编码与同义词替换结合的可逆文本水印算法
2015-04-21林新建唐向宏
林新建 ,唐向宏,2 ,王 静
(1. 杭州电子科技大学 通信工程学院,浙江 杭州 310018;2. 杭州电子科技大学 信息工程学院,浙江 杭州 310018)
编码与同义词替换结合的可逆文本水印算法
林新建1,唐向宏1,2,王 静1
(1. 杭州电子科技大学 通信工程学院,浙江 杭州 310018;2. 杭州电子科技大学 信息工程学院,浙江 杭州 310018)
从通信编码的角度,该文探讨一种利用编码方法和同义词替换相结合的可逆文本篡改检测水印算法。以可替换同义词为标志对文本进行分组,提取分组文本特征生成认证水印信息;利用霍夫曼编码和纠错编码对同义词库各词进行编码,利用同义词替换技术完成水印的嵌入。在接收端,利用分组文本特征和霍夫曼编码,实现水印文本的篡改定位,利用纠错码实现可替换同义词的还原恢复。仿真实验表明,算法嵌入的水印具有良好的不可见性和较强的鲁棒性,在实现对文本篡改定位的同时,较好地实现了可替换同义词无损还原。
编码;同义词替换;可逆文本水印;定位篡改
1 引言
为了克服自然语言的文本水印算法中因同义词替换不具有可逆性[1-4]造成的文本语义的偏离问题,一种称为可逆文本水印的技术近几年得到了广泛的关注。所谓可逆文本水印是指算法不仅能够从文本载体中提取出嵌入的水印,同时还能够完全恢复原始文本载体。
现今国内外学者对可逆水印的篡改定位和恢复研究主要集中在图像领域[5-9], 对可逆文本水印算法研究相对较少。目前,针对中文文本可逆文本水印的研究主要集中在对同义词的可逆替换,实现水印的可逆嵌入。Luis[10]等提出一种篡改文本的恢复算法,对一些删除、篡改替换等攻击均可实现文本内容的定位以及恢复。Anamitra[11]等利用IWT和DCT两种技术提出一种可检测篡改和恢复的水印算法,该算法对内容修改有着较强的鲁棒性以及定位恢复能力。然而,文献[10-11]所提算法的前提条件是将文本文档转为文本图像,因此严格意义上说该类算法还是属于图像领域。姜传贤等[12]提出了一种鲁棒可逆文本水印算法,该算法通过同义词替换评价模型寻找替换同义词,将替换同义词与原生同义词的词典编码异或值作为可逆恢复数据。该算法充分考虑了同义词替换对文本产生的语义偏离,然而在提取水印和恢复原始文本时需要大量的冗余信息。同年,刘志杰等[13]在基于图像可逆水印的基础上,提出了两种可逆水印方案,基于整数可逆变换的文本可恢复水印算法和一种改进的差值扩展的文本可恢复水印算法。两种方案首先都对同义词编号进行像素值模拟,之后利用整数可逆变换和差值扩展对这些模拟像素值进行水印嵌入,水印嵌入完成后再将模拟像素值还原为同义词编号,依据编号找到对应同义词替换原始文本中同义词得到水印文本,两种算法充分借鉴了图像可逆水印的思想,但是都没考虑在改变词语嵌入水印时,对文本产生的语义偏差。费文斌等[14]提出了基于预测误差扩展的文本可逆水印算法,该算法考虑了水印嵌入后可能造成的文本歧义性。文献[12-14]所提出的可逆文本水印算法都很好地定位了可替换同义词是否被篡改替换,并实现可替换同义词还原,实现原始文本内容的无损恢复。然而,三种算法却无法判断和定位出可替换同义词以外区域文本的篡改情况。
为此,本文从通信编码的角度,探讨一种编码技术和同义词替换相结合的可逆文本水印算法。算法通过搜索文本得到所有可替换同义词及其对应的同义词库,以可替换同义词为标志对文本进行分组;提取可替换同义词的相邻分组文本的特征构造水印信息;对同义词库中各词进行霍夫曼编码和纠错编码。嵌入端用霍夫曼编码与水印一致的同义词替换原始同义词,完成水印的嵌入。在提取端通过对比提取的水印信息和定位信息是否一致,判断和定位出可替换同义词是否篡改,以及文本区域被篡改情况;对每个同义词码字进行纠错解码,完成被替换同义词的恢复。
2 编码原理
为实现分组文本的篡改定位,本文对每个可替换同义词对应的同义词库中的各词进行霍夫曼编码。众所周知,霍夫曼编码依据字符的出现概率进行编码[15],概率大的字符其码长相对较短,概率小的字符其码长相对较长。假设某一可替换同义词对应的同义词库中有n个词,考虑同义词替换的语义影响[16],对各词的霍夫曼编码算法如下。
① 计算同义词库中各词在句子上下文的搭配度CDi[3],搭配度小于阈值thr的同义词从词库中删除,最后得到词库满足条件的有m(m≤n)个词,同时得到这m个词的搭配度总和,如式(1)所示。
(1)
② 按式(1)计算得到同义词库中各词的归一化概率Pi,使搭配度越大的同义词其归一化概率越小,并按归一化概率升序对同义词库各词进行排序,如式(2)所示。
(2)
③ 根据各词的归一化概率,对排序后的同义词库各词进行霍夫曼编码,得到同义词库各词的霍夫曼编码,其中搭配度大的同义词其码长相对较长,搭配度小的同义词其码长相对较短。
为使水印系统的实现简单易行,本文纠错码采用循环冗余校验码(CRC)[17]。码长为N的(N,K)-CRC码由两部分构成:K位信息码和R=N-K位校验码。在本算法中用K位信息码表示同义词位置的编码,R位校验码表示同义词可逆替换所需的监督信息。当水印嵌入后,R位校验码保存作为水印提取时的密钥。
关于N、K大小的选择,根据汉语特点,一个词的同义词总数最多可有几十个。以哈尔滨工业大学的《同义词词林扩展版》为基础,在不考虑句子语义的前提下对词林中8 602个同义词组进行统计测试,其中拥有超过16个同义词的同义词组有75个,所占比例为75/8 602=0.008 7。在实际应用中,当考虑句子语义后,通过阈值的合理设置,可以将这个比例降到为0。因此,可用4bit的二进制码对同义词编号进行编码,K=4。为能够纠正错误码字,R最小取值为3,即用3bit表示其对应校验码信息,因此本文采用的纠错码为(7,4)-CRC。
表1给出本文(7,4)-CRC正确码字的组成结构,定义同义词编号1-8的同义词词标记位flag=0,同义词编号9-16的同义词词标记位flag=1。信息码对应同义词编号1-16,一个校验码对应两个信息码。当码字发生错误时,可根据原始校验码、词标记位flag以及表1找到一个正确的信息码,从而得到纠正后的正确码字。
经过上述编码,一个可替换同义词在其同义词库中的位置就拥有两种编码: 霍夫曼编码和(7,4)-CRC编码。霍夫曼编码功能实现水印的嵌入与提取,(7,4)-CRC编码功能实现同义词的可逆替换,两种编码独立不相关。
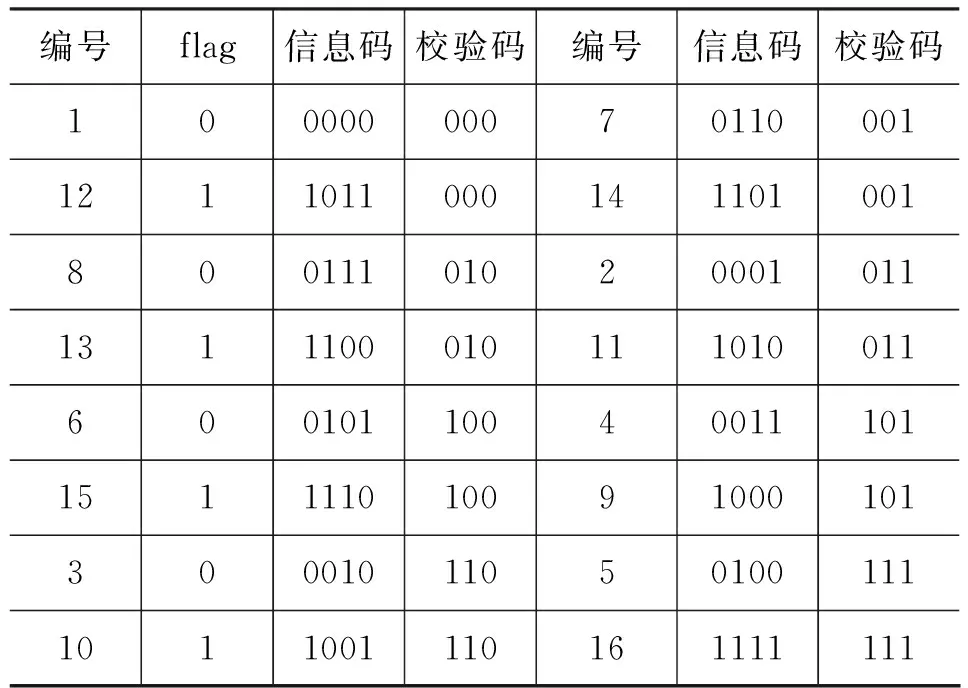
表1 同义词编号生成的(7,4)-CRC码字组成结构表
3 水印嵌入和提取算法
3.1 水印的嵌入
可逆水印嵌入的具体流程如图1所示,具体步骤如下。
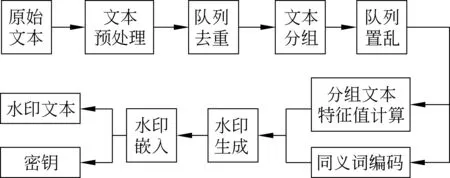
图1 文本水印嵌入
(1) 文本预处理
(2) 队列去重
(3) 文本分组
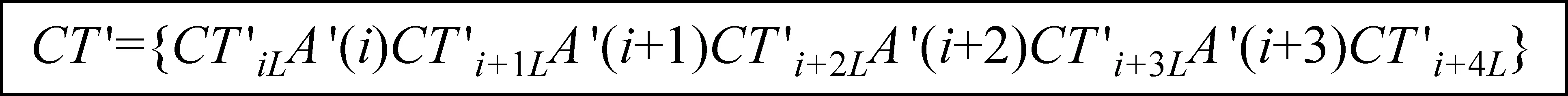
图2 相邻可替换词的左邻分组文本
注意: 若第一个词(假设为A′(i))无左邻分组文本,则该词的左邻分组文本为空;若最后一个词(假设为A′(i+3))有右邻分组文本,则将CTi+3L′和CTi+4L′二者合并作为A′(i+3)的左邻分组文本,即CTi+3L′={CTi+3L′CTi+4L′}。
(4) 队列置乱
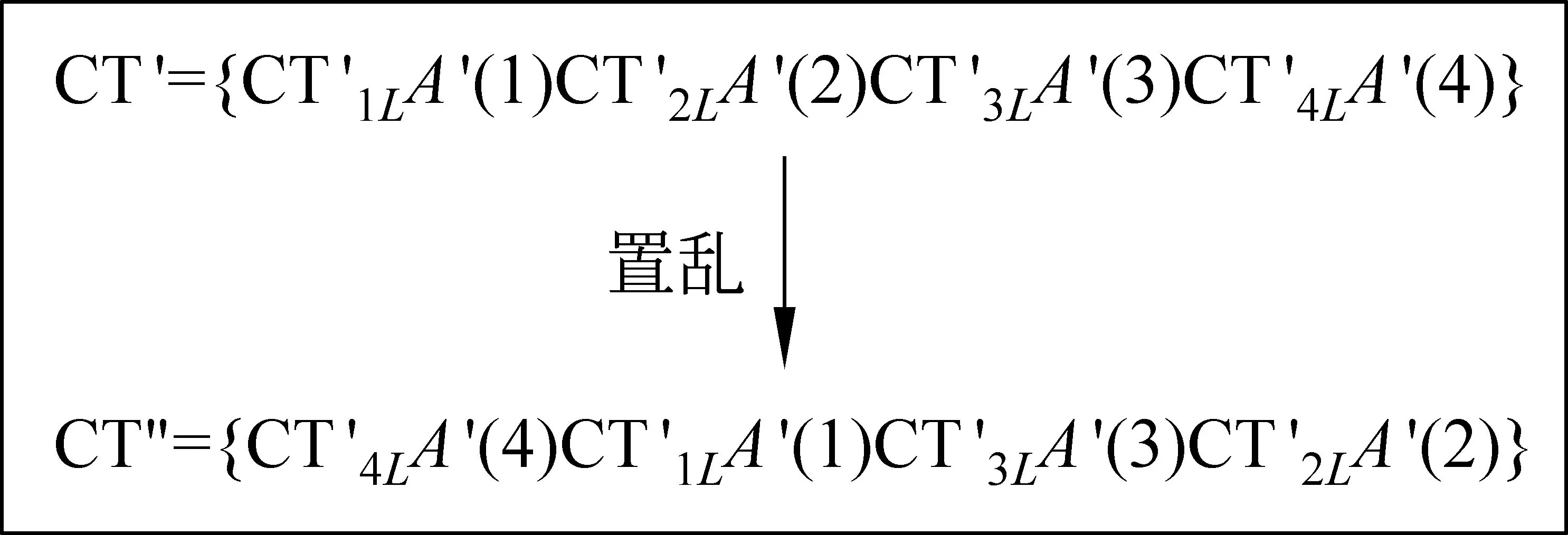
图3 可替换同义词及其相邻分组文本的置乱
(5) 同义词编码
(6) 分组文本特征值计算
为生成水印信息,先对分组文本进行预处理。定位词A″(i)的左邻分组文本,统计分组文本的字数以及各字的笔画数,按式(3)计算分组文本的特征值x0;
(3)
式(3)中,n代表分组文本的字数,Sm代表分组文本中最小笔画数,SM代表分组文本中最大笔画数,Si代表分组文本中某个字符的笔画数,得到可替换同义词的左邻分组文本的特征值Lx0(i)。若n=0,即词A″(i)的左邻分组文本为空,则令x0=0.001。
(7) 水印信息的生成
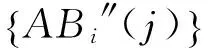
① 令k=MaxLen,(Li)k表示二进制序列Li的前k比特;
② 读取词库中霍夫曼编码码长为k的所有同义词,遍历搜索这些同义词,获取霍夫曼编码为(Li)k的同义词,若该同义词不存在,则转步骤③;反之,得到水印信息Wi=(Li)k,搜索算法停止;
③ 令k=k-1,重新执行步骤②。
(8) 水印的嵌入
重复执行步骤(5)~(8),遍历完原始文本。得到水印文本和密钥KEY。
3.2 水印提取及同义词的可逆替换
水印的提取为水印嵌入的逆过程。图4给出一个可替换同义词的水印提取及其左邻分组文本的篡改检测流程,图5给出一个可替换同义词的无损还原流程。具体步骤如下:
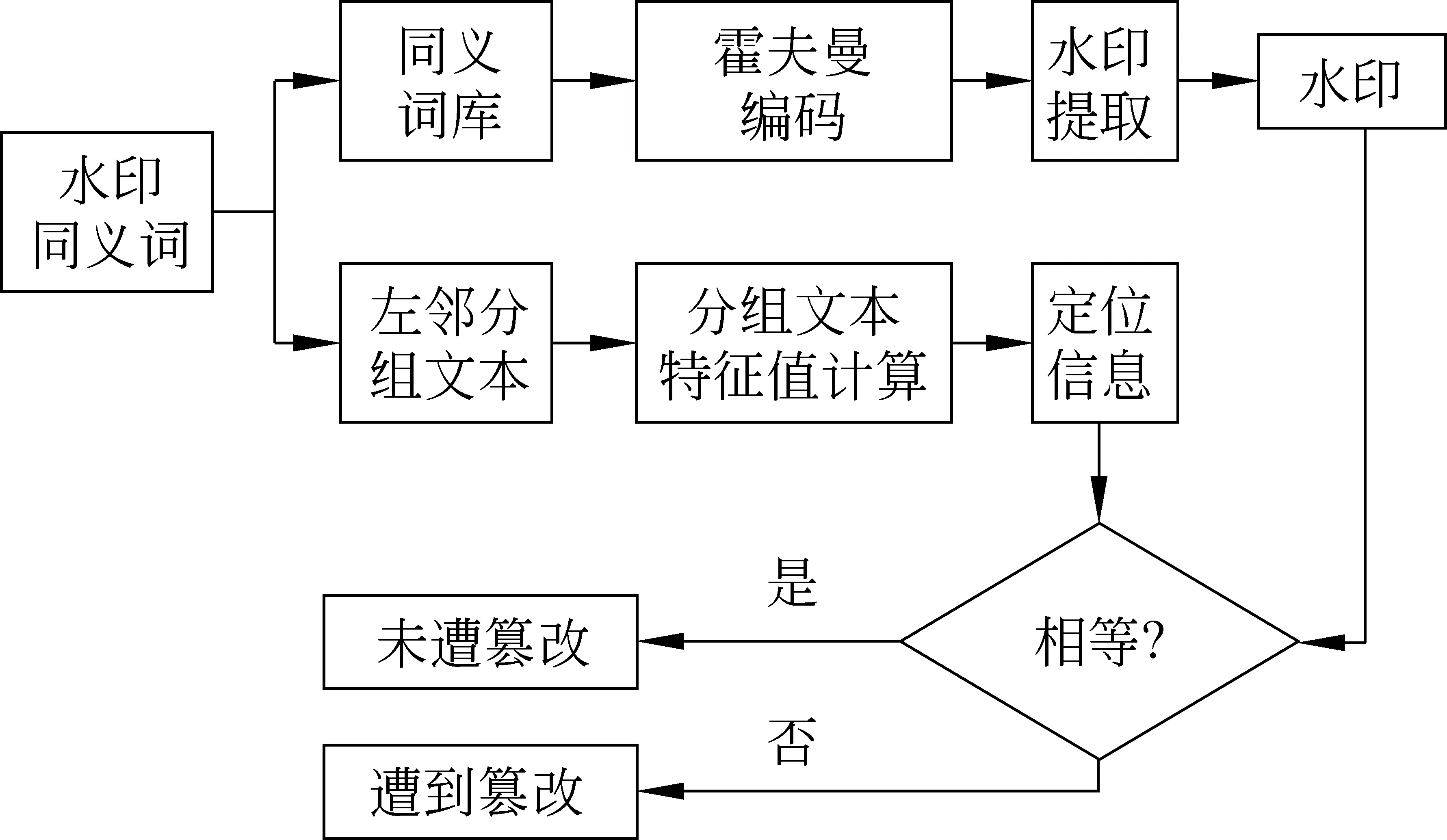
图4 可替换同义词的水印提取及其左右相邻分组文本的篡改检测
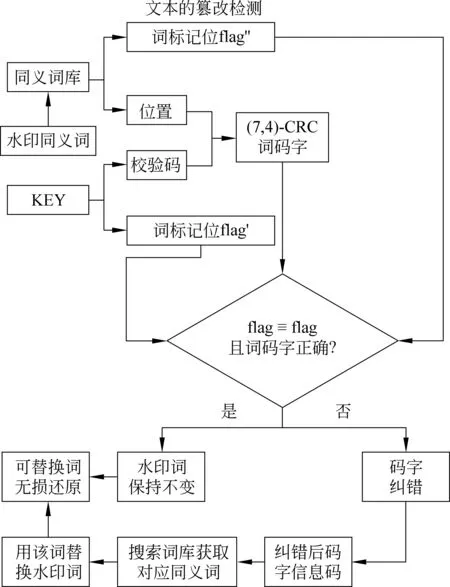
图5 可替换同义词的无损还原
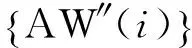
(2) 水印的提取
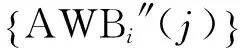
(3) 篡改定位
对词AW″(i)的左邻分组文本,以Lx0(i)′为初值,生成与水印Wi′等长的二进制混沌序列Li′,得到定位信息LRi′=Li′;若Wi′≡LRi′,则该词的左邻分组文本内容未遭篡改。反之,若Wi′≠LRi′,则定位该同义词的左邻分组文本某处内容遭到篡改。
(4) 同义词的可逆恢复
① 获取词AW″(i)在同义词库{AWBi″(j)}中的位置(wki)2以及词标记位flagi′;;依次从密钥KEY中提取3bit校验码(wvi)2和1bit词标记位flagi′;将(wki)2和(wvi)2二者重构成(7,4)-CRC码字Cwordi′;
② 根据表1,对码字Cwordi′进行正确与否判别: 当且仅当码字Cwordi′可在表1中找到,且flagi″和flagi′一致,则码字正确;反之,码字出错;
③ 若码字Cwordi′正确,则词AW″(i)保持不变;若码字Cwordi′出错,需根据表1对码字Cwordi′进行纠错实现被替换词的恢复;
④ 纠错具体实现过程如下: 首先,根据词AW″(i)的词标记位flagi′和码字Cwordi′的校验码(wvi)2,利用表1,找到对应的信息码,得到纠错码字Cwordi′,实现对码字Cwordi′纠错处理;然后,读取纠错码字Cwordi″的4bit信息码(eki)2,搜索同义词库{AWBi″(j)}中位置eki对应的同义词AWBi″(eki),并用该词替换水印同义词AW″(i),实现被替换词的恢复。其流程如图4所示。
重复执行步骤(2)到步骤(4),遍历完水印文本。得到水印信息{Wi′}和文本篡改检测结果。
4 实验结果和性能分析
为了验证本算法的性能,在计算机(PentiumIVCPU2.8GHz、1GB内存)上进行了仿真,并与相关算法进行了比较。编程语言为MATLABV7.0,实验文本内容取自网上新闻语料,文本为纯文本格式文件。同义词上下文搭配度算法使用的语料库来自人民日报1998年和2002年部分语料,一共约385万字,搭配度阈值thr=1。限于篇幅,下面仅给出部分实验结果。另外,为了便于区分文本在水印嵌入前后词语的变化,所以,在水印嵌入和提取等过程,采用对字体加粗、带阴影、单下划线、双下划线等方式进行标注。
4.1 可恢复性分析
图6给出原始文本,图中字体加粗带阴影的词汇代表可替换的同义词。图7给出嵌入水印后的水印文本及嵌入的水印,图中字体加粗带阴影和单下划线的词汇代表替换的同义词。图8给出提取水印后恢复的文本及提取的水印,图中字体加粗带阴影和双下划线的词汇代表还原的同义词。每个可替换同义词嵌入的水印不等长,图中水印信息间隔加阴影以示区分。

图6 原始文本

图7 水印文本
从图7中嵌有水印的水印文本可以看出,水印的嵌入没有引起文本格式外观上的变化;采用搭配度方法选取同义词,较好地避免了词汇语境的歧义性,所嵌水印具有较好的不可见性。从图8恢复的文本可以看出,本算法能够无损的恢复原始文本。提取得到的水印W′与原始水印W一致。从以上比较分析可得,本算法在正确提取水印信息的同时,也无损地恢复了原始文本中被替换同义词,且信息的隐蔽性能很好。另外,由于在水印嵌入之前,将可替换词队列进行了置乱处理,使得水印信息与文本中可替换词非一一对应,提高算法的安全性。
4.2 鲁棒性分析
(1) 常见格式攻击
表2分别给出了对水印文本的文本再生攻击、格式转换、字体大小、颜色变化、删除空格等一些常见文本格式攻击后提取得到的水印信息。由于本算法水印的嵌入是发生在文本的内容中,故通过删改这些属性无法达到攻击水印信息的目的。由于这些格式攻击并没有造成文本内容的改变,因此算法将这些攻击视为无恶意攻击,并不将其定位检测出来。
(2) 句子、段落交换攻击
图9给出了水印文本(图7)受到句子交换攻击的攻击文本,图中带单下划线的句子代表互相交换的句子,图10为图9的恢复文本。图11给出了水印文本(图7)受到段落交换攻击的攻击文本,图中带双下划线的段落代表互相交换的段落,图12为图11的恢复文本。图中带细波浪线的内容代表定位成功的篡改分组文本区域,带粗波浪线的内容代表定位失败的篡改分组文本区域,以下类似标注。
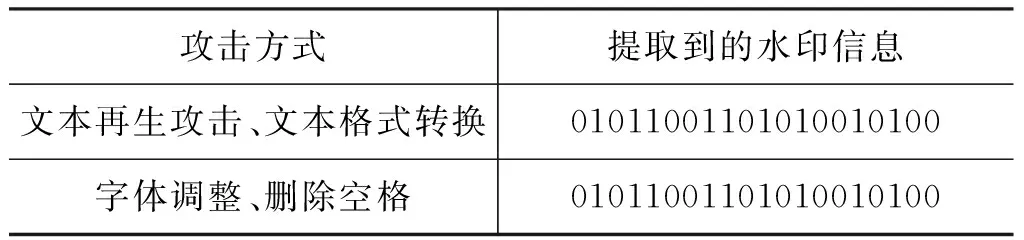
表2 格式攻击分析

图9 句子交换攻击文本

图10 句子交换攻击恢复文本

图11 段落交换攻击文本

图12 段落交换攻击恢复文本
由图10和图12可看出,句子、段交换攻击不影响本算法对水印信息的正确提取和文本被替换同义词的无损恢复,即本算法可很好地抵抗此类攻击。由图10和图12亦可知,算法定位出可替换同义词以外区域文本的篡改情况结果并不都是正确的,定位结果受限于算法的定位精度。由嵌入的水印可知,可替换同义词一次嵌入的水印比特位最小为1bit,最大为4bit,因此,定位精度最小为1-1/21=50.00#,最大为1-1/24=93.75#。算法无法还原句子、段落的原始顺序。
(3) 句子复制粘贴攻击
图13给出水印文本(图7)受到句子复制粘贴攻击的攻击文本,图中带单下划线的句子代表复制粘贴的句子,图14为图13的恢复文本。

图13 句子复制粘贴攻击文本

图14 句子复制粘贴攻击恢复文本
由图14 可知,句子复制粘贴攻击即使增加了可替换同义词的词数,但它并不会影响到本算法对水印信息的正确提取和文本原始被替换同义词的无损恢复,即本算法可很好地抵抗此类攻击。定位检测结果如图14所示。
(4) 句子内容增删攻击
图15和图17分别给出水印文本(图7)受到不同句子内容增删攻击的攻击文本,图16和图18分别为图15和图17的恢复文本。图中带单删除线的内容表示删除不包含可替换同义词的内容,带点式下划线的内容表示增加不包含可替换同义词的内容;带双删除线的内容表示删除包含可替换同义词的内容,带虚下划线的内容表示增加包含可替换同义词的内容。

图15 句子词汇增删攻击文本1

图16 句子词汇增删攻击恢复文本1

图17 句子词汇增删攻击文本2

图18 句子词汇增删攻击恢复文本2
由图16可看出,当增删的内容不涉及到可替换同义词时,这时的攻击不会影响本算法对水印信息的提取和文本原始被替换同义词的无损恢复;当增删的内容涉及到可替换同义词时(图18),这时攻击将影响到水印信息的提取和文本原始被替换同义词的无损恢复,不能正确提取水印信息和还原被替换的同义词。定位检测结果如图16和图18所示。
(5) 同义词替换攻击
图19给出水印文本(图7)受到同义词替换攻击的攻击文本,图中带双下划线的词汇代表同义词替换攻击替换的同义词。由于文献12、文献13和文献14的每个可替换同义词只能嵌入1bit水印,假设这三种算法嵌入的水印信息为101100010110。图20、图21、图22及图23分别为文献12、文献13、文献14以及本算法对图19的恢复文本和提取的水印。

图19 同义词替换攻击文本

图20 文献[12]同义词替换攻击恢复文本

图21 文献[13]同义词替换攻击恢复文本

图22 文献[14]同义词替换攻击恢复文本

图23 本文同义词替换攻击恢复文本
由图20、图21和图22可知,水印文本受到同义词替换攻击时,文献[12]、文献[13]及文献[14]无法恢复出原始同义词。与此相反,从图23可知,本算法基本恢复出了原始同义词,且文中一旦有可替换同义词被替换掉,算法肯定能够判断出文中内容遭过篡改。
通过以上仿真的实验分析,实验中与其他可逆算法进行了性能比较,如表3所示。
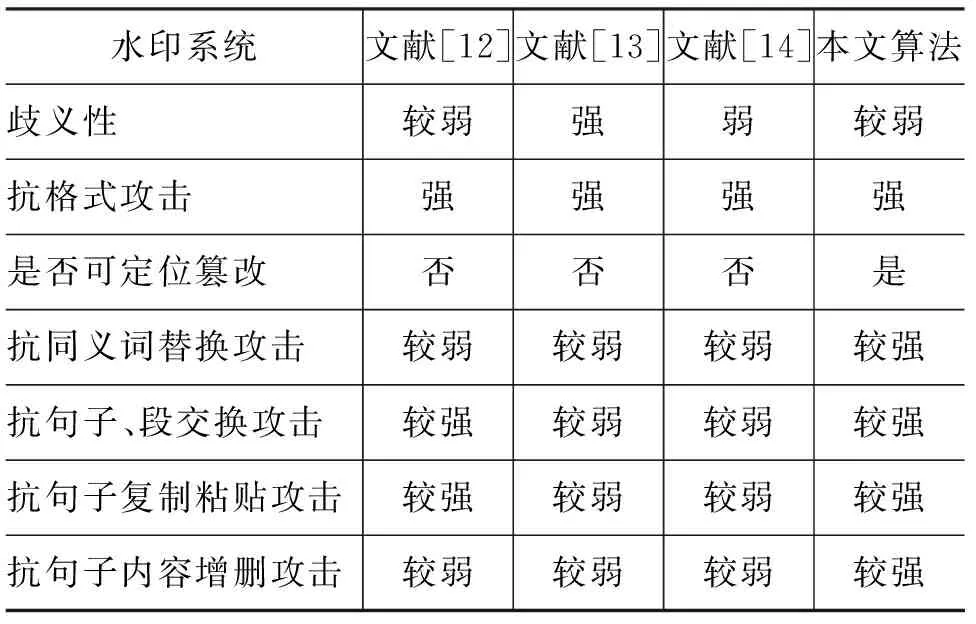
表3 算法性能比较
5 结论
本文从通信编码的角度,探讨一种同义词替换和编码技术相结合的可逆文本水印算法。借鉴霍夫曼和纠错编码的思想以及采用同义词替换技术,实现水印的嵌入及可恢复提取。在提取水印时既不需要原始载体也不需要原始水印,只需密钥就可实现水印的提取及原始文本的无损恢复, 增强了方案的实际可行性。实验仿真表明,算法对格式攻击、句子、段变换攻击表现出了较强的鲁棒性,且可定位文
本篡改区域;在水印文本未遭到攻击时,能完全恢复出原始同义词;当遭到小范围同义词替换、内容增删等攻击时,算法能恢复出原始同义词;当遭到大面积同义词替换、内容增删等攻击时,算法只能部分恢复出原始同义词。当然,算法还是存在着一些不足,例如,恢复只是针对同义词替换而不是文本任意内容,篡改定位精度还有待提高,以及同义词替换引起语义歧义或语句不是很通顺等问题,这些不足也将是今后研究的重点。
[1] Mercan Topkara,Cuneyt M,Taskiran. Natural language watermarking [C]//Proceedings of Security,Steganography,and Watermarking of Multimedia Contents VII,2005,2005: 441-452.
[2] Zunera Jalil,Anwar M Mirza. A review of digital watermarking techniques for text documents [C]//Proceedings of 2009 International Conference on Information and Multimedia Technology,ICIMT 2009,2009: 230-234.
[3] Zheng Xueling,Huang Liusheng,Chen Zhil. Hiding information by context-based synonym substitution[C]//Proceedings of 8th Internation- al Workshop on Digital Watermarking,IWDW 2009,2009: 162-169.
[4] 黄华,齐春,李俊,等. 文本数字水印[J]. 中文信息学报,2001, 15(5): 52-57.
[5] Coatriuex G,Guillou C L,Gauvin J M. Reversible watermarking for knowledge digest embedding and reliability control in medical images [J]. IEEE Transaction on Information Technology in Biomedicine,2009,13(2): 158-165.
[6] 彭飞,雷瑜洲,孙星明. 2维CAD工程图小波域可逆水印[J]. 中国图象图形学报,2011,16(7): 1134-1139.
[7] 王俊祥,倪江群,潘金伟. 一种基于直方图平移的高性能可逆水印算法[J]. 自动化学报,2012,38(1): 88-96.
[8] Banani Patra,Jagdish C Patra. CRT-based fragile self-recovery watermarking scheme for image authentication and recovery [C]//Proceedings of 20th IEEE International Symposium on Intelligent Signal Processing and Communications Systems(ISPACS),2012: 430-435.
[9] T jokorda Agung B.W,Adiwijaya. Medical image watermarking with tamper detection and recovery using reversible watermarking with LSB modification and Run Length Encoding (RLE) compression [C]//Proceedings of 2012 IEEE International Conference onCommunication,Networks and Satellite,COMNETSAT 2012,2012: 167-171.
[10] Luis Rosales-Roldan,Mariko Nakano-Miyatake. Watermarking-based tamper detection and recovery algorithms for official documents[C]//Proceeding of 8th International Conference on Electrical Engineering,Computing Science and Automatic Control,CCE 2011,2011.
[11] Makur Anamitra,Sridharan Govindarajan. Watermark based recovery of tampered documents[C]//Proceedings of ACM SIGKDD Workshop on Intelligence and Security Informatics,ISI-KDD 2012,2012.
[12] 姜传贤,陈孝威. 鲁棒可逆文本水印算法[J]. 计算机辅助设计与图形学学报,2010,22(3): 879-885.
[13] 刘志杰. 基于自然语言的文本可恢复水印研究[D].长沙: 湖南大学,2010.
[14] 费文斌. 可逆文本水印算法研究[D].杭州: 杭州电子科技大学,2013.
[15] 甘灿. 基于同义词替换的自然语言文本信息隐藏技术研究[D]. 长沙: 湖南大学,2010.
[16] 张宇,刘挺,陈毅恒,等. 自然语言文本水印[J]. 中文信息学报,2005, 19(1): 56-62.
[17] 傅祖芸. 信息论—基础理论与应用[M].北京: 电子工业出版社,2007 : 367-380.
[18] 向华,曹汉强,伍凯宁,等. 一种基于混沌调制的零水印算法[J]. 中国图象图形学报,2006,11(5): 720-724.
A Reversible Text Watermarking Algorithm Based on Coding and Synonymy Substitution
LIN Xinjian1,TANG Xianghong1,2,WANG Jing1
(1. School of Communication Engineering, Hangzhou Dianzi University , Hangzhou, Zhejiang 310018,China;2. School of Information Engineering, Hangzhou Dianzi University, Hangzhou, Zhejiang 310018,China)
From the perspective of communication encoding, a reversible text watermarking algorithm based on coding and synonymy substitution is discussed. The algorithm employs interchangeable synonyms as signs to group the texts and generates watermarking by extracting group text feature. The algorithm uses the method of Huffman coding to encode synonyms and uses the method of error correction coding to encode the position of a synonym in the thesaurus into , then completes the watermark embedding combined with synonymy substitution. At the receiving end, using packet text feature and the Hoffman code to locate tampered watermark text and using error correcting codes to restore the original synonymy. Experimental results show that, the proposed algorithm can improve the robustness and imperceptibility of watermarking. In addition, it can locate the tampering and restore the original synonymy.
coding;synonymy substitution;reversible text watermarking; tampering identification

林新建(1988—),硕士,主要研究领域为文本数字水印。E-mail:lxj657983@126.com唐向宏(1962—),博士,教授,主要研究领域为扩频通信、图像压缩与传输和数字水印。E-mail:tangxh@hdu.edu.cn王静(1989—),硕士,主要研究领域为文本数字水印。E-mail:wang_jing001@163.com
1003-0077(2015)04-0151-08
2013-09-09 定稿日期: 2014-02-28
TP391
A
