查询扩展技术在跨语言信息检索中的应用
2015-05-15杨亮
杨亮
(广东技术师范学院图书馆,广州 510400)
查询扩展技术在跨语言信息检索中的应用
杨亮
(广东技术师范学院图书馆,广州 510400)
互联网的快速发展使得网络资源的表现形式日益多样化,其中信息资源的多语种问题,成为人们获取信息的主要障碍。当用户检索的信息是自己不熟悉的语言时,往往难以获得准确的检索结果。基于Lucene平台设计并实现跨语言信息检索系统,系统在提问式翻译的基础上应用查询扩展技术。实验结果表明,查询扩展技术可有效提高跨语言信息检索的查全率。
跨语言信息检索;查询扩展;Lucene
0 引言
随着互联网的不断发展,使用不同语言的互联网用户也在不断增加,网络上的海量信息资源由很多不同的语言所组成,当用户需要检索的信息是自己不熟悉的语言时往往会面临一定的障碍,这使得很多用户不能自由地获取信息。为了解决多语种问题带来的语言障碍,让用户可以更加便捷地检索信息,学者们开始对跨语言信息检索进行探索。
传统的信息检索研究的是单一语种的检索问题,即检索提问式和被检索文档集采用的是同一种语言表述。而跨语言信息检索(Cross-Language Information Retrieval,简称CLIR)是指用户通过一种语言(通常是自己的母语)进行检索,获取以另一种或几种语言表述的信息或文档的信息检索技术和方法[1]。在跨语言信息检索中,用户构造检索提问式所使用的语言通常称为源语言(Source Language),一般是用户的母语或用户所熟悉的语言;而被检索的文档集所使用的语言通常称为目标语言(Target Language),目标语言一般是用户不熟悉甚至完全陌生的语言[2]。跨语言检索重点研究的是源语言与目标语言之间翻译匹配的问题。
1 翻译方法
目前,实现源语言与目标语言的翻译匹配主要有四种方法:提问式翻译、文献翻译、中间语种转换和非翻译[3~6]。
提问式翻译(Query Translation Approach)。这种方法将用户输入的检索提问式翻译为系统支持的语言,然后进行检索。提问式翻译是目前最为常用的方法,它可以很容易地与传统的单语种信息检索相结合,特点是对系统要求不高,执行速度快。但由于提问式比较短,通常都是一个或几个词,缺乏一定的上下文语境,对于一词多义、一义多词等翻译歧义问题不能很好地解决。实现提问式翻译主要有基于词典(Dictionary-Based)和基于双语语料库(Bilingual Corpus-Based)两种模式。
文献翻译(Document Translation Approach)。文献翻译在信息检索之前,将被检索的文档集转化为与检索提问式相同的语种,通过该方法返回给用户的结果是用源语言所描述的,且上下文语境信息比较宽泛,用户选择利用起来也就更加便利。不过由于目前机器翻译的效果并不理想,而将系统中的所有文献都从目标语种翻译为源语种的工作量十分庞大,完全由人工来翻译又不现实,因此,文献翻译的实用性较差。
中间语种转换(Interlingual Representation Approach)。提问式翻译将源语种转化为目标语种,而文献翻译将目标语种转化为源语种,中间语种转换方法则是将源语种和目标语种同时转换为第三方的中间语种。这种方法多用于源语种和目标语种不能直接翻译或双语词典不存在时,如德语和意大利语。
非翻译(No Translation Approach)。该方法不对源语种或者目标语种进行翻译就可以实现跨语言信息检索,即潜语义索引。这种方法不需要词典、机器翻译系统,但是如何针对具体问题构造优化的向量空间模型是一项经验性的工作,且训练文档不容易获取。
2 查询扩展技术
信息需求是用户想要查找的信息主题,信息检索就是从大规模非结构化数据的集合中找出满足用户信息需求的资料的过程。在检索时用户使用检索提问式来代表其信息需求,将检索提问式提交给系统,系统从文档集中返回与之相关的文档[7]。然而,用户提交的检索提问式通常是一个很短的句子或者是少量的关键词,简短的检索提问式不能很好地代表用户的信息需求,从而造成检索出的文档对用户的需求价值不高。为此,有学者提出了查询扩展技术。
查询扩展(Query Expansion)指的是利用计算机语言学、信息学等多种技术,把与原查询相关的词语或者与原查询语义相关联的概念添加到原查询,得到比原查询更长的新查询,然后检索文档,以改善信息检索的性能,解决信息检索领域长期困扰的词不匹配问题,弥补用户查询信息不足的缺陷[8]。查询扩展技术主要分为全局分析和局部分析两大类。全局分析是对整个文档集的语词进行相关分析,计算每对语词间的关联程度,在检索时选取与检索提问式关联程度高的语词对检索提问式进行扩充。全局分析需要对整个文档集进行相关处理,系统计算量大,只适合小范围内的信息检索,不适用于大规模的海量检索。局部分析利用初始检索得到的最相关的N篇文档作为扩展用词的来源,不需要对全部语词进行相关计算[9]。
在跨语言信息检索领域,以往的研究多集中在理论和模型方面,实践研究较少,本文基于Lucene平台设计并实现了一个汉英跨语言信息检索系统,使用局部分析中的相关性反馈技术对翻译后的检索提问式进行查询扩展[10],通过实验研究应用查询扩展前后系统的检索性能。
3 系统设计与实现
本文基于Lucene平台实现了一个跨语言信息检索系统,结构如图1。系统应用了查询扩展技术检索系统,采用了B/S架构,使用Eclipse开发平台和Tomcat服务器搭建开发环境,采用Java语言进行编程,并使用MySQL数据库管理机读词典。
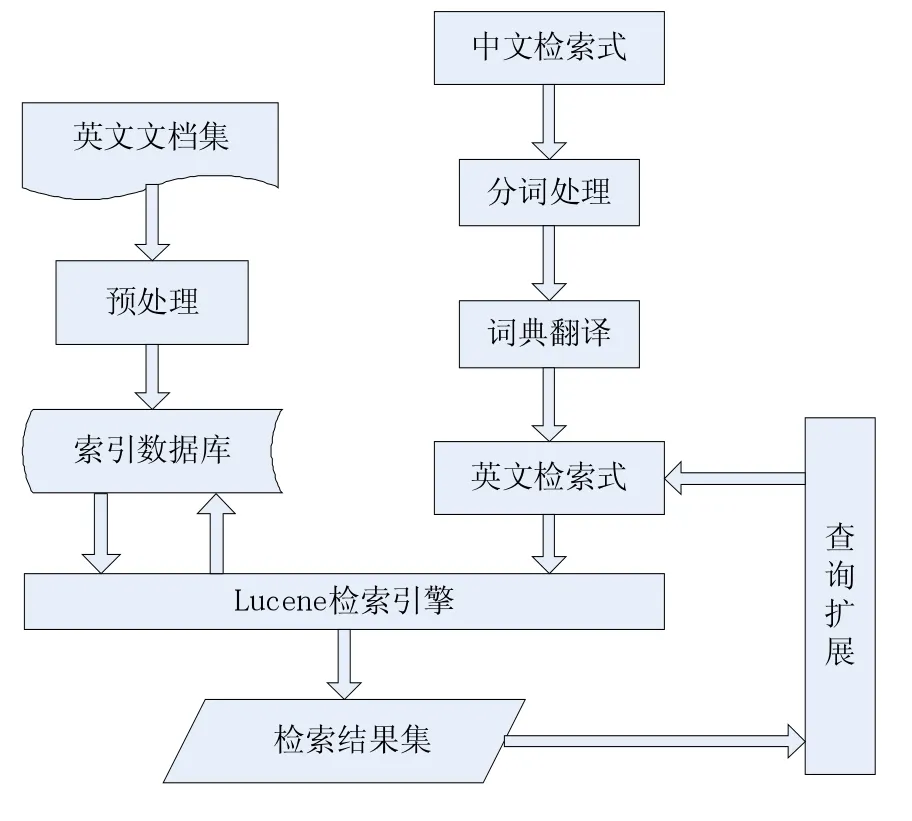
图1 跨语言信息检索系统结构图
3.1 Lucene检索引擎
Lucene是一款高性能的、可扩展的信息检索(IR)工具库,是一款以Java实现的成熟、自由、开源的软件,为开发者提供了完整的检索引擎和索引引擎,可以方便地在系统中实现全文检索的功能。同时,Lucene是Apache软件基金会(Apache Software Foundation)中的一个项目,基于Apache软件许可协议授权,在近年来已经成为最受欢迎的开源信息检索工具库。
本文基于Lucene平台实现系统的检索功能,Lucene的核心API主要可分为两类。第一类是索引过程的核心类,包括IndexWriter、Directory、Analyzer、Document等。其中IndexWriter(写索引)是索引过程的核心组件,主要负责创建新索引和对索引的维护。Directory类指明了Lucene索引的位置所在。Analyzer和Document则表示在建立索引前,文本文件需要经过分析器和文档化的处理。第二类是搜索过程的核心类,包括IndexSearcher、QueryParser、Query、TopDocs等。其中IndexSearcher用于搜索由IndexWriter类创建的索引,所有的检索操作都是通过IndexSearcher实例使用一个重载的search方法来实现。QueryParser类将用户输入的检索提问式处理为一个具体的Query对象;大多数IndexSearcher的search方法都会以返回TopDocs对象的形式来返回搜索结果。
3.2 分词
在英语环境中,英文单词之间用空格来进行间隔,单词就是自然的索引单元,而在中文环境中,中文文本是以字为基本单元的,字和字之间没有明显的间隔,这就需要中文分词技术来解决这个问题,运用中文分词技术可以将连续的文本序列按照一定的规则切分成具有独立语义的词组[11]。中文分词是中文信息处理的基础与关键,本文使用ICTCLAS(Institute of Computing Technology,Chinese Lexical Analysis System)来对中文检索提问式进行分词。ICTCLAS是由中国科学院计算技术研究所研制出的汉语词法分析系统,主要功能包括中文分词、词性标注、命名实体识别、新词识别等。ICTCLAS是目前比较好的汉语词法分析器,提供了一套完整的动态链接库供开发者直接在自己的系统中调用来实现汉语词法分析,支持C/C++/C#/Delphi/Java等主流开发语言。
3.3 词典翻译
本文使用基于词典的提问式翻译方法对中文检索提问式进行翻译处理,词典选用了MDBG汉英词典,该词典属于1997年Paul Denisowski创办的CEDICT项目,支持简体中文、繁体中文以及拼音与英语的对照翻译。词典可以在MDBG网站上免费获取,内容涵盖了单字、词组、短语、地名、专业术语等110284个词条。
词条示例:
世界觀世界观[shi4 jie4 guan1]/worldview/world outlook/Weltanschauung/
3.4 建立索引
在进行检索前,首先要对检索文档建立索引,以便进行快速检索。索引操作把数据处理成一种高效的、可交叉引用的数据结构,这种结构允许对存储在其中的单词进行快速随机存取。本文基于Lucene平台建立索引,Lucene的索引结构分为索引(Index)、索引段(Segment)、索引文档(Document)、索引域(Field)和索引项(Term)五个层次。Lucene的每个索引结构由若干个段组成,每个段包含若干个文档,每个文档管理若干个域,每个域中有若干个项,项就是索引中最基本的语汇单元[12]。
本文对数据建立索引的过程分为三个部分:
(1)预处理:将所有检索文档都转换成Lucene能够处理的格式——纯文本数据流,以.txt的格式保存在磁盘中。
(2)分析:通过Lucene索引管理器对文档进行分析,将文本转换为最基本的索引项,并且过滤掉一些频繁出现却没有实际意义的词,如英文中的a、an、the、in、on等停用词,去除标点符号。
(3)写入索引:将分析处理后的结果写入到索引文件,以倒排索引的结构存储在磁盘中。从文档中抽取出的语汇单元被看作是查找关键词,可以快速地执行检索操作。
3.5 查询扩展
本文使用局部分析中的相关性反馈技术对翻译后的检索提问式进行查询扩展,根据初始检索的结果,利用Lucene的评分机制对返回结果中的文档进行排序,将排名前3的文档取出,并对这3篇文档进行词汇统计,用出现频率最高的词汇w_1去扩展翻译后的检索式。如果w_1已经出现在翻译后的检索式中,则使用出现频率第二高的词汇w_2进行扩展,以此类推。
3.6 实验过程
实验目的是测试应用查询扩展技术前后跨语言信息检索系统的检索性能,使用查准率和查全率两个指标来衡量。查准率是指检出的相关文档与检出文档总数的比值,查全率是指检出的相关文档与相关文档总数的比值[13]。查准率用来衡量系统的检索精度,查全率用来衡量系统检出相关文档的能力。
实验运行环境如下:CPU:Intel Pentium Dual-Core E5200、内存:4GB、硬盘:希捷250GB、操作系统:Windows 7 Ultimate。实验所用的检索文档全部来源于新华网,共计300篇英文文档,内容涵盖科技、健康、体育、经济等多个类别。针对实验设计了10个检索式,先进行一次初始检索,然后再进行两次查询扩展,对比系统的查准率和查全率。
具体的实验步骤如下:
①输入中文检索式,标记为zws;
②对zws进行分词和去除中文停用词的处理;
③通过机读词典对zws进行翻译,得到相应的英文检索式ews0;
④使用ews0进行初始检索,根据检索结果计算相应的查准率和查全率;
⑤进行第一次查询扩展,将扩展结果加入到ews0中得到检索式ews1;
⑥使用ews1进行检索,根据检索结果计算相应的查准率和查全率;
⑦进行第二次查询扩展,将扩展结果加入到ews1中得到检索式ews2;
⑧使用ews2进行检索,根据检索结果计算相应的查准率和查全率。
3.7 实验结果
例如,用户的信息需求是查找手机系统方面的信息,输入中文检索式“手机系统”,经分词处理后系统翻译得到英文检索式“cell phone mobile phone system”,进行初始检索后根据检索结果计算出查准率为0.5588,查全率为0.95。之后进行第一次查询扩展,得到检索式“cell phone mobile phone system android”,再次进行检索,根据检索结果计算出查准率为0.5405,查全率为1.0。然后进行第二次查询扩展,得到检索式“cell phone mobile phone system android smart”,根据检索结果计算出查准率为0.5333,查全率为1.0。
对10个检索式初始检索结果的查准率和查全率、两次查询扩展后检索结果的查准率和查全率进行对比,如图2、图3。
通过检索结果可以看出,在应用了查询扩展技术后,系统的查全率得到了提升,同时因为获取了较多的检中结果,系统的查准率有所下降,这也是系统表现良好的一个证明。“检索式10”的查准率在第二次查询扩展后有明显的下降,其查全率在第一次查询扩展后有明显的上升,这是因为词典对一些新词汇没有完全收录而产生的噪点数据。另外,当初始查询得到的文档在经过排序后,如果排名靠前的文档与原信息需求相关性不大,在查询扩展时就会把一些无关的词加入到新查询中,也会影响检索效果。从总体上看,查询扩展技术在跨语言信息检索系统中表现出了良好的性能。
4 结语
本文基于Lucene平台实现了一个跨语言信息检索系统,通过实验对初始查询、一次查询扩展、二次查询扩展进行了比较研究,实验结果表明查询扩展技术可有效提升跨语言信息检索的查全率。在一个好的系统中,查准率往往会随着返回文档数目的增加而降低[7],怎样在满足用户信息需求的同时控制查准率和查全率之间的平衡是今后需要研究的方向。另外,本文对跨语言信息检索由中文到英文的翻译进行了研究,中英文双向互译也将作为今后进一步的研究工作。
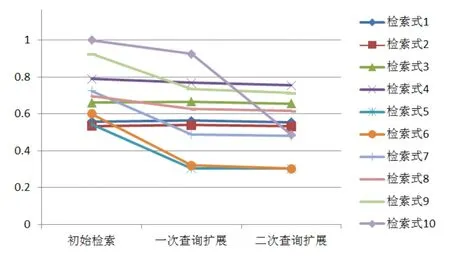
图2 应用查询扩展前后系统的查准率

图3 应用查询扩展前后系统的查全率
参考文献:
[1] 朱培焱,夏栋梁.汉英跨语言信息检索研究[J].计算机与现代化,2011,08:13~16
[2] 张会平,周宁,陈立孚.跨语言信息检索可视化研究[J].情报科学,2007,01:134~138
[3] 任成梅.跨语言信息检索的发展与展望[J].图书馆学研究,2006,04:79~82
[4] 赖茂生,侯艳飞.跨语言检索技术:策略与方法[J].郑州大学学报(哲学社会科学版),2005,04:11~14
[5] 王昊.跨语言信息检索实现方法与关键技术探讨[J].情报杂志,2005,07:46~49
[6] 刘伟成,孙吉红.跨语言信息检索进展研究[J].中国图书馆学报,2008,01:88~92
[7] Manning C D,Raghavan P,Schütze H.Introduction to Information Retrieval[M].Beijing:Posts&Telecom Press,2010
[8] 陈燕红,黄名选.基于Apriori改进算法的局部反馈查询扩展[J].现代图书情报技术,2007,09:84-87
[9] 黄名选,严小卫,张师超.查询扩展技术进展与展望[J].计算机应用与软件,2007,11:1~4+8
[10] 郑敏.跨语言信息检索的理论与实践[J].情报理论与实践,2003,03:223~225+212
[11] 于雪丽.Lucene中文分词在科研文档全文检索系统的应用研究[D].青岛大学,2011
[12] 郑榕增,林世平.基于Lucene的中文倒排索引技术的研究[J].计算机技术与发展,2010,03:80~83
[13] Ricardo Baeza-Yates,Berthier Ribeiro-Neto等.王知津,贾福新,郑红军等译.现代信息检索[M].北京:机械工业出版社,2005
Applications of Query Expansion in Cross-Language Information Retrieval
YANG Liang
(Department of Library,Guangdong Polytechnic Normal University,Guangzhou 510400)
With the rapid development of the Internet,the network resources have too many forms.Meanwhile,most of them are described in different languages,which has become a mainly obstacle when people get information.People can't get precise results if the information resource uses a language that is unfamiliar to them.Designs and implements a cross-language information retrieval system which uses query translation approach and query expansion technology based on Lucene.The experimental results show that the recall of cross-language information retrieval is improved when query expansion is applied.
Cross-Language Information Retrieval;Query Expansion;Lucene
1007-1423(2015)02-0026-05
10.3969/j.issn.1007-1423.2015.02.007
杨亮(1982-),男,江苏丰县人,硕士研究生,馆员,研究方向为信息管理、信息检索
2014-12-02
2014-12-16
广东技术师范学院2013年校级科研项目(No.13KJY18)
