用于电力大数据快速组合查询的 动态索引技术
2015-05-25栾开宁郑海雁李昆明
栾开宁 郑海雁 丁 陈 李昆明
(1.江苏省电力公司,南京 210024; 2.江苏方天电力技术有限公司,南京 211102; 3.上海晟淘大数据科技有限公司,上海 200433)
随着电力系统数字化进程的推进,电力系统积累了大量的发、输、用电数据。目前仅江苏省用电信息系统历年保存下来的全省用电信息数据已达到几十TB,如何利用现有的大数据分析技术,挖掘电力大数据的潜在价值,使电力企业为客户提供更好的服务,是一个值得研究的课题。而2013年《中国电力大数据发展白皮书》[1]的发布,将中国的电力大数据研究推向了一个新的起点,对中国电力大数据的研究与应用有着划时代的意义。
目前比较常见的大数据解决方案为 Hadoop+ HBase[2],该解决方案通过搭建分布式处理软件框架和分布式存储系统[3-4],实现大数据的分布式存储和查询。HBase 是按Rowkey 进行排序和存储的,在进行数据查询时需要对数据块按行检索,查询速度远无法满足实时的需求。
本文提出采用动态索引图(Dnamic Index Graph,DIG)技术建立电力大数据的索引,实现多条件列索引的建立和快速组合查询,它通过建立索引图为每个查询专门创建复合索引,避免了全表逐行扫描,大大提升了查询的速度。
1 用电大数据的特征
文献[1]指出电力大数据其特征可概括为3“V”3“E”,3“V”代表体量大(Volume),类型多(Variety)和速度快(Velocity),3“E”代表数据即能量(Energy)、数据即交互(Exchange)、数据即共情(Empathy)。在用电大数据中,这样的概括同样适用。
体量大。目前为止江苏省用电采集系统投入运行140 余万台采集终端,120 余万集抄终端,覆盖3400 余万用户。仅上采集一项日产生数据量达30多GB,自2006年以来,积累下来的数据已达40TB之多。在构建基于气象因素的用电影响因素模型时,经多轮次数据验证、调整、重算,生成江苏省13 个地市8000 多类,300 多万条模型数据,预计未来各模型反映的总电量影响关系将超过2 亿条。
类型多。从数据本身结构来看,用电数据类型包括结构化数据、半结构化数据和非结构化数据。从业务角度来看,用电数据涉及不同用户群体、不同行业领域、不同电气指标等。未来,当所有的大中型家用电器都装有电量传感器之后,用电数据类型将得到极大地扩展,也更加便于电力企业分析和研究用户的用电结构,为用户提出更加合理的用电建议。
速度快。在采集端,目前3400 余万居民用户每日取一次电量数据、20 余万企业用户每15min 取一次电量数据,在未来将要求所有用户15min、1min,甚至1s 取一次电量数据,这无疑对现有的通信系统传输速度、采集终端处理能力发起了极大地挑战。在客户端,电力公司要求实时处理大量产生的用电数据,实时优化控制用电设备的启停;居民用户要求实时查询用电量情况和家用电器用电比例,企业用户要求实时查询用电量情况和生产设备的运行情况。
2 大数据创建索引和快速查询面临的挑战
2.1 大数据快速查询存在的问题
一直以来,快速查询是数据库最核心的技术之一。数据库一般存放的数据比较复杂,一个查询往往需要将多个数据表相关联,甚至需要跨库数据的关联,导致查询性能急剧下降,即使在一个不是非常大的数据库(千万级)执行一次查询可能需要几个小时,乃至几天。
大数据带来了诸多数据库核心技术的突破。大数据的核心理念是“分布处理”,通过普通计算机横向扩展,多台设备协同工作,把耗时的计算分布在多台设备上并行处理,从而获得高性能。值得一提的是,大数据不仅仅通过“分布处理”获得高性能,另一个非常重要的核心理念是“普通计算机”,通过大量低廉的计算机实现低成本、高性能。因为技术能力从某种程度上获得了“无限”的提升,算法在某种意义上“失效”了:即通过大量快速计算,不同算法之间的差异趋于无限小。
但同时,在大数据快速查询方面,主要问题是过度依赖大数据带来的计算能力而放弃方法上的努力。如当前市场上最火热的基于Hadoop 的大数据系列产品,都是通过大量廉价机器堆积来获得性能的保证。在大数据起步阶段,这样做可以获得相当不错的数据处理效率的提升。然而,数据量往往不是线性增长的,而是呈指数形式的快速增长,但是硬件性能和数量却是以线性方式在增长。这样随着时间的发展,数据量与硬件的矛盾在不远的将来会再次成为大数据处理的瓶颈。
表1列出了基于Hadoop 的大数据快速查询产品。
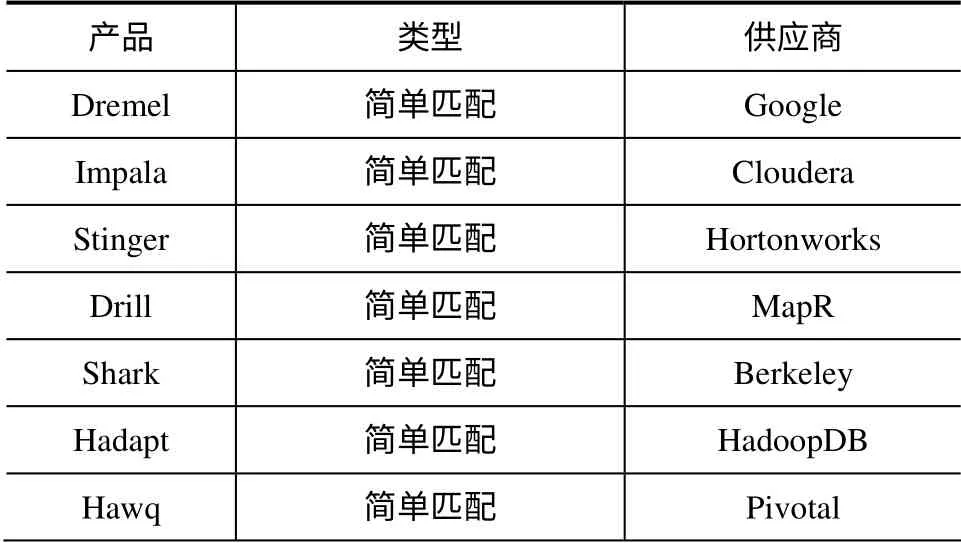
表1 基于Hadoop 的大数据产品
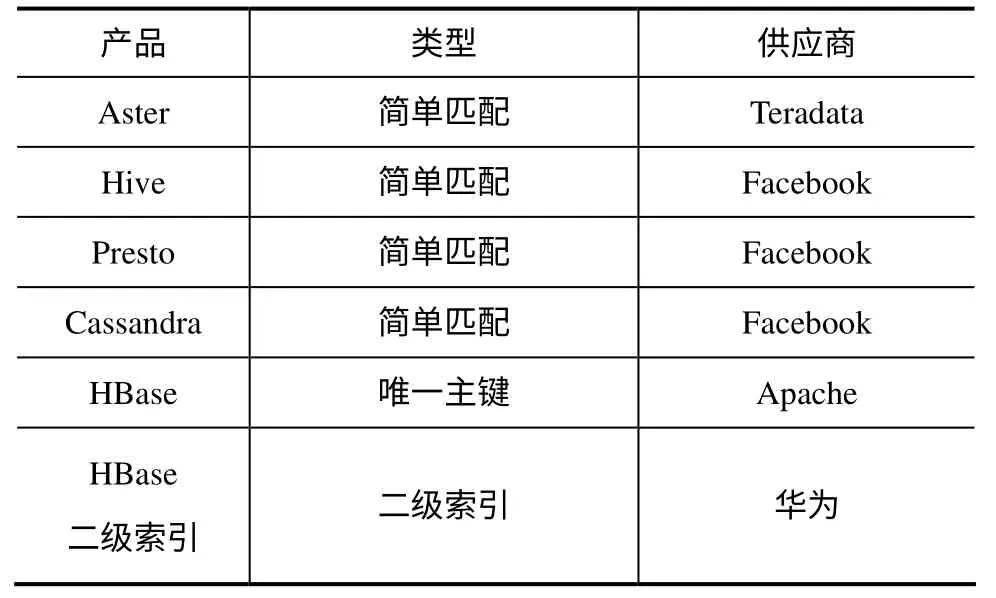
(续)
不难看出,绝大部分大数据快速查询产品都放弃使用索引,HBase 也仅仅是一张表支持一个索引。华为在HBTC 2012 上公布了其二级索引方案,在业界引起了强烈的反响,它通过二级索引采用B 树和R 树互相补充的方式,可以通过维度信息范围快速定位到子节点上的索引,有效提升大数据查询速度。
2.2 大数据创建索引面临的挑战
大数据创建索引虽然重要,然而其难度也是同样大幅提高的。
1)创建索引成本极高,尤其是数据量越来越大时,维护索引的成本越来越高,导致系统整体性能急剧下降。
2)磁盘读写速度限制。计算机技术飞速发展,尤其是计算机CPU 速度及内存容量,但是磁盘的读写速度却一直没有本质性的突破。创建索引需要大量修改数据,极大地增加对磁盘IO 压力。更为严重的是这些修改可能都是海量的“小数据”修改,需要频繁地对存储有海量数据的磁盘进行重复性的IO 操作。
3)Hadoop 本身不支持数据修改,但维护索引需要修改数据,这是令Hadoop 上的几乎所有快速查询软件都不使用索引的另一主要原因。
3 大数据高效索引与快速组合查询技术
3.1 大数据快速查询理念
在数据量急剧扩展的同时,随着商业智能分析的深入,各种查询分析的逻辑也越来越复杂。这两个因素是当前传统数据面对查询越来越力不从心的根本原因。
如今大数据技术方兴未艾,查询效率无疑是大数据领域重要的一环。如前文所述,传统数据近年来为了提升查询效率也已经做了很多工作,但它们更多的还是依赖于更快的计算速度,优化的查询逻辑等。面对过快的数据量和查询逻辑级数的增长,大数据技术针对这一问题则具备了它独特的理念。
1)通过底层处理逻辑的优化,而非仅仅查询处理层面的逻辑优化。通常查询者的查询逻辑是客观存在的,在这上面去做优化要做到既保证质量又保证性能,对查询者的专业技能要求太高。DIG 则是从数据最底层的处理逻辑上来实现查询性能的根本性改变。
2)通过预处理来减少用户的等待时间。当数据库表数量众多,而用户进行复杂逻辑的SQL 查询时,即使只有几百万的数据,传统方法下一个查询也许需要用户等待几十分钟,甚至几个小时。大数据的核心理念之一便是尽可能的使用预处理,而减少用户查询时实时数据处理的工作量。DIG 技术的核心思想也正是如此,尽可能地在数据进入数据库时即自动创建索引。通过底层核心技术,在用户进行复杂多条件查询时,动态地将各个数据表上的索引文件智能组合,快速响应用户的查询请求。
3.2 大数据的高效索引技术
大数据基础之上创建高效索引虽然非常之难,但显而易见的是,大数据对索引的需求相比传统数据库更加迫切:传统数据库在几十万、几百万数据量的情况下需要使用索引才能提供满足要求的查询性能,那么专注于处理动辄几百亿、几千亿数据量的大数据技术如果不提供索引又如何能满足性能需求呢?
传统数据库的索引其实都是一种单索引结构,虽然很多基于Hadoop 的大数据产品可以支持复合索引,然而这种复合索引其本质依然是单索引,即一次查询只能用一个索引,所谓复合索引也只是将多个字段简单拼接。单索引的效率可以满足用户单条件的查询,而传统的复合索引由于其拼接的技术过于简单,因此也只能支持单一的查询,如果用户的查询条件更复杂、条件组合更灵活时,它就完全不能满足用户的需求了。
为了解决大数据查询的效率问题,同时避免传统复合索引技术的带来的局限性,本文提出了一种适用于用电大数据的复合索引技术——动态索引图技术。
DIG 技术是一种基于分布式存储,分布式计算的索引架构,它对数据建立了一套立体的索引系统。这套索引系统首先利用第一个域进行排序,建立若干索引起始点,使用hash 技术将索引分段,由第一个域的这些起始点指向下一个域的分段,以此类推,构建一个多级立体式的索引分段系统。当某一分段较疏松时,适当合并减少分段数,当某一分段较密集时,适当分离多建立分段,以达到分段的存储读取效率与查询效率之间的平衡。当一个查询开始时,由一个或多个起始点开始,根据约束条件进行递归查询。最终确定终结点的查询内容。
DIG 充分利用了云设备的缓存调度,多核计算,将孤立创建的索引连接成索引系统,如图1所示。
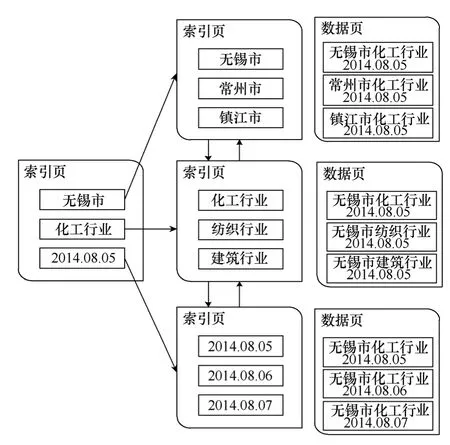
图1 DIG 示意图
当用户执行查询任务时,系统将智能的甄别查询类型,查询规模,自动选取最优的查询算法。在立体的索引系统中,利用选择的最优算法规避逐条搜索,充分使用系统预处理产生的多级索引及索引间的关联索引,索引内预判预读,多线程并行处理。最终达到大幅提高查询速度的效果。
由于在普通规模数据系统中的大多数查询是能够在秒级时间单位中完成,而这些操作对于海量数据往往就会上升成为分钟级,小时级的操作,DIG技术将查询海量数据时的大量应用从耗时若干分钟,加速至只需若干秒,从而把系统的响应时间压缩到用户等待的心理承受范围之内。
以四台设备,40 亿条数据为例,假设每条数据有五个字段,每个字段10 个字节定长。其全表内容约为200GB,每台设备处理50GB 数据,以每分钟处理3GB 的硬盘上限处理能力计算,一次查询需要15min 以上。首页查询较优条件下也在5min 以上。而使用DIG 技术后首页查询时间会缩短至10~20s,从而使查询时间落入用户等待的心理承受范围内。
3.3 大数据快速组合查询的设计
索引对于传统数据库只是一个辅助手段,若用户使用了一个查询组合,但是这个查询组合并未建立索引,临时采用全表扫描技术进行查询也是可接受的一个解决方案。
但当分配到每台普通计算机的数据量大到一定程度时,逐行扫描技术已经完全无法满足系统的性能需求时,大数据下的高效索引则不仅仅是查询加速的辅助,而是查询的必要条件。因此,大数据快速组合查询的设计必须满足速度和通用性两个要求。
为满足快速组合查询的速度要求,从以下两个方面进行查询效率提升:
1)从最底层的数据存储层上,利用大数据虚拟文件系统实现高性能大数据存储,为大数据快速查询提供了良好的基础。
2)使用多维数据库为数据提供最优化的处理方式。
从通用性的角度来看,由于大数据查询对索引的要求不再仅仅局限于为查询提供一种加速的辅助功能,而是所有查询必须要使用的技术,因此,大数据技术下的索引技术必须能够为任意多条件的所有可能组合用的。
DIG 技术创建的索引用户不必去考虑任意多条件的组合的可能性数量,只需要对可能用到的查询条件对应的字段创建索引即可。当用户使用由这些条件组成的条件组合进行数据查询时,数据库引擎会依据自身的独有机制动态使用这些原本独立创建索引提供任意组合的多条件的数据查询。
若使用没有创建索引的字段与其他已经创建了索引的字段进行组合查询,系统首先智能地去判断,发现其中的几个字段已有索引,将优先使用这几个字段初步判断与过滤,得到一组中间查询结果;由于另外的一些字段并未建立索引,因此需要再对中间结果数据进行逐条扫描。因为已经使用已有索引的几个字段进行了过滤,因此进行中间结果的逐条比对时,数据集的规模已经得到大幅降低。因此,即使偶尔使用了极少数没有提前创建索引的字段进行查询,在本文的查询引擎下,也可以提供相当不错的查询效率。
4 电力大数据快速组合查询方案设计
随着智能电表的普及,电力行业的数据量呈井喷式增长。电力行业是当前将终端普及到千家万户每一个角落的少有的几个行业之一(类似的还有水、煤气等行业)。
电力数据具有格式化、数据量大、周期性明显等特征。以江苏电力为例,如果每个小时采集一次数据,则一个小时就会产生三千万量级的数据,这个数据量还会随着数据采集频率的提升和用电单位数量的增长呈指数增长。
面对周期性产生的海量数据,大数据领域较为先进的HBase 作为大数据存储与处理的基本平台。HBase 虽然也提供了相对不错的大数据处理能力,但它依然不能提供任意多条件查询的索引技术。
由于HBase 是按列存储的,并支持列族概念,对一个表做一个固定条件的查询时效率很高;但一般查询时往往需要进行多个条件的组合查询,而HBase 并不支持多个条件的组合查询。因此结合HBase 的自身特性,引入DIG 技术以提高组合查询的效率是非常必要的。
用户通过 java 数据库连接(Java data base connectivity,JDBC)与HBase 实现数据库的互通,并实时完成统计预处理和建立查询索引。具体做法如下:
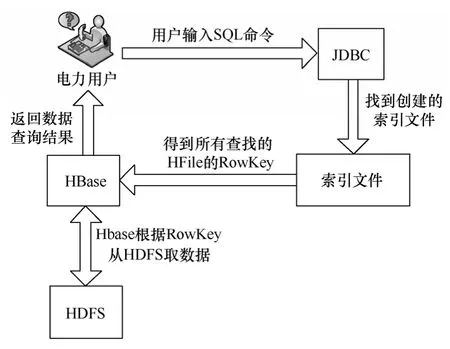
图2 电力用户数据查询流程
1)当HBASE 读入新增数据时,所有数据同步被送到指定的查询加速服务器,按指定关键字和日期对某个字段进行数值的统计,并建立查询 索引。
2)当用户向HBASE 发出查询请求时,该请求 被即时送到特制的查询引擎,根据查询条件返回对应的索引地址,通过索引地址找到原始数据,并返回结果。
基于DIG 技术的查询,无论数据总量多少,查询的速度要求少于5 秒。通过本方案实现了无需改变HBase 的任何配置,同时无需任何编程,即可在海量大数据的压力下实现统计和查询的秒级 响应。
5 结论
通过Jimo 系统的DIG 技术的引入,理论上可以实现无论数据量有多大,都可以提供任意多条件的秒级的查询与统计分析。鉴于数据处理性能的保证,电力系统大数据项目中能实现提供的数据分析 处理的视野也将更加广阔,不会再有数据分析功能因为数据处理性能的低下而变得无法实现,电力大数据的前景将不再受制于数据处理性能。
[1] 中国电力大数据发展白皮书[Z].北京: 中国电机工程学会信息化专委会,2013.
[2] Taylor R C.An overview of the Hadoop/Mapreduce/ HBase-framework and its current applications in bioinformatics[C].// Proceedings of the 11th Annual Bioinformatics Open Source Conference,2010.
[3] Tome White.Hadoop 权威指南[M].2 版.北京:清华大学出版社,2011.
[4] Lars George.HBase 权威指南[M].北京: 人民邮电出版社,2013.
