低延迟路由器中高效开关分配机制的实现与评测
2015-05-29李存禄董德尊吴际雷斐王克非廖湘
李存禄 董德尊 吴际 雷斐 王克非 廖湘科

摘 要:开关分配位于片上网络路由器流水线的关键路径上,对路由器以至整个片上网络的性能都会产生很大影响.已有的开关分配方法主要针对标准流水线路由器进行分析改进,缺乏对低延迟路由器中基于时间序列的开关分配方法的研究.本文首次在低延迟路由器上实现了基于时间序列的开关分配机制,并针对分配过程中优先矩阵的构造特点进行了优化改进.仿真实验结果表明在低延迟路由器中采用基于时间序列的开关分配策略可以使片上网络的性能得到很大提升.
关键词:片上网络;开关分配;时间序列;低延迟路由器;短报文
中图分类号:TP391.9 文献标识码:A
随着芯片制造工艺的提高,单个芯片上所能集成的处理器核的数目也在不断增加[1].这些处理器核通过片上网络进行互连,并通过片上网络的数据交互来协同完成计算任务,因此片上互连网络的性能将极大地影响多核系统的整体性能.
开关分配位于片上网络路由器流水线的关键路径上,对路由器以至整个片上网络的性能都会产生很大影响.通常的开关分配方法通过提高当前周期内匹配的最大个数来提高性能[2],以使分配过程实现极大匹配或最大匹配.基于这一理念设计的分配方法有iSLIP[3],Wavefront[4],Augmenting Paths(增量路径)[1]等.
但是单个周期内的最大匹配并不一定就能实现整个系统上的性能最优,并且单个周期内的最大匹配往往使得硬件复杂度较高,功耗和时延也会相应增加.因此,新的开关分配方法在时间维度上进行了优化.George发现[5],当前片上网络中传输的数据包很多都是长度较短的包,例如在实际系统中有很大部分(78.7%)的数据包都是单切片报文(Single Flit Packet)[6],而且这些单切片报文所请求的输出端口往往和上一周期该端口成功分配的输出端口相同.基于此观察, Packet Chaining[5]和 PseudoCircuit[2]方法发现,加入前一周期成功分配的信息可以提高吞吐率;而TSRouter的方法进一步引入了时间序列(TimeSeries, TS)的概念,提出将未来多个周期的开关请求信息加入分配过程会进一步提高性能.虽然TSRouter中的方法使资源分配的性能得到很大提高,但是该方法只在普通路由器体系结构(General Router Architecture)[7]上进行了实现,而当前的路由器结构已经在普通路由器上进行了很大改进,一个典型的例子就是低延迟路由器(Lowlatency Router)[8] ,该结构极大地减少了路由器流水线的级数,使得数据包在路由器中的处理时间更短.为了使片上网络中路由器的整体性能最佳,我们将这两种技术进行了结合,在低延迟路由器上实现了TSRouter中提出的时间序列的方法,并对该方法进行了一些改进,降低了方法的复杂性,同时保证了性能.
本文首先介绍片上网络中低延迟路由器的体系结构,然后说明低延迟路由器上基于时间序列方法的实现过程和我们所做的改进工作,最后给出我们的方法在Booksim模拟器下的仿真结果以及对今后工作的展望.
1 低延迟路由器
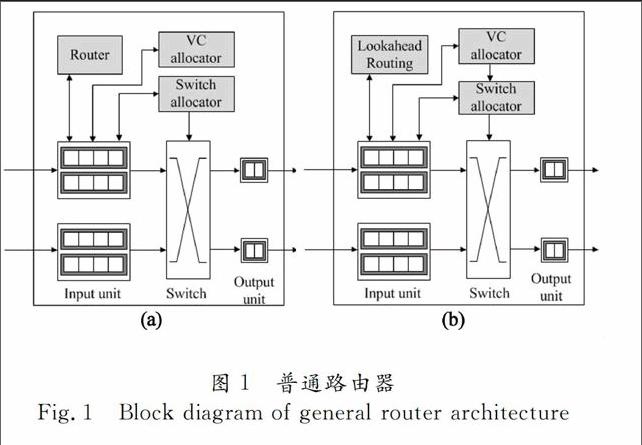
普通路由器体系结构由5个流水阶段组成:路由计算(Routing Computation),虚通道分配(Virtualchannel Allocation),开关分配(Switch Allocation),开关通过(Switch Traversal)和链路通过(Link Traversal).图1(a)展示了这种路由器的结构[1].每个输入端和输出端可以有多个虚通道,数据包要从输入端口到达特定的输出端口,必须由开关分配器(Switch Allocator)分配一个时钟周期,以使数据包在这个时钟周期内从开关中通过.每一个输入端首先通过路由计算模块确定当前数据包所需要到达的输出端口和允许的虚通道集合,然后再由虚通道分配器分配下一跳路由器输入端的一个空闲虚通道供数据包的输入.数据包要从输入端口到达特定的输出端口,必须由开关分配器(Switch Allocator)分配一个时钟周期,以使数据包在这个时钟周期内从开关中通过,开关分配器就是要在不产生资源冲突的前提下,决定当前周期哪个输入端可以向分配的输出端传输数据.在同一时钟周期内,每个输入端只能向一个输出端传输数据,每个输出端也只能接收一个输入端的数据.
为了减少数据包在片上网络的传输时间,提高吞吐率,路由器的结构进行了很多改进.图1(b)是一种低延迟路由器体系结构[2],我们将在此结构上实现改进后的基于时间序列的开关分配方法.该结构采用了适应性的超前路由(Lookahead Routing)[9]技术以及分配预测技术[10-12],省去了路由计算的流水阶段并将开关分配和虚通道分配并行执行.这种低延迟路由器比原来普通路由器减少了两个流水周期.
2 低延迟路由器中基于时间序列分配方法
的实现
时间序列分配的主要策略是优先分配可能和下一周期的请求冲突的当前请求.该方法首先获取下一周期的请求信息,如果当前周期资源的请求矩阵[1]中存在可能和下一周期的请求相冲突的请求,则优先分配这些可能发生冲突的请求.具体的说,就是在资源请求矩阵中将与下一周期的请求在同一行同一列的其他请求的优先级升高一级,这样在资源分配的时候就可以优先分配这些可能和下一周期请求发生冲突的请求.
在低延迟路由器下实现时间序列分配方法需要对路由器进行新的设计,关键是如何在当前周期内获取下一周期将要到达的请求信息.图2(a)所示的是TSRouter的数据流,它在普通路由器五级流水的基础上,通过增加一条从路由计算阶段到开关分配阶段的通路,将路由信息提前传递给开关分配阶段,而正常的数据流则要先通过虚通道分配后才能到达开关分配阶段,这样在开关分配阶段就可以提前一个周期知道下一周期要到达的请求的信息.
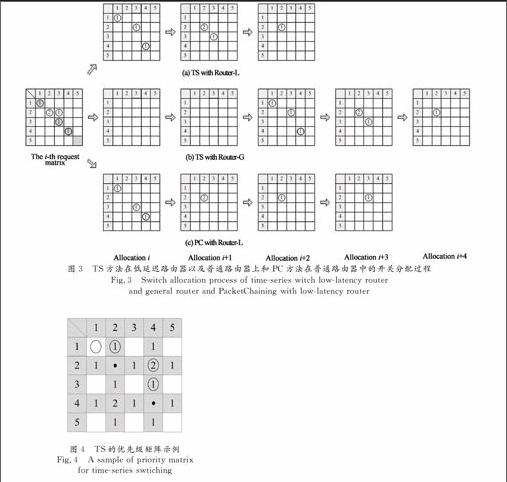
但是对低延迟路由器来说,通过增加新的通路来提前获取下一周期请求信息的方法却很难实现.图2(b)是低延迟路由器的数据流图,该结构路由器的流水线由路由计算/虚通道分配/开关分配(NRC/VA/SA)、开关通过(ST)和链路通过(LT)3部分组成.由于采用了超前路由和预测技术,路由计算、虚通道和开关分配可以并行执行.当数据包从输入缓存中读出后,如果是头切片(Head Flit)则会在下一周期同时进行超前路由计算、虚通道分配和开关分配,路由信息会和数据包一起到达路由器并立即进入开关分配阶段,因此我们无法提前一个周期获取路由信息.但是在进行开关分配的时候,我们可以知道哪个输入端的请求是新到达的,也就是说,这个请求在上一周期没有出现过.当一个新请求到达时,它之后的请求很可能申请的是和它相同的资源,即对同一个资源的请求可能连续多次出现.这样,我们虽然不能得到下一周期的请求情况,但是我们可以利用当前周期新加入请求的信息.如果一个新到达的请求和当前周期的任何一个请求具有相同的输入端或输出端,则优先分配这些可能发生冲突的请求.具体来说,就是将当前周期中冲突请求的优先级升高一级,使得这些请求可以被优先分配.因为新到达的请求所申请的输出端口被连续申请的次数很可能大于其他输入端口连续申请同一个输出端口的次数,所以如果其他输入端口上的请求优先分配的话,就可以使这些可能产生冲突的请求尽早分配完,以避免在接下来的周期与新到达的请求发生冲突.这种方法的有效性在片上网络的模拟实验中得到进一步验证.图3显示了利用这种改进后的时间序列方法(TS)进行开关分配的原理.图3(a)表示的是在低延迟路由器(RouterL)中使用改进后的TS方法进行开关分配的过程,图3(b)显示的是在普通路由器(RouterG)中使用改进后的TS方法进行开关分配的过程,图3(c)显示的是在低延迟路由器中使用PacketChaining(PC)方法进行开关分配的过程.图中将开关分配的请求通过矩阵表示,矩阵的每行代表一个输入端,每列代表一个输出端,行列相交的小方块则表示该输入端对输出端的请求状态.图中灰色方块表示该请求在上一周期被成功分配,圆圈表示当前周期的请求或资源分配情况,而圆圈内的数字则表示该请求在随后的多少个周期内会连续产生.这3种不同的分配过程使用相同的请求矩阵,该请求矩阵表示的是周期i中路由器开关输入端的所有请求的状态.为了更清楚地说明问题,我们没有考虑在每个周期中不断加入的数据包对分配过程的影响.我们给出了3种不同的分配方法将这些请求全部分配完所经历的过程,并给出了每个周期中成功分配的请求情况.图中请求矩阵中坐标为(2,2)的请求是新到达的,有两个连续的请求,该周期其他请求不是新到达的,只有一个连续的请求.图3(a)中,由于在低延迟路由器中,数据包刚到达路由器就可以进行开关分配,TS方法在3个周期内就可以分配完所有请求.而图3(b)中,由于普通路由器数据包达到后需要先经过路由计算和虚通道分配两个步骤才能开始进行开关分配,所以数据包到达后的前两个周期内没有成功分配的开关请求,直到第三个周期才开始按照TS方法进行开关分配,这样普通路由器就比低延迟路由器多出两个周期的延迟.从图3(c)中可以看出,同样是在低延迟路由器中,TS方法的性能明显优于PC,PC优先分配与前一周期分配结果相同的请求,需要4个周期才能分配完所有请求,而TS方法则只需要3个周期就能分配完所有请求.
但是对低延迟路由器来说,通过增加新的通路来提前获取下一周期请求信息的方法却很难实现.图2(b)是低延迟路由器的数据流图,该结构路由器的流水线由路由计算/虚通道分配/开关分配(NRC/VA/SA)、开关通过(ST)和链路通过(LT)3部分组成.由于采用了超前路由和预测技术,路由计算、虚通道和开关分配可以并行执行.当数据包从输入缓存中读出后,如果是头切片(Head Flit)则会在下一周期同时进行超前路由计算、虚通道分配和开关分配,路由信息会和数据包一起到达路由器并立即进入开关分配阶段,因此我们无法提前一个周期获取路由信息.但是在进行开关分配的时候,我们可以知道哪个输入端的请求是新到达的,也就是说,这个请求在上一周期没有出现过.当一个新请求到达时,它之后的请求很可能申请的是和它相同的资源,即对同一个资源的请求可能连续多次出现.这样,我们虽然不能得到下一周期的请求情况,但是我们可以利用当前周期新加入请求的信息.如果一个新到达的请求和当前周期的任何一个请求具有相同的输入端或输出端,则优先分配这些可能发生冲突的请求.具体来说,就是将当前周期中冲突请求的优先级升高一级,使得这些请求可以被优先分配.因为新到达的请求所申请的输出端口被连续申请的次数很可能大于其他输入端口连续申请同一个输出端口的次数,所以如果其他输入端口上的请求优先分配的话,就可以使这些可能产生冲突的请求尽早分配完,以避免在接下来的周期与新到达的请求发生冲突.这种方法的有效性在片上网络的模拟实验中得到进一步验证.图3显示了利用这种改进后的时间序列方法(TS)进行开关分配的原理.图3(a)表示的是在低延迟路由器(RouterL)中使用改进后的TS方法进行开关分配的过程,图3(b)显示的是在普通路由器(RouterG)中使用改进后的TS方法进行开关分配的过程,图3(c)显示的是在低延迟路由器中使用PacketChaining(PC)方法进行开关分配的过程.图中将开关分配的请求通过矩阵表示,矩阵的每行代表一个输入端,每列代表一个输出端,行列相交的小方块则表示该输入端对输出端的请求状态.图中灰色方块表示该请求在上一周期被成功分配,圆圈表示当前周期的请求或资源分配情况,而圆圈内的数字则表示该请求在随后的多少个周期内会连续产生.这3种不同的分配过程使用相同的请求矩阵,该请求矩阵表示的是周期i中路由器开关输入端的所有请求的状态.为了更清楚地说明问题,我们没有考虑在每个周期中不断加入的数据包对分配过程的影响.我们给出了3种不同的分配方法将这些请求全部分配完所经历的过程,并给出了每个周期中成功分配的请求情况.图中请求矩阵中坐标为(2,2)的请求是新到达的,有两个连续的请求,该周期其他请求不是新到达的,只有一个连续的请求.图3(a)中,由于在低延迟路由器中,数据包刚到达路由器就可以进行开关分配,TS方法在3个周期内就可以分配完所有请求.而图3(b)中,由于普通路由器数据包达到后需要先经过路由计算和虚通道分配两个步骤才能开始进行开关分配,所以数据包到达后的前两个周期内没有成功分配的开关请求,直到第三个周期才开始按照TS方法进行开关分配,这样普通路由器就比低延迟路由器多出两个周期的延迟.从图3(c)中可以看出,同样是在低延迟路由器中,TS方法的性能明显优于PC,PC优先分配与前一周期分配结果相同的请求,需要4个周期才能分配完所有请求,而TS方法则只需要3个周期就能分配完所有请求.
对每个请求的优先级的记录,是通过和TSRouter中相同的优先级矩阵[9]来实现的,图4说明了这种优先级矩阵的构造方法.图中黑点代表新到达的请求,圆圈表示当前的请求.对于每个新到达的请求,我们将与它在同一行和同一列的其他请求的优先级升高一位,这样每个请求都有自己对应的优先级,然后在开关分配的过程中选取优先级最高的请求优先分配.如图所示,由于(1,1)请求的优先级为0,小于(1,2)请求的优先级1,所以在开关分配中会优先选择(1,2)进行分配;同样,(2,4)的优先级2高于(3,4)的优先级1,所以也会优先选择(2,4)进行分配.
通过实验我们发现,构造优先级矩阵时可以不考虑一个新到达请求的输出端是多少,而直接根据这个新到达请求的输入端来进行决策,即选择一个固定的输出端口.虽然这种策略只根据输入端口的信息来决定各个请求的优先级,但是依然可以达到较理想的性能.基于以上观察,我们对TS分配方法进行了简化,只需要在每个输入端口处判断该端口的数据包是否是新到达的,如果是则将其他端口的请求的优先级升高后再进行开关分配.这种方法实现起来比较简单,硬件复杂度较低,我们只需要在每个输入端口增加一个判断逻辑,检测是否有新的请求到达并以此来更新优先级矩阵即可,该方法的性能评测结果将在下一章进行介绍.
3 性能评估
为了测试改进后的TS方法在低延迟路由器中的效果,本文使用修改后的BookSim模拟器进行实验仿真.实验在一个拥有64个节点的8×8二维Mesh网络[1]中进行,每个节点都连接有一个路由器,负责数据产生、转发或接收.每个路由器有5个端口(网络边缘端口数可能不足5个),其中4个端口与相邻的路由器连接,一个端口负责接收和向网络中注入数据包.网络中的每条链路由不同方向的两条链路组成,链路传输的延迟是一个周期.实验采用确定性维序路由(Deterministic dimensionorder routing,DOR)以及经典的VC流控策略[10],每个端口设有4个VC,每个VC的缓存长度是8个flit.我们将迭代一次的iSLIP(iSLIP1)分配器作为基准进行比较.实验中使用只有一个Flit的报文,并采用多种合成负载(synthetic traffic)进行评测.我们还与两种可以实现极大匹配的分配器进行了比较:maxsize和wavefront,maxsize分配方法采用Augmenting paths的策略实现最大分配,wavefront方法采用复杂的硬件逻辑实现极大匹配.
我们首先对方法的吞吐率进行了评测.图5给出了均匀负载下吞吐率随注入率的变化情况,我们将TS方法和一次迭代的iSLIP(iSLIP1)、两次迭代的iSLIP(iSLIP2)以及PC进行了比较.从图中可以看出,当注入速率小于0.4的时候,4种方法的吞吐率都呈直线上升,而当注入速率继续增大时,不同的分配器的性能开始有了明显差异.各个分配器的吞吐率均在约0.45的位置达到最大值,随后开始下降或保持不变.在整个过程中TS的性能最优,而PC优于iSLIP2和iSLIP1.iSLIP1方法作为其余三种方法实现的基础,性能最低.在饱和注入速率下,和iSLIP1相比,TS方法性能的提高比PC性能的提高高出27%.iSLIP2并没有比TS和PC有更优的性能,这是因为两次的迭代增加了路由器中开关分配所需的时钟周期数,并且迭代带来的分配效率的提高也并不明显.
图6比较了低延迟路由器与普通路由器的最大吞吐率.从图中可以看出,在均匀通信模式下,低延迟路由器中开关分配方法所能达到的最大吞吐率均优于普通路由器.对于特定的路由器结构,TS方法的性能均优于其他分配方法.我们发现在低延迟路由器中,maxsize的分配方法可以达到和TS方法相近的性能,这是因为maxsize方法在每个周期都分配最多的请求.这种只根据当前周期请求状况进行最大分配的策略,在请求数量较多的情况下具有很高的性能优势,而低延迟路由器由于缩短了路由器流水线长度,使得报文可以更快到达开关输入端,也就使得开关输入端能够有更多的请求等待分配,进而使得maxsize的性能得到很大提升.
图7显示的是不同注入速率时在均匀负载下两种路由器结构中不同开关分配方法的延迟.图7(a)显示的是在普通路由器结构下的评测结果,图7(b)显示的是在低延迟路由器中的评测结果,图7(c)显示的是网络低注入率时,采用不同分配器时的数据包平均延迟在普通路由器和低延迟路由器下的变化情况的比较.图中注入速率从0.1一直变化到1,数据包的延迟呈增长趋势.从图中可以看到,注入速率小于0.4时,由于网络中数据包较少而不会发生阻塞,数据包的延迟也相应的很小.而当注入速率大于0.4时,延迟开始快速增加.这是由于当注入速率超过饱和点时,在网络中某些节点上,数据包到达的速度可能超过节点的处理速度,造成数据包在该节点的阻塞,并且这种阻塞的情况还可以以树形的形式向数据包的源节点扩散,形成饱和树(Tree Saturation)[1].而在注入速率不断增加的过程中,TS的性能总是优于其他分配器,PC,maxsize,wavefront,iSLIP2和iSLIP1这3种方法的延迟依次升高.在注入速率大于饱和点时,与iSLIP1相比,TS分配性能的提高比PC性能的提高最高可以高出39%.
为了对性能进行进一步评测,我们对非均匀负载下方法的性能也进行了评测.图8显示了延迟的评测结果.对于不同的流量模型,开关分配方法的性能差异很大,虽然低延迟路由器中分配方法的性能普遍优于普通路由器,但是不同的分配方法在同一种流量模型下,以及同一种分配方法在不同的流量模型下性能的差异也是很大的.可以看出当数据包的注入速率较大时,TS方法的性能优势也较明显,这是因为在较高注入速率下TS可以获取更多的下一周期的请求信息.而PC方法则会在注入速率较大时出现饥饿(starvation)现象,这是由于PC方法在当前请求跟上一周期请求相同时会尽可能地保留当前分配情况,这样初始时未分配到资源的请求可能要等待很长时间来得到它所请求的资源,从而导致这些请求经常处于饥饿状态.
(a) bitcomp
(b) neighbor
(c) tornado
图8 非均匀通信模式下网络延迟与注入速率的关系
Fig.8 Injection ratelatency under
different traffic patterns
PC和TS方法在时间维度上对开关分配进行了扩展,实现了高效的单周期可实现的分配方法.但是在报文长度较长的网络中,在时间维度上获取的信息对当前分配的影响并不大或者会产生负面的影响(如进一步增加某些报文的等待时间,加剧饥饿现象),因此在报文长度较长时,这种基于时间维度设计的分配方法性能并不具有优势,甚至比其他分配方法性能更低.图9显示了均匀通信模式下,在低延迟路由器中,数据包长度从1(flits)到16(flits)时,网络的最大吞吐率的变化情况.从图中可以看出,当数据包长度不断变长时,各种分配策略的性能均有所降低,但是PC和TS方法降低的速度比其他分配方法要快.这两种方法在短报文,特别是单切片报文情况下性能很高,而当报文长度逐渐增加到16时,最大吞吐率与其他分配方法相差不多,或者比某些分配方法的性能更低.
Packet length in flits
图9 均匀通信模式下低延迟路由器网络
最大吞吐率随报文长度的变化
Fig.9 Maximum throughput by packet length for the
different allocators under uniform traffic pattern
4 结 论
本文在一种低延迟路由器上实现了改进后的时间序列分配方法.时间序列分配方法能够使路由器中开关分配的效率得到很大提高,低延迟路由器极大地减少了路由器流水线的长度,通过将这两种技术进行结合,能够更好地提升片上网络的性能.实验证明,在低延迟路由器中,时间序列分配方法能够使网络的吞吐率得到很大提高,同时降低了数据包在网络中的延迟.
参考文献
[1] DALLY W J, TOWLES B P. Principles and practices of interconnection networks[M]. San Francisco, USA: Elsevier, 2004.
[2] AHM M, KIM E J. Pseudocircuit: Accelerating communication for onchip interconnection networks[C]//Proceedings of the 43rd Annual IEEE/ACM International Symposium on Microarchitecture. USA: 2010 IEEE Computer Society: 399-408.
[3] MCKEOWN N. The iSLIP scheduling algorithm for inputqueued switches[J]. IEEE/ACM, 1999, 7(2): 188-201.
[4] TAMIR Y, CHI H C. Symmetric crossbar arbiters for VLSI communication switches[J]. Parallel and Distributed Systems, 1993, 4(1): 13-27.
[5] MICHELOGIANNAKIS G, JIANG N, BECKER D, et al. Packet chaining: efficient singlecycle allocation for onchip networks[C]//Proceedings of the 44th Annual IEEE/ACM International Symposium on Microarchitecture. USA: 2011 ACM: 83-94.
[6] MA S, JERGER N E, WANG Z. Whole packet forwarding: Efficient design of fully adaptive routing algorithms for networksonchip[C]//High Performance Computer Architecture (HPCA). USA: 2012 IEEE: 1-12.
[7] AGARWAL N, KRISHNA T, PEH L S, et al. GARNET: a detailed onchip network model inside a fullsystem simulator[C]//Performance Analysis of Systems and Software. USA: 2009 IEEE: 33-42.
[8] MULLINS R, WEST A, MOORE S. Lowlatency virtualchannel routers for onchip networks[C]//ACM SIGARCH Computer Architecture News. USA: 2004 IEEE Computer Society, 32(2): 188.
[9] GALLES M. Scalable pipelined interconnect for distributed endpoint routing: the SGI SPIDER chip[C]//Hot Interconnects. USA: 1996 IEEE: 96.
[10]PEH L S, DALLY W J. A delay model and speculative architecture for pipelined routers[C]//HighPerformance Computer Architecture. Mexico: 2001 IEEE: 255-266.
[11]CHANG Y Y, HUANG Y S C, POREMBA M, et al. Tsrouter: On maximizing the qualityofallocation in the onchip network[C]//High Performance Computer Architecture (HPCA2013). China: 2013 IEEE: 390-399.
[12]DALLY W J. Virtualchannel flow control[J]. Parallel and Distributed Systems, 1992, 3(2): 194-205.
