基于相似度的信息颗粒更新方法
2015-05-27聂规划于珊珊刘平峰游怀杰
聂规划,于珊珊,刘平峰,游怀杰
(武汉理工大学电子商务与智能服务研究中心,湖北武汉430070)
互联网信息的爆炸式增长给用户带来了高昂的搜索和浏览成本。整合多源信息,为用户提供简单高效的信息检索方式是一个难题,而解决这个难题的重要方法之一是进行有效的信息融合。通过信息融合可以将具有相似主题的文本聚合在一个信息颗粒下,便于用户检索。目前有关信息融合的研究主要集中在Web 信息融合方面,特别是多源Web 信息检索融合[1]、多源知识融合[2]和面向决策的Web 信息融合等[3],部分学者也进行了多粒度多层次的Web 信息划分与融合的研究。多粒度划分的方法主要包括层次聚类法和模糊粒度计算等。其中刘平峰等[4]结合模糊熵空间理论与现有划分方法,提出了一种基于模糊等价关系的方法。层次聚类法等传统的文本多粒度划分方法多采用全量更新的方式,但在互联网信息海量增长的大背景下,其显然无法满足高效处理信息的需求。目前有部分学者开始研究增量学习算法以解决快速处理信息的问题。古平等[5]提出了一种基于类别上下文特征的层次分类模型及增量学习算法,提升了算法的自适应性和分类精度。王万良等[6]提出了一种稀疏约束下非负矩阵分解的增量学习算法,利用迭代运算提升了大数据处理中降维的时间效率及分解后数据的稀疏性。郭躬德等[7]提出了一个基于KNN 模型的增量学习算法,引进层的概念达到增量学习的效果。赵耀红等[8]提出快速支持向量机增量学习算法,有选择地淘汰学习样本。但以上方法在类别有偏情况下存在算法精确度波动大、应用范围存在局限性、测试时间较长和样本集的选取显著影响增量学习效果等问题,不利于大数据环境下信息颗粒的即时、高效和精准更新。
基于以上研究,笔者采用增量式算法对新加入的文本进行处理。在不对所有信息颗粒进行重构的情况下,仅进行新增文本更新,使信息颗粒树处于动态更新的状态,从而既能自适应学习,又能保持良好的时间特性。
1 基于相似度的信息颗粒更新
1.1 信息颗粒更新流程
当有新文本进入后,对其预处理得到文本空间向量模型。结合原信息颗粒树,得到新文本/信息颗粒树的关键词矩阵。基于余弦相似性算法计算新文本关键词与原信息颗粒关键词的相似度,得到新文本/原信息颗粒的相似关系矩阵。依据相似度是否高于设定的阈值决定是否向上重新选择信息颗粒,把新文本归入最优信息颗粒下,得到新增文本后的信息颗粒树。根据新文本加入给信息颗粒主题带来的变化,更新信息颗粒质心,计算颗粒间的相似度情况并进行颗粒的泛化、剪枝、细化和拆分操作,从而达到更新信息颗粒树的目的。
1.2 文本动态更新方法
每个底层信息颗粒的关键词集合都由其所包含的文本实例计算得出,一旦加入数量足够多的新文本,颗粒的主题就可能随之发生变化。为了使整棵信息颗粒树保持人类认知变化规律,首先需要将新文本归入合适的颗粒中,其次判断信息颗粒的主题是否发生变化而需要更新,最后进行相应的调整。而将新文本归入信息颗粒同样需要经过3 个步骤,即文本预处理、关键词相似度计算和插入新文本。
1.2.1 文本预处理
文本预处理的目的在于确定代表新文本的关键词集合,主要操作包括词语分解和TF -IDF 计算。通过使用现代汉语通用分词系统(GPWS)对新文本进行词语分解和词频统计,并对分解出来的词语进行过滤。在过滤非关键词后,再通过TF -IDF 计算进一步筛选。给定文本集d= {d1,d2,…,dn},以及出现的关键词t={t1,t2,…,tm},通过TF -IDF 计算一个词语在一篇文档中的重要性,考虑不同文本长度对权重值的影响,对TF -IDF 的结果进行归一化[9],其计算公式如下:
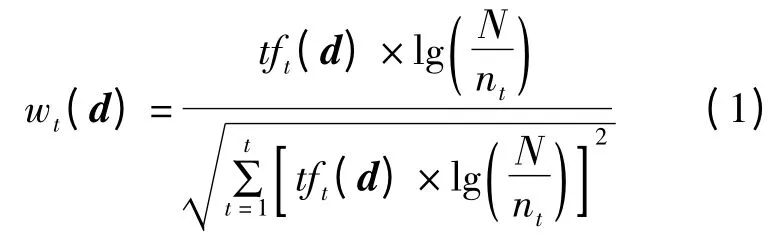
关键词频tft(d)为关键词t在文本d中出现的频率,逆向文件频率IDF=lg(N/nt),其中N为论域中文本总数;nt为出现关键词t的文本数。
利用向量空间模型(VSM)对文本进行表示,把每一个文本d当作空间内的一个向量或空间点,表示为V(di)= (wi1,wi2,…,wip),其中wip为文本di第p个关键词在文本向量中的权重值,p为关键词的个数,即文本空间维数。
1.2.2 关键词相似度计算
建立新文本/信息颗粒-关键词矩阵。假设新增n个文本,原信息颗粒树中含m个底层信息颗粒,每条记录分别为新文本及底层信息颗粒的各关键词权重值。已知第i条记录为V(di)=(wi1,wi2,…,wip),采用余弦相似性算法,依次计算新文本与各信息颗粒向量的相似性,其中i∈[1,n],j∈[n+1,n+m],计算公式为:
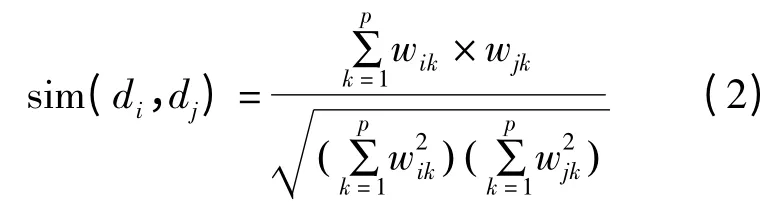
可将新文本与信息颗粒向量的相似关系写成关系矩阵,如式(3)所示:

其中,Sij=sim(di,dj),关系矩阵的第i行表示第i个新文本与每个底层信息颗粒的相似度。
1.2.3 插入新文本
计算关键词相似度,若新文本与某底层信息颗粒的关键词语义相似度最高,且高于预设的相似度阈值,系统则将新文本归并到该信息颗粒下;若小于阈值,则向上逐层选择信息颗粒,将新文本归入最优信息颗粒下,同时记录下更新文本实例后信息颗粒的关键词变化情况,包括关键词词频、出现该关键词的文本数等数据。
1.3 信息颗粒更新方法
加入新文本后,信息颗粒主题会发生一定变化,需要进行有效的更新。CALEGARI 等[10]在研究应用于本体的粒计算时提出4 种粒操作,即泛化、剪枝、细化和拆分。笔者的研究同样涉及对信息颗粒进行更新的4 种操作。
(1)泛化。信息颗粒是一个包含多个关键词的集合。随着信息颗粒下的文档数量逐渐增多,部分主题相近的信息颗粒所包含的文本内容趋于相似,导致类间距离减小,分类不明确。而泛化操作则是将一系列颗粒合并成一个更具概括性的信息颗粒,以降低颗粒间的分类模糊性。
(2)剪枝。当一个信息颗粒与其子信息颗粒具有过于类似的关键词集合,或者子信息颗粒下的文本数较少,自成一类的意义不大时,就需要对信息颗粒树进行剪枝操作,即将子颗粒删减,并把子颗粒下的文本升级为母颗粒的文本实例。
(3)细化。当一个信息颗粒下所包含的文本数量较多时,可能会出现类内文本主题分散、分类不统一的问题,需要对该信息颗粒进行细化,分解成更具体的不同主题。而细化操作则是为信息颗粒添加若干子颗粒,并根据文本主题的契合度将相应文本进行重新组织。
(4)拆分。拆分操作与细化操作的区别在于:①原信息颗粒在细化后依然存在,而拆分则是添加新的颗粒来替代原信息颗粒;②拆分操作无法对直接包含文档的信息颗粒进行操作。
2 实验及结果分析
2.1 实验准备与性能评价指标
从复旦文本分类语库中选取200 篇有关计算机方面的文本,另外选取20 篇进行划分新增文本的实验。并将笔者提出的更新方法与层次聚类方法进行性能对比分析。性能评价考虑底层信息颗粒的类内距离和类间距离,其公式为:
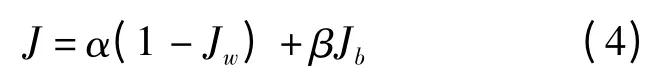
式中:α 和β 分别为类内距离和类间距离的加权因子,视两者的重要性而变化,但保持α+β =1,取α=β=0.5;Jw和Jb分别为信息颗粒的类内距离和类间距离。
类内距离Jw是每个信息颗粒内文本的权向量与质心平均距离的归一化表示,其公式为:

式中,Xi为信息颗粒j中第i个文本的权向量;为质心;nj为颗粒内的文本数量;k为底层信息颗粒的总数。
类间距离Jb是每个信息颗粒与其他信息颗粒质心的距离,其公式为:

信息颗粒j质心的计算公式为:
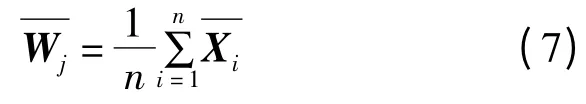
其中,n为颗粒j中文本的个数。
2.2 更新算例
按照笔者方法,在完成新文本的插入更新后,对插入新文本后的信息颗粒的质心进行更新,计算新信息颗粒的类内距离和类间距离。经过泛化、剪枝、细化和拆分更新颗粒质心后,得到新信息颗粒树,计算机领域新信息颗粒树如图1 所示。
通过计算新信息颗粒树中各信息颗粒的类内距离和类间距离,得出笔者提出的信息颗粒更新方法与重新进行层次聚类方法相应性能指标J 的对比结果,如图2 所示。
图2 显示,笔者提出的方法和层次聚类法在聚类数较少时就达到了较好的聚类性能。随着各层聚类数的增加,用笔者方法构建的新信息颗粒树聚类性能高于层次聚类法,能够更好地表述领域信息颗粒树主题。
此外,由于笔者采用的是动态插入新文本、增量更新信息颗粒树的方式,相对于全量更新的层次聚类法,效率更高。两种方法的效率对比情况如图3 所示。
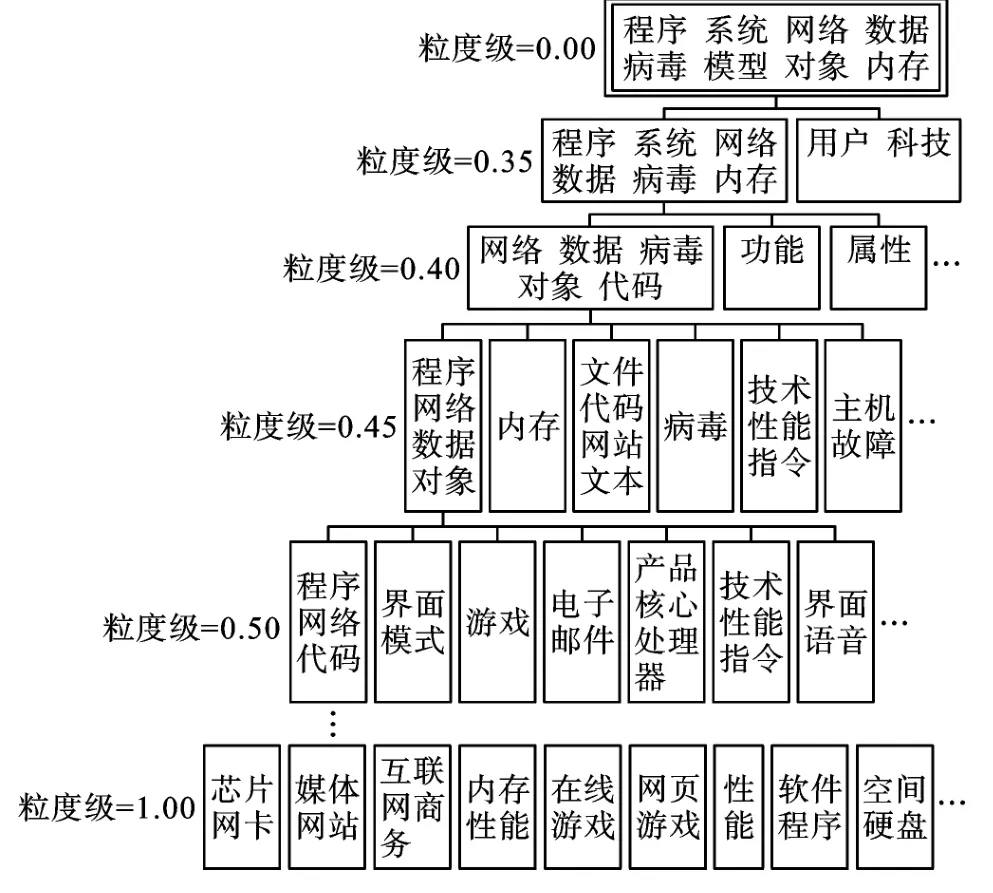
图1 计算机领域新信息颗粒树
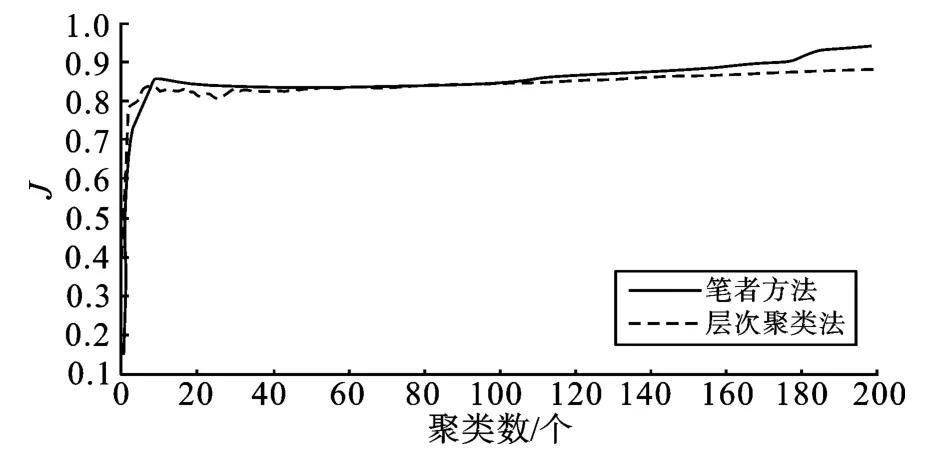
图2 聚类结果对比图
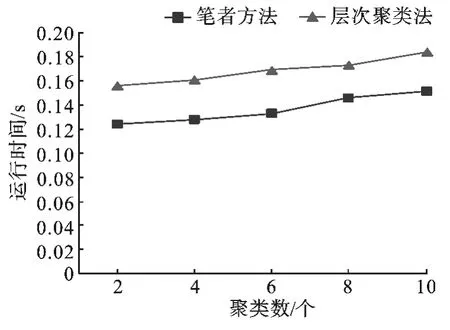
图3 运行时间对比图
3 结论
大部分文本粒度研究都只为获得领域信息颗粒树,忽视了由于增量更新文本而引起的信息颗粒树的变化。笔者在以往信息颗粒树生成研究的基础上,探索了新文本的插入更新及新文本加入后信息颗粒树的4 种更新机制,并进行了验证。不足之处在于未能给出用于判断执行何种更新机制及其阈值设置依据。另外,由于各文本权向量与信息颗粒质心的长度由关键词集合的大小而定,关键词集合大小的设定也需要在未来的研究中进一步探讨。
综上所述,信息颗粒更新方法无论是在性能还是在效率方面,都显著优于层次聚类法,信息颗粒更新方法能有效表达动态更新的信息颗粒树主题,提高了更新效率。
[1]KEYHANIPOUR A H,MOSHIRI B,KAZEMIAN M,et al. Aggregation of web search engines based on users' preferences in WebFusion[J]. Knowledge -based Systems,2007,20(4):321 -328.
[2]周芳,王鹏波,韩立岩.多源知识融合处理算法[J].北京航空航天大学学报,2013(1):23 -27.
[3]YU L A.Web warehouse:a new web information fusion tool for web mining[J].Information Fusion,2008(9):501 -511.
[4]刘平峰,余文艳,游怀杰.基于模糊等价关系的文本多粒度划分方法[J].情报学报,2012,31(6):589-594.
[5]古平,罗志恒,欧阳源遊.基于增量模式的文档层次分类研究[J].计算机工程,2014,40(1):209 -212.
[6]王万良,蔡竞. 稀疏约束下非负矩阵分解的增量学习算法[J].计算机科学,2014,41(8):241 -244.
[7]郭躬德,黄杰,陈黎飞.基于KNN 模型的增量学习算法[J].模式识别与人工智能,2010,23(5):701-707.
[8]赵耀红,王快妮,钟萍,等.快速支持向量机增量学习算法[J].计算机工程与设计,2010 (1):161-163.
[9]张霞,尹怡欣. 基于模糊粒度计算的文本聚类研究[J].计算机工程与应用,2010,46(13):53 -55.
[10]CALEGARI S,CIUCCI D. Granular computing applied to ontologies[J]. International Journal of Approximate Reasoning,2010,51(4):391 -409.
