改进的贝叶斯分类方法在电信客户流失中的研究与应用
2015-05-10滕少华
杨 婷,滕少华
(广东工业大学 计算机学院,广东 广州 510006)
改进的贝叶斯分类方法在电信客户流失中的研究与应用
杨 婷,滕少华
(广东工业大学 计算机学院,广东 广州 510006)
随着电信市场竞争日益加剧,客户流失成为运营商关注的焦点问题之一.针对电信数据量庞大且有时间序列的特点,提出一种改进的贝叶斯分类方法来研究电信客户流失问题,通过对不同属性加权改进了朴素贝叶斯分类器默认每个属性对分类结果影响相同的假设,进一步探讨了应用增量学习方法来应对不断增加的数据,以改善分类器的准确率.实验结果表明,本文的方法有较高的准确率.
贝叶斯分类; 电信数据; 增量学习; 客户流失; 预测
随着中国电信业的飞速发展和市场竞争加剧,电信产品及服务模式愈加丰富,用户对产品与服务模式的选择更多,客户保持变得越来越困难.此外,获得一个新客户比保持原有客户要有更大的开销且不一定会产生更高的效益.因此保持原有客户,防止客户流失越显重要.
客户流失预测就是通过对客户基本信息与历史行为等数据进行深入分析,提炼出已流失客户在流失前具有的特征或行为,建立客户流失预测模型.通过模型来预测企业近期内将可能流失的客户,反馈一个流失预测名单给企业,为企业有针对性开展业务来预防或减少客户流失提供参考.
本文基于某电信企业的客户实际通信数据进行深入分析,利用朴素贝叶斯分类器具有计算量少、准确度高、以概率论为理论基础的特点[1],结合增量学习方法,构建一个改进的贝叶斯分类器,研究客户流失问题,探讨并预测客户流失情况.
1 贝叶斯分类器
1.1 贝叶斯分类原理
假设数据集为D,其属性集为:U={A1,A2,…,An,C},其中A1,A2,…,An是样本的属性变量,C是有m个值C1,C2,…,Cm的类标号属性变量.数据集D中的每个样本X可以表示为X={x1,x2,…,xn,Cj},x1,x2,…,xn分别是A1,A2,…,An的n个取值,而Cj是所属类的类标号值.
给定一个类标号未知的样本X,朴素贝叶斯分类将预测X属于具有最大后验概率P(Cj|X)的类,即[2]:
P(Cj|X) = arg maxP(Cj|X)=

(1)
分母P(X)为常数,根据贝叶斯公式和朴素贝叶斯类条件独立性,得到朴素贝叶斯分类模型[2]:

(2)
1.2 加权朴素贝叶斯
由于各条件属性对分类结果的重要性是不同的,因此,在实际应用时需要改正朴素贝叶斯条件独立性的假设,将其扩展为加权朴素贝叶斯.对朴素贝叶斯分类法加权,已有许多研究,Harry和Sheng[3]提出了根据属性的重要性给不同属性赋权值的加权朴素贝叶斯分类器;贾娴等[4]提出了通过提取特征冗余度判别函数来为不同属性赋权值的方法;杨敏等[5]提出了一种基于属性约简的偏最小二乘回归加权朴素贝叶斯分类算法,对不同条件属性赋权值;Dong等[6]给出了基于粗糙集的属性加权方法,文献[7-8]也改进了朴素贝叶斯分类算法.上述方法结合具体应用,扩展了贝叶斯的应用范围.有鉴于此,本文通过信息增益来为分类属性赋权值.
信息增益(Information Gain,IG)是信息论中一个重要概念,在IG中,重要性的度量标准就是看属性能够为分类系统带来的信息量的大小,值越大,说明其包含的信息量也越大.属性A给分类C带来的信息增益为
Gain(A) =H(C) -H(C|A),
(3)
其中,
(4)
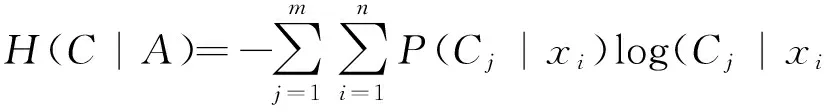
(5)
式(4)中,H(C)是类C的熵,m是类C取值个数,P(Cj)是样本中属于类Cj的概率.
式(5)中H(C|A)是属性A确定时的条件熵,n为属性A取值个数,P(Cj|xi)是属性A取值xi的条件下分类为Cj的概率.
Gain(A) 就是从特征A上获得该划分的IG,它越大,表示该特征在给定记录集中具有的区分度越大,对分类越重要.
通过计算每个特征属性的信息增益Gain(Ak),得到每个特征属性的权重为
(6)
则加权后贝叶斯分类模型变为
(7)
2 电信数据预处理
在数据分析之前,需要将原始数据集进行预处理,包括数据清洗、数据集成、数据转换和数据归约,以删除噪声数据,解决数据不一致的现象等,以下是本文针对电信数据的预处理过程.
2.1 客户样本数据整理
客户样本数据集中包含客户的类型、通话级别、月消费额等属性,如果数据特征的有效值少于总记录数据的1/5时,则删除此类特征;如果某记录中存在大量空缺值,而这些空缺值难以以正常方法给予补全,则删除此类记录.
2.2 客户数据的集成与概化
由于数据集中缺少一些直接体现客户价值和客户流失倾向的特征,本文从时间维度对数据进行了概化,构造了以下特征:
(1) 季度总费用:连续的12个月,分为4个季度,计算每个季度的汇总费用.
(2) 月消费比率:指下一个月与上一个月的总费用比值.根据这一原理可构造11个月消费比率特征.用符号可表示为:
ratei= total_feei+1/total_feei,(1≤i≤11).
(3) 根据客户在一个年度内的消费情况可构造未消费月份数,此特征可反映样本客户消费情况及流失情况.对于原始数据集中连续10、11或12个月都没有消费的客户数据,当作该客户已流失,在本文中不考虑他们,这部分数据予以删除.
2.3 数据属性选择
为了便于分析,通过计算各个属性与类属性的互信息并结合专家意见删除不相关或冗余的属性以减小数据集,减少样本的维数,降低时间和空间复杂度,简化学习模型.通过数据预处理后,得到构建朴素贝叶斯的特征属性,如表1所示.

表1 特征属性表
3 改进的贝叶斯分类器
本文首先应用贝叶斯算法计算先验概率与类条件概率;再通过信息增益确定各个特征属性的权重;最后,为避免初始样本覆盖范围不全并考虑到未来的数据随时间不断变化的情况,通过批量加入新数据,采用增量学习来修正分类器的各个参数,使分类器不断改进,具体描述如下.
3.1 分类器体系结构
改进的贝叶斯分类器由数据收集、数据预处理、贝叶斯建模、加权学习、增量学习等过程组成,如图1所示.

图1 分类器体系结构
数据预处理参见第2部分,其他部分描述如下.
3.2 贝叶斯建模
(1) 先验概率.
一般地,对于绝大多数电信企业来说,正常客户与流失客户的分布是不平衡的,每月流失的客户总是少数,而正常客户占绝大多数.通过数据统计分析发现,正常客户与流失客户的比例大概为4∶1,从而得出类先验概率.假设类属性描述为C={0,1},其中,C=0表示流失客户,C=1表示正常客户,则流失客户的先验概率P(C=0)=0.2,正常客户的先验概率P(C=1)=0.8.
(2) 类条件概率.
针对电信数据集,从用户消费行为中可以获知该用户是否流失,如连续若干个月没有消费的用户,很可能已流失;月消费从多到少的用户也可能会流失;而月消费从少到多的用户,则其流失的可能性比较小.由于用户每天的通话情况变化较大、每月电话的使用也会有较大的波动,本文采用按季度汇总数据,获取数据的趋势来进行分析.针对样本中连续属性,通过统计分析发现,其分布类似于正态分布,所以用正态分布来估计其类条件概率.该分布有2个参数,均值μ和方差σ2,类别Cj下连续属性xk的类条件概率等于[1]
(8)
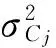
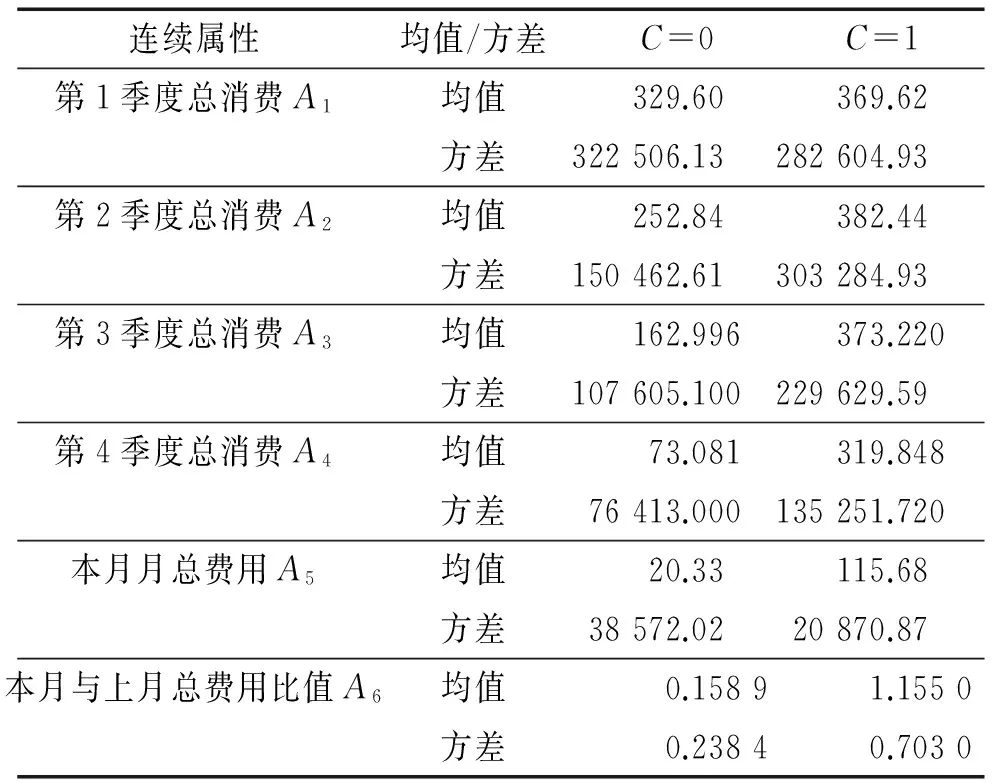
表2 连续属性的均值和方差
对于离散属性,在后验概率计算过程中,当有一个属性的条件概率等于0,则整个类的后验概率都等于0,简单地使用记录比例来估计类条件概率的方法显得太脆弱,为避免这一问题,条件概率为0时一般采用Laplace估计来解决这个问题.类别Cj下离散属性xk的类条件概率计算公式如式(9),最终得出的类条件概率如表3、4、5所示.
(9)
其中,v是Ak取值的个数.
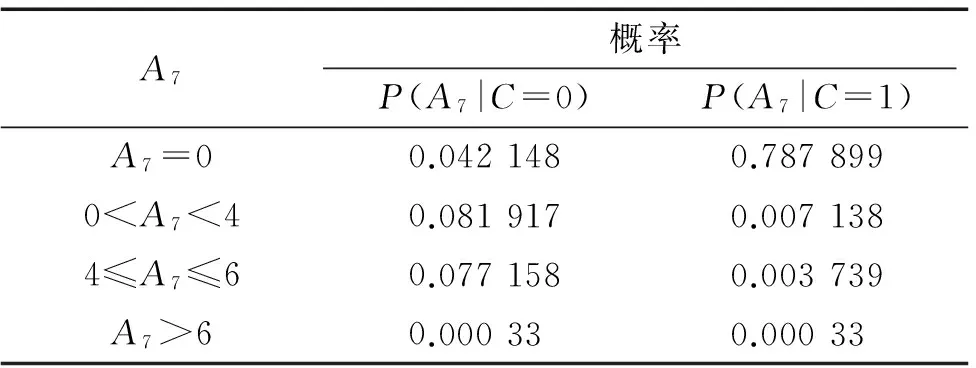
表3 未消费月数的类条件概率表
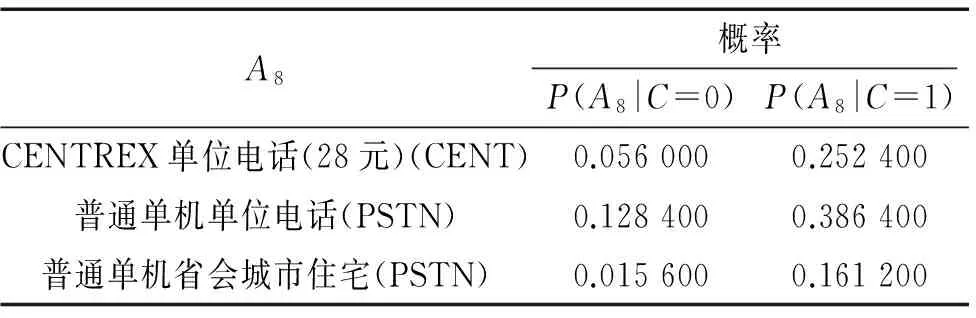
表4 客户类型的类条件概率表
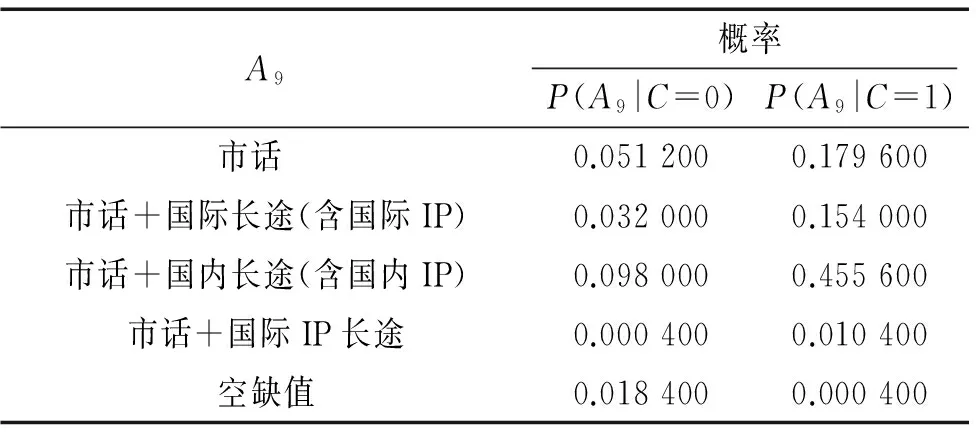
表5 通话级别的类条件概率表
(3) 信息增益加权.
利用1.2小节中式(6),通过计算每个特征属性的信息增益Gain(Ak),得到每个特征属性的权重Wk,如表6所示.
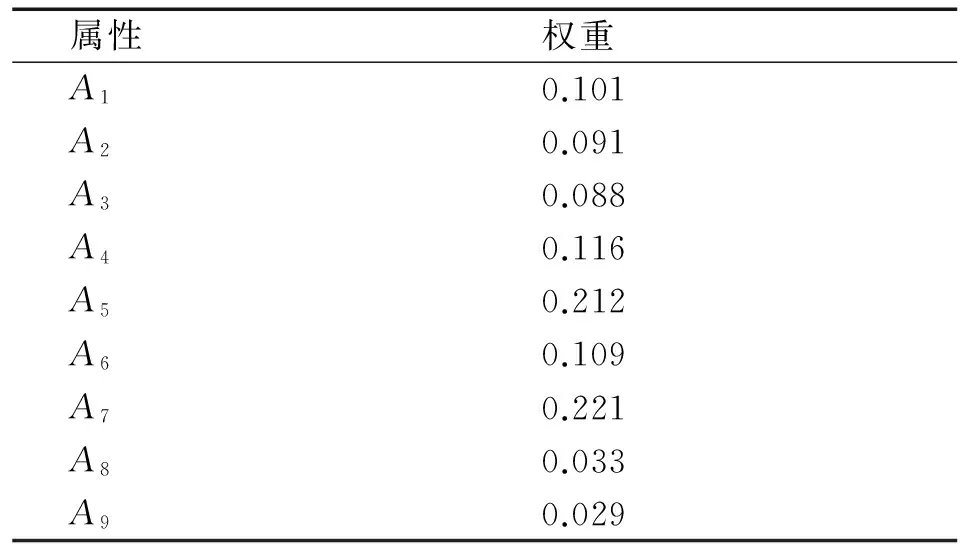
表6 各个属性的权值
3.3 加权分类器构造
在构造分类器前,将收集到的数据分为训练集D、候选增量学习样本集D1、D2、D3及测试集T5部分,由训练集构造分类模型,最后由测试集检验模型分类的准确度.分类器的构造过程如下:
Step1:数据收集.本文以某电信公司部分客户一年来的业务数据作为实验数据[2],该数据集包含了156 810条记录,每条记录X都包含客户基本特征和客户行为特征以及一个类标号特征.
Step2:数据预处理.通过数据清洗、数据集成、数据归约后,形成如表1所示的可用于构建朴素贝叶斯分类器的特征属性数据.D、D1、D2、D3,T所占比重分别为 30%、 10%、 10%、 10%、40%.
Step3:对训练集D,计算类先验概率和类条件概率.
Step4:对训练集D,根据式(6),计算每个属性的权重.
Step5:根据各个参数,构造加权分类器.
Step6:对测试集T,由式(7),计算每个测试数据的概率,将每个测试数据X分类为概率Pi最大的那个类,获得测试数据集的分类.
Step7:比较模型分类结果与测试数据的类属性,计算分类准确率.
3.4 增量学习
对数据分类,一般的方法是将所有训练数据记录一次读入内存,但当数据量非常大或者数据是分批获得时,这些传统的方法就显示出局限性了,增量式学习是解决此问题的有效途径,它能充分利用先验信息和样本信息求解此类问题[9-14].但是,电信数据量庞大,很多属性的值因增量数据可能会变动且数据都有一定的时效性,新的数据随时间不断产生,原训练集的价值可能会越来越小,导致构造的分类器准确率会有所下降,所以本文增加一个增量学习模块,通过加入新的有价值的数据来修改已构造分类器的部分参数,从而有效提高分类准确率.
(1) 增量学习.
本文增量学习思路是:针对候选样本集,用已构建好的加权贝叶斯分类模型对其进行分类,针对每一个候选样本,分类结果分2种情况.第1种情况,此样本分类正确,则对此类样本不作任何处理.第2种情况,该样本未流失但分类结果显示流失,这存在两种可能,一是分类结果出错,这时需要用增量数据修正分类模型,可通过模型重构等方法解决;二是由于客户各种原因(诸如较长时间停用等)导致无通信数据,这时仍需要通过增量数据修正模型,以提高分类准确率.
(2) 修正分类器参数.
假设训练集为D,样本X′为增量数据.当将样本X′={x1,x2,…,xn,C′}加入到训练集D时,要重新计算类先验概率和类条件概率,根据Dirichlet先验分布特性,类先验概率和类条件概率修正方法如式(10)、(11)[9].
(10)
其中,δ是类标签个数与训练集样本数之和,j是类的个数,j=1,2,…m.
(11)
其中,ζ是Ai取值个数与训练集中类Cj的个数之和.
由于新样本X′的加入,使训练集中加入了新的样本数据,类先验概率和类条件概率都发生了变化.通过分析式(10)和(11)可知,X′的加入,只改变了与它相关项的概率,仅需进行局部修改.
(3) 修正权值.
对新增加的候选样本集用1.2节信息增益方法,求各个属性的权值Wk-2,k=1, 2,…,n,然后和原训练集求得的权值通过整合得到新的权值.
Wk-new=αWk+βWk-2,
(12)
其中,α+β=1,α和β是两个参数,用来设置训练集和候选样本集的权重.
(4) 改进的贝叶斯算法.
算法描述如下:
Input:分类器C,候选增量样本集D1,分类错误的样本集S=Ø;
Output:分类器C-new.
Step1:对候选样本集D1中每个样本进行分类,把分类错误的样本保存入S;
Step2:whileS≠Ø,对S中每个样本利用式(10)、(11)重新计算类先验概率和类条件概率;
Step3:对分类错误的样本集S,利用式(6)计算各个属性的权值,利用式(12)得到修正后的权值;
Step4:更新分类器C的各个参数,得到新的分类器C-new.
Step5:对测试集T,由式(7),计算每个测试数据的概率,将每个测试数据X分类为概率Pi最大的那个类,获得测试数据集的分类.
Step6:比较模型分类结果与测试数据的类属性,重新计算分类准确率.
4 实验及结果分析
为了验证算法的有效性,利用UCI机器学习数据库中Abalone 、Car Evaluation、Heart数据集[15]和电信行业的客户数据对算法进行检验,分别求出对应的朴素贝叶斯分类准确率、加权贝叶斯分类准确率和改进的增量学习贝叶斯分类准确率,并进行对比,结果见表7.
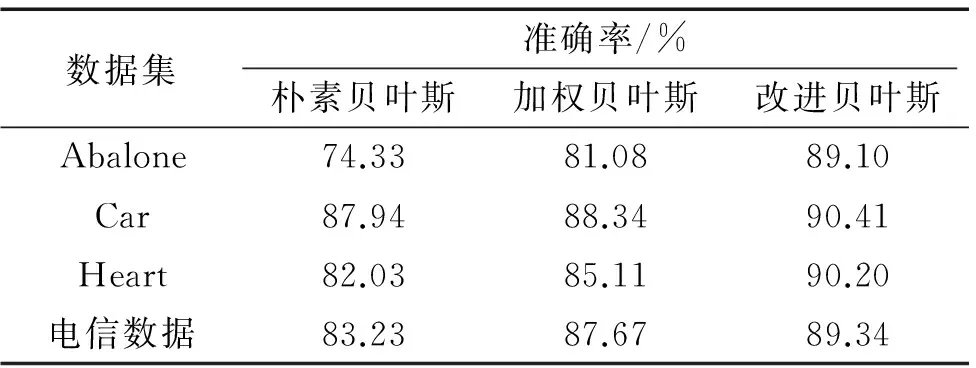
表7 几种分类器准确率对比
从表7可知,加权贝叶斯分类法优于朴素贝叶斯分类器;而通过增量学习修正贝叶斯分类器参数后的贝叶斯分类法又优于加权贝叶斯分类法.它进一步提高了分类准确率.本文中的α=0.65、β=0.35,它们是由多次实验获得.
针对Car和Heart数据集,本文算法实验结果与文献[5]采用方法的实验结果进行对比,结果如表8所示.

表8 与其他算法的准确率比较
另外,本文增量学习过程中得到的实验结果见表9.

表9 本文增量学习过程中的实验结果
从图2中可知,随着对候选样本集进行增量学习,分类准确率越来越高.
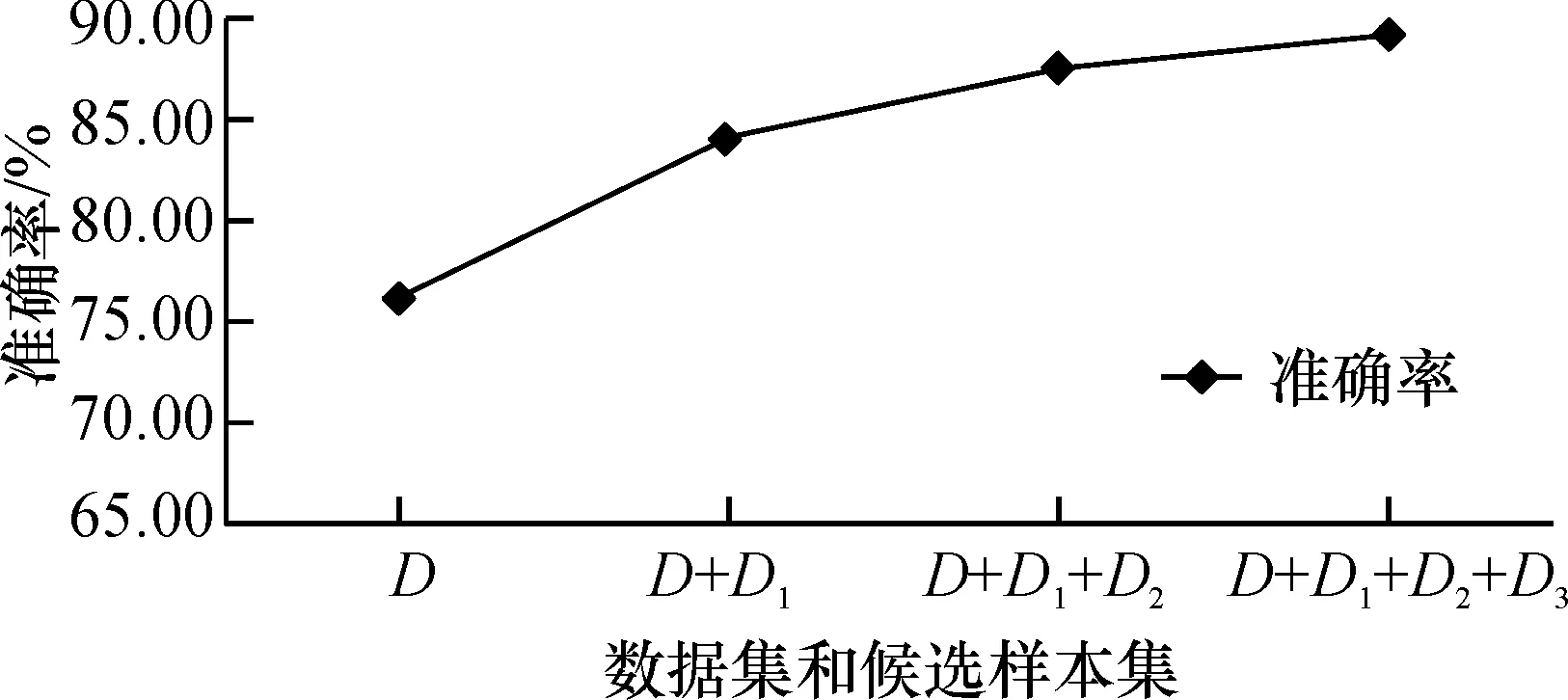
图2 增量学习过程准确率变化图
5 结束语
以开源数据集及某电信公司部分客户一年来的业务数据作为实验数据[2],引入按月/季度汇总数据,获取数据的趋势来进行分析,选择合适的特征属性,通过信息增益法对特征属性赋权值,构建一个加权朴素贝叶斯分类器,并对其进行增量学习,提高了预测客户流失的精度.经该电信公司确认,本文的方法能够更好地把握客户流失倾向,及时采取有效的挽留措施,降低客户流失概率,这为运营商提供了有效的决策支持.
[1] Jiang L X,Zhang H , Cai Z H.A novel bayes model :hidden naïve bayes [J]. IEEE Transactions on Knowledge and Data Engineering(TKDE),2009, 21(10):1361-1371.
[2] 蒋盛益,李霞,郑琪.数据挖掘原理与实践[M].北京:电子工业出版社.2013.
[3] Harry Z, Sheng S L. Learning weighted naive bays with accurate ranking[C]∥Proceedings of the 4th IEEE International Conference on Data Mining(ICDM 04), Brighton, UK: [s.n.], 2004:567-570.
[4] 贾娴,刘培玉,公伟.基于改进属性加权的朴素贝叶斯入侵取证研究[J].计算机工程与应用,2013,49(7):81-84.
Jia X,Liu P Y,Gong W. Research of intrusion forensics based on improved attribute weighted naive Bayes[J]. Computer Engineering and Applications, 2013,49(7):81-84.
[5] 杨敏,贺兴时,刘平丽,等.基于属性约简的PLS加权朴素贝叶斯分类器[J].西安工程大学学报,2013,27(1):118-121.
Yang M,He X S,Liu P L. Weighted naive Bayes classifier based on attribute reduction-PLS[J]. Journal of Xi'an Polytechnic University , 2013, 27(1): 118-121.
[6] Dong W B,Wang G Y, Wang Y. Weighted naive Bayesian classification algorithm based on rough set[J].Computer Science,2007, 34(2): 204-206.
[7] 宫秀军,孙建平,史忠植.主动贝叶斯网络分类器[J].计算机研究与发展,2002,39(5):574-579.
Gong X J,Sun J P,Shi Z Z. An active Bayes network classifier[J]. Computer Research and Development, 2002,39(5):574-579.
[8] Yager R. An extension of the naive Bayesian classifier[J].Information Sciences,2006, 176(5): 577- 588.
[9] 宫秀军,刘少辉,史忠植.一种增量贝叶斯分类模型[J].计算机学报,2002,25(6):645-650.
Gong X J,Liu S H,Shi Z Z. An incremental Bayes classification model[J]. Chinese Journal of Computers, 2002,25(6):645-650.
[10] 秦锋,任诗流,程泽凯,等.基于属性加权的朴素贝叶斯分类算法[J].计算机工程与应用,2008,44(6):107-109.
Qin F,Ren S L,Cheng Z K,et al. Attribute weighted Naive Bayes classification[J]. Computer Engineering and Applications, 2008,44(6):107-109.
[11] 陈亮,郑宁,郭艳华,等.朴素贝叶斯增量学习在病毒上的报分析中的应用[J].计算机应用与软件,2010,27(1):92-95.
Chen L, Zheng N, Guo Y H,et al. Appliying nive Bayesian incremental learning in virus reporting and analysing[J]. Computer Applications and Software, 2010, 27(1): 92-95.
[12] 张全新,郑建军,牛振东,等.贝叶斯分类器集成的增量学习方法[J].北京理工大学学报,2008,28(5):397-400.
Zhang Q X, Zheng J J, Niu Z D,et al.Increment learning algorithm based on Bayesian classifier integration[J].Transactions of Beijing Institute of Technology,2008,28(5):397-400.
[13] 余承依.基于贝叶斯增量分类的邮件过滤研究[J].科学技术与工程.2009,9(9):2556-2561.
Yu C Y.Research of mail filtering based on bayesian incremental classification[J].Science Technology and Engineering, 2009,9(9):2556-2561.
[14] 罗福星.增量学习朴素贝叶斯中文分类系统的研究[D].长沙: 中南大学软件学院,2008.
[15] University of California, Irvine. UCI Machine Learning Repository [DB/OL].[2014-12-05].http:∥archive.ics.uci.edu/ml/.
Research and Application of Improved Bayes Algorithm for the Telecommunication Customer Churn
Yang Ting, Teng Shao-hua
(School of Computers, Guangdong University of Technology, Guangzhou 510006, China)
With the increasing competition of telecom market, customer churn became one of the focused problems. Because the telecommunication data is huge and has the characteristic of time series, this paper proposes an improved Bayesian classification to study the customer churn problem. The improved Bayesian classification model is designed to make up for the shortcomings of the former Bayes which assumed that each attribute has the same effect on the classification results. Furthermore, by coping with the increasing data, this paper explores the incremental learning method to improve the accuracy of the classifier. The experimental results show that the proposed method has higher accuracy.
Bayesian classification; telecommunication data; incremental learning method; customer churn; prediction
2014- 03- 13
教育部重点实验室基金资助项目(110411);广东省自然科学基金资助项目(10451009001004804,9151009001000007);广东省科技计划项目(2012B091000173,2013B090200017,2013B010401029,2013B010401034);广州市科技计划项目(2012J5100054, 2013J4500028)
杨 婷(1990-),女,硕士研究生,主要研究方向为数据挖掘.
10.3969/j.issn.1007- 7162.2015.03.013
TP393
A
1007-7162(2015)03- 0067- 06
