基于K-means的图像文字识别与提取研究
2015-05-15岳建杰赵旦峰
岳建杰,赵旦峰
哈尔滨工程大学信息与通信工程学院,黑龙江哈尔滨 150001
基于K-means的图像文字识别与提取研究
岳建杰,赵旦峰
哈尔滨工程大学信息与通信工程学院,黑龙江哈尔滨 150001
针对当前图像文字识别与提取的最新发展状况,提出一种基于K-means的图像文字识别与提取算法,其主要处理步骤包括图像的预处理、像素点聚类处理、图层的选择与优化以及最终的文字切分等。经过上机对算法进行测试,该算法能够有效提高图像文字识别与提取的准确率与执行效率,并可以针对不同环境下的图片文字进行有效识别。
K-means;图像文字提取;文字识别;二值化处理
目前常用的识别算法包括神经网络、支持向量机、K-近邻算法等,而K-means聚类算法是当前常用的基于划分的分类算法,能够按照既定标准与要求将集合进行划分。在数字图像文字提取与识别中,可以通过对数字图像进行灰度处理,将文字背景与文字前景用不同的灰度像素来表示,并使用K-means聚类算法进行像素划分,从而将文字从数字图像中提取出来,作为OCR识别的图像输入[1]。所以,K-means聚类算法是当前图像文字识别与提取中使用非常广泛的处理算法。
1 K-means聚类算法基本原理
根据集合元素划分方法的不同,聚类算法可以分为层次划分、密度划分、网格划分以及模型划分等,K-means属于基于密度划分的聚类算法[2]。
K-means聚类算法的基本思想是利用集合元素之间的距离为划分标准,在集合内部按照元素的分布密度的不同将元素划分为不同的子集合。
在划分过程中,通过定义元素之间的距离,按照元素到聚类中心之间的距离最小原则将元素进行聚合,从而得到最终的划分结果。
K-means聚类算法的基本流程主要包括以下几个步骤[3]:
1)根据元素划分的基本要求,从集合元素中随机选择k个元素作为划分结果的中心元素,并针对集合中的每个元素计算其到聚类中心元素的距离大小,按照最小距离原则把各个元素划分到对应的聚类中心元素集合中;
2)按照划分结果对各个子集合中的元素计算特征均值,并根据计算结果对划分结果进行更新操作[4];
3)对更新后的子集合元素再次按照第一步中的方法进行聚类操作,从而得到更新后的元素划分结果;
4)按照上述步骤进行循环计算,当2次计算所得到的聚类中心元素相同时,所得到的划分结果即为聚类结果。
由于K-means聚类算法的基本流程比较固定,其本质是在给定的集合元素距离计算方法的前提下,不断进行聚类迭代与循环运算即可对元素进行聚类划分[5]。所以在应用过程中只需要定义合适的距离计算方法即可非常方便地将K-means算法转化为计算机可执行程序进行上机运行,所以K-means聚类算法是目前对集合元素进行分类的常用方法。
采用K-means聚类算法的缺陷主要是在选择聚类中心元素时,算法受到样本元素的选择随机性和外部噪声的影响比较显著,如果不进行有效的算法优化则比较容易导致算法陷入局部最优。因此在采用K-means聚类算法的图像文字提取与识别处理中需要根据图像文字自身的特点对算法进行改进与优化。
2 算法流程设计
文中提出的基于K-means的图像文字识别与提取算法中主要包括数字图像预处理、像素聚类处理、图层选择与优化以及文字切分4个核心步骤,并最终得到能够被OCR进行识别的文字数字图像,算法详细流程设计介绍如下。
2.1 图像预处理
在本文提出的图像文字识别与提取算法中,首先需要对数字图像进行一系列的预处理,包括图像灰度转换、二值化处理、文字块定位以及文字边缘检测等,图像预处理的算法流程设计如图1所示。

图1 图像预处理算法设计
从图1中可以看到,图像预处理的过程主要包括如下几个步骤。
1)图像灰度转换
将彩色图像转化为仅包含像素亮度信息的灰度图,并将数字图像中的背景冗余信息与其他噪声进行去除,从而为后续的文字块分割以及文字提取提供便利。
数字图像文字提取与识别中的噪声主要是由于外界光照因素、颜色因素和其他因素导致的图像有效信息受到干扰所产生的,因此噪声的去除主要采用了滤波方式,包括领域平均滤波法以及中位值滤波法等,将数字图像像素中的噪声去除[7]。
2)二值化处理
将数字图像经灰度化处理后得到的黑白图像中的背景与前景进行分离,一般采用灰度像素阈值分离的方法来进行,包括全局域阈值分离法、局部阈值分离法以及动态可变阈值分离法等。
由于动态阈值分离法的计算量较大、处理效率不高,同时全局阈值分离法的分离效果较差,所以本算法采用了局部最优阈值分离法,通过计算数字图像不同区块中像素的灰度梯度值的变化来对像素进行分离[8]。
3)边缘检测处理
将经二值化处理后的图像进行特征区域划分,通过对数字图像灰度变化、颜色变化以及纹理特征的变化差异进行检测,从而实现文字块与图像背景的分离。
本算法的边缘检测算法中主要采用了一阶以及二阶微分算子来进行图像像素灰度导数值的计算,从而实现不同区域的边缘检测。
2.2 聚类处理
经过图像预处理之后即可得到能够采用K-means聚类算法进行文字块提取的目标图像[9]。通过对目标图像中的像素进行聚类处理,可以从图像中提取得到待识别的文字目标区块,本算法采用的聚类处理详细流程如图2所示。

图2 聚类处理详细流程设计
从图2中可以看到,聚类处理过程主要包括的步骤如下所述。
1)对数字图像进行像素空间分类,将其划分为N个子簇,并在每个像素簇中随机选择一个像素作为中心点;
2)采用欧几里得距离作为像素间距离的计算方式分别计算N个像素簇中各个像素点到中心点的距离大小,并按照最小距离原则进行像素聚类,得到N个像素点子集合,记为Pi(n),其中i=1,2,…,N;
3)随机选择2个像素子集合Pk和Pm,并计算2个集合之间的最近距离,随后将Pk中距离Pm最近的像素点归入Pm集合,并从Pk中删除;
4)重新计算经过上一步处理后得到的N个像素子集合的中心点,重复上述过程直到各个像素子集合不再发生变化;
5)对最终得到的N个像素子集合计算灰度均值,并以计算得到的灰度值作为各个像素子集合的标记,并采用局部聚类分类法进行,从而得到最终的聚类结果。
2.3 图层选择与优化
在经过聚类处理后可以将原数字图像的灰度处理结果划分为多个图层。由于数字图像文字的中心特性,可以通过计算各个图像图层像素点距离中心区域的距离大小得到最终需要选择的图像图层[10]。
在本算法中为了提高图层选择的准确度,在图层选择过程中,首先将图层集合按照中心距离的大小划分为2个子集合。其次采用连通域分析、像素噪声去除等操作,最后再选择距离最小的图像图层作为最终的选择结果,在此图层中即包含了要进行提取与识别的文字块,即可对其进行文字切分操作。
2.4 文字切分
在经过阈值分割后得到的图像区域中可能还包含部分噪声像素,即得到的分割结果中还包含了部分不属于文字区域的像素点,所以需要对这些噪音像素进行去除处理,经过切分处理后得到最终能够被OCR识别的文字图像[11]。
在本文的算法中对上述噪音像素进行剔除的步骤主要包括:
1)首先将文字处理结果中明显不符合文字高宽比的像素进行去除;
2)通过定义文字块的边缘密度,并根据文字块边缘密度通常大于0.2的特征进一步去除噪音像素;
3)将处理结果中区域面积小于10个像素点的区域进行去除;
4)对处理结果中的像素块进行融合处理,得到最终的文字块。
通过文字切分处理后即可得到能够被OCR识别的文字图像。
3 算法检测效果测试
为了检验本文提出的图像文字识别算法的识别效果,做了与基于BP神经网络识别算法的对比。本文提出的图像文字识别算法采用OpenCV开发接口在Visual C++6.0开发环境下对算法进行了软件实现,OCR识别功能接口采用Microsoft Office工具实现,软件实现的基本流程如图3所示。
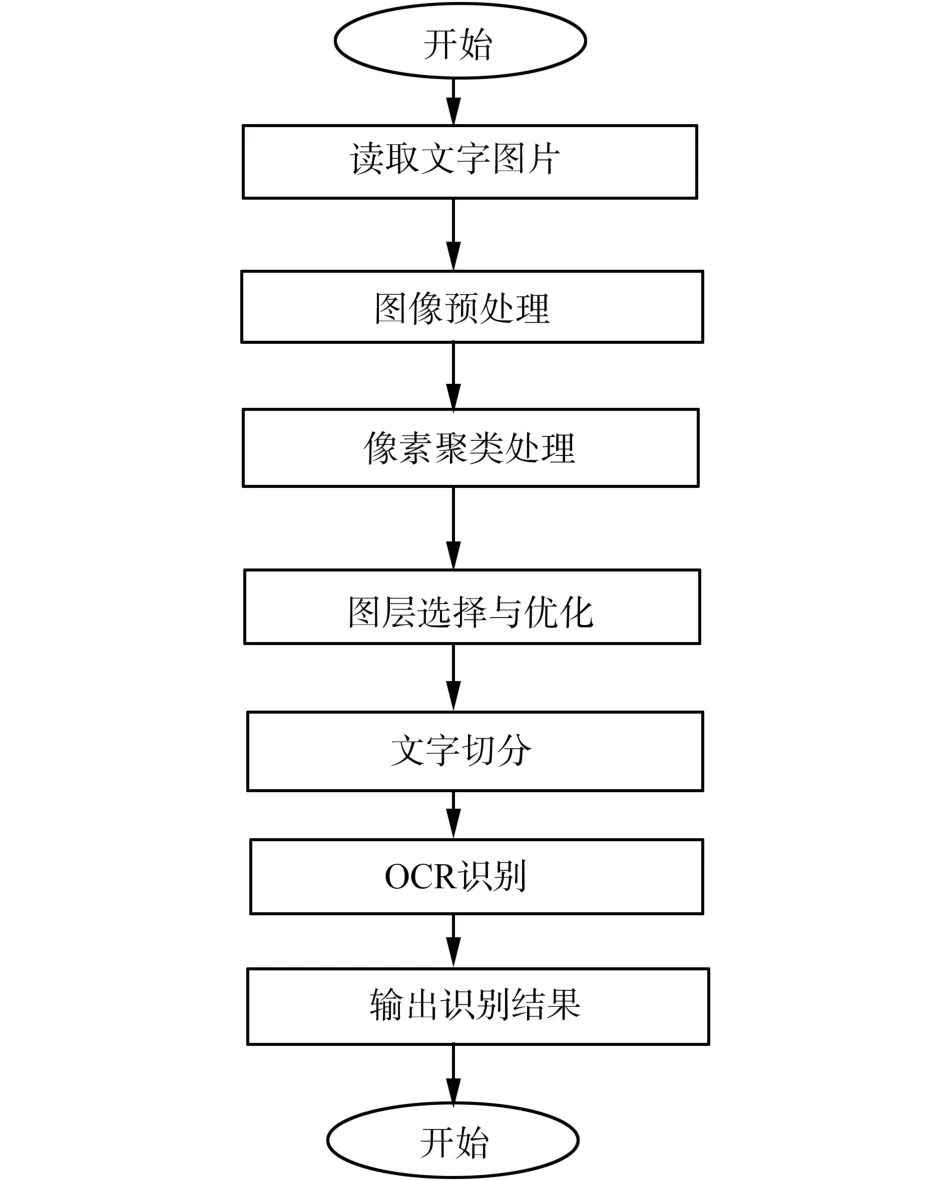
图3 图像文字识别软件实现流程图
图像文字识别软件的运行界面如图4所示。
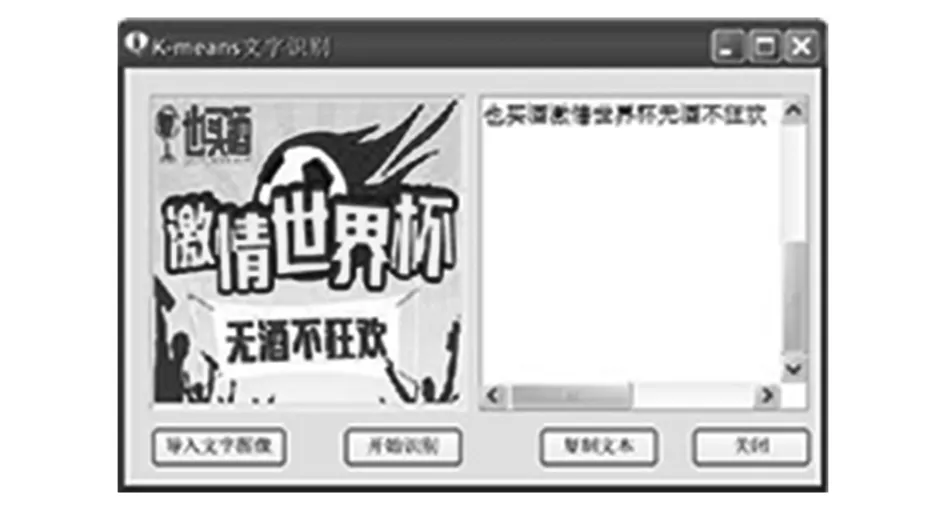
图4 图像文字识别软件运行界面
2种算法对文字识别软件的识别效果测试结果如表1、2所示。从表中可以看出,本文提出的文字提取与识别算法对数字图像中的文字区域定位比较准确,高于BP神经网络的识别算法,在图像文字排列比较复杂的情况下,算法的定位准确度依然保持在95%以上,而BP神经网络明显低于本文提出的算法。

表1 K-means图像文字识别软件测试效果

表2 BP神经网络图像文字识别软件测试效果
4 结束语
通过对K-means聚类算法进行考察与分析,并结合数字图像的灰度处理、二值化、边缘检测等技术,设计了一个基于聚类的图像文字识别与提取算法。通过与BP神经网络识别算法的对比验证得出,该算法能够很好地对复杂数字图像背景中的文字区域进行定位与提取操作,并得到能够被OCR进行识别的图像文字,具有比较高的执行效率与准确度。
[1]杨春蓉,赵小勇.利用改进的最优聚类算法边缘提取方法研究[J].计算机应用与软件,2012(12):54-58.
[2]RAMAN M,AGGARWALH.Study and comparison of vari-ous image edge detection techniques[J].International Jour-nal of Image Processing,2009(2):113-118.
[3]王景中,胡贝贝.归一化算法在文字识别系统中的应用研究[J].计算机应用与软件,2011(3):22-24.
[4]阎少宏,彭亚绵,杨爱民,等.LLE算法及其在手写文字识别中的应用[J].河北联合大学学报:自然科学版,2012(2):49-53.
[5]种耀华.基于NSCT图像文字信息提取新方法[J].计算机应用,2012(2):182-185.
[6]常莹.基于聚类与边缘检测的自然场景文本提取方法[J].计算机工程与设计,2010(18):33-36.
[7]胡石根,陆以勤.汉字联机手写识别系统的设计与实现[J].计算机仿真,2010(9):77-79.
[8]MANSHENG X,X M,MANSHENG X,et al.A property optimization method in support of approximately duplicated records detecting[C]//IEEE International Conference on Intelligent Computing and Intelligent Systems.[S.l.],2009:118-122.
[9]胡广,李娟,黄本雄.结合空间信息的模糊C均值聚类图像分割算法[J].计算机与数字工程,2008(4):29-32.
[10]刘小丹,牛少敏.一种改进的K-means聚类彩色图像分割方法[J].湘潭大学自然科学学报,2012(2):47-51.
[11]GATOSB,PRATIKAKIS I,PERANTONISS J.Adaptive degraded document image binarization[C]//Computation-al Intelligence Laboratory,Institute of Informatics and Tel-ecommunications,National Center for Scientific Research “Demokritos”.Athens,Greece.2006:327-329.
Research on the recognition and extraction of image characters based on K-means
YUE Jianjie,ZHAO Danfeng
College of Information and Communication Engineering,Harbin Engineering University,Harbin 150001,China
Based on the latest developments in the recognition and extraction of image characters,this paper propo-ses a K-means-based algorithm for the recognition and extraction of image text.Itsmain processing steps include im-age preprocessing,pixel clustering process,selection and optimization of the layer and the final text segmentation.By computer testing,itwas found that the algorithm can effectively improve the accuracy and efficiency of recogni-tion and extraction of image characters.In addition,it can effectively identify image characters under differentenvi-ronments.
K-means;extraction of image text;character recognition;binarization
TN971.1
A
1009-671X(2015)02-017-04
10.3969/j.issn.1009-671X.201406014
2014-06-19.
日期:2015-03-25.
黑龙江省科技攻关计划资助项目(GC12A305).
岳建杰(1986-),男,硕士研究生;
赵旦峰(1961-),男,教授,博士生导师.
岳建杰,E-mail:348274742@qq.com.
http://www.cnki.net/kcms/detail/23.1191.u.20150325.1256.009.html
