理的高要求。所以云计算和云存储在这种环境下应运而生,这加快了大规模数据的处理速度,增加了大规模数据的存储量。而现阶段由于数据结构化过于受限于人工处理,非结构化数据的增长速度远远大于结构化数据。所以对于非结构化数据的存储研究将非常有意义。
1 分布式存储技术介绍
1.1 什么是分布式存储技术
分布式存储系统是大量普通PC服务器通过Internet互联,对外作为一个整体提供存储服务。
1.2 分布式存储系统中数据如何分布
分布式系统要解决的主要问题是数据分布。如何将数据均匀分布到多个存储服务器节点中,这些分布的数据要保证可靠性和可用性,需要将数据复制到多个副本。我们要做的就是要保证多个副本之间的数据一致性。
一般来说,分布式存储系统会保存多份数据在不同的服务器上,当其中一份数据在服务器上发生故障时,能通过其他的副本继续提供服务。其中一个副本为主副本,其他副本为备份副本,通常操作方法为:数据写入到主副本,由主副本确定操作顺序并复制到其他副本。主要的操作方法有两种:强同步复制副本和异步复制副本。
1.2.1 强同步复制副本
客户端将写请求发送给主副本,主副本将写请求复制到其他备份副本中和,常见的做法是同步操作日志。主副本首先将操作日志同步到备份副本,备份副本回放操作日志,完成后通知主副本。接着,主副本修改本服务器,等到所有的操作都完成后通知客户端写成功。这种要求主、备同步成功才可以返回给客户端写成功的协议称作强同步协议。如图1所示:W1写请求发给主副本;W2主副本将写请求同步给副本;W3备份副本通知主副本同步成功;W4主副本返回客户端写成功。
实现强同步复制时,主副本可以将操作日志并发的发给所有备份副本并等待回复,只要有一个备份副本返回成功就可以回复客户端操作成功。其优点为:如果主副本出现故障,至少有一个备份副本拥有完整的数据,分布式存储系统可以自动地将服务切换到最新的备份副本,不用担心数据的丢失。
1.2.2 异步复制副本
与强同步对应的复制方式就是异步复制。在这种复制模式下,主副本不需要等待备份副本的回应,只需要本地修改成功就可以告知客户端操作成功。其优点在于系统的可用性较好,但是一致性较差,如果主副本发生不可恢复性故障,可能丢失最后一部分更新操作[1]。
2 非结构化数据存储方式
非结构化数据具有如下五个特点:第一,存储方式不统一,通常情况下,用户各自管理自己的非结构化数据,包括结构化的数据管理、FTP以及传统的纸质资料管理等多种方式;第二,非结构化数据格式多样化,如Word、Excel、PDF、JPEG图等等;第三,业务流程多样,非结构数据处理涉及的流程主要有上传下载、打印扫描、系统内部流传等;第四,非结构化数据难以标准化,相对结构化数据,也更难理解,所以在存储、检索、发布以及利用上需要更加智能的IT技术,比如内容保护、知识挖掘、智能检索、海量存储等;第五,非结构化数据遍布于异构系统中,信息量非常大,尤其是多媒体数据,从信息整合的角度分析,信息需要集成。基于上述五点,存储非结构化数据在技术上是一项巨大的挑战。目前对非结构化数据的存储方式主要有如下三种:文件系统存储、数据库存储以及数据库与文件系统结合存储的方式。
2.1 文件系统存储方式
文件系统存储方式通过文件系统直接把数据存储在文件服务器中。数据资源以文件的形式存放在计算机的特定目录下,仅仅通过人工对文件夹进行简单的分类,所以数据的存储通常是无序的。需要访问数据时,应用程序直接通过文件存储路径读取文件。早启的计算机对数据存储要求简单,文件系统可以满足数据的管理要求。
随着计算机技术的发展,计算机的应用领域扩展,数据不仅类型变的多样,数据量也迅速积累、增长,文件系统提供的数据存储能力已经无法满足应用的需求。文件系统存储方式无法更好的解决根据属性对数据进行索引、查找、排序的问题,通常需要程序进行定制[3]。
2.2 数据库存储方式
关系数据库自出现以来,功能不断发展。目前大多数应用系统中的非结构化数据都是以二进制的格式存储在关系型数据库的BLOB字段中。用户直接向数据库发送请求进行数据操作。但是存储在BLOB字段中有一些缺点:一是非结构化数据文件大,随着数据量的不断增大,会导致关系型数据库存储量迅速膨胀,影响数据库性能,进而使得整个应用系统的性能下降;二是各应用系统之间相对封闭和独立,其他应用无法共享相关文档资料。
关系型数据库是针对结构化数据的处理而产生的,无法很好地满足现在网络环境下对于非结构化数据的处理要求,例如数据的全文检索就显得力不从心。
多媒体数据包含多种信息类型,数据格式的特殊性带来了数据存储结构和存取处理的差别。多媒体数据库随需要应运而生。多媒体数据库结合了数据库技术和多媒体技术,继承了传统关系数据库的优点,其作为一种全新的数据系统,可有效实现多媒体数据的存储检索。
非结构化数据库是基于网络应用的新型数据库,作为结构化数据库的补充,可以表达复杂的嵌套,支持更多的数据类型。关系数据库限制了数据长度且改写不方便,而非结构化数据库支持重复字段,变长记录可由若干重复的字段组成,每个字段又可由若干可重复的子字段组成。非结构化数据库概括而言,就是字段数和字段长度可变的数据库,在处理非结构化信息方面有着传统关系型数据库无法与之相比的优势。
2.3 数据库与文件系统结合存储方式
数据库与文件系统相结合的模式是将非结构化数据以文件的形式存放在计算机中,数据文件的存储路径存放在数据库中。此种方式下非结构化数据源文件存放在的文件系统中,便于数据的浏览、传递和更改。而非结构化数据文件的属性则采用数据库中的数据表字段进行表述,方便数据的检索、分类、查找,有序地存储了数据文件。内容管理系统便是数据库与文件系统相结合模式的典型应用。内容的含义比数据更为广泛,“内容”强调对象,可以是任何结构的数据类型,不仅包含了结构化数据、非结构化信息,还涉及到知识。可以说,内容是一个比数据、文档和信息更加全面的概念,是对所有结构化数据、非结构化数据及信息的聚合。内容管理侧重于管理半结构化和非结构化数据。在研究数据存储方式的基础上,内容管理还致力于对象的处理过程,例如收集、存储、检索、分析、更新、传递等,以便将内容能够及时准确的传递到正确的地点和用户。内容管理是数据管理新的发展方向。
非结构化数据存储技术与数据库的发展密切相关,更与文件系统及其存储技术的的发展密不可分。设计无限大的存储空间、无限制的I/O带宽和更高的性价比的理想存储系统是缓解存储压力的总体目标。云存储技术发展结合各种存储技术应用的特点,在吞吐量、冗余、容错、读写分布、数据划分、负载均衡等特性方面进行技术提升,并综合多种存储技术适应复杂的不同种类的数据存储需求[4]。
3 MongoDB
MongoDB是lOgen公司研发的面向文档 开源的NoSQL数据库系统,用C++语言编写,是当前最流行的NoSQL数据库。它提供一种强大、灵活、可扩展的数据存储方式。
3.1 MongoDB数据模型
一个MongoDB系统由多个数据库组成,每个数据库由一组集合组成,每个集合由任意个文档组成,而文档由一系列字段组成,每个字段是一个键值对,其中键是字段名称,值为对应的属性值,数据模型如图2所示。MongoDB的集合类似关系型数据库中的表,用户不用预先定义一个集合的字段结构,可以存储不同结构的文档在同一个集合,在数据库运行时,可以随时动态地添加或删除文档的字段。MongoDB的文档使用BSON结构,一个文档对应一个BSON对象,包含多个键值对,BSON是一种二进制序列化的类JSON数据交换语言。它以二进制字节的形式存储键值对,键为字符串格式,值可以为任意数据类型,除了基本的整数、浮点数、字符串、日期等,还可以是数组或键值对。
MongoDB的文档采用BSON的二进制结构,可以节省存储空间,BSON格式的存储效率在最坏的情况下也比JSON做好情况下的高。除此之外,BSON还支持键值对、数组这类的复杂数据结构,使得MongoDB的文档可以嵌套子文档或者数组,如此,MongoDB就不用像关系型数据库那样需要依靠外键关联其他的集合,而只需要设计一个集合,提高了数据库的性能。在某些情况下,BSON会牺牲额外的存储空间换取更高的传输速度。下面代码为一个典型的BSON对象。
{
Name:”Jack”,
Address:{city:”Hangzhou”,state:”China”},
Likes:[‘Bascketball,Music,Football],
Grade:[{lesson:”Computer”,score:99},{lesson:”math”,score:88}]
}
3.2 MongoDB特性分析
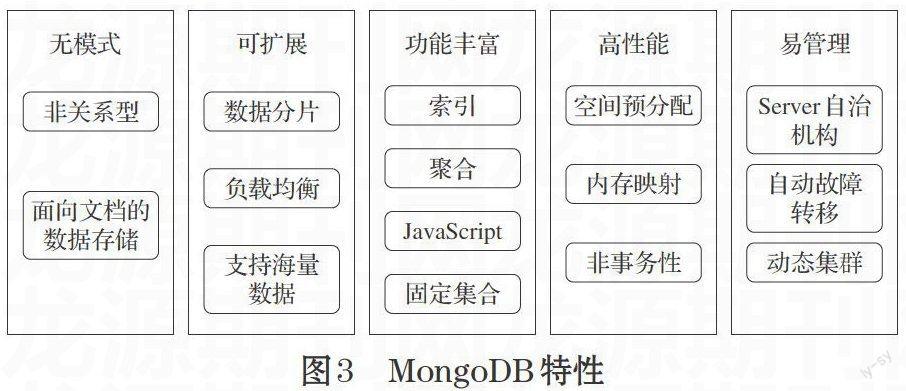
MongoDB扩展了关系型数据库的众多功能,如辅助索引、分片、复制等。与其他NoSQL数据库不同的是,MongoDB还具有建立索引、使用聚合等功能,在完成这些功能的同时,MongoDB并未牺牲速度。MongoDB的主要特性如图3所示。
[无模式][非关系型][面向文档的数据存储] [可扩展][数据分片][负载均衡][支持海量
数据] [功能丰富][索引][聚合][JavaScript][固定集合] [高性能][空间预分配][内存映射][非事务性] [易管理][动态集群][Server自治机构][自动故障
转移]
图3 MongoDB特性
⑴ 丰富的数据类:MongoDB是面向文档的数据库,为了获得更加灵活的横向扩展性,MongoDB抛弃关系存储模型。它是无模式的,文档中的字段不用事先定义,也不是一成不变的,应用层可以很容易地向文档中添加字段,更改数据模型。
⑵ 容易扩展:MongoDB在设计之初就考虑到数据库扩展的问题,无模式的数据模型可实现服务器之间的自动分割。通过MongoDB的自动分片机制,可以动态实现集群中数据的均衡负载。
⑶ 功能丰富:支持辅助索引、存储JavaScript和MapReduce等其他独特功能。
⑷ 卓越的性能:MongoDB中文档记录是可以动态扩充,预先分配数据文件,用空间换取稳定的性能。默认情况下,存储引擎配置了内存映射文件,管理内存的工作交由操作系统处理。
⑸ 管理简便:MongoDB采用复制集机制提升系统的可靠性,尽可能让服务器进行自动配置。MongoDB的核心是文档,每个文档中的字段名和值有序地存放在一起,文档可以比喻成关系型数据库中的元组。集合类似于关系数据库中的表,一个集合中包含若干个文档,多个集合构成一个数据库,一个MongoDB的实例创建多个相互独立的数据库[5-6]。
3.3 MongoDB分布式存储架构
MongoDB复杂数据的存储、管理和出错处理,它是一个高度容错的分布式存储系统,适合用于大规模非结构化数据的存储,部署在大规模的集群上,系统扩展能力强。
⑴ 分片
在MongoDB中,每个分片(shard)由一个或多个服务器构成,其上运行mongod进程来存储数据。在实际的生产环境中,为了提高系统的可靠性和实现自动故障恢复,每个shard就是一个replica set。replica set支持两个以上节点的自动故障恢复,其结构如图5所示。replica set实质上是一种异步的主从复制机制,每个replica set只能有一个primary节点,负责数据的写入;secondary节点只能读数据,并不能进行写操作。两类节点之间的一致性通过oplog来保证,所有的操作及其对应的时间戳都会被写入oplog,因其大小固定,所以新数据的写入会覆盖旧数据。所有的secondary节点监听oplog的变化情况,以实现与primary节点的同步。
⑵ 配置服务
配置服务(config servers)用于存储MongoDB集群的元数据信息,这些元数据包括两部分:一是shard server上的chunks信息;二是chunk上的集合信息和文档信息。每一个config server都包括了 MongoDB中所有chunk的信息,使用一个两阶段提交协议来保证config server中配置信息的一致性。config server拥有自己的复制模型,并不使用replica set的复制方式。当任何一个config server发生宕机时,集群中的元数据就变为只读状态,这样处理方式避免了系统在不稳定的情况下,冒然改动元数据信息,导致config servers节点间中出现元数据不一致的情形。但这并不影响集群的正常工作,仍然可以向集群中写入数据或从集群中读取数据。
⑶ 路由进程
路由进程(mongos),可以当作一个路由和协调进程,它使集群中的多个组件形如一个单一的系统。mongos接收到用户请求时,首先查询config server,找到存放相应数据的shard servers,然后把用户请求转发给对应shard servers。当所有的shard servers完成操作后,把结果分别发送给mongos。当mongos汇总了所有的结果后,再把最终结果返回给用户。mongos的每次启动,都要到config servers中读取元数据,并缓存在本地。每当config server中的元数据有改动,它都会通知所有的mongos。mongos可以运行在任何服务器上,同时启动的mongos进程数量也没有限制[7]。
4 结论
本文介绍了分布式存储技术,重点介绍了强同步复制副本,它比较稳定。比较了非结构化数据的三种存储方式。其中数据库与文件系统结合存储方式更适合非结构化数据的存储。研究了非关系型数据库MongoDB的数据模型和它的一些特性,分析了MongoDB的分布式存储架构、工作原理以及它在非结构性数据存储上所起的作用。
参考文献:
[1] 中国互联网络信息中心.中国互联网络发展状况统计报告[R].CNNIC,2014.
[2] Mell P,Grance T. The NIST definition of cloud computing (draft)[J]. NIST specialpublication,2011.800(145):7
[3] 陈康,郑纬民.云计算:系统实例与研究现状[J].软件学报,2009.20(5):1337-1348
[4] 谢华成,陈向东.面向云存储的非结构化数据存取[J].计算机应用,2012.32(7):1924-1928
[5] 刘正伟,文中领,张海涛.云计算和云数据管理技术[J].计算机研究与发展,2012.49(1):26-31
[6] 倪永军,谢长生.网络存储技术现状,存在的问题及对策研究[J].计算机工程与应用,2003.39(10):159-161
[7] 张薇,马建峰.LPCA分布式存储中的数据分离方法[J].系统工程与电子技术,2007.29(3):20-22
