基于LDA+kernel-KNNFLC的语音情感识别方法
2015-05-06张昕然徐新洲
张昕然 查 诚 徐新洲 宋 鹏 赵 力
(1东南大学水声信号处理教育部重点实验室,南京210096)(2东南大学信息科学与工程学院,南京210096)(3东南大学儿童发展与学习科学教育部重点实验室,南京210096)
基于LDA+kernel-KNNFLC的语音情感识别方法
张昕然1,2查 诚1徐新洲1宋 鹏3赵 力1,2
(1东南大学水声信号处理教育部重点实验室,南京210096)(2东南大学信息科学与工程学院,南京210096)(3东南大学儿童发展与学习科学教育部重点实验室,南京210096)
结合K近邻、核学习方法、特征线重心法和LDA算法,提出了用于情感识别的LDA+kernel-KNNFLC方法.首先针对先验样本特征造成的计算量庞大问题,采用重心准则学习样本距离,改进了核学习的K近邻方法;然后加入LDA对情感特征向量进行优化,在避免维度冗余的情况下,更好地保证了情感信息识别的稳定性.最后,通过对特征空间再学习,结合LDA的kernel-KNNFLC方法优化了情感特征向量的类间区分度,适合于语音情感识别.对包含120维全局统计特征的语音情感数据库进行仿真实验,对降维方案、情感分类器和维度参数进行了多组对比分析.结果表明,LDA+kernel-KNNFLC方法在同等条件下性能提升效果最显著.
语音情感识别;K近邻;核学习;特征重心线;线性判别分析
由于语音情感识别(speech emotion recognition,SER)融合模式识别、机器学习以及语音信号等领域,因而得到了广泛的研究.相比情感特征提取和语音数据库分析领域的大量研究,对语音情感识别性能方面的关注度偏少.
近年来在情感计算领域,包括重回归分析和主元素分析等多变量解析方法神经网络技术,都取得了一定的进展[1],但由于情感特征学习收敛性问题,还存在一定的局限性.另外,采用主元分析法、最大似然贝叶斯分类器和K最近邻分类器、人工神经元网络、隐马尔科夫模型[2-3]等技术的情感计算方法,也取得了一定的成果.
语音情感识别中的K近邻分类法(K-nearest neighbor,KNN)因其易于实现而被作为常用的分类器.但是其识别性能在很大程度上依赖于语音情感特征数据库的表征能力.因此,文献[4-5]提出最近特征线(nearest neighbor feature line centroid,NNFLC)的识别方法来扩展样本的表征能力.先提取出样本的低维特征,然后用同一个类中的2个样本特征点得到一条直线,用此直线来描述2个样本点间的特征变化,从而扩展样本的表征能力,取得了较好的识别结果.文献[6-7]提出的核学习方法,可将原空间的待分类样本映射到一个高维的特征空间(核空间).该方法利用核学习思想和结合K近邻分类方法,通过非线性映射来突出不同类别的样本特征差异,使得原来线性不可分的样本点在核空间变得更加线性可分(或近似线性可分),从而提高了分类效果.
NNFLC和核学习分类方法虽然在一定程度上提升了语音情感特征的识别性能,然而这些方法存在如下问题:① 这2种分类方法用于语音情感识别,需要先抽取情感数据库的特征作为样本,如果数据量较大则运算效率会大幅降低,难以保证训练样本的有效性.② NNFLC是针对线性变换得到的方法,但在实际语音情感数据中,单用线性变换难以全面地表征人类复杂的情感信息;核学习方法虽然利用高维空间映射保留了情感信息的非线性因子,但同时也加大了数据的冗余量,可能会导致计算量过大甚至“维度灾难”.
针对上述问题,本文提出了将核K近邻与线性判别分析(linear discriminant analysis, LDA)方法相结合,并采用重心准则学习样本距离,从而得到LDA+核K近邻重心(LDA+kernel-KNNFLC)方法.这种方法保留了非线性空间部分的语音情感信息,并同时避免了维度过高造成的计算量问题.其中,LDA保证了更好的情感信息识别稳定性;而核学习通过再生核希尔伯特空间(RKHS)思想[8],尽可能地保留了数据信息;同时,重心准则降低了距离计算的复杂度并解决了特征线失效问题.
1 基于核K近邻特征线重心分类方法
1.1 基于核学习K近邻语音情感识别方法
KNN算法是最近邻算法的推广,其优点是分类速度快、简单易行且属于非参数分类算法,现已广泛应用于模式识别和数据挖掘等各个领域.然而其性能较大依赖于训练样本特征的表征能力.传统K近邻法简单地说就是取未知样本X的K个近邻,按照近邻数目所属类别把x归类[9].即:从N个已知样本中找出的X的K个近邻,若K1,K2,…,Kc分别是K个近邻中属于ω1,ω2,…,ωc类的样本数,则可定义判别函数为
gj(X)=Kii=1,2,…,c
(1)
若
(2)
则得到决策X∈ωj.
但语音情感数据保留高自然度和复杂语义属性,其样本边界往往存在线性不可分或分布为非高斯分布等情况,K近邻法表现出的分类效果较差[10].为了提高分类的效果,克服K近邻法这一缺点,将统计学习理论中的核学习方法(kernel learning)与K近邻法相结合[11],得到基于语音情感识别的kernel-KNN法.
kernel-KNN分类算法的基本思想是:首先利用一个隐式的非线性映射Φ(x),将样本x从输入空间R映射到一个高维的特征空间F中,如
Φ:Rn→F,x→Φ(x)
(3)
映射的目的是突出不同类别样本之间的特征差异,使得样本在特征空间中变得线性可分(或近似线性可分),然后再在这个高维的特征空间中进行传统的K近邻分类.
核学习方法的一个重要特点就是利用核函数取代特征空间的内积运算,因此在计算时无需知道非线性映射函数Φ(x)的形式.样本x,x′映射至特征空间F中的点Φ(x),Φ(x′)的内积为
k(x,x′)≤Φ(x),Φ(x′)≥ΦT(x)Φ(x′)
(4)
式中,k(x,x′)为核函数.
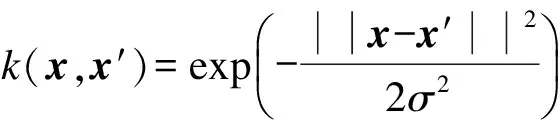
这些函数中应用最广的是RBF核,无论是小样本还是大样本,高维还是低维等,RBF核函数均适用.针对语音情感数据特征,RBF函数相比其他的函数有以下优点:
① RBF核函数可以将一个样本映射到一个更高维的空间,而且线性核函数是RBF的一个特例,而语音情感样本集就包含多种语义信息和特征性质,因此相比线性核函数,RBF更适用于语音情感识别.
② 与多项式核函数相比,RBF需要确定的参数要少,核函数参数的多少直接影响函数的复杂程度.另外,当多项式的阶数比较高时,语音情感样本核矩阵的元素值将趋于无穷大或无穷小,而RBF则具有相对固定的参数,会减少计算情感数据样本数值的困难.
③ 对于需要保留自然度和多种语义的样本参数,RBF比sigmoid具有更好的性能.其映射能力和非线性逼近能力均较强,更加适合大数据量的语音情感识别样本集.
1.2 基于核学习K近邻特征线重心法
图1 特征线示意图
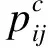
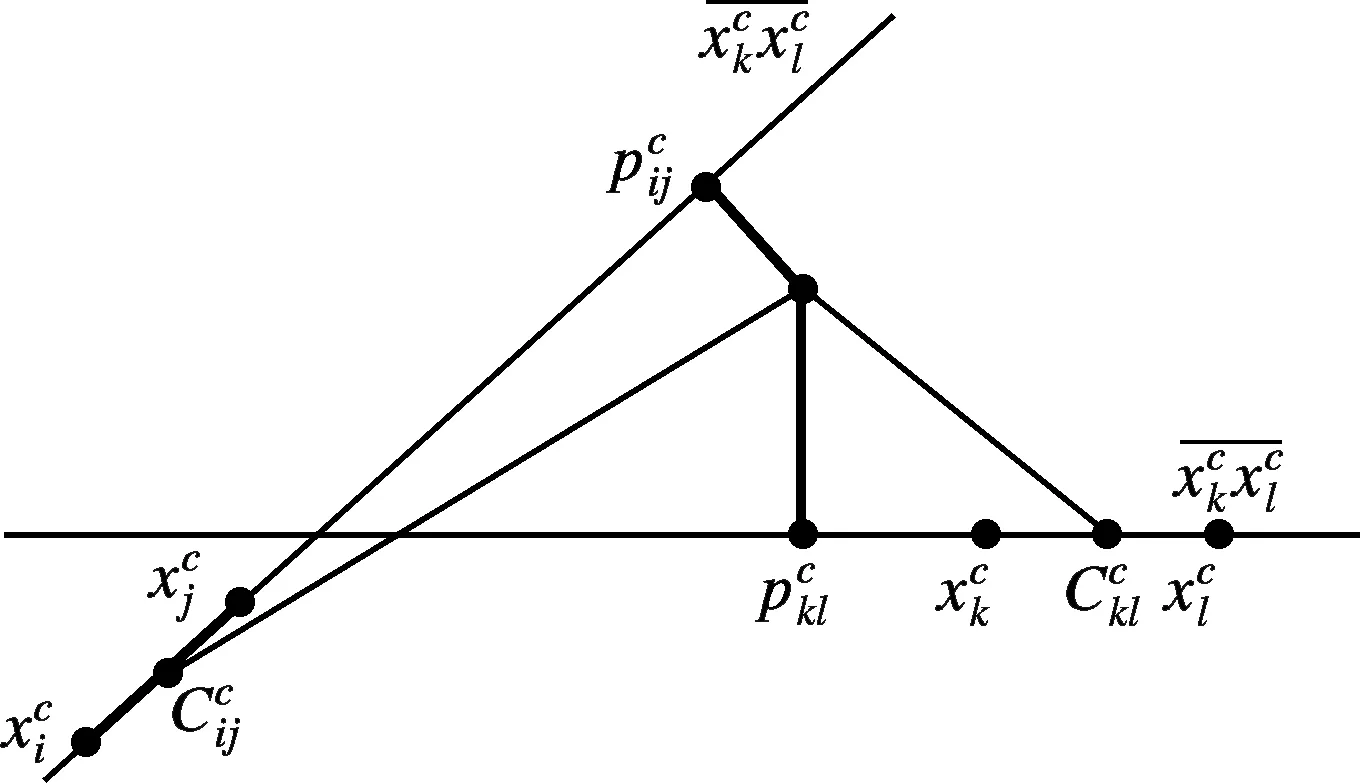
图2 特征线的失效和特征线重心方法示意图
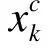
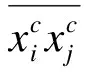
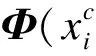
(5)
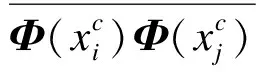
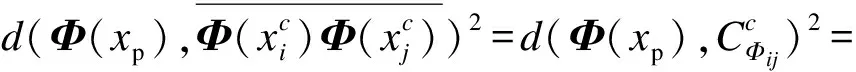
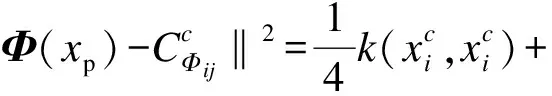
(6)
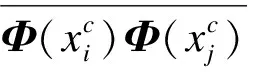
1.3 基于LDA的kernel-KNNFLC语音情感识别方法
LDA的基本思想是将高维的模式样本投影到最佳判别矢量空间,以达到抽取分类信息和压缩特征空间维数的效果,投影后保证模式样本在新的子空间有最大的类间距离和最小的类内距离.利用LDA在该空间中有最佳的可分离性,将语音情感数据样本类间离散度矩阵定义为
(7)
式中,μi为Ci类情感的均值;μ为所有情感样本的均值;Pi为先验概率.
情感样本类内离散度矩阵定义为
(8)
(9)
情感样本类间离散度越大越好,而情感样本类内离散度越小越好.因此如果Sw是非奇异矩阵,最优的投影Wopt就是使得情感样本类间离散度矩阵和情感样本类内离散度矩阵的行列式比值最大的正交特征向量[12].因此,Fisher准则函数定义为
(10)
据此,可以将该问题转化为求Wopt满足如下等式的最优解问题:
SbWi=λiSwWi
(11)
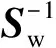
y=WTx
(12)
在使用核函数将情感样本映射到高维的特征空间时,其优点是能够使得在原空间中不易线性可分的数据在高维的特征空间变得线性可分(或近似线性可分).但是由于情感样本被核函数映射到高维空间,使得特征的维数增加,影响识别计算的速度,甚至造成“维数灾难”.同时,本文在仿真实验中提取了120维语音情感特征,这些特征不一定都是最有效的,所以需要进行特征选择.而线性判别分析(LDA)可以有效地进行特征提取,在降低特征维数的同时提高不同类别情感特征之间的区分度.
为验证结合LDA识别方案的区分效果,对语音情感库中的愤怒、烦躁、高兴3种情感特征进行LDA线性判别分析.样本特征降维至2维,经LDA变化后各样本特征在新特征空间的分布如图3所示.由图可见,经过LDA变换后情感特征之间区分度增大,聚类效果明显,进而可以针对5类情感数据进行进一步的实验设计.

图3 LDA变换后样本在特征空间分布图
本文提出将LDA与核KNNFLC结合用于语音情感识别,在识别时先对C类语音情感特征进行LDA线性判别分析,将情感特征降维至C-1维,再使用核学习的KNNFLC方法进行分类识别.LDA+kernel-KNNFLC训练识别步骤如下:
① 对C类训练样本提取出n维情感特征,进行LDA线性判别分析,使用式(11)计算出变换矩阵W,利用式(12)将n维情感特征降维至C-1维,构成样本库.
② 从待识别样本中提取n维情感特征x,由式(12)将n维特征降维至C-1维特征y.
③ 利用式(6)在高维空间中计算出特征y与样本库中每个特征线重心的距离d.
④ 依据K近邻法则将待识别样本归类.
本文提出的LDA+kernel-KNNFLC语音情感识别流程如图4所示.
2 实验结果
实验在实验室录制的语音情感库上进行[13].使用了120个全局统计特征,构成用于识别的情感特征向量.
1) 特征1~4.短时能量最大值、最小值、均值、方差.
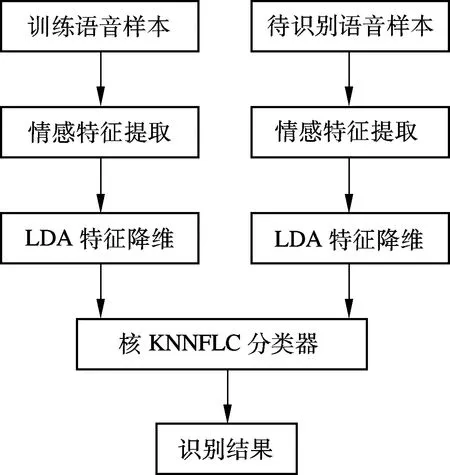
图4 语音情感识别流程图
2) 特征5~8.基音最大值、最小值、均值、方差.
3) 特征9~12.基音一阶差分最大值、最小值、均值、方差.
4) 特征13~16.第一、第二、第三共振峰最大值、最小值、均值、方差.
5) 特征17~68.梅尔倒谱系数MFCC1~MFCC13最大值、最小值、均值、方差.
6) 特征69~120.梅尔倒谱系数MFCC1~MFCC13一阶差分最大值、最小值、均值、方差.
用于实验的样本集包括了愤怒、烦躁、高兴、悲伤和平静5种情感的语句各800条.其中每种情感选600条作为训练样本,另外200条作为待识别样本,而且训练样本和待识别样本中,男女声音样本比例基本为1∶1.提取出语音情感的120维特征,采用全局统计特征原理构成语音情感特征的向量.仿真实验环境为Inter Core i5-2300 2.8 GHz,4 GB内存,Windows 7操作系统,编程环境为Matlab R2011b.
本文分别对KNN,LDA+KNN和LDA+kernel-KNNFLC算法进行了语音情感识别仿真实验,并同时分别使用主成分分析(principal component analysis, PCA)和朴素贝叶斯分类(naive Bayesian classification)对降维部分和情感识别分类部分进行对比实验,测试本文提出的语音情感识别方案的性能.
2.1 3种KNN分类方案情感识别实验分析
针对KNN算法所构建的仿真实验中基于核的非线性分类器均是直接对120维的语音情感矢量进行识别的,而线性分类器均先用LDA抽取主分量特征,所选最优投影Wopt使LDA的重构误差为4%.为消除单次选择样本的随机性,每类随机选取200个样本共1 000个训练样本,剩下的3 000个作为测试样本,重复10次取平均识别率.表1为K近邻、LDA+K近邻以及LDA+kernel-KNNFLC三种方案针对5类情感类别的识别率和平均识别率.
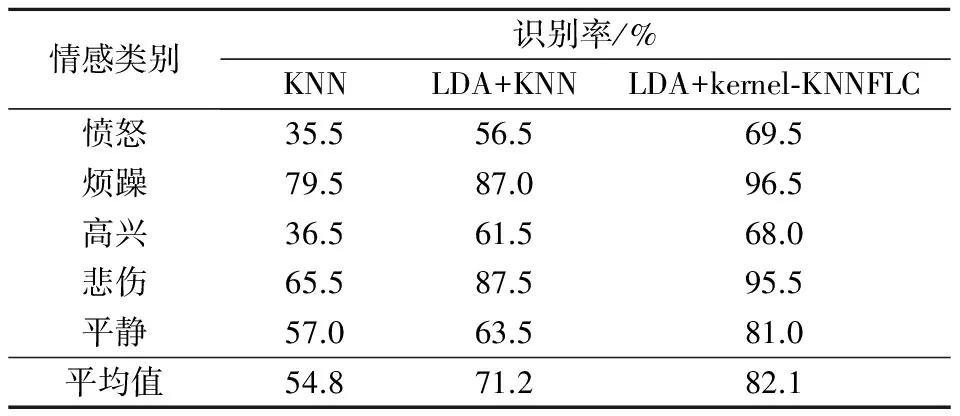
表1 3种语音情感识别方案的识别率
从表1中可以看出,KNN方法对5种情感的识别率普遍较低,平均识别率不到60%,2类情感识别率只有36%左右,效果很不理想.LDA+KNN方法通过对原始特征进行LDA变换,提高了样本特征之间的区分度,识别效果相对于KNN方法有了较大的提高,平均识别率超过70%.LDA+kernel-KNNFLC方法在LDA变换的基础上,利用核学习思想改进了传统的KNN方法,通过引入特征线重心提高了样本特征的表征能力,平均识别率达到了82.1%.
2.2 2种kernel-KNNFLC降维方案情感识别实验分析
采用PCA方法替换LDA对语音情感数据样本进行降维,实验模型采用与上述实验相同的结构,并设置降维后特征空间维数为5,K近邻中临近加权参数设K=3(维度及加权参数的实验分析在LDA+kernel-KNNFLC参数对比实验中进行).对比实验结果如图5所示.
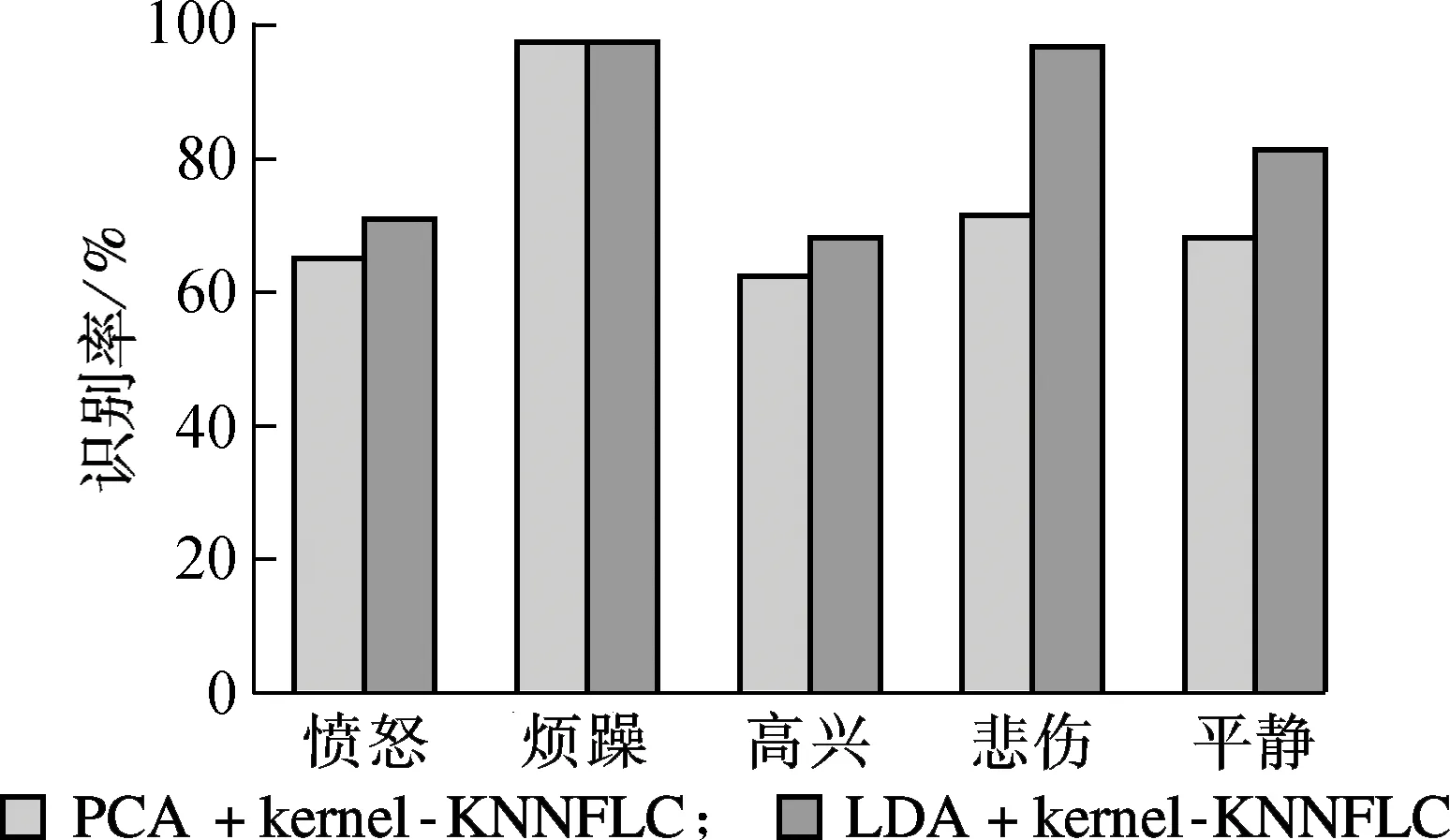
图5 2种方案对5类情感降维识别对比图
由图5中对比实验可以观察到,2种降维方法均采用核学习的K近邻特征线重心分类方法,与KNN和LDA+KNN方法相比,正确识别率有了明显的提升.“烦躁”、“悲伤”和“平静”3种情绪的识别率在70%以上,其中“烦躁”达到了95%以上.对比2种降维方案,在“愤怒”、“高兴”、“悲伤”和“平静”4个情绪类别中,LDA+kernel-KNNFLC方案相比其对照组,语音情感识别率分别提高了4.5%,6.5%,25%和13%.这是由于PCA特征空间的降维优化是以区分5类情感为准则的,因此在同一个特征空间中,就很难兼顾到所有5类语音情感的最佳情感特征.特别地,从图5中可以看出,PCA对“悲伤”的情感特征的优化并不理想.而本文提出的LDA+kernel-KNNFLC方案,利用特征向量间的离散度加权,使得情感特征类间区分度极大化,增加了对语音情感样本集的识别能力.
2.3 kernel-KNNFLC与NB和GMM分类器对比实验分析
本组实验对朴素贝叶斯(naive Bayes, NB)和高斯混合模型(GMM)2种常用的分类器进行实验仿真,识别测试中将LDA降维后与NB,GMM相结合,分析3种不同分类方案的情感识别性能.
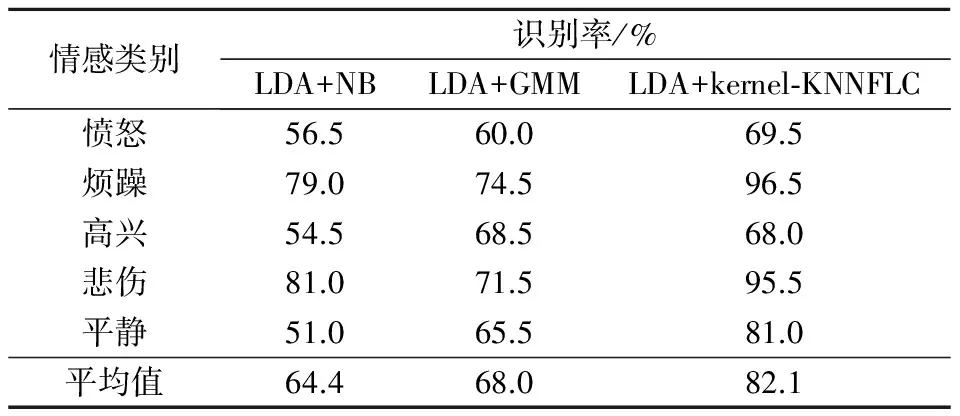
表2 3种语音情感识别分类器的识别率
从表2可以看出,引入LDA降维后,LDA+NB和LDA+GMM分类器比KNN独立识别语音情感,识别率有了一定的提高,但与LDA+kernel-KNNFLC方案相比,还有较大差距.这是由于NB算法有一定的局限性,其假定了特征向量之间是独立分布的,而在语音情感特征空间中的几个特征向量显然不是独立分布的,因而得到的LDA+NB分类器性能就比较有限.而GMM 是一种单状态的混合连续分布隐马尔可夫模型,能够融合含有不同情感的语音在发音时的声学特性和时间上的变动[14].然而在选用GMM 模型进行建模时一般需要比较多的训练数据,当训练数据较少时会影响GMM 模型的学习性能[15].因此相比kernel-KNNFLC方法,其语音情感识别稳定性较差.
2.4 LDA+kernel-KNNFLC方案中参数对比实验分析
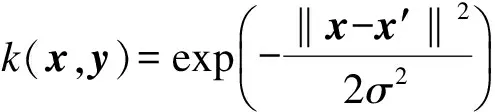
由图6(a)可看出,结合LDA降维算法改进后,基于核的KNNFLC分类器对语音情感识别性能比较稳定,并在维度为4和5时达到最佳效果.这是由于求解广义特征值原理中,求解最小特征数目能达到最优化的目的[16].本文实验采用5类语音情感来进行,因此维度降至4和5,即可达到最佳的识别效果.从图6(b)可以看出,用最近特征线重心方法改进的RBF核函数,在近邻参数K=3时效果达到最佳.
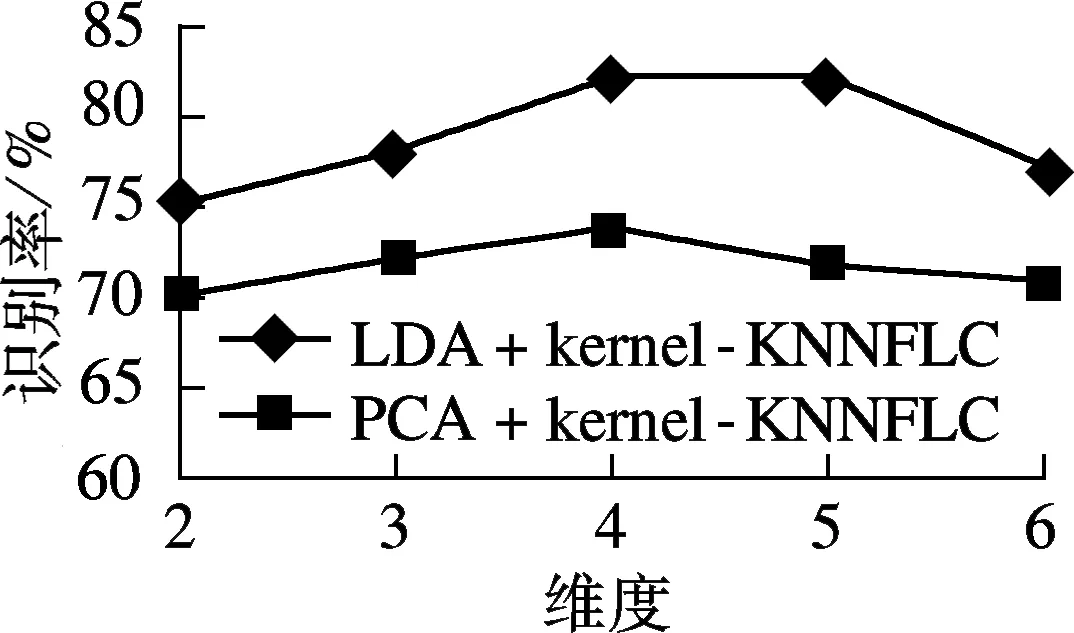
(a) 目标维度
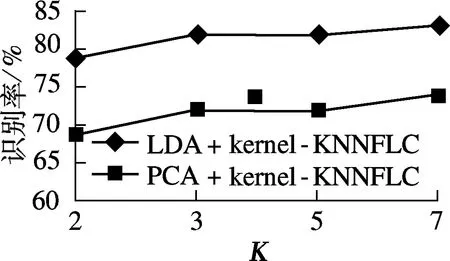
(b) 径向基核函数
3 结语
本文在LDA+KNNFLC方法核学习的基础上,结合LDA降维方法,同时引入了特征线重心对KNN算法进行改进,扩展了样本特征的表征能力,进而提高了分类识别能力.LDA的引入解决了由于核空间维数较高,易造成“维数灾难”影响识别计算速度的问题,提高了不同类别特征之间的区分度.
由对比实验可以看出,结合LDA的核学习K近邻特征线重心的语音情感识别方法,相比其他分类方案具有更好的识别效果;同时,针对5种情感样本集,相较于其他降维方法也具有更稳定的工作性能.分别针对语音情感识别中,预先抽取样本造成的训练数据量过大问题,以及非线性映射和数据冗余的平衡问题进行的方案改进,相比原有几种识别方案改进后的方案体现出明显的优势.
另外根据本文进行的多组仿真对比实验,可以观察出这5种情感中,“烦躁”情感识别率在各个识别方案中都是最高的,而“愤怒”和“高兴”较差,原因主要是后2类情感在发音时,许多生理特征相似,较易混淆,同时本文提取的情感特征对于“烦躁”情感表征更准确.这也说明了在后续的研究工作中,情感特征的优化还有一段提升的空间.
References)
[1]Scherer K R. Vocal communication of emotion: a review of research paradigms[J].SpeechCommunication, 2003, 40(1/2): 227-256.
[2]Scherer K R, Mortillaro M, Mehu M. Understanding the mechanisms underlying the production of facial expression of emotion: a componential perspective[J].EmotionReview, 2013, 5(1): 47-53.
[3]Lin J C, Wu C H, Wei W L. Error weighted semi-coupled hidden Markov model for audio-visual emotion recognition[J].IEEETransactionsonMultimedia, 2012, 14(1):142-156.
[4]Li S Z, Lu J. Face recognition using the nearest feature line method[J].IEEETransactionsonNeuralNetworks, 1999, 10(2): 439-443.
[5]Li S Z. Content-based audio classification and retrieval using the nearest feature line method[J].IEEETransactionsonSpeechandAudioProcessing, 2000, 8(5): 619-625.
[6]Scholkopf B, Smola A, Muller K. Non-linear component analysis as a kernel eigenvalue problem [J].NeuralNetwork, 1999, 9(4): 1299-1319.
[7]Muller K, Mika S, Ratsch G, et al. An introduction to kernel-based learning algorithms[J].IEEETransactionsonNeuralNetworks, 2001, 12(2): 181-201.
[8]Jung A, Schmutzhard S, Hlawatsch F. The RKHS approach to minimum variance estimation revisited: variance bounds, sufficient statistics, and exponential families[J].IEEETransactionsonInformationTheory, 2014, 60(7): 4050-4065.
[10]Wu Chung-Hsien, Liang Wei-Bin. Emotion recognition of affective speech based on multiple classifiers using acoustic-prosodic information and semantic labels[J].IEEETransactionsonAffectiveComputing, 2011, 2(1):10-21.
[11]Zeng Hong, Cheung Yiu-ming. Feature selection and kernel learning for local learning-based clustering[J].IEEETransactionsonPatternAnalysisandMachineIntelligence, 2011, 33(8):1532-1547.
[12]Yan Shuicheng, Xu Dong, Zhang Benyu, et al. Graph embedding and extensions: a general framework for dimensionality reduction[J].IEEETransactionsonPatternAnalysisandMachineIntelligence, 2007, 29(1):40-51.
[13]黄程韦,赵艳,金赟,等. 实用语音情感的特征分析与识别的研究[J]. 电子与信息学报, 2011, 33(1): 112-116. Huang Chengwei,Zhao Yan,Jin Yun, et al. A study on feature analysis and recognition of practical speech emotion[J].JournalofElectronics&InformationTechnology, 2011, 33(1): 112-116.(in Chinese)
[14]Dileep A D, Sekhar C C. GMM-based intermediate matching kernel for classification of varying length patterns of long duration speech using support vector machines[J].IEEETransactionsonNeuralNetworksandLearningSystems, 2014, 25(8): 1421-1432.
[15]Wu Chung-Hsien, Wei Wen-Li, Lin Jen-Chun, et al. Speaking effect removal on emotion recognition from facial expressions based on eigenface conversion[J].IEEETransactionsonMultimedia, 2013, 15(8):1732-1744.
[16]Satapathy S C, Udgata S K, Biswal B N, et al.Speechemotionrecognitionusingregularizeddiscriminantanalysis[M]. Bhubaneswar, Switzerland: Springer International Publishing, 2014: 363-369.
Speech emotion recognition based on LDA+kernel-KNNFLC
Zhang Xinran1,2Zha Cheng1Xu Xinzhou1Song Peng3Zhao Li1,2
(1Key Laboratory of Underwater Acoustic Signal Processing of Ministry of Education, Southeast University, Nanjing 210096, China) (2School of Information Science and Engineering, Southeast University, Nanjing 210096, China) (3Key Laboratory of Child Development and Learning Science of Ministry of Education, Southeast University, Nanjing 210096, China)
Based on KNN (K-nearest neighbor), kernel learning, FLC (feature line centroid) and LDA (linear discriminant analysis) algorithm, the LDA+kernel-KNNFLC method is put forward for emotion recognition according to the characteristics of the speech emotion features. First, in view of the large amount of calculation caused by the prior sample characteristics, the KNN of kernel learning method is improved by learning sample distances with the FLC. Secondly, by adding LDA to emotional feature vectors, the stability of emotional information recognition is ensured and dimensional redundancy is avoided. Finally, by the relearning of feature spaces, LDA+kernel-KNNFLC can optimize the degree of differentiation between emotional feature vectors, which is suitable for speech emotion recognition (SER). An emotional database is used for simulation tests, which contains 120 dimensional global statistical characteristics. Multiple comparison analysis is conducted through the dimension reduction scheme, emotion classifiers and dimension parameters. The results show that the improvement effect for SER by using LDA+kernel-KNNFLC is remarkable under the same conditions.
speech emotion recognition; K-nearest neighbor; kernel learning method; feature line centroid; linear discriminant analysis
2014-09-17. 作者简介: 张昕然(1987—),男,博士生;赵力(联系人),男,博士,教授,博士生导师,zhaoli@seu.edu.cn.
国家自然科学基金资助项目(61273266, 61231002, 61375028)、教育部博士点专项基金资助项目(20110092130004).
张昕然,查诚,徐新洲,等.基于LDA+kernel-KNNFLC的语音情感识别方法[J].东南大学学报:自然科学版,2015,45(1):5-11.
10.3969/j.issn.1001-0505.2015.01.002
TP391.42
A
1001-0505(2015)01-0005-07
