印刷体满文文字数据库的构建与实现
2015-04-21周兴华郑蕊蕊胡艳霞
周兴华,李 敏,郑蕊蕊,许 爽,胡艳霞
(大连民族学院a.计算机科学与工程学院;b.信息与通信工程学院;c.东北少数民族研究院,辽宁大连116605)
清朝统治中国将近300年,作为中华民族的少数民族之一的满族,历史悠久,文化内涵丰富,在中国历史上起着举足轻重的作用。现存的大量满文档案至今已有400多年的历史,由于年限久远,很多历史文献已经不同程度的破损[1]。如何将这些珍贵的文化历史记录转化为可永久保存的电子文档成为当务之急[2]。光学字符识别技术(Optical Character Recognition,OCR)具有将图片中文字翻译成计算机文字的功能,已广泛应用于少数民族文档的数字化保护,是实现满文文档数字化的技术保障[3]。利用光学字符识别技术识别满文,必须以大量的字符样本为基础,因此建设满文文字数据库是研究满文识别方法的必要条件[4]。目前,国内已经建成了蒙文、藏文、维文等少数民族文字库,但满文字库的研究相对较少,还没有一个有影响的满文文字数据库可以为开发满文识别算法提供公共的训练和测试样本,实验结果存在很大差异性,识别结果无法统一比较。因此,建立满文文字数据库是满文识别技术的必要前提。
考虑到满文文字的特殊性,满文文字库的构建与其它字库不同,需要将单词部件作为采集内容,而部件的分割是建库的重点和难点。本文将建库与文字切分联系在一起,提出了一种多级库的构建思想。该库为后续满文识别和特征提取提供有利的保证。对继承和发扬少数民族文化,研究满清历史,保护和传承非物质文化遗产,促进各民族共同繁荣有着十分重要的历史意义[5]。
1 印刷体满文文字数据库的结构
基于满文的特殊性,提出了一种多级数据库的构建思想,满文文字数据库的构建框图如图1。该库包括列文本库、单词库、基元库三个子库。列文本库可用于分析满文的语法结构,单词库可用于基元切割和样本测试训练,基元库可用于后续的特征提取和模式识别等。该数据库的构建以《满文365句》一书为采集内容,书中都是常用的满文高频词汇,大多数高校和研究所都是以该书为教材学习满语,因此以该书为采集内容构建的数据库普适性更强。
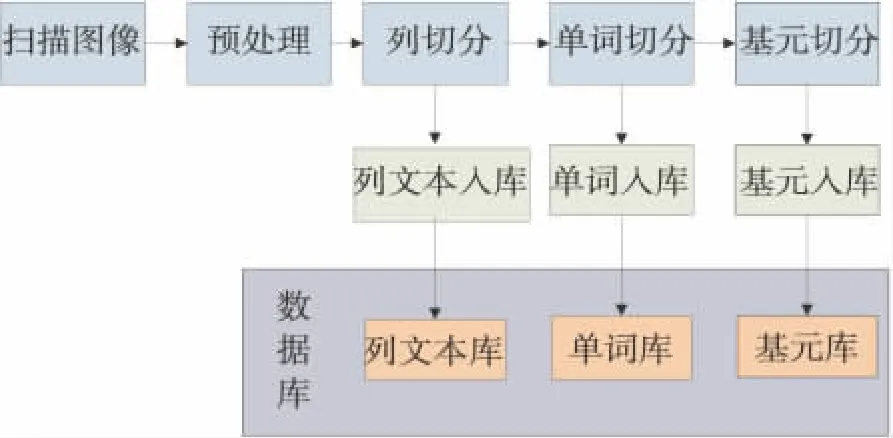
图1 满文文字数据库构建框图
满文文字数据库结构如图2,该库最大的结构特点在于它是一个多级库,其中根据满文单词的长度又将单词库分为多个子库。为了方便文字识别的调用,系统可以先判断满文文字的字长,根据组成单词基元的个数选择去哪个子库匹配,提高了系统的运行速度和匹配效率。同样,基元库中根据基元出现在单词中的不同位置划分为单字基元库、字头基元库、字中基元库和字尾基元库。这样,在文字识别、特征提取的时候就可以根据基元出现在单词中的位置选择去哪个子库查询匹配。
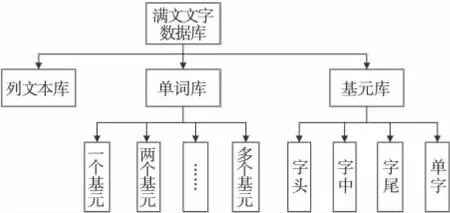
图2 满文文字数据库结构图
2 数据库的构建
要构建印刷体满文文字数据库,首先要对扫描得到的满文图像进行一系列的预处理,提取图像中的列文本建立列文本库,再切分出单个满文单词和基元,建立单词库和基元库。
2.1 图像预处理
由于获取的原始图像因为噪声、倾斜、污点、痕迹及人为扫描过程中各种参数调整不当等原因,使得扫描的图像并不完美,质量也不高,因此,需要对图像进行灰度化、二值化、倾斜矫正、行列切分等预处理[6]。
对于图像的灰度化和二值化,采用文献[7]中的方法,该方法能够较好地反映原图像的亮度信息,取得了较为理想的灰度化和二值化结果。但是如果扫描图像产生倾斜,就会引起字符变形,字符分割就很困难,严重影响文字的识别率[8]。因此,在预处理过程中,还要对二值图像进行倾斜校正,如图3(a)。扫描得到的满文文本图像存在一定的倾斜角θ,以原点为中心,将像素(x,y)旋转θ角度而得到新的像素点坐标(x',y')的旋转变换公式为
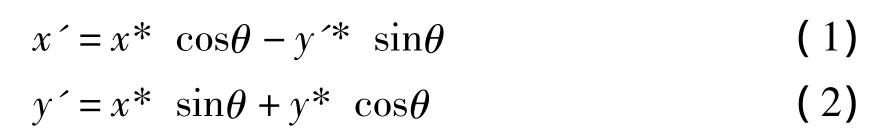
旋转校正后的图像如图3(b)。通过设定不同的θ值,可实现图像不同角度的旋转校正。
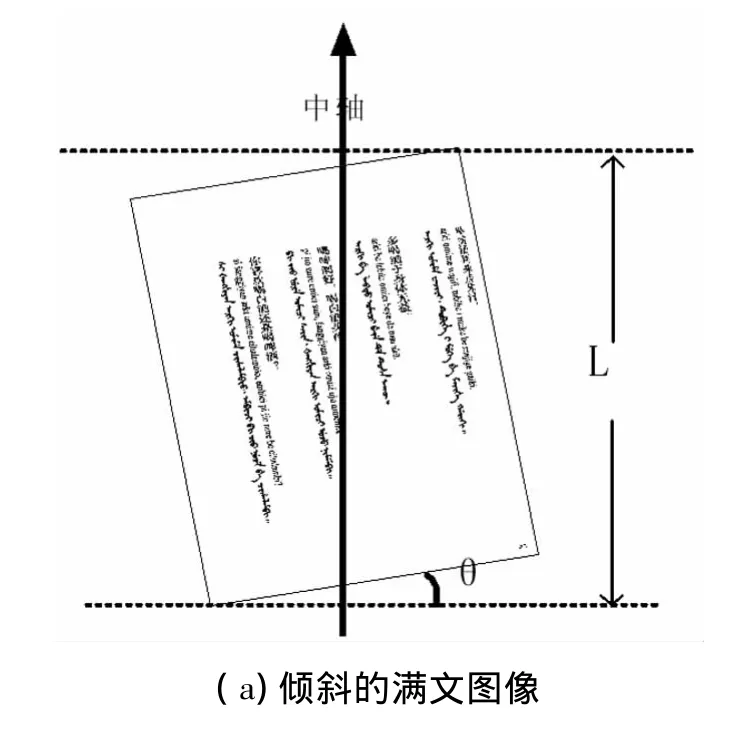
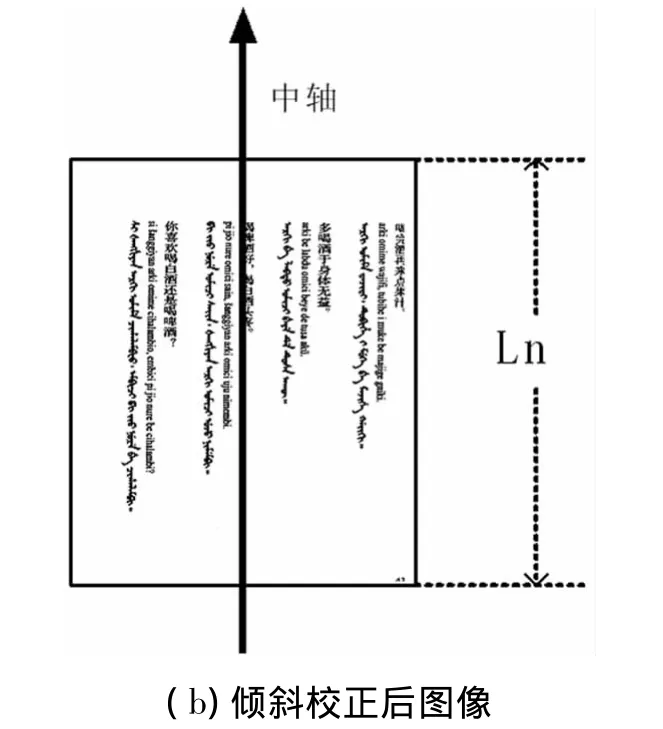
图3 倾斜校正
2.2 列文本库的构建
满文为拼音文字,在结构上与蒙古文相似,都是以词为单位,书写时从左至右,从上至下。每个满文在垂直方向上是由头部、中部、尾部构成的,由主干线相连。而且主干线大多位于单词的中部,由分布密集的黑色像素点构成[9]。
要建立列文本库,首先要对二值图像进行列切分,提取图像中的满文列文本。列切分的关键技术是如何确定左右边界,这里采用的是文献[10]中的投影法。满文二值图像在X轴上的投影曲线如图4,使用该方法的切分效果如图5,在切分出的列文本中挑选满文列保存入库。
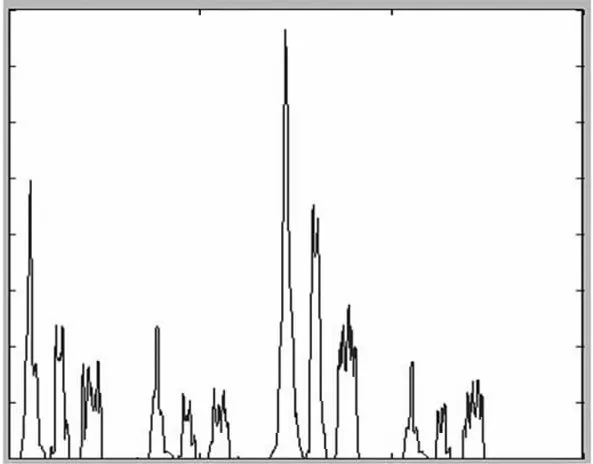
图4 在X轴上的投影曲线

图5 列切分效果图
2.3 单词库的构建
单词库的构建需要调用列文本库中的图像,提取图像中的满文单词。单词切分与列切分原理基本类似,将图像的像素点在Y轴上做投影,根据先前经验设定合适阈值,具体切分算法如下:
(1)设f(i,j)是二值图像中点(i,j)的像素值,其中 0≤i≤pic_height,0≤j≤pic_wide;
(2)第i=0行时,计算第i行黑色像素点总个数,并存入一维数组count[i]中,i循环加1;
(3)如果i小于图像高度,重复操作(2);
(4)设定阈值p,如果count[i]小于等于p,则返回i的值;
(5)沿(4)中返回的i值横向切分图像。
这种结合阈值的投影法,在某些特定规则下取得了较好的切分效果。将切分出的满文文字存入单词库中,最后根据词长以及构成单词的基元个数对满文单词进行分类,分别放入对应的子库中。
2.4 基元库的构建
基元库的构建相对复杂,因为同一字母出现在单词中的不同位置会有不同的写法,为了便于基元库的充分调用,我们将基元库分为字头基元库、字中基元库、字尾基元库以及单字库四个三级子库。基元的切分需要对原始文字图片进行列扫描列,选取有效像素点最多的列作为该文字的中轴[11]。构建基元库具体算法流程如图6,该算法切分出的基元效果图如图7。

图6 构建基元库算法流程图
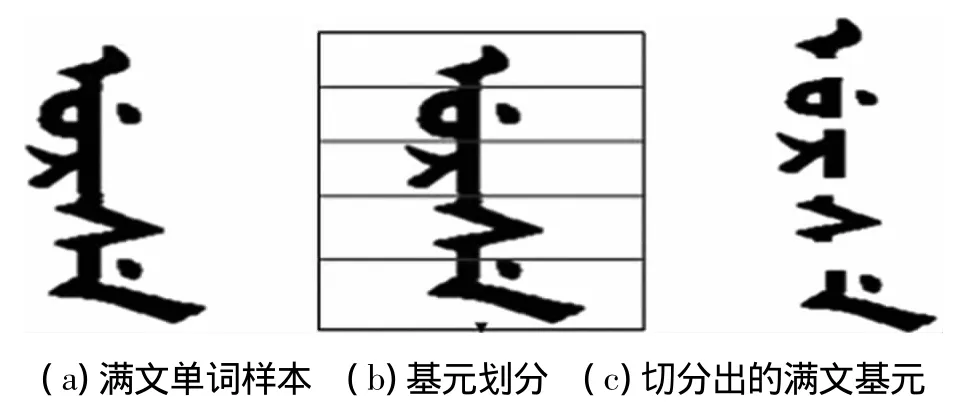
图7 基元切分效果图
通过以上方法构建的列文本库、满文单词库、基元库样本如图8。
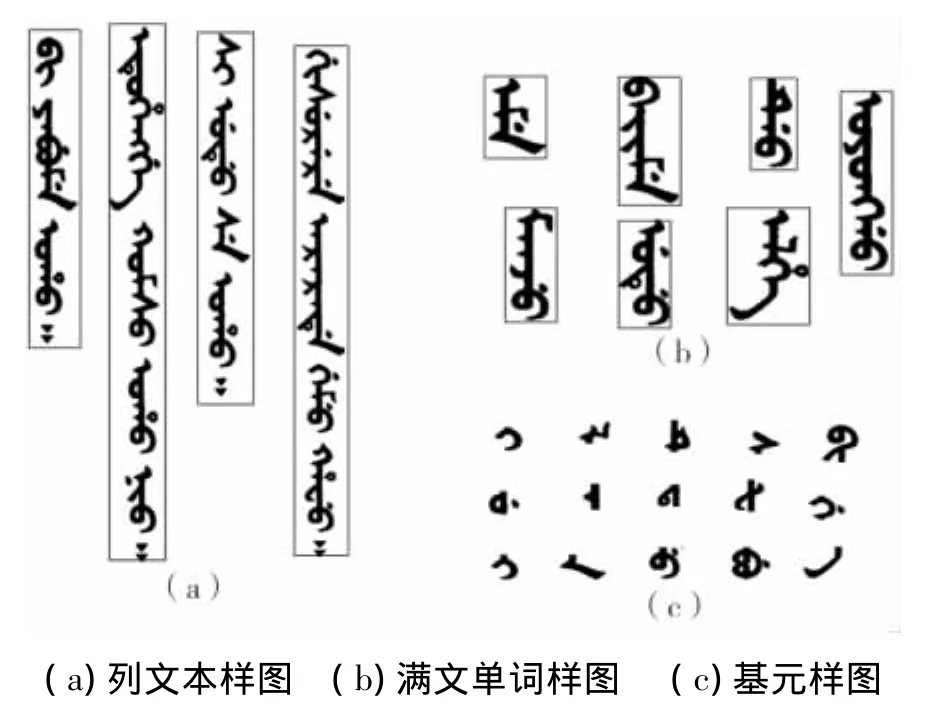
图8 印刷体满文文字数据库样本示例
3 结 语
文章提出了一种多级满文文字数据库的构建思想,将数据库分为列文本库、单词库和基元库三个子库,又根据基元个数的多少和出现位置的不同分为多个三级子库。这种多级库的设计有利于文字的调用和特征提取,可有效提高后续的文字识别速率。另外,该库包含丰富的满文文字及特征资源,可为其他学者研究和学习满文提供测试和训练样本,为后续满文识别奠定基础。在今后的研究中,将努力改进方法,进一步改善和丰富该数据库内容,努力构建不同字体和字号都适用的满文文字数据库。
[1]赵骥,王丽君,李晶皎.基于统计的满文识别后处理的研究和实现[J].鞍山科技大学学报,2005,28(6):444-446.
[2]吴敏.从满文发展的历史与现状谈保护与发展满文的意义[J].满族研究,2010(2):62-65.
[3]LIN W S,JAY K C C.Perceptual Visual Quality Metrics:A Survey[J].Journal of Visual Communication and Image Representation,2011,22(4):297-312.
[4]郑蕊蕊,李敏,吴宝春.基于MATLAB GUI的少数民族文字手写体采集系统—以满文为例[J].大连民族学院学报,2014,16(3):306-309.
[5]魏巍,郭晨.基于多特征集成分类器的脱机满文识别方法[J].计算机工程与设计,2012,33(6):2347-2352.
[6]吴刚,德熙嘉措,黄鹤鸣.印刷体藏文识别技术[J].青海师范大学学报:自然科学版,2006(01):286-291.
[7]郑蕊蕊,赵印继,李敏,等,.多民族脱机手写体汉字数据库的设计与构建[J].大连民族学院学报,2011,13(5):205-506.
[8]刘芳,欧珠.藏文文字识别系统中的数字图像预处理方法研究[J].西藏大学学报,2006,22(13):257-264.
[9]张广渊.脱机手写体满文识别研究[D].沈阳:东北大学,2006.
[10]刘赛,李益东.彝文文字识别中的文字切分算法设计与实现[J].中南民族大学学报:自然科学版,2007,26(3):70-72.
[11]白文荣.手写体蒙古文字识别—切分技术的研究[J].科技经济市场,2009,(6):30-31.
[12]魏宏喜,高光来.印刷体蒙古文字识别中蒙古文字特征的选择[J].内蒙古大学学报,2006,37(6):694-697.
[13]朱满琼,李敏,许爽,等.图像背景下的满文文字提取[J].大连民族学院学报,2014,16(1):78-81.
[14]唐春强,赵骥,王爱侠,等.基于投影法的满文识别研究[C].中国控制与决策学术年会论文集,2004:256-265.
[15]张广渊,李晶皎,王爱侠.脱机手写满文笔画基元的提取和识别[J].计算机工程,2007,33(22):200-202.
[16]郭海,赵晶莹.基于小波分析及改进二次鉴别函数的民族文种识别[J].计算机应用,2009,29(12):3360-3365.
[17] PENG Liangrui,LIU Changsong,DING Xiaoqing.Multi-font printed Monglian document recognition system[J].International Journal on Document Analysis and Recognition(IJDAR),2010,13(2):93-106.
