否定与不确定信息抽取研究综述
2015-04-21邹博伟周国栋朱巧明
邹博伟,周国栋,朱巧明
(苏州大学 自然语言处理实验室,江苏 苏州 215006)
否定与不确定信息抽取研究综述
邹博伟,周国栋,朱巧明
(苏州大学 自然语言处理实验室,江苏 苏州 215006)
否定与不确定表达在自然语言中广泛存在,正确识别此类信息并将其与准确信息分开处理,在信息抽取、情感分析、文本挖掘等自然语言处理任务中具有重要研究价值。自从2008年BioScope语料库发布以来,针对否定与不确定信息抽取研究举办了多次大规模评测会议和学术论坛,为采集语料、明确任务及性能评测等提供了交流平台,否定与不确定信息抽取逐渐成为自然语言处理领域的研究热点。该文简要介绍了否定与不确定信息抽取的研究背景、任务定义、相关语料等,并通过回顾和分析该领域的研究现状,展望未来的发展趋势。
否定信息;不确定信息;自然语言处理
1 研究背景
随着信息抽取技术的发展,越来越多的相关应用试图从海量信息中获取所需要的信息, 在Hobbs[1]提出的信息抽取通用体系中,并没有对信息的准确性进行甄别,因此,若抽取到的知识来源于表示否定、推测或可能等非准确信息(Lakoff[2]),则很难保证所获取知识的可靠性。否定与不确定信息抽取研究目前主要集中在面向生物医学科技文献的信息抽取任务中,根据在BioScope生物医学语料库上的统计,针对实验结果或临床现象的推断通常涉及否定或不确定表达,其比例分别达到13.45%和17.70%,因此,准确识别和抽取否定与不确定信息具有重要意义。近年来,各类面向否定与不确定信息抽取研究的评测会议和专刊的出现,也表明了该研究的重要性: BioNLP’2009事件抽取评测[3]将否定信息和不确定信息抽取作为其三个关键任务之一;CoNLL’2010[4]专门针对不确定信息抽取设置了评测任务;期刊ComputationalLinguistics在2012年第2期出版了针对否定与不确定信息抽取研究的专刊*http://www.mitpressjournals.org/toc/coli/38/2。
Morante等[5]从符号语言学的角度详细描述了否定信息和不确定信息。否定信息通常关系到一个命题运算符及其语义作用范围,它反转了命题的可靠性或真实性;不确定信息描述了事物的或然性,是介于确定和否定之间的表达类型。早期的否定与不确定信息抽取研究一直停留在语言学层面,例如,Horn[6]最早从语言学的角度对否定信息进行了详细地分类。由于不同应用对信息抽取需求的差别,否定与不确定信息抽取通常面向特定领域的信息抽取任务,例如,在面向科技文献的信息抽取研究中,Hyland[7]通过对该领域语料的分析,详细阐述了科技文献中含有大量不确定信息及将其与可靠信息区分处理的思想。随着自然语言处理相关技术的不断发展,开始有研究尝试自动识别否定或不确定信息,例如,Friedman等[8]在生物医学领域最早使用信息抽取技术识别包含否定和不确定信息的语言片段,后来,Friedman等[9]开发了医学语言处理(Medical Language Processing,简写为MLP)平台,该系统能够识别生物医学文献中的否定信息。在否定与不确定信息自动抽取的早期研究中,最著名的系统是由Chapman等[10]开发的基于正则表达式算法的NegEx系统,该系统用于自动识别医学诊断记录中的否定结论,之后,围绕该系统的相关研究一直未间断,逐渐形成了基于启发式规则的否定与不确定信息抽取方法;另一方面,随着BioScope语料库(Vincze 等[11])的公布,以及各种评测会议的开展,大量基于机器学习方法的否定与不确定信息抽取技术开始出现。
目前,否定与不确定信息抽取研究主要围绕以下三个要素: 线索词(Cue)、覆盖域(Scope)和聚焦点(Focus)。线索词是指一句话中能够“标识”出否定或不确定含义的单词或短语,例1和例2中,以粗体表示的“不会”和“可能”分别作为否定线索词和不确定线索词;覆盖域是指线索词的语义覆盖范围,通常为句子中的某一连续片段(以方括号表示),如例1中,否定线索词“不会”否认了命题“在今年夏天之前签下内马尔”的真实性,而“巴塞罗那主席罗塞尔表示”是事实,不在否定线索词的覆盖域内;聚焦点指线索词的语义作用点(以波浪线表示),例如,将例1的否定命题“不会在今年夏天之前签下内马尔”与另一否定命题“不会签下内马尔”比较后,不难发现,前者中的否定线索词“不会”针对的是“在今年夏天之前”,至于会不会在其他时间“签下内马尔”则不知道,据此判断,其聚焦点是“在今年夏天之前”。
例1 巴塞罗那主席罗塞尔表示 [不会在今年夏天之前签下内马尔]。
例2 国际金价持续下跌的原因 [可能是周五塞浦路斯央行卖出黄金储备]。
否定与不确定信息抽取技术已经成功应用在很多自然语言处理方向上。例如,在情感分析中,Turney[12]、Councill等[13]和Li等[14]的研究表明: 情感词对载体的极性不仅与其本身极性相关,还与作用在其上的否定词相关,因此,处于否定词覆盖域中的情感词需要反转极性;同时,不确定词的覆盖域在判断情感强度上也起到了重要作用,例如,“这部电影 [或许真的有他们说得那么好看]。”,正极性的情感词“好看”处于不确定词“或许”的覆盖域中,可降为弱正极性。除了情感分析,否定与不确定信息抽取研究还涉及了以下自然语言处理应用: Averbuch等[15]采用信息增益的方法构建否定上下文信息模版,应用在医学信息搜索引擎中;Bachenko等[16]将不确定信息作为识别欺诈描述文本的指示器之一;Baker等[17]利用自动标注的不确定信息提高了机器翻译系统的性能。
本文简要介绍了否定与不确定信息抽取研究的背景、任务、评测和语料,重点论述和分析了该领域的相关研究及其相互关系,并在篇尾展望了否定与不确定信息抽取研究的未来发展。本文组织如下,第二节简要介绍否定与不确定信息抽取的相关任务及评测标准;第三节介绍该领域中较为成熟的语料库和标注规则;第四节着重介绍否定与不确定信息抽取研究及发展现状;第五节概述现有研究存在的问题,以及对该研究未来的发展趋势进行展望。
2 评测任务
本节介绍了目前否定和不确定信息抽取研究涉及的三个子任务: 线索词识别、覆盖域识别和聚焦点识别,以及任务评测指标。
计算自然语言学会议CoNLL’2010*http://www.inf.u-szeged.hu/rgai/conll2010st/index.html#intro针对不确定信息抽取研究提出了两个子任务[4]: 线索词识别和覆盖域识别。在该评测中,线索词识别任务仅仅要求判断句子中是否包含不确定信息,而未将识别线索词作为目标,目前大多数研究通常会给出线索词识别的性能;覆盖域识别任务要求根据前一任务中识别的线索词,判断该句子内部表示不确定含义的片段。Blanco等[18]发现否定覆盖域中的内容在很多情况下可以再进一步分为事实内容和否定内容,该区分对更细粒度的文本语义理解具有重要意义。基于此,Blanco等提出了面向否定信息的聚焦点识别任务。该任务的主要目标是,在线索词的覆盖域中,识别其针对或强调的内容。Blanco等还基于PropBank语料库[19]标注了聚焦点识别语料。
以上提到的三个子任务具有不同侧重点: 线索词作为一种语义标记*注意: 并非所有否定或不确定词都可以作为线索词。例如,在否定信息识别任务中,本文认为双重否定属于一种修辞方式,而非真正意义上的否定。,其作用是标识出句子中包含的否定或不确定语义;覆盖域则划定了否定或不确定语义延伸的范围,重点在于指示出线索词管辖的片段;而聚焦点则是对否定或不确定内容更细粒度的表示,是覆盖域中被强调的部分。现有研究通常面向否定或不确定信息,针对其中一个或若干子任务开展研究工作。
目前通常使用两类指标来衡量否定与不确定信息抽取系统的性能: (1)正确率(Accuracy)。正确率以句子为基本单位,要求系统结果与正确答案严格匹配,该指标反映了系统判断出正确结果的能力;(2)准确率(Precision)、召回率(Recall)和F值。该指标通常以进行判别的实例为基本单位,反映了系统能够正确判断给定句子中是否包含否定或不确定信息的能力。
3 语料资源
2008年BioScope语料库出现之前,大多数研究通常采用人工或半自动方法收集否定或不确定信息语料,例如,Medlock等[20]以线索词为特征,从生物医学文献中半自动获取包含不确定信息的训练样本。常用的否定与不确定信息抽取语料有: (1) BioScope生物医学语料库。该语料库标注了否定和不确定线索词及其覆盖域;(2) 维基百科语料。该语料利用维基百科中缺乏事实证明的描述文本(Weasels)构建语料。
3.1 BioScope语料库
为体现生物医学文献中语言的异构性,BioScope语料库[11]包含了四种不同来源的语料: GENIA语料库[21]中的文本摘要语料、五篇果蝇功能基因组文献的全文、四篇英国医学委员会(BMC)生物信息学网站的开源文章以及1 954篇放射学临床报告。其中,GENIA语料库是一个生物医学文献集合,BioScope语料库包含了其中的1 999条联机医学文献分析和检索系统的摘要,主题为“人”、“血细胞”和“副本因子”。标注者手工针对BioScope语料库中14 541个句子标注了否定和不确定线索词及其覆盖域。BioScope语料库根据语料类型不同分为三个子语料库,分别为摘要(Abstract)语料库、全文(Full Paper)语料库和临床记录(Clinical Report)语料库,详细统计信息如表1所示。
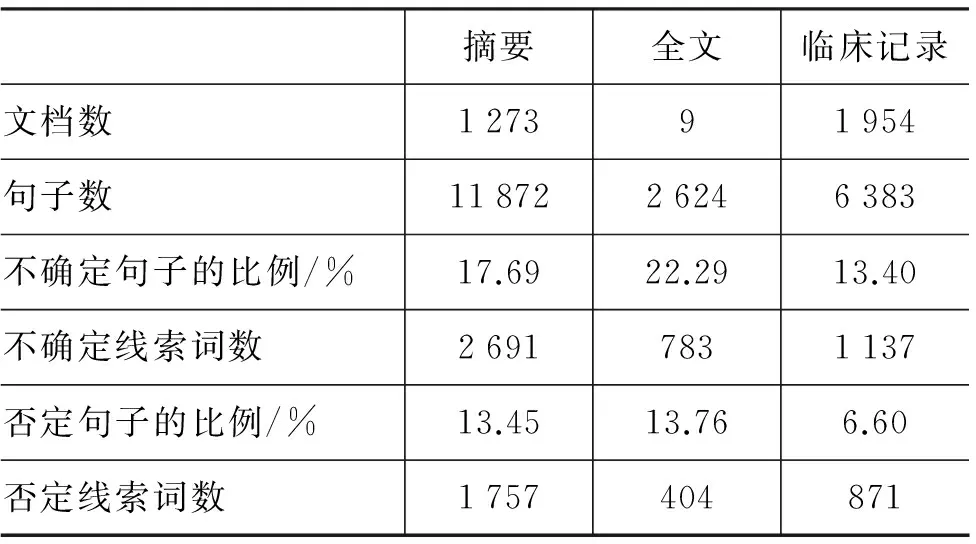
表1 BioScope语料库统计信息
CoNLL’2010评测在BioScope语料库的基础上构建了评测任务的测试数据集,该语料集合增加了1篇随机从2009年10月BMC生物信息学专刊上获取的论文全文和五篇GENIA语料库的论文全文,全文语料总数为15篇,摘要语料和临床记录语料则与BioScope语料库一致。此外,评测机构还提供了未标注的150篇PubMed Central全文,这部分数据与标注数据一样进行了预处理工作,以此作为领域内的数据样本,供评测者使用。
3.2 维基百科语料
维基百科(Wikipedia)是基于wiki技术的多语言百科全书协作计划,任何人都可以编辑维基百科中的任何文章及条目,但其要求编辑者针对缺乏证据支持的内容添加模糊标签*http://simple.wikipedia.org/wiki/Wikipedia:WEASEL(Weasel Tag),此类数据通常为缺乏证据支持的观点或阐述,其中包含了大量无证据的推断,因此被认为是不确定信息,维基百科要求分离出此类信息,以便在证据充足或得到补充时对其重新编辑。Ganter等[22]认为这些片段与Hyland[7]对模糊信息的描述相似,因此,Ganter等通过维基百科收集了这类信息并进行人工标注。但由于维基百科更新速度快,模糊标签存在时间短且特别稀疏,抽取出的语料规模较为有限。
CoNLL’2010评测也同时采用了维基百科作为语料来源之一,随机抽取了438个Weasel段落,人工标注了最常见的不确定线索词,然后在其他维基百科段落中抽取包含这些不确定线索词的句子作为训练数据和测试数据,但该语料没有标注出线索词对应的覆盖域信息。CoNLL’2010评测中的不确定句子识别任务收集了11 111个句子作为训练集,其中2 484个句子包含不确定信息;测试集使用了9 634个句子,其中2 234个句子含有不确定信息。维基百科语料的相关数据统计见表2。评测会议还提供了100万条经过预处理但未标注的维基百科段落,作为领域内的数据样本供评测者使用。

表2 维基百科语料统计信息
4 研究现状
有关否定与不确定信息的研究最初仅局限于语言学,Friedman等[8]首次将否定与不确定信息抽取技术引入自然语言处理领域。早期的相关研究大多基于启发式规则的方法识别否定与不确定信息,此类方法实现简单并且准确率较高,但其可扩展性差;后来,研究者通过构建否定与不确定信息语料库,借助机器学习方法,利用各种自然语言处理模型来抽取否定与不确定信息。
4.1 线索词识别研究
早期的线索词识别任务往往以判断句子中是否包含否定或不确定信息为目标,这样即便没有正确识别线索词也可能导致最终的检测结果正确,因此,大多数研究将正确识别线索词作为评价否定与不确定信息抽取方法的主要指标。线索词识别研究的方法包括基于词表、基于模版、基于统计和基于序列标注等方法。
基于词表的线索词识别研究依赖于构建线索词词表。Kilicoglu等[24]提出了一种基于词表的半自动方法,为构建和精炼这个词表,Kilicoglu等从WordNet和生物医学的专业词表中手工提取了不确定概念和事实概念的语义和词法关系,添加到词表中,用来判断句子中是否包含不确定信息或者事实型信息。
基于模版的线索词识别研究的关键在于模版的准确获取与可扩展性。Sanchez等[25]构建了基于完全依存分析的启发式系统,用于识别生物学文本中否定的蛋白质相互作用信息,该系统使用线索词和句法树特征寻找否定表达的潜在结构。
基于统计的线索词识别研究的重点在于如何获取各种有效的句法或语义特征,并将其进行筛选和融合,获得有效的全局特征。Light等[26]以词作为特征,尝试使用支持向量机(Support Vector Machine)分类器判断医学论文摘要中的句子是否包含不确定信息;后来Georgescul[27]利用基于高斯径向基核函数(Gaussian Radial basis Kernel Function)的SVM分类器改进了Light的方案,并通过调整类别权重克服了训练数据不平衡的问题,在Georgescul的系统中同样仅使用了词特征,取得了CoNLL’2010-Task1W(基于维基百科语料的不确定句子识别子任务)评测的最好性能,F值达到60.2%。Özgür等[28]采用线索词的多种特征进行融合,包括词干、词性、位置、依存关系、前后词及关键词共现等特征,通过SVM分类器识别线索词。Øvrelid等[29]将线索词识别问题看作二元分类问题,判断每个单词是否是线索词,其使用的特征包括词、词原型、词性及句法范畴等信息。
由于线索词可能由多个连续的单词构成,因此有些研究将线索词的识别任务转化为序列标注问题。Tang等[30]采用基于条件随机场模型(Conditional Random Field Model)的序列标注方法和大规模基于边界模型(Large Margin-based Model)分类器训练数据,以词性、命名实体和组块等作为特征,取得了CoNLL’2010-Task1B(基于BioScope语料的不确定句识别子任务)的最好性能,F值为86.4%,而在Wikipedia数据集上却仅取得了55%的F值,同一方法在不同领域中表现出了不同的性能,表明基于序列标注的线索词识别方法依赖于领域内的文本特征;Verbeke等[31]提出了基于kLog[32]的核方法来解决不确定线索词识别任务,其特点在于能够将上下文信息转化成图模型,使用基于图的核函数来获取句子内部词之间的关系,从而识别线索词,Verbeke在CoNLL’2010提供的Wikipedia数据集进行了实验,将F值提高到61.5%(该任务的评测最好结果为60.2%)。
4.2 覆盖域识别研究
最早的覆盖域识别系统是由Chapman等[10,33]开发的基于正则表达式的NegEx系统,该系统根据一个由183个否定词/短语组成的线索词列表识别否定信息,并规定距离线索词六个窗口以内为否定线索词的覆盖域;Goldin等[34]扩展了NegEx系统的功能,利用基于统计的朴素贝叶斯和基于符号规则的决策树分类器,判断该词窗口是否可以作为覆盖域;Goryachev等[35]在哈佛医学院的一份技术报告中指出,他们比较了四种不同的否定线索词识别方法的性能,在1 745份出院报告数据集上的实验表明,基于正则表达式方法优于基于分类的方法,其中ExNeg系统性能最好。Harkema等[36]针对生物医学信息抽取研究开发了ConText系统,该系统是ExNeg系统的升级扩展版,采用了上下文中线索词、伪线索词及其覆盖域等特征,ConText系统不仅识别否定信息,还能够识别假设或经验等非事实性信息。目前,覆盖域识别研究大体可划分为基于启发式规则的方法与基于机器学习的方法两类。
基于启发式规则的覆盖域识别研究大多通过寻找和提取线索词与其覆盖域中某些元素的关系,生成模版或规则,这些关系通常包括句法关系、实体关系或浅层语义关系等。Huang等[37]首次提出在句法树结构上,利用启发式规则判定句法树结点是否处于某个否定词的作用范围之内。然而,这种基于句法规则的方法往往针对某一类线索词的覆盖域识别任务比较有效,但可扩展性较差,很难延伸到其他类别的覆盖域识别任务上。Rokach等[38]提出了一种基于模版的方法识别否定词的作用范围,该方法的好处是可以自动学习和提取模版,尤其是当线索词为短语时,该方法的性能明显好于现有的基于机器学习的方法。Özgür[28]利用基于句法特征模版的启发式规则判断不确定线索词的覆盖域,在BioScope的文摘语料和全文语料上分别取得了79.89%和61.13%的准确率。Øvrelid[29]则将依存句法结构引入不确定词覆盖域识别的研究中,定义启发式规则,识别不确定线索词的覆盖域。Apostolova[39]从BioScope语料库中自动抽取出一套“词-句法”模式集合,然后利用这个模式集合识别否定词和不确定词的覆盖域,这种基于规则的方法取得了与机器学习算法相当的性能。
自2008年BioScope语料库发布后,基于机器学习的覆盖域识别研究成为热门。Morante等[40]首次采用机器学习方法对否定词的覆盖域进行识别,他们将覆盖域识别问题看作分类问题,针对每个给定的否定词,从左至右依次判断句子中的每一个单词是否落入该否定词的覆盖域之内,最后根据标记结果,进行后处理,以确保每个否定词的覆盖域都是连续的。Morante等[41]将多分类器方法优化到单分类器,采用基于存储算法的分类器,并且在浅层句法特征的基础上加入了依存句法特征,获得了CoNLL’2010-Task2(覆盖域识别子任务)评测的最好性能,F值达到57.3%。Zhu等[42]和Li等[43]发现,在语义角色标注中,谓词的作用范围与覆盖域类似,如果将线索词看作谓词,则覆盖域识别的问题就可以转化为论元标注问题,通过该想法,他们提出了一种基于简化的浅层语义分析模型的覆盖域识别方法。Zou等[44]采用基于树核的方法获取覆盖域的句法结构特征,同时还针对不同词性的线索词自动建立各自独立的分类器,在BioScope文章摘要语料库上,将否定线索词和不确定线索词的覆盖域识别任务的性能(F值)分别提高到76.90%和84.21%。
除了线索词和覆盖域识别研究,针对否定和不确定信息其他要素(例如聚焦点、实体等)进行识别的相关研究较少。本文第二章中提到聚焦点识别任务,该任务识别覆盖域中线索词所强调的内容,属于更细粒度的否定与不确定信息抽取任务,由Blanco等[18]首次提出,该研究通过自动标注动词性谓词的语义角色来判断与动词相关的否定线索词的聚焦点。此外,Elkin等[45]采用否定赋值语法规则识别电子病例中被否定或具有不确定性的概念,如实体、事件等。
5 研究发展与趋势
目前,否定与不确定信息抽取研究大都集中在句子内部线索词及其覆盖域识别任务上,针对此类任务,相关研究机构组织了大量的评测会议和学术论坛,并发布了标准语料库。然而,在否定与不确定信息抽取研究中,仍存在很多问题没有解决甚至没有提出。本章将具体阐述否定与不确定信息抽取研究未来的发展趋势,主要集中在以下几个方面:
(1) 语义层面的否定与不确定信息抽取研究
BioScope语料库的标注规范和CoNLL’2010评测中均将否定与不确定线索词对应的覆盖域定义为其句法作用范围,这种定义使得覆盖域识别任务受到句法分析的严重制约,Morante等[23]指出,按照该定义,覆盖域通常会将被否定或不确定线索词所修饰的主语排斥在外。因此,否定与不确定信息抽取研究需要从语义上划分出更细粒度的要素。Blanco等[18]首次提出了聚焦点识别任务,重点研究否定线索词语义上所修饰的内容。随着浅层语义分析技术的不断发展,否定与不确定信息抽取将涉及更多语义层面的研究,例如,否定或不确定线索词的修饰目标(实体、事件等),否定或不确定信息的发布者,以及与这些目标相关联的各种语义角色等。
(2) 面向篇章的否定与不确定信息抽取研究
如本章开头所述,目前,否定与不确定信息抽取研究的对象往往集中在句子内部,如果这些信息分布在篇章的不同句子中(如对话、问答等),则无法通过现有的检测技术识别此类信息。因此,跨句子的否定与不确定信息抽取将成为领域内的研究重点,这就对系统正确识别线索词、覆盖域及聚焦点等提出了更高的要求,而仅依赖句法结构的方法无法完全解决这一问题,需要结合篇章结构分析、指代消解等技术来实现面向篇章的否定与不确定信息抽取研究。
(3) 隐式线索词的否定与不确定信息抽取研究
现有研究在抽取否定或不确定信息时,均以是否存在线索词为标准,然而,在某些特殊的上下文语境中,存在不含明显线索词的否定与不确定信息。例如,“你要对这件事负法律责任!”“谁说的?”,这段问答中并没有出现明显的否定线索词,但根据上下文不难理解,第二个说话者否定了前者的论断,反问修辞代替了否定线索词的功能;再例如,“桑托斯俱乐部对允许内马尔转会一事并没有明确表态。”“只有获得桑托斯俱乐部的批准,内马尔才能在诺坎普亮相。”,这两段话表述了两件事,一是桑托斯俱乐部是否允许内马尔转会是不确定的,二是说没有这个允许内马尔就不能在新东家亮相,前一描述中“没有明确表态”即为不确定信息的线索,表明该事件不确定,而后一描述中没有任何线索,但根据上下文的含义可知,内马尔不能在诺坎普亮相这一事件也是不确定的,前后事件之间的条件关系使得这种不确定性得到传递。通过对以上两个例子的分析表明,隐式线索词的否定与不确定信息抽取需要借助上下文中更多的隐含信息,以及实体或事件之间的潜在关联进行识别。
(4) 面向汉语的否定与不确定信息抽取研究
面向英语的否定与不确定信息自动抽取研究已经取得了初步的成果,然而,面向汉语的否定与不确定抽取研究仍处于摸索阶段。目前有两方面问题亟待解决: 第一个问题是语料库的构建。语料库建设是开展相关研究的重要基础,除了通过人工标注的途径,本文认为可以利用已有语料(如Chinese PropBank)尝试自动辅助人工标注构建汉语否定与不确定信息抽取语料库,其优点在于既降低了标注成本,又使得在使用该语料的同时,可以利用其他标注信息。否定与不确定信息属于语义层面的表述,依赖于具体语言特征(如语法、修辞等),因此,开展面向汉语的否定与不确定信息抽取研究的第二个问题在于,需要有针对性地引入适应汉语的相关自然语言处理技术。
6 总结
综上所述,否定与不确定信息抽取研究主要集中在线索词识别和覆盖域界定两个子任务上,在生物医学自然语言处理领域已经取得了初步的成果,并应用于相关领域的信息抽取、情感分析和问答技术等任务中。随着BioScope语料库的发布和CoNLL’2010评测的开展,否定与不确定信息抽取研究逐渐成为自然语言处理领域的研究热点。
目前,大多数否定与不确定信息抽取研究集中在句法层面,严重依赖于句法分析的结果,因此,需要在语义层面定义更细粒度的否定与不确定信息要素;其次,跨句子的否定与不确定信息很难使用现有方法进行抽取,借助篇章结构分析的相关技术可以收集到更多的上下文信息,实现基于篇章的否定与不确定信息抽取;此外,在某些特定的上下文环境中,并没有明显的线索词指示出否定或不确定信息,需要依靠事件或实体之间的关系进行推理,从而识别此类否定或不确定信息;最后,面向汉语的否定与不确定信息自动抽取研究刚刚起步,面临着语料库匮乏的问题,同时,如何获得有效特征也是亟待解决的问题。
总之,否定与不确定信息抽取研究仍未完善,未来的研究将集中在: 语义层面的否定与不确定信息要素抽取研究;面向篇章的否定与不确定信息抽取研究;隐式线索词的否定与不确定信息抽取研究;以及面向汉语的否定与不确定信息抽取研究等方面。
[1] Hobbs J R. The Generic Information Extraction System[C]//Proceedings of the 5th conference on Message understanding. Stroudsburg, PA, USA: Association for Computational Linguistics, 1993: 87-91.
[2] Lakoff G. Linguistics and Natural Logic[J]. Journal of Synthese, 1972, 22(2): 151-271.
[3] Kim J D, Ohta T, Pyysalo S, et al. Overview of BioNLP’09 Shared Task on Event Extraction[C]//Proceedings of the BioNLP’2009 Workshop Companion Volume for Shared Task. Stroudsburg, PA, USA: Association for Computational Linguistics, 2009: 1-9.
[4] Farkas R, Vincze V, Mora G, et al. The CoNLL’2010 Shared Task: Learning to Detect Hedges and their Scope in Natural Language Text[C]//Proceedings of the 14th Conference on Computational Natural Language Learning. Stroudsburg, PA, USA: Association for Computational Linguistics, 2010: 1-12.
[5] Morante R and Sporleder C. Modality and Negation: An Introduction to the Special Issue[J]. Computational Linguistics, 2012, 38(2): 223-260.
[6] Horn L R. A Natural History of Negation[M]. Chicago: Univ. of Chicago Press, 1989.
[7] Hyland K. Hedging in Scientific Research Articles[M]. Amsterdam: John Benjamins, 1998.
[8] Friedman C, Alderson P O, Austin J, et al. A General Natural-language Text Processor for Clinical Radiology[J]. Journal of the American Medical Informatics Association, 1994, 1(2):161-174.
[9] Friedman C and Hripcsak G. Natural Language Processing and its Future in Medicine[J]. Journal of Academic Medicine, 1999, 74(8):890-895.
[10] Chapman W W, Bridewell W, Hanbury P, et al. A Simple Algorithm for Identifying Negated Findings and Diseases in Discharge Summaries[J]. Journal of Biomedical Informatics, 2001, 34(5):301-310.
[11] Vincze V, Szarvas G, Farkas R, et al. The BioScope Corpus: Biomedical Texts Annotated for Uncertainty, Negation and their Scopes[J]. Journal of BMC Bioinformatics, 2008, 9(11):S9.
[12] Turney P D. Thumbs Up or Thumbs Down? Semantic Orientation Applied to Unsupervised Classification of Reviews[C]//Proceedings of the 40th Annual Meeting on Association for Computational Linguistics. Stroudsburg, PA, USA: Association for Computational Linguistics, 2002: 417-424.
[13] Councill I G, McDonald R, Velikovich L. What’s Great and What’s Not: Learning to Classify the Scope of Negation for Improved Sentiment Analysis[C]//Proceedings of the Workshop on Negation and Speculation in Natural Language Processing. Stroudsburg, PA, USA: Association for Computational Linguistics, 2010: 51-59.
[14] Li SS, Lee YM, Chen Y, et al. Sentiment Classification and Polarity Shifting[C]//Proceedings of the 23rd International Conference on Computational Linguistics. Stroudsburg, PA, USA: Association for Computational Linguistics, 2010: 635-643.
[15] Averbuch M, Karson T, Ben-Ami B, et al. Context-Sensitive Medical Information Retrieval[J]. Journal of Studies in Health Technology and Informatics, 2004, 107(Pt1): 282-286.
[16] Bachenko J, Fitzpatrick E and Schonwetter M. Verification and Implementation of Language-Based Deception Indicators in Civil and Criminal Narratives[C]//Proceedings of the 22nd International Conference on Computational Linguistics. Stroudsburg, PA, USA: Association for Computational Linguistics, 2008: 41-48.
[17] Baker K, Bloodgood M, Dorr B J, et al. A Modality Lexicon and Its Use in Automatic Tagging[C]//Proceedings of the 7th Conference on International Language Resources and Evaluation, 2010: 1402-1407.
[18] Blanco E and Dan Moldovan. Semantic Representation of Negation Using Focus Detection[C]//Proceedings of 49th Annual Meeting of the Association for Computational Linguistics, Stroudsburg, PA, USA: Association for Computational Linguistics, 2011: 19-24.
[19] Palmer M, Gildea D, Kingsbury P. The Proposition Bank: An Annotated Corpus of Semantic Roles. Computational Linguistics[J], 2005, 31(1):71-106.
[20] Medlock B, Briscoe T. Weakly Supervised Learning for Hedge Classification in Scientific Literature[C]//Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics. Stroudsburg, PA, USA: Association for Computational Linguistics, 2007: 992-999.
[21] Collier N, Park H S, Ogata N. The GENIA Project: Corpus-Based Knowledge Acquisition and Information Extraction from Genome Research Papers[C]//Proceedings of the 9th Conference on European Chapter of the Association for Computational Linguistics. Stroudsburg, PA, USA: Association for Computational Linguistics, 1999: 271-272.
[22] Ganter V, Strube M. Finding Hedges by Chasing Weasels: Hedge Detection Using Wikipedia Tags and Shallow Linguistic Features[C]//Proceedings of the ACL-IJCNLP 2009 Conference Short Papers. Stroudsburg, PA, USA: Association for Computational Linguistics, 2009: 173-176.
[23] Morante R, Schrauwen S, Daelemans W. Corpus-based Approaches to Processing the Scope of Negation Cues: an Evaluation of the State of the Art[C]//Proceedings of 9th International Conference on Computational Semantics. Bos J. and Pulman S. (editors), 2011: 350-354.
[24] Kilicoglu H, Bergler S. Recognizing Speculative Language in Biomedical Research Articles: A Linguistically Motivated Perspective[J]. Journal of BMC Bioinformatics, 2008, 9(11):S10.
[25] Sanchez G O, Poesio M. Negation of Protein-Protein Interactions: Analysis and Extraction. Journal of BMC Bioinformatics[J], 2007, 23(13): 424-432.
[26] Light M, Qiu XY, Srinivasan P. The Language of Bioscience: Facts, Peculations, and Statements in Between[C]//Proceedings of the HLT BioLINK’2004. Stroudsburg, PA, USA: Association for Computational Linguistics, 2004: 17-24.
[27] Georgescul M. A Hedgehop over a Max-Margin Framework Using Hedge Cues[A]//Shared Task Proceedings of the 14th Conference on Computational Natural Language Learning. Stroudsburg, PA, USA: Association for Computational Linguistics, 2010: 26-31.
[28] Özgür A, Radev D R. Detecting Speculations and their Scopes in Scientific Text[C]//Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA, USA: Association for Computational Linguistics, 2009: 1398-1407.
[29] Øvrelid L, Velldal E, Oepen S. Syntactic Scope Resolution in Uncertainty Analysis[C]//Proceedings of the 23rd International Conference on Computational Linguistics. Stroudsburg, PA, USA: Association for Computational Linguistics, 2010: 1379-1387.
[30] Tang BZ, Wang XL, Wang X, et al. A Cascade Method for Detecting Hedges and their Scope in Natural Language Text[C]//Proceedings of the 14th Conference on Computational Natural Language Learning. Stroudsburg, PA, USA: Association for Computational Linguistics, 2010: 13-17.
[31] Verbeke M, Frasconi P, Van Asch V, et al. Kernel-based Logical and Relational Learning with kLog for Hedge Cue Detection[C]//Proceedings of the 22th Meeting of Computational Linguistics in the Netherlands. Tilburg, the Netherlands, 2011: 1-6.
[32] Frasconi P, Costa F, De Raedt L, et al. KLog-A Language for Logical and Relational Learning with Kernels[R]. http://www.dsi.unifi.it/~paolo/ps/klog.pdf. 2011.
[33] Chapman W W, Hanbury P, Cooper G F, et al. 2001. Evaluation of Negation Phrases in Narrative Clinical Reports[C]//Proceedings of the American Medical Informatics Association Symposium. Washington, DC, 2001: 105-109.
[34] Goldin I M, Chapman W W. Learning to Detect Negation with ‘Not’ in Medical Texts[C]//Workshop at the 26th ACM SIGIR Conference. 2003.
[35] Goryachev S, Sordo M, Zeng QT, et al. Implementation and Evaluation of Four Different Methods of Negation Detection[R]. Technical Report, DSG. 2006.
[36] Harkema H, Dowling J N, Thornblade T, et al. ConText: An Algorithm for Determining Negation, Experiencer, and Temporal Status From Clinical Reports[J]. Journal of Biomedical Informatics, 2009,42(5): 839-851.
[37] Huang Y, Lowe HJ. A Novel Hybrid Approach to Automated Negation Detection in Clinical Radiology Reports[J]. Journal of the American Medical Informatics Association, 2007, 14(3):304-311.
[38] Rokach L, Romano R, Maimon O. Negation Recognition in Medical Narrative Reports[J]. Information Retrieval Online, 2008, 11(6): 499-538.
[39] Apostolova E, Tomuro N, Fushman D D. Automatic Extraction of Lexico-Syntactic Patterns for Detection of Negation and Speculation Scopes[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies: short papers-Volume 2. Stroudsburg, PA, USA: Association for Computational Linguistics, 2011: 283-287.
[40] Morante R, Liekens A, Daelemans W. Learning the Scope of Negation in Biomedical Texts[C]//Proceedings of the 2008 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA, USA: Association for Computational Linguistics, 2008: 715-724.
[41] Morante R, Van Asch V, Daelemans W. Memory-Based Resolution of In-Sentence Scopes of Hedge Cues[C]//Proceedings of the 14th Conference on Computational Natural Language Learning. Stroudsburg, PA, USA: Association for Computational Linguistics, 2010: 40-47.
[42] Zhu QM, Li JH, Wang HL, et al. A Unified Framework for Scope Learning via Simplified Shallow Semantic Parsing[C]//Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA, USA: Association for Computational Linguistics, 2010: 714-724.
[43] Li JH, Zhou GD, Wang HL, et al. Learning the Scope of Negation via Shallow Semantic Parsing[C]//Proceedings of the 23rd International Conference on Computational Linguistics. Stroudsburg, PA, USA: Association for Computational Linguistics, 2010: 671-679.
[44] Zou BW, Zhou GD, Zhu QM. Tree Kernel-based Negation and Speculation Scope Detection with Structured Syntactic Parse Features[C]//Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing. Seattle, Washington, USA: Association for Computational Linguistics, 2013: 968-976.
[45] Elkin PL, Brown SH, Bauer BA, et al. A Controlled Trial of Automated Classification of Negation from Clinical Notes[J]. BMC Medical Informatics and Decision Making, 2005, 5(13):13.
Negation and Speculation Extraction: An Overview
ZOU Bowei, ZHOU Guodong, ZHU Qiaoming
(Natural Language Processing Lab, Soochow University, Suzhou, Jiangsu 215006,China)
Negation and speculation expressions exist extensively in natural language. Identifying and separating them from the reliable information have important value for many natural language processing tasks, such as information extraction, sentiment analysis, and text mining. Since the release of BioScope corpus in 2008, several large-scale evaluation conferences and workshops provided platforms for scholars to collect corpora, define tasks, and perform evaluations. Negation and speculation information extraction has gradually become a hot topic in nature language processing in recent years. This survey mainly introduces the research background, task definition, and corpora for negation and speculation information extraction. In addition, this paper also reviews and analyzes the present researches, and outline its developing trends.
negation; speculation; natural language processing

邹博伟(1984—),博士研究生,主要研究领域为自然语言处理、信息抽取。E-mail:zoubowei@gmail.com周国栋(1967—),博士,教授,主要研究领域为自然语言处理、信息抽取。E-mail:gdzhou@suda.edu.cn朱巧明(1964—),博士,教授,主要研究领域为中文信息处理、分布式计算。E-mail:qmzhu@suda.edu.cn
1003-0077(2015)04-0016-09
2013-08-19 定稿日期: 2015-06-16
国家自然科学基金(61272260, 61331011, 61273320),江苏省高校自然科学基金重大项目(11KJA520003)
TP391
A
