基于谷歌距离的汉英词表概念映射研究
2015-05-25张李义崔恒
张李义 崔恒
(武汉大学信息管理学院,湖北武汉430072)
·理论探索·
基于谷歌距离的汉英词表概念映射研究
张李义 崔恒
(武汉大学信息管理学院,湖北武汉430072)
本文对《汉语主题词表》(工程技术版)概念与英文超级科技词表概念的映射进行研究,建立优化的汉对英有序映射模式,并采用基于谷歌距离的语义相似度算法进行实验,计算英文词之间的语义距离,导入原有汉英映射信息。通过实验分析,获得了按相似度排序的汉英映射模式,实现了多个英文词汇与汉词的对应并由高到低排列出来。该方法获得的排序结果基本满足要求,部分词语需要人工修正。
语义相似度;汉语主题词表;谷歌距离;概念映射
词表映射研究是研究和建设跨语言信息检索(Cross Language Information Retrieval,CLIR)的基础,本文的目标是通过计算映射词语的相同程度来解决跨语言搜索结果的有序排列问题,其关键在于获取语义距离和改进现在的映射规则。研究双语言或多语言的CLIR是一个热门的话题,《汉语主题词表》(工程技术版)(以下简称《汉表》)与英文超级科技词表分别用于进行中外文科技文献的知识组织,而两者的相互映射正是为了实现对中外文文献资源的跨语言检索;考虑到两个词表知识体系的差异和语义映射的复杂性,本文不进行知识概念体系、词间关系和范畴体系等方面的语义映射,主要研究基于概念的映射模型和方法。
本文以《汉表》的概念作为源(Source)概念,英文超级科技词表的概念作为目标(Target)概念,参考并修订W3C的词表映射规则,建立映射模型。《汉表》概念具有上下位、多层次关系,英文超级科技词表概念也是网状关系,在建立概念间映射关系时,只在距离最短、关系最近的概念间建立关系,没有必要将等同的概念重复给定向上或向下匹配的关系,按照需要,将词表的原词间关系导入映射信息即可确定新的映射关系。本文以标准谷歌距离[1](Normalized Google Distance)作为语义距离的基本计算方法,并设计了映射流程,在已有汉英词表的基础上,对映射进行排序,能有效地解决检索时汉英词语的匹配问题。在检索过程中,可以做到按相似度的高低呈现有序的检索结果,从而给用户更优的检索体验。本文通过程序进行演算获取实验结果,根据语义相似度进行排序,建立新的有序映射。
1 相关研究工作
自然语言的词语之间有着复杂的关系。在实际的应用中,语义相似度能把这种复杂的关系用一种简单的数量来度量。为了使映射关系更加有序,本文以语义相似度为依据,整理相关词语与核心词语的语义距离。国外的DekangLin[2],Batet M[3],Rudi Cilibrasi[1]等都给出了比较合理的语义相似度计算公式和方法;国内这方面起步较晚,但发展很快,詹志建[4]、杨美荣[5]、王磊[6]、杨春龙[7]等做了很多补充性和改进性的工作。其中基于词形的字面相似度计算[8]、基于语义词典的语义相似度算[9]、基于结构的相关度计算[10]和基于语料共现的相关度[11]等方法最为常用。发展到现在,语义距离主要有两类常见的计算方法,一种是根据某种本体知识(ontology)或分类体系(Taxonomy)来计算;另一种利用大规模的语料库进行统计。前一种主要基于客观计算,采用树论、图论的方法能有效计算出字面上不相似的词语之前的相似度,但局限性是受人的主观影响比较大;第二种则是依赖大规模语料库的经验计算方法,能够客观地反映词语的形态、句法、语义、标签等多重属性,计算机自然语言处理专家Rudi Cilibrasi、Paul[1]提出了语义相似度计算方法NGD是该类计算方法的典范。语义网(Semantic Web)是当前互联网的延伸,并且可以作为基于语料共现方法的资料库。语义网的实现需要三大关键技术的支持:XML、RDF和Ontology。目前语义网关键技术的讨论大多集中在RDF和Ontology上,本文属于RDF的研究范畴。
要建立词表映射模型,叙词表的形式化研究及其如何发挥叙词表中语义网的作用成为当前叙词表研究的关键问题。常春[12]建立农业的跨语言检索模型便是基于W3C于2005年发布的简单知识组织系统(Simple Knowledge Organization System,SKOS)。SKOS支持RDF框架,并强调为知识组织系统的表达提供强有力且简单的机器理解方式。SKOS映射的来源是来自源叙词表中的单一概念,目标是来自目标叙词表中单一概念或者概念组合。映射用以解释源概念与目标概念的术语集合之间的关系,该模式由一系列映射属性集合构成,其中近义匹配包括MajorMatch(主近义词)或者MinorMatch(次近义词)。由于相近程度量化的难度较大,具体操作中不对MajorMatch和MinorMatch两条规则进行区分,只定义为一种近义匹配。在当前的W3C的映射规则中,对近似程度没有进行有效的区分。本文希望用语义距离来描述这种近似程度。本文采用文献[1]和文献[16]中的NGD及mNGD算法进行计算排序。语义距离和语义相似度是一对词语的相同关系的不同表现形式,语义距离越短代表相似度越大。如今,Internet飞速发展,语料库不断完善,也部分解决了由于语料库规模问题引起的数据稀疏问题。Google作为实践语义网的先驱,在其搜索引擎中已经实现了部分语义网,如在搜索过程中通过高级搜索和打标签的方式获得垂直搜索的结果。国内的艾冬梅[13]、杨慧荣[14]等人已经在语义距离及相关的研究中使用NGD算法。
2 中英词表映射流程设计与算法选择
2.1 中英词表映射流程设计
以汉语词语进行跨语言的信息检索,需要对该词语进行匹配转化,在数字化和预处理之后的排序面临多种情况。流程的核心为映射过程中的排序问题:
(1)当一对一的词表映射,检索时中文词语直接转化为英语词;
(2)存在一对多的词表映射情况时,可以首先依据专家判定,给出与中文词表中某词语语义最相关的一个英语词汇,然后将剩下的待匹配词汇同该词汇进行语义相似度计算,并依据与其语义相似度的高低进行排序。例如中文词表中“安全标准”,依据专家判定与其语义最相关的英文词汇为“safety standard”,对于剩下的带匹配英文词汇,依次与“safety standard”进行语义相似度计算,并按相似度的高低进行排序。语义相似度的计算采用基于谷歌距离的语义相似度算法。如图1所示,建立汉英词表的映射流程用来完成映射选取与结果输出。

图1 汉英词表映射流程
为了验证映射流程的效果,作者使用JAVA语言编写了简易的系统程序用来进行实验。该系统功能为:由领域专家设定与中文某词汇语义最相关的英文词汇后,获取并自动导入词表信息;采用谷歌语义距离进行英语语义相似度的算法,自动计算剩下词汇与该词汇的语义相似度并将信息导入进汉英词表,生成新的映射词表;将词表中的词语按相似度高低依次排序,最终输出映射结果。
2.2 中英词表映射流程算法选择
万维网存在着数以百万计的用户和海量的文本语料,谷歌2009年公布的数据显示其索引页面已经超过80亿,经常出现一个常用词的搜索词会出现在数以百万计的网页中,因此Rudi以实际语言学的研究为依据,提出Google Similarity Distance概念,计算语义相似度[1]。该方法理论基础涉及信息论、压缩原理、柯尔莫哥洛夫复杂性、语义WEB、语义学等,基本思想是把Internet作为一个大型的语料库,以Google(对其它的搜索引擎如百度同样适用)作为搜索引擎,搜索返回的结果数作为计算的数值依据,其计算公式[1]如(1)所示。

其中,NGD表示标准谷歌距离,以此衡量语义相似性大小f(x),f(y)分别表示包含词语x,y的网页数,f(x,y)表示同时含有概念的网页数,其中M可以是任何有理论依据的参数,一般用M表示Google引用的互联网上的网页总数。在本文中x有一定的特殊性,表示领域专家选定的最适映射词primary word,而y则表示需要与y相比较的其他可映射词。当两个词语的NGD为0时,一般是同一词语与自身比较;当两个词语的NGD接近0时,表示两个词语几乎完全相同,语义相似性极高;当两个词语的NGD为infinity时,表示两个词语从未同时出现过,几乎没有什么相似性;NGD越靠近0,表示两个词语的语义相似性越高。
可以以一次实验来说明,假设用Google搜索词语“horse”返回46 700 000(记为f(x))条结果,搜索词语“rider”返回结果数为12 200 000(记为f(y)),搜索同时含“horse,rider”的网页数量是2 630 000(记为f(x,y)),当时Google共引用的网页数SM=8 058 044 651,代入上述公式求得:NGD(horse,rider)≈0.443。
随着M的变化,得到的语义距离也会发生小范围的变化。Risto Gligorov与Zharko Aleksovski[15]利用谷歌相似度研究近似本体的匹配问题时,根据相关词语的从属特性简化了公式,使得M这个不断变化的参数不再影响结果,在汉英词表中也能实现部分适合条件词汇的简化计算,采用文献[16]研究本体匹配的公式(4)、(6)、(7)等。得到mNGD[16]公式:
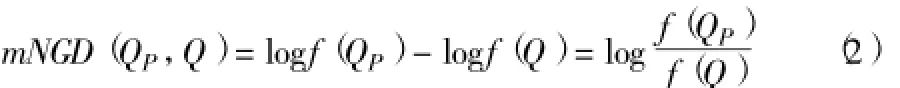
mNGD[16]即为简化标准谷歌距离。这个计算方法的优点是相对于原始的NGD不再依赖于不断变化的谷歌搜索页面总数的大小M。此方法可作为部分符合要求的词语之间进行映射的优化方法,并不适合英文超级科技词表中所有的词组,因此本文的中英词表映射采用文献[1]的NGD(标准谷歌距离)算法。
3 实验及相关分析
3.1 实验数据及实验过程
选取了中文词表中前10个词语,以及与其对应的英语词表中的172个英语词语。首先对10个汉语词语进行匹配,由领域专家给出与其语义最相关的一个英语词汇。选定的10个汉语词汇如表1所示。与汉语词汇匹配的172个英语词汇如表2所示。
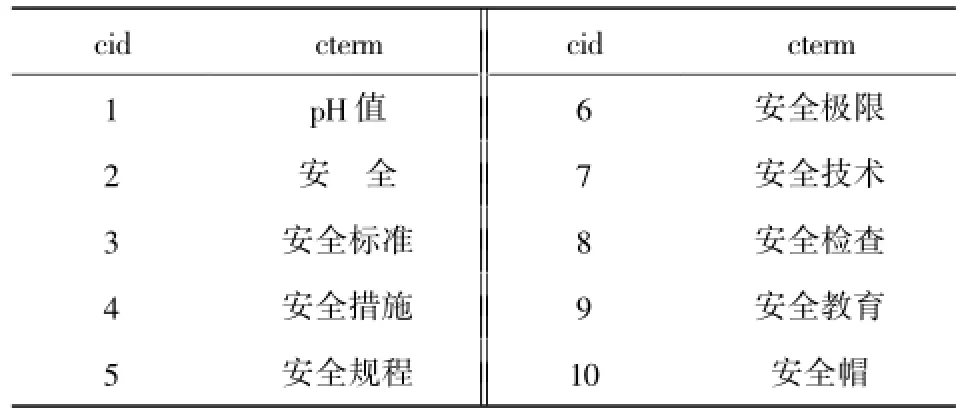
表1 汉语词表
按照映射流程设计的程序将剩下的待匹配词汇同该英语词汇进行语义相似度计算,即NGD的计算,并把得出的值由低到高排序。相似度的判断规则如下:
(1)NGD的取值范围为[0,∞]。由Google距离可知,词语与其本身的距离为0;语义距离为0时,相似度为1;语义距离为无穷大时,相似度为0。
如果x=y或x≠y,而f(x)=f(y)=f(x,y)>0,那么NGD(x,y)=0。这说明词汇x和y在Google中的语义是相同的。如果f(x)=0,那么对于任何搜索词条y都有f(x,y)=0,即NGD(x,y)=∞/∞。
(2)通常情况,NGD为非负数且对任意x有NGD(x,x)=0,即primary word的语义距离为0。对任意x,y有NGD(x,y)=NGD(y,x),它们是相互对称的。
(3)概念间的语义距离越大,则相似度越小,表明这两个概念的相关度越小。

表2 英语词表
在获得计算结果后,按照语义相似度的顺序插入新建数据表中,如表3所示。英英词汇间的语义距离导入汉英映射词表后转化为汉英词表间的相似度,完整有序的显示了汉英词表间的映射关系。在整个实验过程中,NGD算法简单可靠,接入Google api的搜索安全、快速且不需要人工干预。
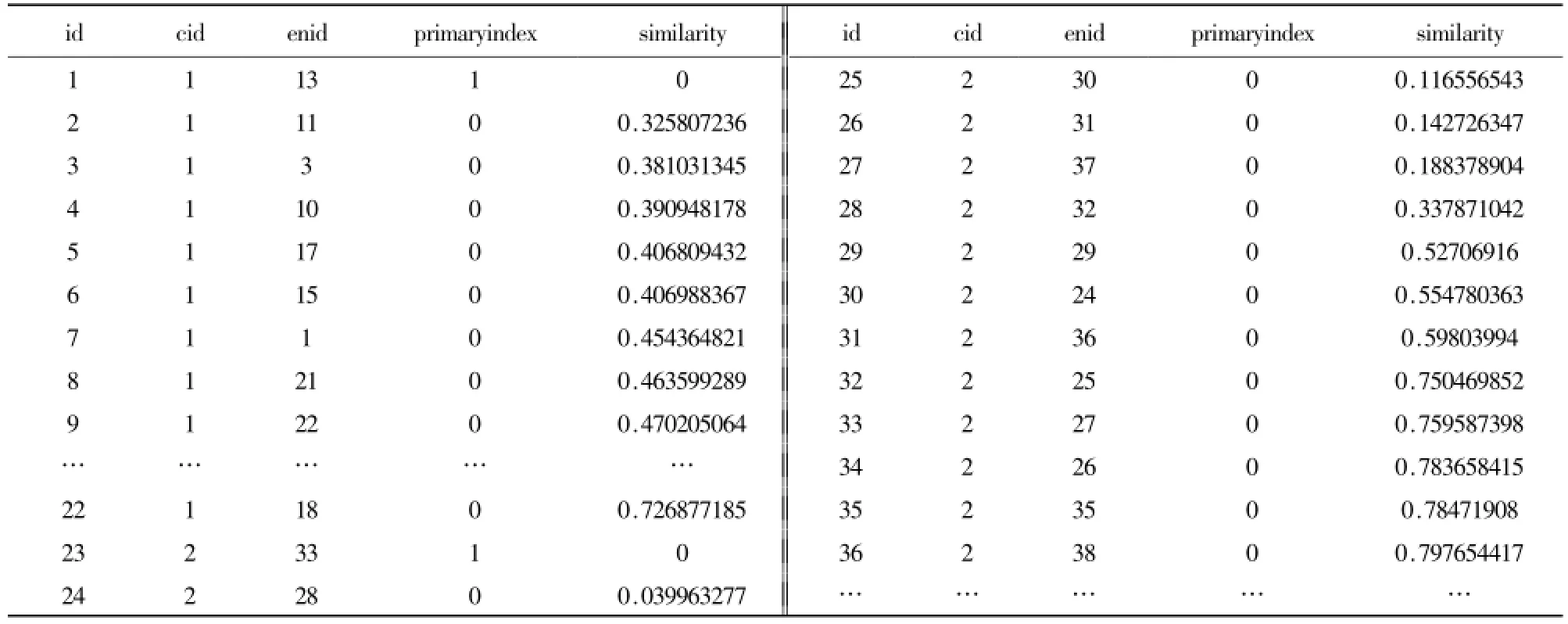
表3 经过NGD 计算后的映射词表
3.2 实验结果分析
我们对这几组数据进行了映射信息进行分析,获得映射模式如图2所示。
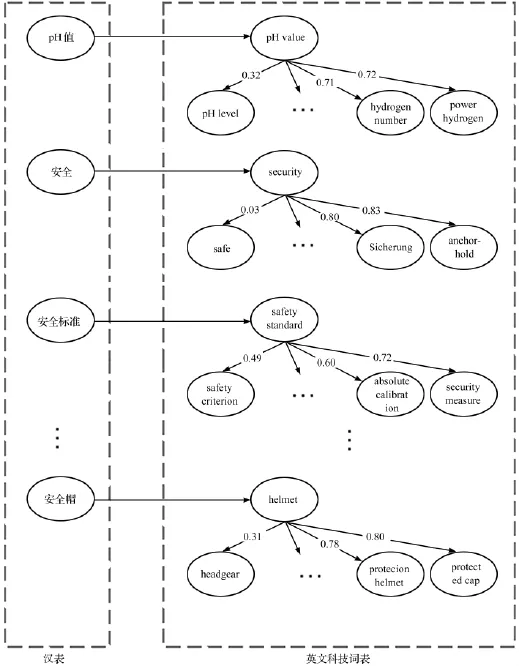
图2 映射信息模式图
左侧为汉表映射词汇,右侧为英文科技词表与汉表匹配的概念。水平映射为领域专家给定的最优映射,右侧数据代表其他相似词汇与最匹配词汇语义距离。将英英词汇间的相似距离导入映射信息中,获得汉英词汇之间的映射关系,最终英语词表中与某一中文词语相对应的多个词汇按语义相似性由高到低排列出来;这样,在后续的检索过程中,就可以直接调用此映射结果,将与汉语词语最相关的英文检索结果优先呈现,按语义相关性依次呈现后续检索结果,从而达到更好的检索体验。
4 总结
由于本项目所要达到的目标是更优的检索结果体验,因此对于某一中文检索词语,我们只需用文献[1]中的NGD方法对其所映射的多个英语词语按语义相关性进行一个排序,然后导入原有无序的汉对英映射表即可。Google距离计算时不需要提供领域本体,而是以Google的海量词汇为语义推理基础词库。虽然语义网会无限扩充,具体的数值是动态的,但词语之间的相关程度基本保持不变,为了更优的处理映射,对于部分满足优化算法条件的词语,可以采用文献[16]中优化的mNGD公式进行更准确快捷的计算。当前的计算已经基本满足我们的排序目标,在后续的工作中,可以对此映射模式进行优化改进,比如加入信息熵作为衡量相似度的指标。
在未来,由于NGD可以拓展成为NWD(标准网络距离),利用中文搜索引擎实现英语词汇对汉语词汇一对多的映射也是可以实现的。但是此方法也存在一些问题:在一个汉语词汇对应少量语义距离无限大即相似性太小的英语词汇时,只能依靠专家来修订,这也是大量映射模型研究的缺陷;过于依赖万维网和Google搜索引擎,当某些事件引起了个别词汇热度的上涨,会引起噪声干扰问题,需要消除歧义。在将来的研究中可以加入信息熵的计算,进行降噪,提高准确率。
[1]Rudi Cilibrasi,Paul M.B.Vitányi.The Google Similarity Distance[J].IEEE Trans.Knowl.Data Eng.,2007,19:1.
[2]Lin D.An information-theoretic definition of similarity[C]∥ICML,1998,98:296-304.
[3]Batet M,Sánchez D,Valls A,et al.Semantic similarity estimation from multiple ontologies[J].Applied intelligence,2013,38(1):29-44.
[4]詹志建,杨小平.基于语言网络和语义信息的文本相似度计算[J].计算机工程与应用,2014,(5):33-38.
[5]杨美荣,邵洪雨,史建锋,等.改进的领域本体概念相似度计算模型研究[J].情报科学,2014,(5):72-77.
[6]王桐,王磊,吴吉义,等.WordNet中的综合概念语义相似度计算方法[J].北京邮电大学学报,2013,(2):98-101,106.
[7]杨春龙.基于概念语义相似度计算模型的信息检索研究与实现[D].上海:华东理工大学,2013.
[8]Ristad E S,Yianilos P N.Learning string-edit distance[J].Pattern Analysis and Machine Intelligence,IEEE Transactions on,1998,20(5):522-532.
[9]Richardson R,Smeaton A,Murphy J.Using WordNet as a knowledge base for measuring semantic similarity between words[R].Technical Report Working Paper CA-1294,School of Computer Applications,Dublin City University,1994.
[10]Vizine-Goetz D,Hickey C,Houghton A,et al.Vocabulary mapping for terminology services[J].Journal of digital information,2006,4(4).
[11]Chan L M,Vizine-Goetz D.Toward a computer-generated subject validation file:feasibility and usefulness[J].Library resources&technical services,1998,42(1):45-60.
[12]常春,卢文林.基于叙词表映射的农业跨语言检索系统设计[J].情报学报,2008:294-296.
[13]张玉芳,艾东梅,黄涛,等.结合编辑距离和Google距离的语义标注方法[J].计算机应用研究,2010,(2):555-557,562.
[14]杨惠荣,尹宝才,付鹏斌,等.基于Google距离的语义Web服务发现[J].北京工业大学学报,2012,(11):1670-1675.
[15]Gligorov R,ten Kate W,Aleksovski Z,et al.Using Google distance to weight approximate ontology matches[C]∥Proceedings of the 16th international conference on World Wide Web.ACM,2007:767-776.
(本文责任编辑:马卓)
Concept Mapping Research Between Chinese and English Vocabularies Based on NGD
Zhang LiyiCui Heng
(School of Information Management,Wuhan University,Wuhan 430072,China)
This article mainly researched on concepts mapping between“Chinese Thesaurus”and“Science&Technology English Super-thesaurus”,then established an optimized and ordered mapping mode.It conducted experiments by using Semantic similarity algorithm based on the Google distance to calculate the semantic distance between English and primary word.Through experimental analysis,it got the sort of English words by similarity mapping mode to achieve a corresponding number of English words and Chinese words and arrange them in descending.The results obtained by sorting meet the basic requirements,some words require manual correction.
semantic similarity;Chinese Thesaurus;google distance;concept mapping
10.3969/j.issn.1008-0821.2015.03.001
TP391;G25
A
1008-0821(2015)03-0003-05
2015-01-03
本文系国家科技支撑计划项目“中英文双语检索模型研究”(项目编号:2011BAH10B00)的研究成果之一。
张李义(1965-),男,教授,博士生导师,研究方向:电子商务理论与技术,发表论文90余篇,出版专著1部。
