基于社团主题的领域相关推荐算法*
2015-05-29丁艳会郝俊寿李春明
丁艳会, 郝俊寿, 李春明
(1.内蒙古工业大学 信息工程学院,内蒙古 呼和浩特010051;2.内蒙古电子信息职业技术学院 数字媒体与艺术系,内蒙古 呼和浩特010070;3.内蒙古电子信息职业技术学院 教务处,内蒙古 呼和浩特010070;4.内蒙古工业大学 信息工程学院,内蒙古 呼和浩特010051)
随着电子商务的日益发展,大量的商品信息充斥着整个互联网.推荐系统通过分析,过滤用户不感兴趣的商品,并选出用户可能喜欢的商品推荐给用户.通过对用户进行个性化的商品推荐,一些著名的电子商务网站,如Amazon和Netflix,在扩大商品市场和收益上都取得了巨大的成功.
然而,现有的客户评论网站往往都没有用户的兴趣主题信息.最直接的解决方法是计算用户关于该领域的购买次数或鼠标点击次数,但是却忽略了那些只有社会关系而没有交互行为的用户.本文通过为用户社团挖掘出可解释的主题,提出了一种面向领域的推荐算法.首先将用户聚类成不同的社团,然后与预先定义的领域相匹配,最后应用同一领域的用户协同信息进行推荐.
基于模型的协同过滤方法通过机器学习或统计技术对已有的用户进行建模,然后按照该模型对未知的用户行为进行预测[1].常用的用户建模的方法有潜在因子模型[2]、图模型[3]、聚类模型[4]以及贝叶斯模型[5]等.潜在因子模型最重要的方法之一是低秩矩阵分解.低秩矩阵分解[6]仅仅应用部分用户的偏好信息来估计所有用户的特征,并应用这些低秩的潜在因素来估计用户对商品的评价值.从矩阵的完整度角度来看,低秩潜在因子模型在矩阵缺失大量值的情况下可以胜任位置元素的预测.大量的事实表明,矩阵分解模型的预测性能优于协同过滤方法.
协同过滤方法的假设前提是用户之间是独立同分布的,即用户和用户之间不相互影响.然而实际上,用户之间往往存在着千丝万缕的联系,即用户在进行决策时往往受他人的干扰.基于信任敏感的协同过滤方法假设用户之间不是独立同分布的,这种方法基于如下原理:用户在购买商品时往往与社会网络中的那些可信的好友有着相同的品位.本文工作的创新是在推荐系统中应用网络规划主题模型对用户进行聚类,并应用统一聚类中的用户进行预测.
除了社会关系外,其他的关系,如项的分类,也可以用来弥补评价矩阵的稀疏性,并进行评价值的预测.Zhang等[7]对概率矩阵分解进行了扩展,提出了一种多领域下的评价值预测方法.Yang等通过用户评价矩阵和信任关系,将包含多方面信息的信任网络建模成社会矩阵分解的形式.[8]对预测结果进行评价时是对每个领域进行预测,而并不是整个矩阵的性能.
1 推荐算法
1.1 推荐框架与问题定义
本文提出的推荐框架包含3种类型的数据:所有用户之间的社会网络,用户对商品的评价记录和项的分类信息.图1为一个包含兴趣交互和社会网络的异构的网络拓扑结构.本文的目标是通过给定的数据构建领域,挖掘主题社会团体,并进行面向领域的推荐.该框架包含如下两个步骤:
(1)社团主题挖掘.本步骤基于以下三点应用概率主题模型挖掘社团主题.首先,现实生活中每个人都是多方面的.用户兴趣不同仅限于某一个主题,因此离散混合成员模型更适合用户特征描述.其次,例如在Epinions等消费者评论网站中,在每个领域里都有活跃的用户(如图1中较大的节点),这些用户在主题定位时可以为概率模型提供先验知识.最后,概率主题模型允许相似用户通过社会关系相联系,并可以解释他们为什么联系在一起.
(2)领域相关的协同过滤.在提取出主题社团后,根据用户感兴趣的主题将用户分成若干个社团.在每个领域中采用概率矩阵分解方法预测用户的偏好,并根据预测值返回一个有序的列表.

假设推荐系统包含 N 个用户,M 个项,U = {u1,u2,…,uN}为用户的集合,V = {v1,v2,…,vM}为项的集合.用户对项的评价矩阵为R={r1,r2,…,rN}T,其中ri为用户ui对项集V的评价的列向量.同时,ri也可以看作用户ui的特征表示,即用户ui可以用户一系列评价值表示.T= (t1,ti,…,tN),T∈ ℝN×N为用户之间的二值社会信任网络,其中ti表示用户ui信任用户集合U的列向量.该信任网络T是一个有向的网络,将其转化为无向网络后可用邻接矩阵来W表示.
如果领域的个数为K,领域Dk由项的子集Vk和用户的子集Uk组成,其中k=1,…,K,每个领域包含Nk个用户和Mk个项.于是,领域的集合可以表示为D={D1,…,DK}.
如图1所示,假定不同的商品分别属于不同的领域(即商品的分类目录),那么领域的个数取决于商品的分类级别.商品的分类越细,得到的领域越多,反之领域越少.不同领域包含的项的子集之间是不相交的,所有领域的项合起来就是项的集合.在每个领域中,同样包含了对领域中的项进行评价的用户子集,而不同的领域之间可能包含了相同的用户,即用户子集之间有交差,这表明同一用户购买了不同领域中的商品.
给定评价矩阵R,社会信任网络T和项的领域信息Vk={v1,v2,…,vMk},目标是:在第一步,通过挖掘用户子集Uk= {u1,u2,…,uMk}发掘领域信息Dk= (Uk,Vk),k=1,…,K.第二步,对每一个领域Dk,应用用户与项对(ui,vj)对概率矩阵分解模型进行训练,其中ui∈Uk,vj∈Vk.最后,应用经过训练的与领域相关的潜在特征进行预测.
1.2 统一推荐模型
将专家指导的主题模型与网络约束的主题模型进行线性组合,构建成公式(1)所示的统一推荐模型.在该统一推荐模型中,规范化参数λ控制着网络中的主题在两个模型中的分布情况.

通过对专家指导的主题模型和网络约束的主题模型进行整合,得到一个既包含主题一致性又包含链接相干性的联合目标函数.分别将后验概率公式和正则化矩阵公式代入公式(1),可以得到如下的统一推荐模型.

2 实 验
2.1 数据集与评价标准
试验采用了两个带有信任网络的多领域产品评论数据集,Epinions和Ciao.这两个数据集都来自于著名的消费者评论网站,数据集中不仅包含了消费者对商品的评论,还包含了消费者之间的信任关系.数据集的详细信息见表1.图2为两个数据集的度分布图.从图中可以看出,这两个数据集都是稀疏的并且用户关于商品的偏好服从幂率分布.
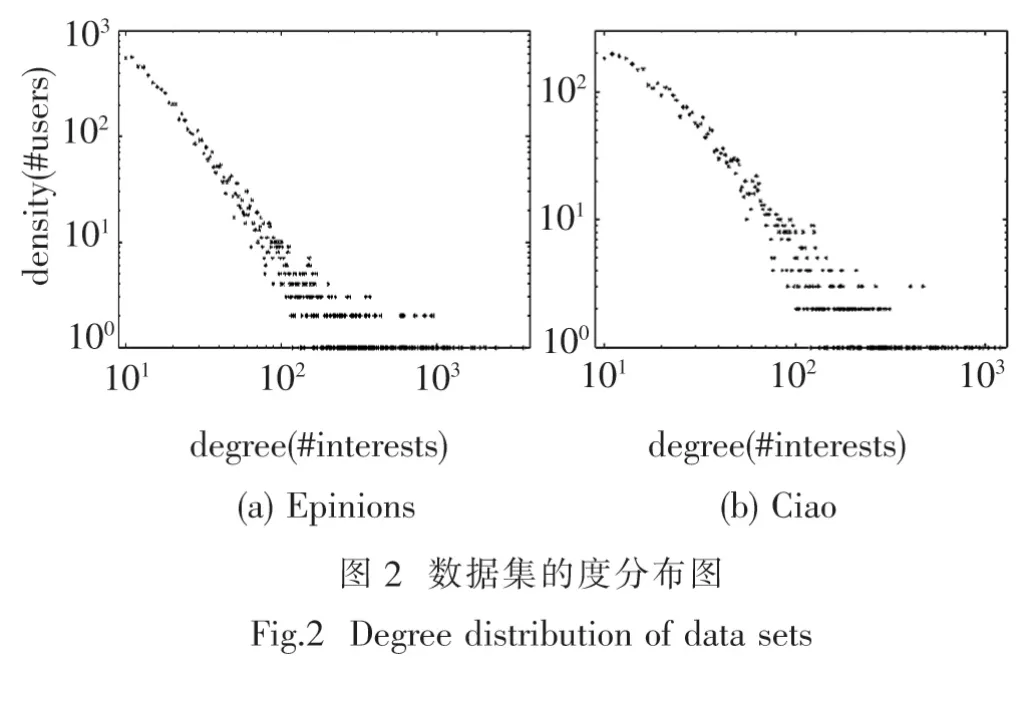
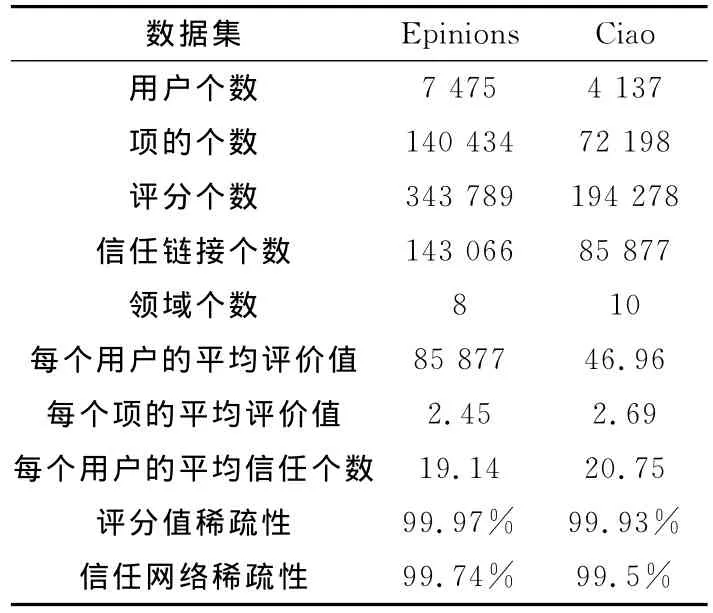
表1 数据集基本信息Tab.1 Basic information of the data set
实验中,两个数据集随机选取了80%的评论数据作为训练数据,并将余下的20%作为测试数据,每组数据测试10次取其平均值.
实验通过对测试结果的top-n项进行分析,从而能评价算法的性能.采用的评价标准分别为MAP(Mean Average Precision),F1值和nDCG(normalized Discounted Cumulative Gain),其定义分别如下.

其中IDCG是通过精确的排名算法得到的排序结果,nDCG对排名靠前的实体赋予更大的信任值.MAP,F1和nDCG越大,得到的推荐结果越好.
2.2 实验结果
在实验中,将本文提出的算法记为TopRec,并将其与概率矩阵分解PMF[12]和随机方法RANDOM进行对比.在概率矩阵分解中,令低秩矩阵特征矩阵的潜在维度为d=10,并且令规范化稀疏为β=0.1.对于TopRec算法,分别考虑算法在单类、多类和网络约束下三种情况.在单类下,TopRec-S算法的聚类标准是:用户ui对zk感兴趣当且仅当所有的zk'都满足f(zk,ui)>f(zk',ui).在多类下,TopRec-M算法认为用户对多个领域感兴趣.在网络约束下,TopRec-Net算法在TopRec-M算法下加入了网络约束,其定义如公式(2)所示.
首先,对比各种算法的性能.表2为各种算法在Epinions和Ciao两个数据集下的性能测试结果对比.实验中,每个算法都令最近邻的个数为5,即n=5.从表中可以看出,TopRec算法在单类下效果比较差,多类情况下效果优于单类下的性能,在多类下如果与网络约束相结合(TopRec-Net)效果最好,并且明显优于其他的四种算法.

表2 实验结果对比(n=5)Tab.2 Comparison of experimental results(n=5)
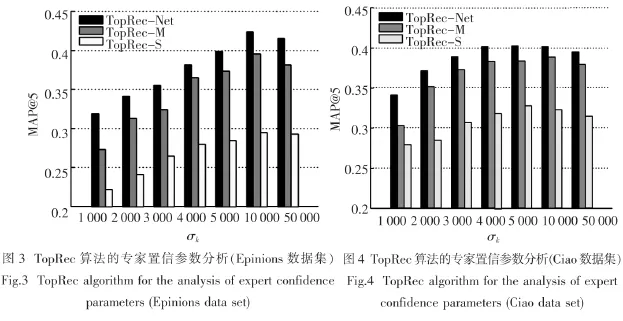
接着,对TopRec算法的三种情况下的专家自信参数σk进行了分析,实验结果如图3和图4所示.在Epinions数据集中,三种算法的MAP@5都随着专家置信参数的增大而增大.然而在Ciao数据集中,三种算法的MAP@5随着专家置信参数的增大先增加,增加到一定程度时再减小.这表明在专家置信参数的选择时置信参数应该选取较大的值.
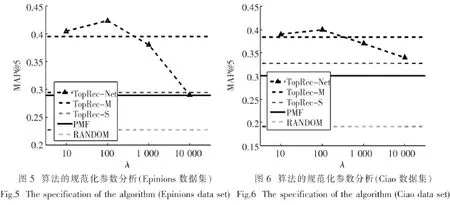
然后,对规范化参数λ的选择进行了分析,结果如图5和图6所示.这里,λ分别取自为10,100,1 000,和10 000.从这两个图中可以看出只有在TopRec-Net算法下,算法的MAP@5随着λ的变化而变化,其他算法的MAP@5都为恒定的值.当λ取很小的值时,TopRec-M和TopRec-Net算法的性能较好.当λ的值增大时,TopRec-M的性能很好,TopRec-Net算法的性能逐渐降低.因此,为了使TopRec算法的性能达到最优,λ的取值不宜过大.
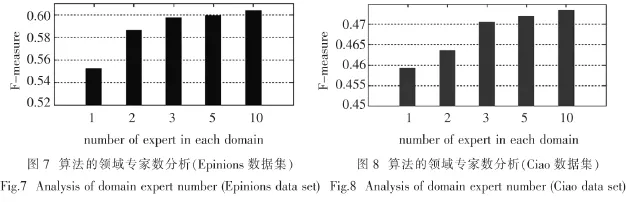
最后,对TopRec-Net算法中每个领域的专家个数进行了分析,实验结果如图7和图8所示.实验应用F-measure对TopRec-Net算法的性能进行评价.从图中可以看出,当每个领域中的专家个数增大时算法的F-measure也随着增大.这表明,在推荐算法的设计中,用户社团中的专家越多,推荐结果的性能越好,这充分表明了专家在推荐时的作用.
3 结 语
在推荐系统中,有效的对用户的兴趣进行分类,并据此向用户推荐他们喜爱的商品是推荐系统的基本问题.本文提出了一种结合了社团挖掘和面向领域的协同过滤推荐框架.首先,在构建用户主题时,通过专家指导的方式,对用户进行聚类;然后,利用社会网络数据将用户划分为不同的主题;最后,将专家指导的主题模型与社会网络约束主题模型结合成统一模型并用于推荐服务.实验表明,在两个真实的带用户信任网络的消费者评论数据集中,本文提出的方法具有较好的预测准确性,其性能明显优于其他相关算法.
[1]许海玲,吴潇,李晓东,等.互联网推荐系统比较研究[J].软件学报,2009,20(2):350-362.
[2]KOOPMAN S J,LUCAS A,MONTEIRO A.The multi-state latent factor intensity model for credit rating transitions[J].Journal of Econometrics,2008,142(1):399-424.
[3]YUAN M,LIN Y.Model selection and estimation in the Gaussian graphical model[J].Biometrika,2007,94(1):19-35.
[4]BANERJEE A,KRUMPELMAN C,GHOSH J,et al.Model-based overlapping clustering[C]//Proceedings of the Eleventh ACM SIGKDD International Conference on Knowledge Discovery in Data Mining.ACM,2005:532-537.
[5]WASSERMAN L.Bayesian model selection and model averaging[J].Journal of Mathematical Psychology,2000,44(1):92-107.
[6]SALAKHUTDINOV R,MNIH A.Probabilistic matrix factorization[J].Neural Information Processing Systems,2007,1(1):2-10.
[7]ZHANG Y,CAO B,YEUNG D Y.Multi-domain collaborative filtering[C]//Proceedings of the Twenty-Sixth Conference on Uncertainty in Artificial Intelligence,2010:725-732.
[8]YANG X,STECK H,LIU Y.Circle-based recommendation in online social networks[C]//Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.ACM,2012:1 267-1 275.
[9]龙际珍,赵欢.基于一种混合算法的分类规则挖掘[J].湘潭大学自然科学学报,2006,28(1):37-41.
