复句关系词规则生成系统中的冲突检测与处理
2015-04-21杨进才王中华胡金柱
杨进才,谢 芳,王中华,胡金柱
(1. 华中师范大学 计算机学院,湖北 武汉 430079;2. 湖北工业大学 计算机学院,湖北 武汉 430068)
复句关系词规则生成系统中的冲突检测与处理
杨进才1,谢 芳2,王中华1,胡金柱1
(1. 华中师范大学 计算机学院,湖北 武汉 430079;2. 湖北工业大学 计算机学院,湖北 武汉 430068)
复句中的关系词对研究复句中各分句的语义关系有着重要意义,在基于规则的关系词自动识别中需要大量的规则,并且规则库是动态变化和不断完善的,向规则库中入库规则时会出现规则冲突和入库错误的情况,该文探讨如何在入库时识别产生冲突的规则,并对规则进行相关的处理。对复句的普通规则、连用词规则、普通句式规则、连用句式规则四类规则进行了形式化的表示与存储,在此基础上设计了关系词检测、约束类型检测、约束条件检测、结论检测的检测流程。提出了两种冲突处理方式——优先级方式和有向无环图方式,对两种方法进行了比较。利用该检测方法和有向无环图的处理方式,入库了千余条规则。实验表明,利用该方法冲突规则的检测和处理正确率达到100%。
复句关系词;规则冲突;有向无环图
1 引言
中文信息处理可以概括的分为三个平台:字处理平台、词处理平台和句处理平台,其中每一个平台都是以前一个平台为基础[1]。从目前的进展来看,字、词处理已经取得很多研究成果,尤其是2003年Bakeoff[2]分词评测开展以来,中文分词技术获得了长足的进步[3]。而句和篇章方面的研究虽然已取得了句子相似度度量[4]、情感分析[5]、构建语义依存关系树库[6]等的若干研究成果,但是目前还处于初级阶段。从语法单位来讲,复句的研究属于“句处理”阶段的研究,目前研究得较多的是复句层次关系的自动识别,也是从“句处理”层面进行的应用研究。
关系词(又称关联词、关系标记)在现代汉语复句领域中起着重要的作用,是复句中标识关系的一个重要构件,是复句在语表形式上的关系标记,它在很大程度上影响着分句的语义,也影响着层次关系的识别[7]。由于语言的复杂性和多样性,通过完全的句法分析或语义分析来识别复句,现在的技术还很难实现。基于规则的方法早期用于汉语语法规则的自动构造[8],随后在文本分类、自动文摘、短语识别等方面得到广泛使用[9-12],基于规则的关系词标识仍是目前一种比较有效而且实用的方法。基于已构建的汉语复句语料库和复句关系词库,挖掘关系标记在复句中充当关系词的特征规律,再将特征规律整理为规则,据此建立相应的关系标记规则库,是研究关系词计算机自动标识方法和实现策略的关键。从句中发现与制定规则之后,需要对规则进行形式化后入库,在入库时要对待入库的规则与库中的规则进行分析比较,防止重复、矛盾的规则入库。同时,也需要判断具有包含关系的规则,并将这些规则与库中的规则进行归并。本文研究对规则入库的检测与可能的处理。
2 规则的表示与规则的冲突
2.1 规则的表示形式
结合句法理论与关系词分词处理结果,我们将规则分为四类:普通规则、连用词规则、普通句式规则、连用句式规则[13]。在规则数据库中,以四张表对应四类规则。四类规则除了各自具有特有的字段外,公有字段包括:规则号(ID)、关系标记(Keymarks)、约束类型(ConstraintType)、约束条件(Constraints)、结论(Result)、备注(Remarks)。其中,规则号唯一标识一条规则;关系标记表示需要判断的关系词;约束类型表示规则涉及到的约束条件的类型;约束条件表示符合规则的复句应满足的复句特征;结论表示判断的结果;备注用来补充说明复句应具备的特征。冲突进行检测是通过公有的字段来进行的。例如,一个普通规则的表示形式如表1所示。

表1 一个普通规则的表示
其中,约束类型分为12种[13],用数字1~12表示。若该约束类型涉及多种,用“+”号来连接。同样用“+”连接多种约束条件。
2.2 规则冲突
造成冲突事件的规则叫做冲突规则,规则冲突可以分为三类: 规则重复、规则矛盾、规则包含。
若有两条规则A、B;它们的关系标记分别记为Key(A)、Key(B);约束类型分别记为T(A) 、T(B);约束条件分别记为C(A)、C(B);结论分别记为R(A)、R(B)。
定义1 若C(A)=C(B)∧R(A)=R(B),则称规则重复,形式化表示为A≌B。
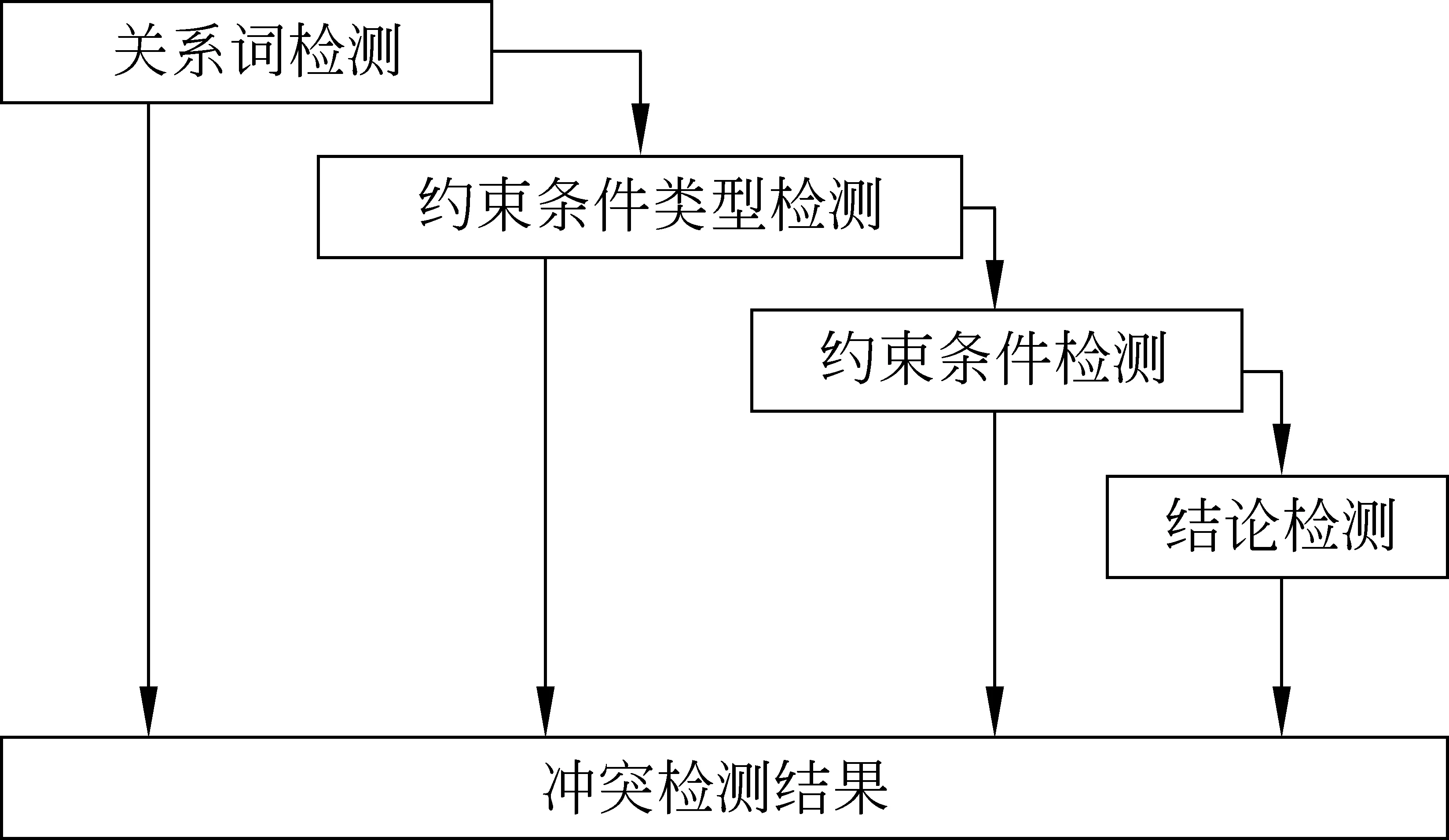
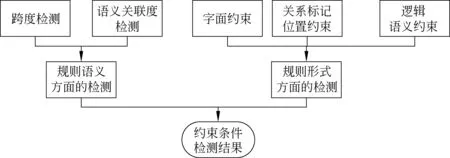
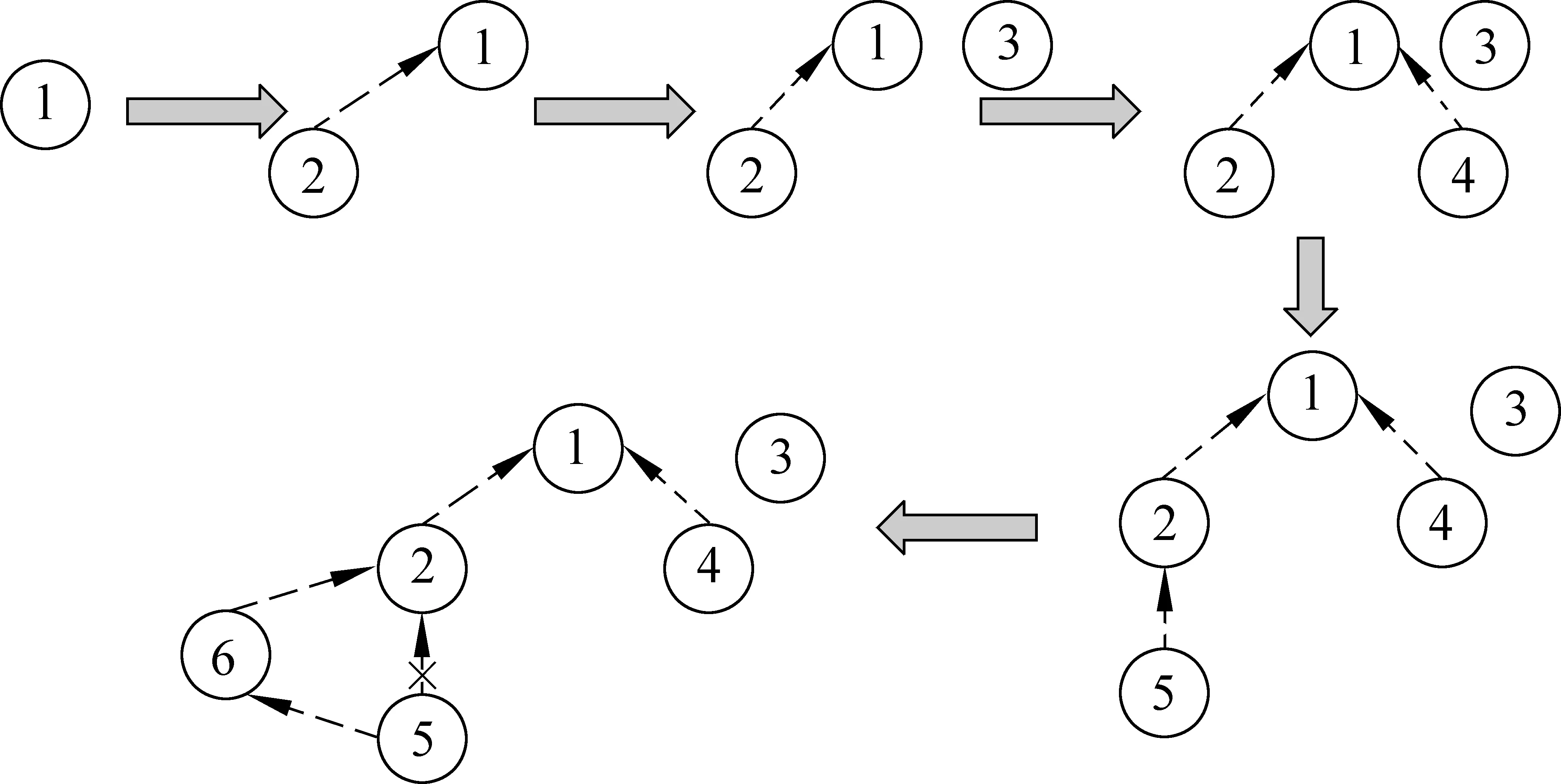
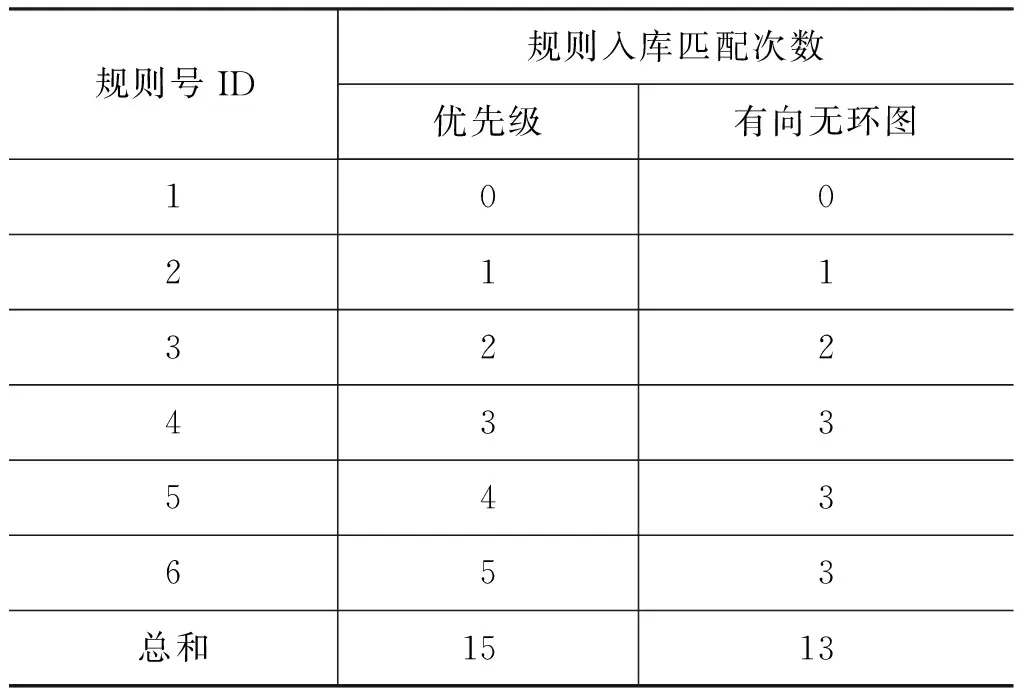
定义2 若C(A)=C(B)∧R(A)≠R(B),则称规则矛盾,形式化表示为A> 定义3 若C(A)⊂C(B)∨C(A)⊃C(B),则称规则包含。若C(A)⊂C(B)称为规则B右包含规则A, “⊂”称为右包含,反之若C(A)⊃C(B)称规则A左包含规则B,“⊃”称为左包含。 定义4 约束左包含与约束右包含 若规则A、B的约束条件语义存在C(A)⊃C(B),称为约束左包含;C(A)⊂C(B),则称为约束右包含。否则,则称为约束不包含,记为C(A)⊄C(B) 定义5 约束相等 若规则A、B的约束条件语义存在C(A)=C(B),称为约束相等。 定义6 规则冲突∀A、B,∃Key(A)=Key(B)∧(A≌B∨A> 规则重复使规则库中出现冗余,规则矛盾使规则引擎调用不同的规则时得出不同的结论。所以,应该排除规则重复与规则矛盾。对于规则包含,则允许其存在,可以通过优先级等方式将包含的关系区分开。 规则库是一个动态的数据库,当向其中添加每一条规则时,都可能出现规则的重复,规则的矛盾或者规则的包含,所以在规则入库时必须进行冲突检测。 规则的检测可以分为关系词检测、约束条件类型检测、约束条件检测和结论检测等四个层次,如图1所示。 图1 冲突检测整体流程图 3.1 关系词检测 关系词检测就是对将要入库的规则(记为规则A)的关系标记(keymarks)字段进行检测。 规则冲突只可能发生在关系标记相同的规则之间,因此首先筛选出关系标记相同的规则。 关系词检测步骤为: 连接规则库,在将要入库的规则表中查找是否有和规则A的关系标记词完全相同,如果存在这样的规则或者规则集合,则进入到下一层检测(约束条件类型检测);否则,表明不存在与规则A相冲突的规则。 3.2 约束类型检测 根据约束类型的不同来进行冲突的进一步判断。 假设要对将要入库的规则A与库中的关系标记相同的规则B进行冲突检测,规则A和规则B的约束类型的关系可以分为以下几种: a)T(A)∩T(B)=∅; b)T(A)=T(B); c)T(A)⊆T(B)∨T(A)⊇T(B) d)T(A)∩T(B)≠∅; 若规则A、B满足a) 、d)的情形,则可以直接判断A⊕B;若满足b)、c)的情形,两规则的约束类型存在这包含关系,则它们的约束条件有可能也存在着包含关系,所以同样得不冲突检测的结论,需要进入下一层继续检测。 3.3 约束条件检测 约束条件检测就是两条规则在确定约束类型存在包含或者相等之后,进一步确定两规则的约束条件之间的关系。 约束条件检测又分为两类,一类通过语义检测的约束条件,语义的检测主要包含跨度的检测和语义关联度[12]的检测;另一类通过表示形式上检测约束条件。 最后综合上面两类检测的结果得出这一层的最终检测结果,若得不出检测结果,还是需要进入下一层的冲突检测。约束条件检测的整体流程图如图2所示。 图2 约束条件检测整体流程图 3.3.1 规则形式检测 规则形式检测主要是检测字符串是否匹配。例如,sameClause(要是,就)与sameClause(就,要是)[10],应判断这两个单一约束条件是相等的。 假设要检测的规则A和库中的规则B,现在要对两条规则的同一类型中进行单一约束条件的检测,判断同一个类型中的约束条件的关系步骤如下: Step1 将规则A、B的当前类型的约束条件拆分成单一的约束条件集合,并存储在A和B中; Step2 ∀a∈A若∃b∈B∧a=b,则相等数目eNum= eNum+1; Step3 若eNum≠min(|A|,|B|),则在这个类型中不存在包含关系;否则,执行Step4; Step4 若|A|=|B|,则在当前类型中是相等关系,否则,执行Step5; Step5 若|A|= min(|A|,|B|),则在这个类型中是右包含关系,否则就是左包含关系。 3.3.2 规则语义检测 进行语义方面的检测前,先进行规则约束条件的预处理,对关系标记词的跨度进行规约处理,将规则规范化。例如,对于跨度有D(word1,word2)>1∧D(word2,word1)<4,我们将他们规约成1 进行预处理之后,将规则A 中的涉及到的约束条件和规则B中的进行分析判断,语义关联度的处理原理与跨度处理的原理一样,同样通过比较语义的包含范围来确定是否存在包含关系,此处仅以跨度类型为例进行说明,包含关系判断依据如下: • (n1 • D(word1,word2) • (n1 • n1 根据上述规则的处理,进一步分析所有的单一包含关系是否是一个方向的包含,若都是一个方向的包含就确定在这类约束类型中是包含关系,否则,就判断它们在这个类型中不存在包含冲突。 当要比较规则A和规则B对应类型中的约束条件是否存在包含关系时,分别用lNum、rNum、eNum表示约束左包含数目、约束右包含数目、约束相等数目。规则A、B在当前类型中的单一约束条件数目分别为T_A,T_B,minNum=min(T_A, T_B)。判断这个单一类型中的包含关系的依据如下: • 若lNum ≠0∧rNum ≠ 0,则此类型中不存在包含的关系; • 若lNum = 0∧rNum ≠ 0∧rNum + eNum = minNum,则此类型中是右包含关系; • 若rNum = 0∧lNum ≠ 0∧lNum + eNum = minNum,则此类型中是左包含关系; • 若rNum = 0∧lNum = 0∧eNum = minNum∧T_A≠ T_B,若minNum= T_A则此类型中是右包含关系;若minNum= T_B则此类型中是左包含关系; • 若rNum = 0∧lNum = 0∧eNum = minNum∧T_A = T_B,则此类型中是相等关系;即此类型中两条规则的约束条件是相等的, 这种情况既可以看作是此约束类型的左包含关系,也可以看作右包含关系; • 如果不符合上面任一种情况,就判断两条规则在此类型里面是不存在包含关系的。 3.3.3 约束条件的包含关系的确定 经过所有单一约束类型的检测之后,将所有类型检测的结果综合考虑,得出整个约束条件(约束条件集合)的关系,综合判断的原理和单类型的判断原理相同,考虑两条规则涉及到的约束类型的数目T_A和T_B,以及其中左包含关系数目lNum,右包含关系数目rNum,相等关系的数目eNum之间的关系。 • 若lNum+eNum=T_A∨lNum+eNum=T_B,则C(A)⊃C(B)。 • 若rNum+eNum=T_A∨rNum+eNum=T_B,则C(A)⊂C(B)。 • 若rNum≠0∧rNum≠0,则C(A)⊄C(B)。 • 若rNum=0,rNum=0∧eNum≠min(T_A,T_B), 则C(A)⊄C(B)。 • 若rNum=0,rNum=0∧eNum=min(T_A,T_B),若eNum= T_B,则左包含关系;若eNum= T_A,则右包含关系;eNum=T_A=T_B则C(A)=C(B)。 根据上面涉及到的约束条件相等的情况,可以直接判断产生了冲突,涉及到的包含关系的情况需要进一步的结论层检测。 3.4 结论检测 结论的检测与规则形式方面检测的方式相同,如果C(A)=C(B)∧R(A)≠R(B),可以判断产生了规则矛盾冲突A> 规则的冲突处理重点是处理那些约束条件存在包含关系的规则, 常见的规则冲突处理方法有: 依照规则存储顺序、定义规则的优先级、最长匹配策略、先入先出策略、元知识。其中最为简单实用的是优先级方法,Drools 规则引擎采用的就是优先级方法,利用优先级来区分各条规则的匹配优先顺序。 4.1 优先级的确定策略 待入库的规则A与规则库中的某条规则B冲突,规则A的优先级确定策略如下(n代表冲突的次数): • 若C(A)⊃C(B),比较两条规则的优先级P(A),P(B);若P(A)>P(B)则将P(A)= P(B)-1 • 若C(A)⊂C(B),比较两条规则的优先级P(A),P(B);若P(A) 采用这种方法处理可能会出现“优先级钟摆问题”。例如: 设库中已有规则A和B,而且A,B的关系标记相同,B的优先级高于A,P(B)=P(A)+1。现在有一条规则C要入库,经检测C的关系标记与A,B相同,则需要进一步检测,如果发现C与A有冲突,且C比A的约束条件更严格,即C的优先级高于A,于是A的优先级加1;然后再将C与B进行冲突检查,如果出现C的约束条件比B的约束条件宽松,即B的约束条件是C的约束条件的子集,这时就应该降低C的约束条件,即B的优先级减1。这时候C的优先级就又回到了和A的优先级一样了,就破坏了第一次冲突检测的修改结果。这样优先级就像钟摆一样的来回变动,永远也配不平衡,这就是所谓的“优先级钟摆问题"。 解决优先级钟摆问题的方法是将优先级的增量或减量不定为一个恒量,而是当入库发生多次冲突时,修改时增量(或减量),取上一次冲突的增量(或减量)的1/2。 • 若C(A)⊃C(B),比较两条规则的优先级P(A),P(B);若P(A)>P(B)则将P(A)= P(B)-1/2n。 • 若C(A)⊂C(B),比较两条规则的优先级P(A),P(B);若P(A) 对于上述规则A、B、C,若默认优先级是5,A、B先后入库优先级分别为5、6,C入库时,先与A冲突优先级变为6,增量为1,然后与B冲突,减量为0.5(上次冲突1的1/2),所以检测完成,最终入库结果优先级为6-0.5=5.5。 为了实现上面的方法,我们需要给每条规则增加一个优先级(priority)字段,规则的表示形式为: Rule(ID, keymarks, priority, constraintType, constrants, result, remarks) 4.2 有向无环图(DAG)方式 规则的约束条件在语义上面存在着包含关系,我们将这种包含关系以有向弧的形式表示,将每条入库的规则用图中一个节点表示。节点之间的有向弧表示弧线两端的规则的一种包含关系,而且这种包含关系是真包含,所有关系标记相同的规则入库后形成一个有向无环图DAG。 我们采用的表示方式是弧首的规则包含弧尾的规则,即弧首的规则的约束条件比弧尾的规则的约束条件更宽松,弧尾的规则表示的集合是弧首的规则表示集合的真子集。 例如,下面有两条包含关系的规则Rule1、Rule2,为了方便,我们只列出两条规则的约束条件: Rule1:sameClause(不仅,同时) Rule2: sameClause(不仅,同时)^backword(同时)=‘具有’ Rule1的范围比Rule2的范围更加广,Rule2的约束更加严格,所以规则连接弧(关系弧)应该是由Rule1指向Rule2(Rule1 —> Rule2)。 以关系标记“如果/那么”为例进行说明有向无环图的形成过程: 首先,库中没有涉及到“如果/那么”的规则,有向无环图为空;插入第一条关系标记“如果/那么”,形成了一个有向无环图,图中只有一个规则结点,没有弧。 然后,试图向库中插入另一条关系标记“如果/那么”,这时,需要对库中的有向无环图中的规则元素进行检测,查找插入的位置。 查找规则Node的插入位置是一个复杂的过程,我们的遍历策略是深度优先遍历[13],步骤如下: Step1 选取一个没有直接前驱的节点,依次深度遍历它的后继,直到找到包含Node的节点Node1和指向Node1的节点Node2; Step2 若规则Node包含Node2,则将Node插入到Node1与Node2之间,否则就将Node作为Node1的一个新前驱; Step3 回溯到Node1选取另一个未遍历的后继节点遍历,直至这个没前驱的节点下的所有连通节点都遍历或找到了插入点为止; Step4 继续选取另一个没有前驱的节点,重复步骤1、2、3,寻找插入点插入; Step5 如果遍历完所有节点,没有找到包含Node的节点,但是Node却包含某个没有后继的节点,就将Node作为这个没有直接后继的节点的后继; Step6 如果Node和所有节点不存在包含关系,那么就将Node独立出来,形成一个单独的孤立的节点。 通过上面的构造我们就能形成一个逻辑的有向无环图。而规则引擎在调用时正好与规则插入的遍历顺序相反,所以在插入时,应该利用两条方向相反的有向弧来生成图。 DAG的存储结构需要给每条规则增加前驱(precursor)和后继(subsequent)两个字段。前驱用来指向包含自身的规则,后继用来指向被包含的规则,规则的格式为: Rule(ID, keymarks, constraintType, constrants, precursor, subsequent, result, remarks) 4.3 两种方式的比较 两种方式各有自己的优缺点: 优先级方式表示简单,实现起来容易,同时也节省存储空间,但是它存在优先级钟摆的问题。而为了解决优先级钟摆问题我们采用的优先级增(减)量指数级递增(减)的方法。 有向无环图方式的表示更加直观,实现起来比较困难,而且需要更多的存储空间来存储规则之间的关系。优点是在规则引擎调用规则进行解析时,不需要对图中的所有规则都进行解析,只需要(沿着实线有向图遍历)找到最后一条符合规则的解析结果即可,这样就节省了规则解析的过程和时间。而且在进行入库检测时也不需要对库中的每一条规则进行检测,同样只需要(沿着虚线有向图遍历)检测到第一条存在包含关系的规则后,就找到了在这条路径里的插入位置。 下面以关系标记“一边/一边”为例说明规则冲突处理的过程,并对两种处理方式的性能进行定量的比较。“一边/一边”涉及的6条规则如表2所示(基于表格篇幅限制,表中只列出规则约束条件)。 表2 涉及“一边/一边”的规则 续表 假设库中不含有“一边/一边”的规则,若按照表中的规则的顺序入库(不同顺序入库结果不同)。 优先级方式入库的步骤如下: ①入库规则1,由于库中没有相同关系标记的规则,所有直接入库,默认优先级设置为5;②入库规则2,先检测库中规则,发现规则1包含规则2,因此规则2的优先级为P(2)=P(1)+(1/2)1-1=6;③入库规则3,与库中规则1、2不存在冲突,直接入库,优先级为默认值5;④入库规则4,依次检测规则1、2、3,与规则1约束包含,因此优先级为P(4)=P(1)+(1/2)1-1=6;⑤入库规则5,依次检测规则1、2、3、4,依次与规则1、2约束包含,因此优先级为P(5)=P(2)+(1/2)2-1=6+(1/2)2-1=6.5;⑥入库规则6,依次检测规则1、2、3、4、5,依次与规则1、2、5约束包含,P(6)=P(5)+(1/2)3-1= 6.75。 经过优先级冲突处理后,六条规则的优先级如表3所示。 表3 六条规则的优先级 有向无环图方式入库的步骤如下: ①入库规则1,直接入库;②入库规则2,检查库中规则1,规则1约束包含规则2,因此虚线由规则2指向规则1;③入库规则3,依次检测规则2、1,不存在冲突,直接入库;④入库规则4,依次检测规则2、1、3,规则1约束包含规则4,虚线由规则4指向规则1;⑤入库规则5,依次检测规则2、4、3,规则2约束包含规则5,所有不需要检测规则2的直接或间接后继(虚线方向),因此虚线规则5指向规则2;⑥入库规则6,依次检测规则5、2、4、3,发现规则2约束包含规则6,规则6约束包含规则5,所有将有规则5指向规则2的虚线改为规则6指向规则2和规则5指向规则6。 有向无环图入库的步骤图解如图3所示。 图3 有向无环图入库步解 通过上面两种方式对“一边/一边”的6条规则进行入库,从入库步骤可以看出,优先级方式简单易实现,但是不直观。有向无环图方式,虽然入库相对来说要更复杂一些,但是能够很好的表示出规则之间的那种包含关系。从存储空间的角度考虑,优先级只需要增加一个“优先级”的属性字段,而有向无环图方式需要增加“前驱”和“后继”两个字段,字段类型也不同,前者是一个数字,后者是一个集合,所有从空间考虑优先级方式更节省空间。但从时间的角度考虑,主要是比较入库的规则匹配次数,通过表4所示,总的比较次数有向无环图方式比较次数要低,因此入库要快。而且这种方式对规则的调用也是产生同样的效果,节省规则匹配的时间。 表4 “一边/一边”规则两种入库方式比较 从表中的数字可以看出,当表中的相关规则比较少时(只入库了规则1、2、3、4时),在入库时规则的匹配是次数是一样的,随着规则的增加,有向无环图的时间优势就体现出来了。规则5入库节省了25%,规则6入库节省了20%的匹配时间。因此随着规则库的扩大,有向无环图的冲突处理方式的性能优势更能体现出来。 规则的挖掘分成三个步骤: 使用分词软件对语料库中的复句进行分词、对照关系词及搭配库进行关系词识别、提取句子特征填写以关系词为索引的规则项。虽然三个步骤每个步骤均借助计算机完成,但三个步骤单独进行,没有形成“自动”的过程,在规则项生成时依靠“人工”总结规则项。这样“人工挖掘”的规则总共有1 029条。其中连用规则表中150条,普通规则表482条,普通句式表157条,连用句式表240条。根据前期的规则分类,我们将规则依次分类入库,规则自动入库的情况如表5所示。 表5 规则入库结果 从表中可以看出规则的冲突所占的比例为6.6%,而这1 029条规则是人工挖掘后再集中入库的,有的规则重复与规则矛盾人工很容易发现,为了测试系统对规则重复和矛盾的处理,在入库时特意制造了一些规则的重复和矛盾规则进行测试。规则冲突的比例很低的主要原因是由于汉语复句的复杂性以及约束条件的制定涉及到的类型之多而形成的,与“人工”制定规则也有关系,因此越是规则制定的详细,规则的冲突就越少,处理的结果就越准确。 在人工集中大量规则入库时,除去人工加入的一些矛盾规则和重复规则的因素,规则冲突中规则包含的冲突所占的比例是很大的,主要是由于规则的约束条件的严格与宽松。若一个关系标记序列有约束条件非常宽松的一条规则,那它接下来的入库规则中与之产生冲突的可能性就越大。 从规则处理的情况来看,所有发现的冲突都得到了相应的处理,规则的重复和规则的矛盾情况比较好判断。而规则的包含情况,在所入库的规则中遇到的23例包含约束都得到了检测和相应的处理。 本文主要解决了规则自动生成系统中规则的冲突检测与处理的问题,它作为整个规则自动生成系统的核心部分,利用规则的各个字段的值来进行冲突检测判断,并将产生冲突的规则进行分类处理,重复规则阻止入库,矛盾规则提出警告并阻止入库,若是包含关系的规则就利用有向无环图的方式进行逻辑的处理,然后入库。 利用该检测方法和有向无环图的处理方式,入库了1 029条规则。实验表明,利用本文的方法对规则检测和处理正确率达到100%。这是一个非常理想的效果。这也说明,本文所研究的规则自动生成系统冲突检测与处理的方法和实现算法是比较有效的。 由于本系统中现有规则表中的规则是由人工整理并自动入库,其效率不高,因此应深入研究规则的自动挖掘技术,在此基础上完成规则的自动生成,使得整个系统更加自动化。 [1] 刘迁,贾惠波. 中文信息处理中自动分词技术的研究与展望[J].计算机工程与应用,2006,(03): 175-177. [2] Sproat R, Emerson T. The First International Chinese Word Segmentation Bakeoff[C]//Proceedings of the Second SIGHAN Workshop on Chinese Language Processing.Sapporo, Japan: July 11-12,2003:133-143. [3] 黄昌宁,赵海.中文分词十年回顾[J].中文信息学报,2007,21(3):8-18. [4] 贾宗福,王知非.中文句子相似度计算的研究[J].科技信息,2009,(11): 402-403. [5] 昝红英,左维松,张坤丽等.规则和统计相结合的情感分析研究[J]. 计算机工程与科学,2011,(5):146-150. [6] 尤昉,李涓子,王作英. 基于语义依存关系的汉语语料库的构建[J].中文信息学报,2003,17(1):46-53. [7] 邢福义.复句与关系词[M].哈尔滨: 黑龙江人民出版社, 1985. [8] 胡金柱,舒江波,等.面向中文信息处理的复句关系词提取算法[J].计算机工程与科学, 2009 (10). [8] 周强,黄昌宁.汉语句法规则的自动构造方法研究[J].中文信息学报,1998,12(3):1-7. [9] 李渝勤,孙丽华.基于规则的自动分类在文本分类中的应用[J],中文信息学报,2004,18(4):9-14. [10] 傅间莲,陈群秀.基于规则和统计的中文自动文摘系统[J],中文信息学报,2006,20(5):10-16. [11] 代翠,周俏丽,蔡东风,等.统计和规则相结合的汉语最长名词短语自动识别[J],中文信息学报,2008,22(6):110-115. [12] 于淼,吕雅娟,苏劲松,等.规则和统计相结合的中文地址翻译方法[J],中文信息学报,2012,26(3):49-53. [13] 胡金柱,陈江曼等.基于规则的连用关系标记的自动标识研究[J].计算机科学,2012,(7):190-194. Rule Conflict Resolution for Relation Word in Chinese Compound Sentences YANG Jincai1, XIE Fang2, WANG Zhonghua1, HU Jinzhu1 (1. School of Computer Science of Huazhong Normal University, Wuhan, Hubei 430079, China;2. School of Computer Science of Hubei University of Technology, Wuhan, Hubei 430068, China) Relation words are very important to the study of semantic relationships among clauses in compound sentences. Rule based relation word identification demands dynamic and constantly improved rules. This article investigates how to recognize the rule conflicts and solve them. Compound sentences have four kinds of rules: common rules, even words rules, common sentence pattern rules, and collocation patterns rule. This article gives a formal description of all the rules and the way of storing them, based on which we designed the flow of relation word detection, rule condition detection, result detection. A way of detecting the conflicts is given, include another two ways of solving the conflicts-priority mode and directed acyclic graph mode. With this proposed method, we have imported more than 1067 rules, with a correct rate of 100%. relation words in compound sentences; rule conflicts; directed acyclic graph 杨进才(1967-),博士,教授,主要研究领域为数据库和中文信息处理。E-mail:jcyang@mail.ccnu.edu.cn谢芳(1981-),博士研究生,讲师,主要研究领域为中文信息处理和软件工程。E-mail:thanks_xf@hotmail.com胡金柱(1947-),教授,博士生导师,主要研究领域为中文信息处理和软件工程。E-mail:jzhu@mail.ccnu.edu.cn 1003-0077(2015)04-0008-08 2013-10-06 定稿日期: 2014-04-09 国家教育部人文社科基金(13YJAZH117),国家社科基金(11BYY052) TP391 A3 规则的冲突检测
4 规则的冲突处理



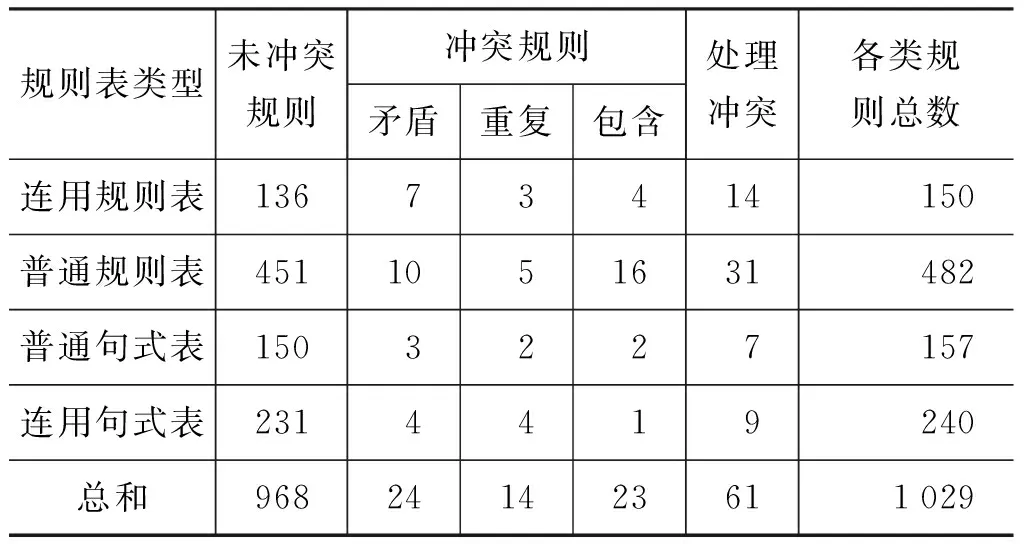
5 系统检测处理的结果与分析
6 结语

