基于Storm和Hadoop的大数据处理架构的研究
2015-05-15靳永超吴怀谷
靳永超,吴怀谷
(1.西华大学数学与计算机学院,成都 610039;2.成都大学信息科学与技术学院,成都 610106)
基于Storm和Hadoop的大数据处理架构的研究
靳永超1,2,吴怀谷2
(1.西华大学数学与计算机学院,成都 610039;2.成都大学信息科学与技术学院,成都 610106)
针对现有的大数据技术Storm和Hadoop,分析其内部实现机制,业务场景以及技术优缺点,提出一种基于Storm和Hadoop的新型大数据处理解决方案,以使得大数据处理更稳定,更高效,并对新型大数据解决方案进行性能测试,证明其高效性和稳定性,所以这种新型架构是高效、稳定、可行的。
大数据;Storm;Hadoop;解决方案
0 引言
在当前这个信息爆炸的时代,企业数据以几何的速度增长,预测到2020年,全球存储数据量将会达到35ZB,很多像Facebook每天每小时产生的数据就达到10TB数据[1]。像这种海量的数据早已经远远超出传统数据处理技术的极限,无论是计算效率,还是计算时间都无法满足要求。所以对大数据的研究得到广泛的关注,目前对大数据处理的研究主要使用两种核心技术:一种是基于MapReduce磁盘处理任务调用的批处理Hadoop技术[1],另一种是基于内存计算的分布式实时流Storm技术[2]。大数据处理现阶段面临的问题是各种不同的业务场景需求,大数据缺乏一个从全局统一的解决方案。文献[3]只是单一地解决Hadoop存储的性能问题,文献[4]也只对Storm的Topology进行设计,大数据技术的稳定性、扩展性和全局性没有得到更好的发展,从本质上说仍然没有解决现有的大数据遇到的难题。
1 Storm和Hadoop内部实现机制原理分析
1.1 Hadoop原理
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,其核心内容是:分布式文件系统(Hadoop Distributed File System,HDFS)和MapReduce(Google File System,GFS)编程模式。MapReduce的核心思想就是将数据切片计算来处理大量的离线数据。
Hadoop有很多优点,例如动态的分配节点、MapReduce任务监控、跨机架保存块副本,DataNode故障后,可以动态记录故障,并重新寻找离客户端最近的DataNode进行任务重新分配,机架感知策略等都显示出其强大的高效性、高扩展性和可靠性。但是Hadoop也有其明显的缺点:①Hadoop的MapReduce擅长处理少量大数据,对小数据处理不擅长,默认64MB为一个Block,如果出现大量小于64MB的小文件,同样每个要占一个Block,大大降低了性能的利用率。②NameN-ode一旦挂掉,整个运行环境陷入困境。③其离线全量的处理方式,业务场景受到局限性,在数据过大的场景下,可能导入数据就要花几天几夜。
1.2 Storm原理
Storm是一个分布式的、可靠的、容错的数据实时流式处理系统,Spout是Storm中的消息源,用于为Topology生产消息,一般从外部数据源(如Message Queue、RDBMS、NoSQL、Log)不间断地读取数据并发送Tuple给Bolt进行数据操作,Bolt是Storm中的消息处理者,用于为Topology进行消息处理,Bolt可以执行过滤、聚合、查询数据等操作,而且可以一级一级地进行处理。这种Topology模型采用消息传递方式交互数据,数据量相比较从磁盘获取要小,而且动态地读取,每次读取量小。
Storm的高可靠性和容错性主要集中体现在Storm的数据重发机制上,由于每个Bolt可以启动多个task,每个task都会带有一个唯一标示的ID,Storm将此ID持久化,在数据重发时候读取发送失败的task的ID状态,重发发送数据,保证了数据的一致性,这明显优于S4实时流系统,而且Topology递交之后,Storm会一直运行直到主动释放Topology或者kill掉,这明显要优于Hadoop系统。
Hadoop的批处理和Storm的实时流处理,本是两种不同的业务场景,但是如果我们很好地进行融合和集成,就会发现组合在一起的新型处理方案在性能和扩展性以及稳定性上都得到了提升。
2 集成Storm和Hadoop的新型大数据处理方案
从离线批处理和实时处理来说,原生Storm支持单个消息及批量消息的事物机制,Trident事务机制通过state以及继承事务spout支持状态持久、更新、查询,Storm-trident-drpc远程调用机制对同步并行查询业务有较好的支持,而且Storm的内存处理方式要比Hadoop的磁盘处理速度快几个数量级,所以数据处理层我们选择Storm技术为主,存储层加入Hadoop的HDFS、HBase,以及整个Hadoop生态圈。
如图1所示,首先通过数据采集入口,针对关系型数据库,配置异构数据源,通过Storm进行大数据处理,将数据按照实时处理、分析、融合等规则进行数据处理,这其实就是设置Topology架构的过程,为了保证实时性能,在处理过程中加入Kafka消息队列。一方面为了为了缓解Web服务器端的处理压力,来缓冲客户端发送的消息,以供后续程序处理,另外主要是支撑Web服务器端的处理和持久化保存。通过Kafka可以降低消息队列系统的复杂性,提高消息队列系统的性能,扩展性以及吞吐量。而在实时的场景中,为了数据交换效率,加入Redis内存数据库,其特点是高性能、持久存储、适应高并发的应用场景、保证了效率,数据缓存在内存中,可以周期性地把更新的数据写入磁盘或者修改操作写入追加的记录文件中,通过实现master-slave(主从同步),提高Storm的并行处理能力。Zookeeper是作为分布式应用建立更高层的同步(synchronization)、配置管理、群组以及名称服务。可以监控挂在其上的节点,包括这个目录节点中存储的数据的修改,子节点目录变化等,一旦变化可以通知设置监控的客户端,通过这个特性可以实现的功能包括配置的集中管理、集群管理、分布式锁等。
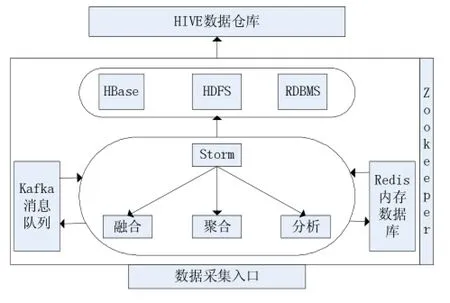
图1 架构设计
在数据存储层,我们设计有RDBMS关系型数据库、HBase列族数据库、HDFS分布式文件系统。引入HBase,一方面是由于其列族的NoSQL数据库在做数据分析时候比较方便,更主要的是为了在Storm做数据融合,数据分析处理过程中,为了保证数据一致性以及数据重发机制,存入到HBase,加入时间戳,一旦任务挂掉或者数据丢失,在数据重发的时候,读取HBase库中数据库的时间戳,返回Storm处理层,通过Storm自带的固化ID的重发机制进行续传,在周期性读取时候,取时间戳最大的数据,这样保证了数据的实时更新和一致性。引入HDFS,由于其对数据类型的支持,以及最大的数据集,将Storm处理的数据统一存储入HDFS中,包括之前存入到HBase的数据,转存在HDFS,如果要进行数据分析,通过构建Hive构建数据仓库,并通过Hive UDF实现HDFS数据提取转化加载,可以存储、查询和分析,数据分析师可以对其进行业务需求分析,提取数据价值。
针对数据存储层,采用集群高可用性,提高数据库稳定性。由于实时处理对HBase的数据库要求比较严格,必须保证数据的一致性和时间戳的问题,一旦数据库挂掉,数据将会无法插入和读取,所以必须搭建HBase集群,使用HA(High Available)高可用性集群,对集群进行心跳检测,实时地对节点数据进行分布式备份和节点切换,一旦某个节点挂掉,自行切换存储进入集群另一个节点,对Storm集群和Hadoop集群以及HBase集群,我们都要有一个统一的集群协作和负载均衡。
3 性能评估
Hadoop分布式部署,使用三台一体机,安装系统CentOS 6.4,CPU 2×2.4G,内存2G,硬盘500G,集群安装环境:Java1.7+Zookeeper-3.4.5-cdh4.3.0+Kafka+ storm-0.9.1+MySQL5.1.69+Hadoop2.0+HBase-0.94.3。
3.1 实验步骤
(1)实验方法:准备10个log文件,分别具备10w~100w行数据,对10个log文件分别进行处理,每处理一个log文件,需要起一个Topology,测试过程中记录导入的数据行数和数据大小,处理过程中监控服务器master的CPU、I/O和Mem变化情况。
(2)结果记录:
①作业处理速度
表1和图2所示,在处理从10w~100w数据中,新型解决方案在数据抽取、数据采集、数据预处理中,随着数据量变大,处理数据大小变化成规律性变化,这体现出数据处理良好的稳定性,而随着数据量变化,所需处理时间越来越少,作业处理速度越来越快,体现其高效性,数据量越大,越能体现这种高性能。
②作业处理的稳定性
如图3所示,在Storm集群中CPU、I/O和Mem数据中,master的CPU占有率和I/O操作数一直处于良好的负载值,集群节点之间的资源处于良好稳定的状态。
4 结语
本文结合Storm和Hadoop构建了一种大数据架构。通过Kafka消息队列,对实时数据进行缓冲,通过Redis内存交换数据,增强的原生Storm的稳定性和处理速度,这种既可以支撑增量的实时流处理,也可以实现类似批量的处理方式,通过扩展数据存储层以及增强高可用性,进一步扩展了大数据业务场景。面临各种各样的大数据需求,未来大数据架构的发展将是高度集成、满足各种业务场景需求的大而全的架构。

表1
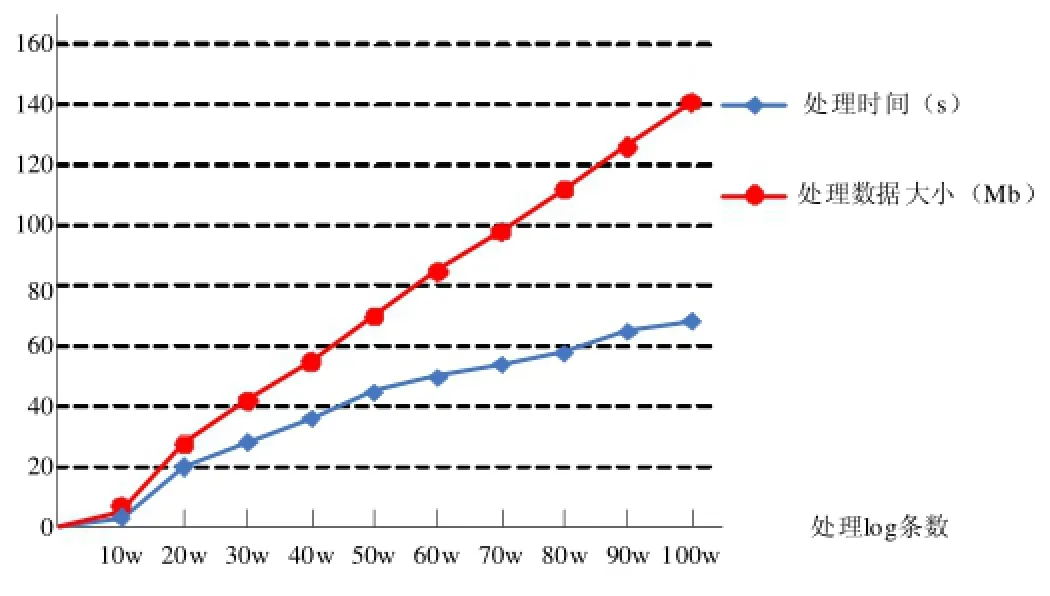
图2
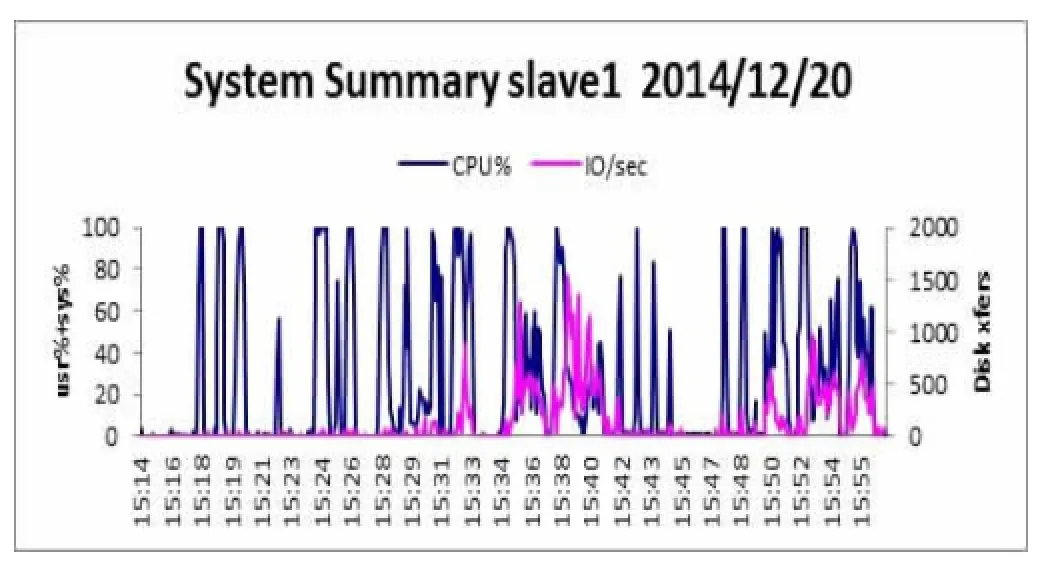
图3 master的CPU占有率和I/O操作数
参考文献:
[1] 路嘉恒.Hadoop实战[M].北京:机械工业出版社,2011
[2] Jin X J.Trident Storm and Flow Calculation Experience[J].Journal of Programmers,2012(10):99~103
[3] 张春明,芮建武,何婷婷.一种Hadoop小文件存储和读取的方法[J].计算机应用与软件.2012,29(11):95~100
[4] 杜政,王鹏,黄焱,等.一种基于Storm编程模型的迭代Topology方案[J].成都信息工业学院学报.2014,29(1):47~51
[5] 邓华锋,刘云生,肖迎元.分布式数据流处理系统的动态负载平衡技术[J].计算机科学,2007,34(7):120~123
[6] 刘鹏.实战Hadoop——开启通往云计算捷径[M].北京:电子工业出版社,2011
[7] 黄健宏.Redis设计与实现[M].北京:机械工业出版社,2014
[8] 陆嘉桓.大数据挑战与NoSQL数据库技术[M].北京:电子工业出版社,2013
[9] 辛大欣,刘飞.Hadoop集群性能优化技术研究[J].北京:电脑知识与技术,2011,7(22):5484~5486
[10] (美)MICHAEL MILLER著.云计算[M].姜进磊,孙瑞志,向勇,史美林译.机械工业出版社,2009
[11] White T.Hadoop:The Definitive Guide[M].US:O'Reilly Media,2012
Research on the Big Data Process Framework Based on Storm and Hadoop
JIN Yong-chao1,2,WU Huai-gu2
(1.College of Mathmatic and Computer,Xihua University,Chengdu 610039;2.College of Information Science Technology,Chengdu University,Chengdu 610106)
Proposes a new solution which is based on the technology of the big data named Storm and Hadoop,analyses the internal implementation mechanism of the Hadoop and Storm,the business scenario,as well as the advantages and disadvantages of them.The new solution can make the processing of the big data more efficient and stable.Tests this new solution which can prove the high efficiency and stability of the solution.So the new solution is efficient,stable and viable.
Big Data;Storm;Hadoop;Solution
1007-1423(2015)04-0009-04
10.3969/j.issn.1007-1423.2015.04.002
靳永超(1987-),男,陕西宝鸡人,硕士,研究方向为云计算、大数据处理
吴怀谷(1975-),男,四川成都人,博士,教授,研究方向为云计算体系结构、移动应用体系结构和分布式信息系统
2014-12-09
2014-12-26
