基于话题相关的文档集的无向基本要素网络的连通性探讨
2015-04-21姬东鸿
杨 华, 姬东鸿, 陈 波
(1. 贵州师范大学数学与计算机科学学院,贵州 贵阳 550001;2. 武汉大学文学院,湖北 武汉 430072;3. 武汉大学计算机学院,湖北 武汉 430072;4. 湖北文理学院文学院,湖北 襄阳 441053)
基于话题相关的文档集的无向基本要素网络的连通性探讨
杨 华1, 2, 姬东鸿3, 陈 波3, 4
(1. 贵州师范大学数学与计算机科学学院,贵州 贵阳 550001;2. 武汉大学文学院,湖北 武汉 430072;3. 武汉大学计算机学院,湖北 武汉 430072;4. 湖北文理学院文学院,湖北 襄阳 441053)
基于数量有限的文档,该文构建以基本要素中的head和modifier为节点的无向网络UBEN,调查了话题相关文档的UBEN的连通性,指出了话题相关的文档的UBEN具有的特性。讨论停用词对UBEN连通性的影响,比较了相关文档集和随机文档集的UBEN的联通特性的差异,指出了连通性在一定程度上是文档之间内容相关导致的融合结果。结论对多文档自动文摘和信息检索等任务有一定的意义。
话题相关文档集;自动文摘;复杂网络;连通性;信息融合
1 引言
近年来,复杂网络开始被用来描述语言这一复杂现象[1-4],包括语言的起源、性质以及认知等。结点小于句子的网络主要有:单词同现/搭配(collaboration)网[1],单词依存语法网[5],同义词典网[2, 6-8]、概念网[6, 8-9],词汇联想网[10]等。文献[4]综述了以单词、句子、文本为结点的语言网络。其他包含语言网络综述性内容的为文献[2-3]。目前构建的、在以句子级别以下的单元为节点的语言复杂网络大多有如下特点:基于海量的文档或者词典;大多没有权值;极少的网络是有向的。很多研究对以什么单位为结点,如何定义结点之间的关系,研究的兴趣何在都未给予充分的回答[4]。但是,观察这些网络的构建过程,结点都是相对完整的语义单位,结点之间在一定程度上语义相关,从而形成边。
多文档就是多个文档(通常为几十篇)构成的集合。多文档又可以分为话题相关的文档集和随机挑选的文档构成的集合。
把文本表达成网络可以对文本更深入地洞察[11]。文献[12]在数量有限的、话题相关的文档上,构建了以基本要素的head和modifier为结点的网络BEN,并尝试将网络特性和原文档集的内容特性关联起来。BEN网络的特点是:结点是比单词更加完整,比句子更加精确的语义单元;结点之间的关系附带了来自原文档的丰富信息;网络构建来自于数量有限得多的文档。在文献中研究的语言网络中,一些大规模的网络表现出高度连通性[8],但是这些网络都是基于词典(而非真实的语料)或者大规模的语料。那么,对BEN这样一个来自数量很有限的文档集而言,连通性如何?语言本身的特性以及文档内容的相关性对连通性的影响会如何?本文将探索这些问题。
本文其余部分组织结构如下:第二部分介绍了“多文档”的概念;第三部分描述了基本要素的概念,及基于该概念的有向基本要素网络;第四部分介绍了无向基本要素网络的构建方法。第五部分给出了MC-FC性质的定性描述;第六部分给出了实验结果;第七部分总结了本文结论及应用场合。
2 多文档的概念
“多文档自动文摘”任务是在话题相关的文档集(通常是几十篇)――多文档(在此特定情况下,多文档也就是内容相关的文档集)的基础上,生成一篇能代表这些文档的主要内容、可读性好的摘要,帮助用户快速了解整个文档的主要内容。当前,人们使用流行的搜索引擎,往往是阅读搜索引擎取回的大量结果中的一部分,在其中寻找自己感兴趣的信息。排在检索结果最前面的若干篇文档,例如,50个文档,总体上可以看成是围绕用户查询的话题相关文档集。多文档是一种独特的文档数据集。为方便陈述,把话题相关的文档简记为TDS(Topic-related Document Set)。相较于TDS,如果文档集中的文档是从海量的文档中随机抽取的,则称该文档集为随机文档的集合,简记为RDS(Random Document Set)。
3 有向基本要素网络
研究对语言网络研究时,应该回答下面的问题:构建网络的标准是什么,即结点和边都代表什么?为什么要分析网络即对这些网络进行分析的研究兴趣是什么[4]。
BEN的节点的选择与多文档文摘中的表示粒度密切相关。在自动文摘的内容选择阶段,选择段落或句子作为基本粒度过于粗糙;词的频率对内容的重要性有很好的指示作用,但是因为词的粒度较小,且仅包含自己的语义信息,其在句中的结构信息被忽视[13]。自动文摘系统评测工作的经验也证明从句子的粒度去评测过于粗糙,从单词的层面来比较内容太不精确。综上,无论是内容选择,还是评测的要求,都需要介于单词和句子之间的、可变长度的,包含重要信息的单元。文献[14]提出了一种自动产生这种单元的方法,这就是基本要素(Basic Element,BE),并指出了使用BE作为基本粒度评测DUC2005中的自动文摘的方法。
BE描述的是基本要素中心词(head)及其修饰(modifier)之间的关系(relation),表示为一个三元组“中心-修饰-关系” (head|modifier|relation),其中“中心词”表示主要的语法成分,关系则表达了Head和Modifier之间的依存关系。为陈述方便,下文提及BE的时候,意指BE 三元组,而 BEH表示BE head,BEM表示BE modifier,BEHM为BE中的BEH或者BEM。图 1是句子“The United Nations imposed sanctions on Libya in 1992 because of their refusal to surrender the suspects”中基本要素的一个例子。

图1 BE的例子
有时候最小的语意单元是由单个词构成的,比如“England”,但是很多时候也由多个单词共同组成,比如“the United States” ,可以统称为词项,也就是基本要素中的BEHM。显然,BEHM是比单词更精确的语义单元。我们定义了以BEHM为结点的网络,简称为BEN(BE Network)。BEN上的边上附加有BEH和BEM之间的关系;因而相同的两个结点之间可能存在不止一条边。而每条边上还附加有权值——相应的BEH、BEM以及它们之间的某种关系在整个文档集中出现的次数。BEN构建的详细过程见文献[12]。该文献还指出,结点的入权代表了一个BEHM在原文档集中受到关注的程度。入权越低,说明在整个文档集中,该BEHM越不可能是重要的内容单元。
4 无向基本要素网络的生成
语言网络可以根据研究的目的来进行定义。出
于本文的目的,我们构建BEN的无向版本UBEN。把有向版本的网络转换成无向版本来研究连通性的理由是:BEN的网络结点在作为BEH或者BEM的倾向性是非常重的*辅助实验中,把网络的结点作为BEH的倾向程度表示成100级,表示为结点的入度与度之比乘以100以后取整,或者结点的入权与结点邻边上权值和之比乘以100以后取整。结果显示,在这两种表示法下,分布在0,25,33,50,66,75,100的结点数处远比其他位置高,在0,100处的结点数又比25,33,50,66,75高很多。该现象的原因将在其他论文中描述。此处仅定性描述。。此外,当前大部分研究复杂网络连通性的文献中是针对无向网络的。
UBEN与BEN相比有如下特征:BEN的结点的入权被附加在相应的UBEN的结点之中,尽管网络是无向的,但结点的入权仍然可以经过简单计算而获得:计算文档集产生的BE三元组可重集合里,一个结点充当BEH的次数即可;在BEN中两个结点之间由于关系不同而可能存在的多条边在UBEN中被合并成一条边,因为两个结点之间无论是一条边还是多条边,起到的连接作用是一样的;为了清晰,UBEN的构建算法如图 2所示。
5 无向基本要素网络连通性
一些被研究过的语言网络表现出高度的连通性[8]。与其他文献中的语言网络相比较,UBEN有如下特点:1)UBEN的构建目的是为了反映文档集的内容特性,而非研究语言的性质、特征及语言的认知和学习。因而,更多的是以多文档的语义特性为研究对象。因此UBEN将被构建在数量有限的文档之上而非大规模的文档集上;2)UBEN的结点,即BEHM,既来自于真实的语料,也比当前其他大部分网络中使用的单词更为精确。3)UBEN的边上附加了类型,权值等来自于原文档集的信息。那么,这样一种精确定义,并且构建于数量非常有限的文档的网络,它的连通性会怎样呢?对自然语言处理有何意义?

图2 UBEN的生成
实验结果表明:文档集的UBEN通常由一个占绝对数量优势的结点的主要分量和数量不多的、其中包含结点数目相对小得多的分量构成。前者也可称为巨组元(the largest component)[7],这里我们称
为MC(Major Component),而将那些琐碎的分量称为FC(Fragment Component)。为了方便后面陈述,把这种连接特性称为MC-FCs。话题相关UBEN的另一个特性是:FC中的结点入权很低,因而不是多文档中的关键信息,这个特性称为UIFC(Unimportance In Fragment Component)。
6 实验设计与结果
6.1 数据集与实验设计
本节采用DUC2004[15]中用于任务1和任务2,DUC2005[16]的数据集来构建BEN,DUC2004数据集包含来自TDT的50个文档集,每个文档集含有10篇话题相关的文档。DUC2005的数据集包含50个文档集,每个相关文档集中含有25至50篇内容相关的文档。一般情况下,DUC2005的文档比DUC2004的长。在将原文档中的句子拆分成BE时候,采用的是南加州大学(ISI)发布的BE包1.0[17]。
6.2 连接特性描述
为了描述高度相关的文档的UBEN的前面提到的两个特性,表 1中列出了表达UBEN连通性的参量。没有专门设计参数来描述MC,因为相应的数值可以通过对FC的参数简单计算而得。例如,可以通过观察1-Pfc得到MC中的结点数与整个网络中的结点数之比。

表1 描述UBEN连接特性的参数
6.3 实验1: MC-FCs和UIFC特性
对DUC2004和DUC2005中两个随机选择的典型文档集(duc2004d30046t和duc2005d347b)构造的UBEN,表 1中的五个参数的结果见表 2,说明这两个文档集的UBEN满足MC-FCs和UIFC特性。
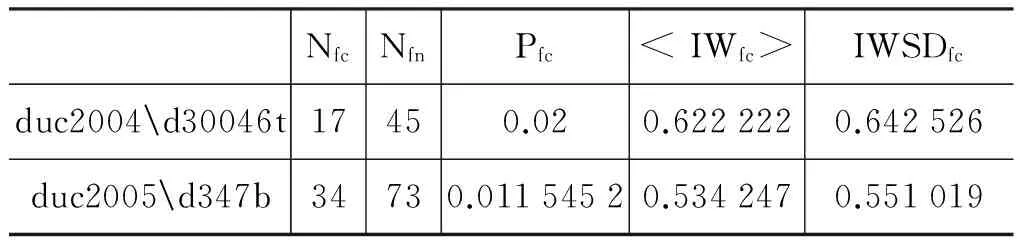
表 2 DUC2004和DUC2005中两个典型多文档的连接性参数
为了说明话题相关文档的UBEN的MC-FCs特性和UIFC特性是一种普遍的现象,对表 1中的五个参数,对DUC2004中的50个文档集和DUC2005中的50个文档集产生的BEN,计算了平均值和标准差,结果见表 3:A04 行和 A05行分别是DUC2004和DUC2005文档集中,表 1中参数的平均值;SD04 行和 SD05行分别是DUC2004和DUC2005文档集中,表 1中参数的标准差。显然,实验结果支持先前描述的结论:TDS的UBEN具备MC-FCs性质和UIFC性质。
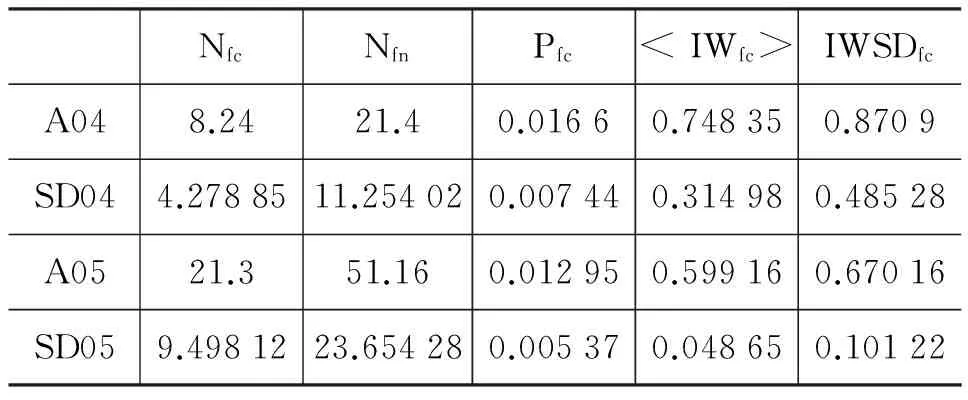
表3 DUC2004和DUC2005中有关连接特性参数的统计数据
6.4 实验2: 停用词对连通性的影响
语言中的停用词具有高度的连接性,这是语言本身的特性。在如此数量有限的文档上,UBEN的高连通性与语言的停用词的高度连接性关系如何?如果去掉停用词,网络的连通性有何变化?为此,设计了表 4中的五种去除停用词的模式,五种模式对消除停用词的影响上,总体上是越来越严格(III和IV哪个的影响更重暂时还不明确)。

表4 去除停用词对网络连通性的影响的五种模式
表 5是DUC2004年的一个典型文档集(d30053t目录)在以上五种模式下,计算出的表 1所列出参量的结果。表 6是DUC2005年的一个典型文档集(d360f目录)在以上五种模式下,计算出的表 1中所列出参量的结果。表 5和表 6均显示,随着消除停用词的影响越来越严格,这两个TDS的UBEN的零碎分量的数目Nfc明显增加,但Nfn,Pfc,
表5 DUC2004的 d30053t 文档集连接特性受去除停用词的影响
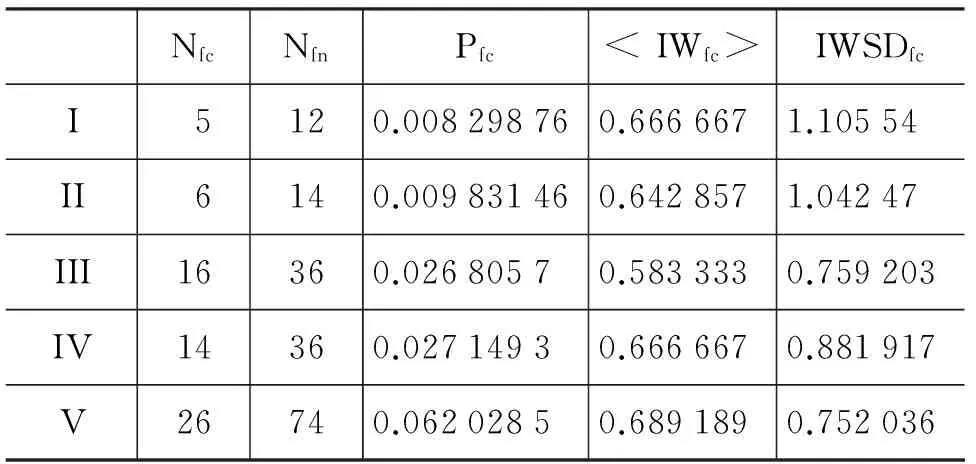
NfcNfnPfc
表6 DUC2005的 d360f 文档集连接特性受去除停用词的影响
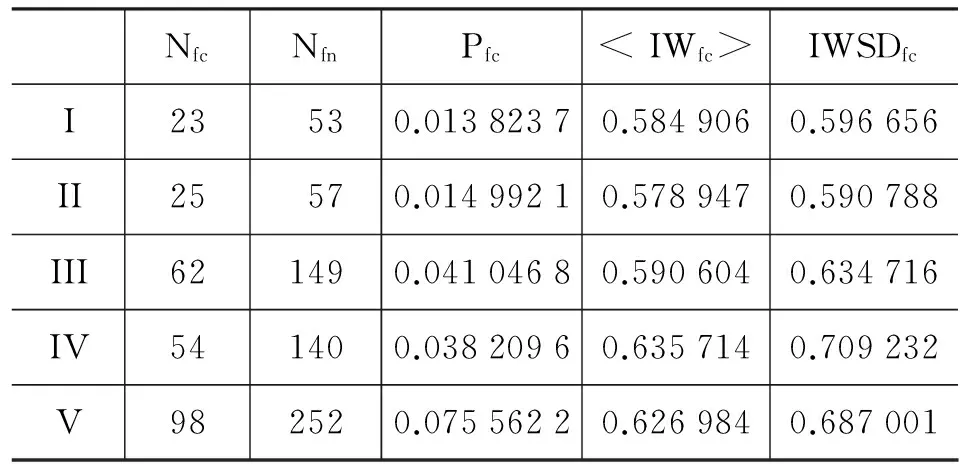
NfcNfnPfc
表 7是对DUC2004和DUC2005的所有文档集连通性参数的统计结果,其中A04,S04列是的所有文档集的五个连接性参量的平均值与标准差,A05,S05列是所有文档集的各个连接性参量的平均值与标准差。可以看出,对DUC2004和DUC2005数据集,文档集的MC-FCs性质和UIFC性质并没有受到停用词很大的影响。五种模式基本对连接性的影响是依次增大的, BEH比BEM的影响相当——模式III比模式IV导致碎分量个数稍微大一点点。这些数据,尤其是模式V的数据说明:停用词对TDS的UBEN的连通特性确实有显著影响,会明显增加碎分量的个数。但MC-FCs和UIFC性质基本不变。可见BEN的高度连通性,可能并非简单地由停用词的高度连接性造成的,很可能大程度上源于文档集内部的相关性。
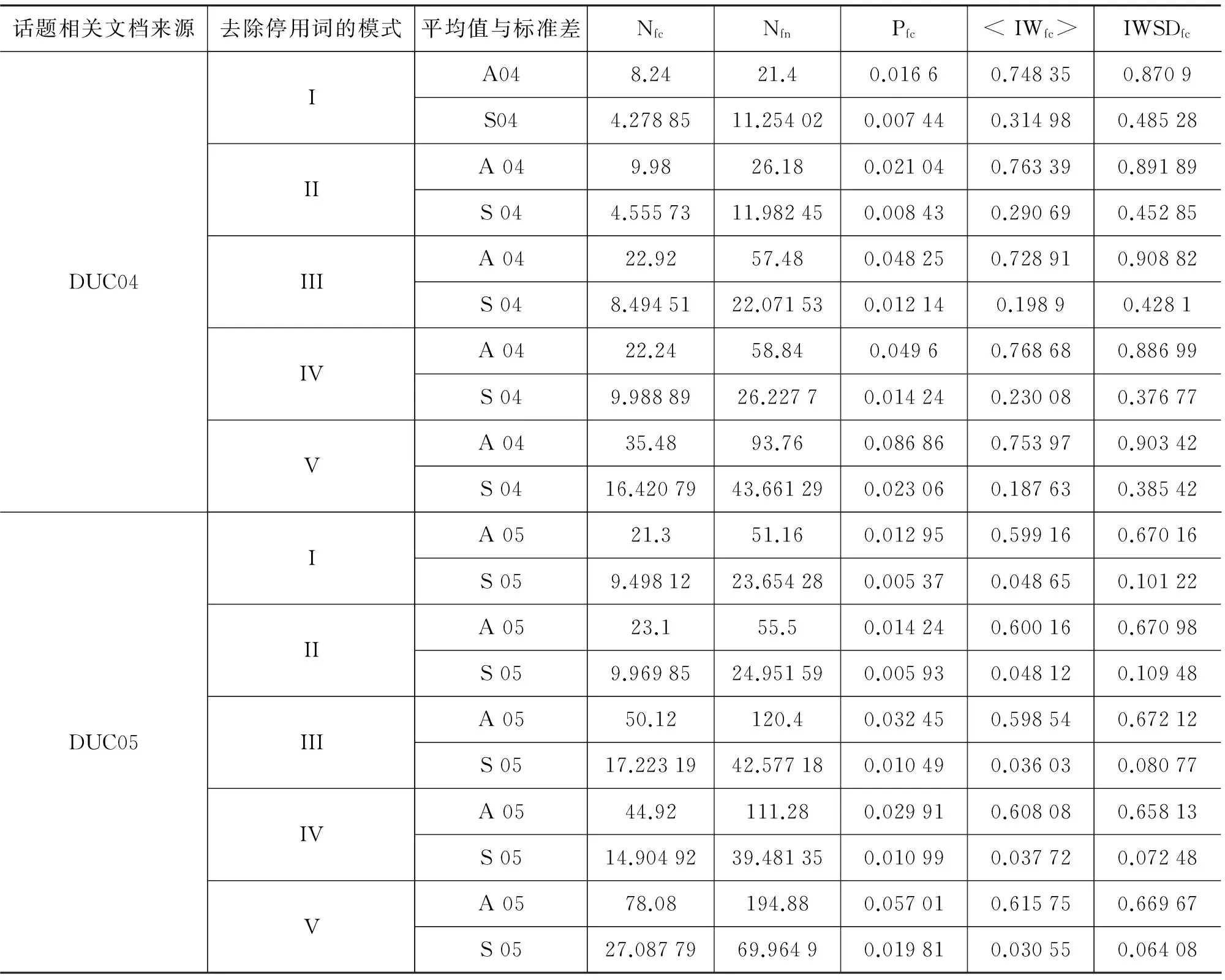
表7 DUC2004和DUC2005数据连接性受到停用词的影响的统计数据
6.5 实验3:随机文档网络与相关文档网络的连接性差异
如前所述,去除停用词能明显增加网络碎分量的个数,但是却不影响其MC-FCs性质和UIFC性质。那么,这个性质是否在一定程度上是文档之间的话题上的相关性导致的呢?为此,还需要比较高度相关的文档集的UBEN与随机文档的UBEN之间的连通性。为此我们设计了如图 3所示的实验。其中对EdgeNum的设置如下,令其分别为:DUC2004的所有BEN的边数的平均值,DUC2005的所有BEN的边数的平均值,即2516和9478,即文献[12]中Table 1中的(I,E),(II,E),这样设置的原因是边数比结点数更能表达原文档集中的信息量。在EdgeNum取定某一值的情况下,分别考察表 4中列出的五种模式下,网络的连通特性。实验的结果如表 8。表中A表示平均值,S表示标准差。

图3 随机文档的UBEN网络的连接性参数的统计特性计算过程
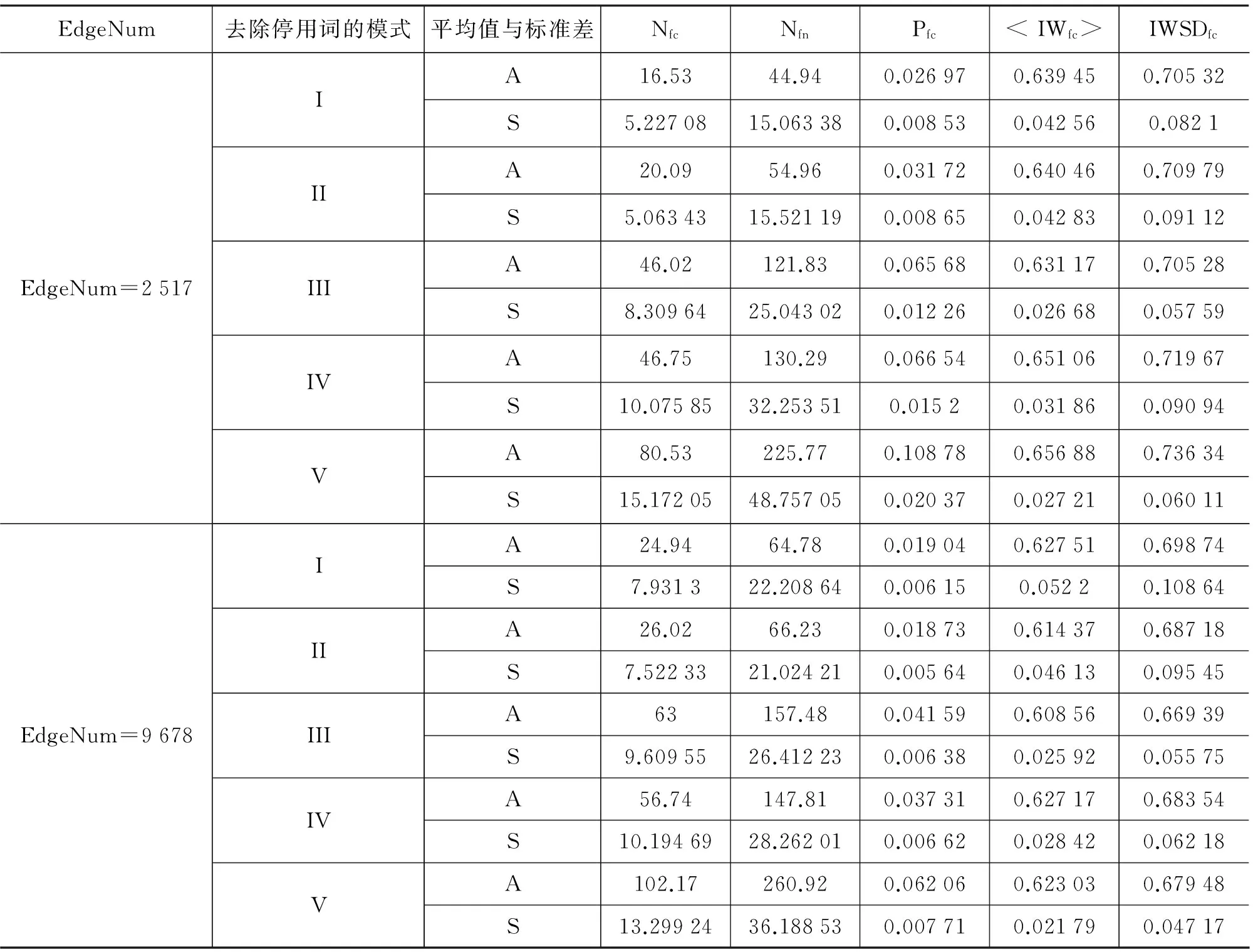
EdgeNum去除停用词的模式平均值与标准差NfcNfnPfc
这样,表 7的DUC2004和DUC2005数据下得到结果与表 8中EdgeNum=2 517,EdgeNum=9 678的数据分别形成了对应,前者表达的是相关文档的网络的连通性,后者表达随机文档的网络的连通性。
观察表 7和表 8,可以得到以下结论:1)随机文档的网络与相关文档的网络都具备MC-FCs性质,但相关文档的MC-FCs性质更显著得多。2)在指定的EdgeNum下,模式I与模式II的连接参数差异不大,这点在表 7中也得到体现。3)停用词会显著影响随机文档的网络的连通分量的个数,但表 7和表 8说明, MC-FCs性质并未发生大的改变。表 8中Nfc与Nfn受BEH和BEM的影响非常接近。而且对于EdgeNum=2 517,BEM的影响反而超过BEH。这点相对于表 7有明显差异。这点可能这样解释:一个非停用词BEH,由于可能是多相关文档的焦点,被从多个角度描述,度数高,一旦被去掉,就会对导致碎分量的大幅增加;然而对于随机文档形成的网络,某个非停用词的BEH,不能得到多个文档的反复提及,从而度数高的概率比较低,BEH对连通性的影响相对来说就降低了,其在通信上的作用就接近了BEM。
如上所述,尽管停用词的去除并没有改变随机文档集或者相关文档集的UBEN的MC-FCs性质和UIFC性质,但是Nfc受到的影响还是很显著的。表 9综合了表 7与表 8中关于Nfc的数据。数据说明:就去除停用BEH和停用BEM对网络碎分量数目的影响,随机文档受到的影响比相关文档的明显得多。这点可能作如下解释:在随机文档的网络中,由于缺乏足够的非停用词形成的关键的通信结点,停用词的去除对通信的影响作用就凸显出来了。比如,不去除停用词时(即I),DUC05的Nfc为21.3, NumScale=9678时Nfc为24.94,差异不大。但是在VI情形,这两个数字却分别为78.08和102.17,有显著差异。所以,Nfc的大小,从一定程度上,能反映文档集的内容相关程度。
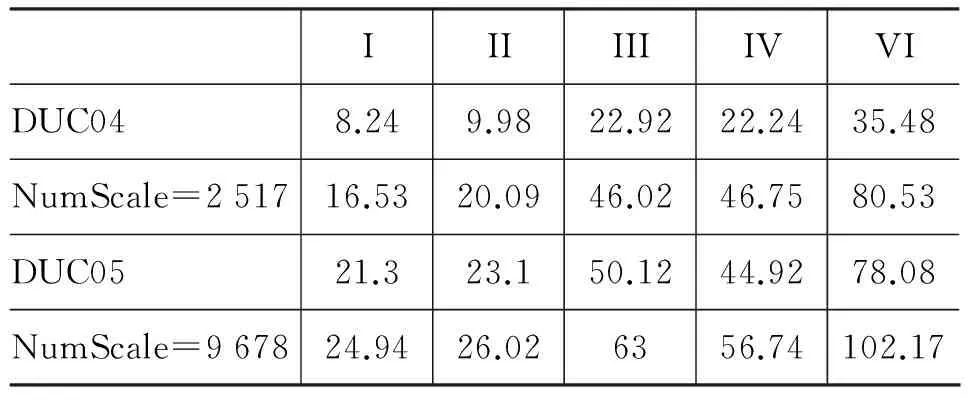
表9 相关文档与随机文档的UBEN的碎分量数Nfc一览
7 结论
调查了网络的连通性,提出了MC-FCs性质,该性质非常利于计算,因为计算可以局限在网络最大连通分量上。MC-FCs性质并不是单纯因为停用词的高连接性造成的,并且在话题相关的文档集的网络上,该性质比在随机的、不相关的文档构成的网络上表现显著得多,这说明MC-FCs一定程度上是话题相关的文档信息融合的结果。这可能为自动文摘提供了一种新的思路: 即基于依存语法和复杂网络理论,进一步,可用于度量“相关文档集”的内容,比如,传统的信息检索系统返回若干“相关文档”,对其中的前K篇文档,不仅要求其与用户的查询高度相关,而且应尽量包含不重复的信息。依据本文的内容,基于该K篇文档构成的UBEN应具备足够高的连通性,因而,UBEN的连通性可作为度量信息检索系统的前K篇文档构成的“文档集”的质量的指标之一。
另外要注意的是:实验中设计的“随机文档”数据,其实还是来自50或者100个话题相关文档,其实还不够随机,因此,真正的随机文档集的UBEN与话题相关文档的UBEN在连通性上的差异都会更大,即本文的结论会更加可靠。
[1] Ferrer I Cancho R, Sole R V. The small world of human language[J]. Royal Society B: Biological Sciences. 2001, 268(1482): 2261-2265.
[2] Ferrer I Cancho R. The structure of syntactic dependency networks: Insights from recent advances in network theory[J]. The Problems of Quantitative Linguistics, Ruta, Chernivtsi. 2005: 60-75.
[3] Sole R V, Murtra B C, Valverde S, et al. Language Networks: their structure, function and evolution[J]. Trends in Cognitive Sciences. 2006.
[4] Mehler A. Large Text Networks as an Object of Corpus Linguistic Studies[C]//Proceedings of the Corpus Linguistics. An International Handbook of the Science of Language and Society. De Gruyter, Berlin/New York. 2007.
[5] Ferrer I Cancho R, Sol R V, K R. Patterns in syntactic dependency networks[J]. Physical Review E Phys Rev E. 2004, 69: 051915.
[6] Motter A E, De M A, Lai Y C, et al. Topology of the conceptual network of language[J]. Science Phys Rev E. 2002, 65: 065102.
[7] Newman M E. The structure and function of complex networks[C]//Proceedings of the Arxiv preprint cond-mat/0303516. 2003.
[8] Steyvers M, Tenenbaum J B. The Large-Scale Structure of Semantic Networks: Statistical Analyses and a Model of Semantic Growth[J]. Cognitive Science. 2001, 29(1): 41-78.
[9] Sigman M, Cecchi G A. Global organization of the Wordnet lexicon[J]. Proceedings of the National Academy of Sciences. 2002, 99(3): 1742-1747.
[10] Steyvers M, Tenenbaum J B. The large-scale structure of semantic networks: statistical analyses and a model for semantic growth[C]//Proceedings of the Arxiv preprint cond-mat/0110012. 2001.
[11] Antiqueira L, Nunes M G, Oliveira J O, et al. Strong correlations between text quality and complex networks features[J]. Physica A: Statistical Mechanics and its Applications. 2007, 373: 811-820.
[12] Yang H, He Y, Ji D, et al. Evaluating Multi-Document's Content: Using Basic Element Complex Networks[J]. Journal of Computational Information Systems. 2008, 4(3): 907-914.
[13] Nenkova A. Understanding the process of multi-document summarization: content selection, rewriting and evaluation[J]. 2006.
[14] Hovy E, Lin C Y, Zhou L. Evaluating DUC 2005 using basic elements[C]//Proceedings of the Fifth Document Understanding Conference (DUC). 2005.
[15] Paul O, James Y. An Introduction to DUC-2004[C]//Proceedings of the 4th Document Understanding Conference (DUC 2004). 2004.
[16] Dang H T. Overview of DUC 2005[C]//Proceedings of the DUC 2005 Workshop at HLT/EMNLP. 2005.
[17] Hovy E, Lin C Y, Zhou L, et al. Basic Elements[C]//Proceedings of the Available from hayden. isi. edu/BE. 2005.
Connectivity of Undirected Basic Element Network Constructed on Document Set of Topic-related Document
YANG Hua1, 2, JI Donghong3, CHEN Bo3,4
(1. School of Mathematics and Computer Science, Guizhou Normal University, Guiyang, 550001, China;2. College of Chinese Language and Literature, Wuhan University, Wuhan, 430072, China;3. School of Computer, Wuhan University, Wuhan, 430072, China;4. Department of Language & Literature, Hubei University of Art & Science, Xiangyang, Hubei 441053)
Based on relatively limited number of documents, undirected basic element networks (UBEN), in which nodes are header or modifier, are constructed. The connectivity of UBEN constructed on topic-related documents is investigated and the stopwords influence on connectivity is discussed. Furthermore, the connectivity difference between UBENs respectively constructed on topic-related documents and randomly-selected documents are contrasted. It is pointed out that connectivity of UBEN construced on topic-related documents are resulted from information fusion of the topic-related documents on some level, instead of from property of language only. This conclusion is of some significance for some natural language processing tasks, such as automatic summarization, information retrieval, etc.
topic-related document set; complex network, automated summarization, information fusion, information retrieval

杨华(1974—),博士后,教授,主要研究领域为自然语言处理。E-mail:yanghuastory@foxmail.com姬东鸿(1967—),博士,教授,博士生导师,主要研究领域为自然语言处理。E-mail:dhji@whu.edu.cn陈波(1976—),副教授,博士,主要研究领域为自然语言处理。E-mail:cb9928@foxmail.com
1003-0077(2015)04-0103-08
2013-06-27 定稿日期: 2014-02-17
国家自然科学基金项目 (61070243);国家社科基金重大项目(11&ZD189);贵州省高层次人才科研项目(TZJF-2010年048号);贵州省科教青年英才培养工程项目(“黔省专合字(2012)155号”);贵州师范大学博士科研启动基金项目(11904-05032110011);中国博士后科学基金项目(2013M531730)
TP391
A
