HowNet与CCD映射方法研究
2015-04-21向春丞穗志方詹卫东
向春丞, 穗志方,2, 詹卫东
(1. 北京大学 计算语言学教育部重点实验室,北京 100871;2. 语言能力协同创新中心,江苏 徐州 221009))
HowNet与CCD映射方法研究
向春丞1, 穗志方1,2, 詹卫东1
(1. 北京大学 计算语言学教育部重点实验室,北京 100871;2. 语言能力协同创新中心,江苏 徐州 221009))
本体映射是解决本体异构问题的关键方案。该文以HowNet和CCD中的名词性概念为例,首先利用机器学习技术发现初始映射关系,主要包括特征选择、样本集合划分、分类器选择等步骤;然后考虑本体的整体结构信息,利用相似度传播算法,对初始映射关系进行全局调整。实验表明,最终的一对一和一对多映射关系的准确率分别达到了94%和87.5%。
本体映射;机器学习;分层抽样;相似度传播算法
1 前言
本体作为一种能在语义和知识层面上描述领域概念的建模工具,近年来在人工智能、信息检索、语义Web等领域受到了极大关注,本体数量在其研究和运用领域呈爆炸式增长。然而,独立地设计和开发导致了大量描述同一领域知识的本体之间存在严重的异构问题,极大阻碍了本体之间知识的共享和融合。本体映射能够在异构本体之间发现语义相似的实体,是解决本体异构问题的关键方案[1],已成为当前语义Web领域中的一个研究热点。
目前,研究者们已在本体映射方面做了大量工作,提出了许多映射方法[2-4],如基于实体名称、基于本体结构、基于背景知识以及基于语义的方法等。通常,大部分本体映射系统[5-6]都将多个基本匹配器进行线性综合,然后使用一些优化策略,发现映射关系。然而,手动地设置组合时的参数很难获得最佳映射关系,于是研究者们将机器学习技术[7-9]引入本体映射任务,自动地对基本匹配器进行组合。
中文本体映射方面的研究相对薄弱。文献[10]尝试将知网与同义词词林进行融合,首先利用知网中的义原对词林中的每个原子词群给出一个DEF描述;然后在该特征上定义两种形式的相似度计算,并将它们结合起来,通过反复试验确定阈值,实现分类的目的。其相似度计算过程中仅考虑了本体本身的词汇信息,缺乏对本体结构以及外部词典或互联网资源的利用,对词汇语义信息的利用也不够。
本文初步探索了知网(HowNet)与中文概念辞书(Chinese Concept Dictionary, CCD)两部词典的映射方法。首先利用两者的词汇信息、语言信息以及语义信息定义映射特征;然后给出将样本集划分成正例集、负例集以及测试集的策略,接着利用机器学习技术发现映射关系;最后考虑本体的整体结构信息,利用相似度传播算法对初始映射结果进行调整。实验表明,最终的概念之间的一对一和一对多映射关系准确率可达到94%和87.5%。
2 术语及相关介绍
本节给出相关的术语和介绍,包括本体和本体映射的定义、HowNet与CCD的简介以及本文中待映射本体的说明。
2.1 本体和本体映射
在计算机科学的不同领域,有很多的数据和概念模型都可以被称为本体,例如,普通的分类、数据库模式、UML模型、字典、主题词表、XML模式以及正式化的本体等。根据文献[11]的描述,本体(Ontology)主要包括概念(Concepts)、属性(Properties)、实例(Instances)以及公理(Axioms),可形式化地表示为:
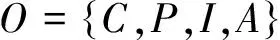
其中,C表示概念或类(Classes)的集合;I表示概念的实例或个体(Individuals)的集合;P表示属性集合,分为对象属性(Object Properties)和数据属性(Datatype Properties),前者用来表示概念之间或实例之间的关系,后者用于描述概念或实例的固有特征;A表示公理集合,用来对概念或属性进行约束。 本体映射(Ontology Matching)是发现不同本体的实体之间的关联关系(relationships)或对应关系(correspondences)的过程[1]。所谓本体的实体,主要指本体中的概念、实例或者属性。可将本体映射形式化为:
其中,函数F表示映射过程,OS和OT分别表示源本体和目标本体,A表示OS与OT之间可能已存在的映射关系,p表示映射过程中用到的权值或阈值等参数,r表示映射过程中用到的外部资源,A′表示映射结果,可理解为由具有映射关系的实体对组成的集合。实体之间的映射结果可以是一对一、一对多、多对一以及多对多的映射情况。
2.2HowNet*出于表述简便,本文中所谓的“HowNet”主要指知网系统中的双语知识词典数据文件。与CCD的简介
知网(HowNet)是一个以汉语和英语的词语所代表的概念为描述对象,以揭示概念与概念之间以及概念所具有的属性之间的关系为基本内容的常识知识库[12]。知网的规模主要取决于双语知识词典数据文件的大小,包含194 302(2011版)条义项记录。
中文概念辞书是一个基于WordNet框架的汉英双语语义知识库[13]。它将代表概念的词语分为名词、动词、形容词以及副词四种,目前收录了近十万个概念。
图1给出了一条HowNet记录的例子。其中,NO.表示记录的编号、W_C表示概念的中文表述、W_E表示概念的英文表述、DEF是对概念的规格化描述。DEF中第一位置的义原“Circuitances|境况”称为主要特征,它是概念“CONDITION|状况”的直接上位概念。
图2为CCD中描述名词性(POS=n)概念“{态势 情形 状况 状态}”的主要格式,其中Definition和Note分别表示概念的释义(定义)和使用举例,Hypernym和Hyponym表示该概念的直接上、下位概念的编号。通常,一个概念的直接上位概念只有一个,而直接下位概念有多个。

图1 HowNet记录举例图2 CCD概念及其描述举例
2.3 待映射本体
HowNet和CCD都是一部体现了对客观世界的认识与把握的中英文词汇概念语义词典,因此将其所描述的概念进行映射是合理的。本文映射任务中,源本体OS中的概念为HowNet中的名词性概念,目标本体OT中的概念为CCD中的名词性概念。
由于HowNet和CCD的编纂时期、概念划分粒度以及应用目标等方面存在一定的差异,因此两部词典中收录的名词性词语的数量差别较大,其统计结果如表1所示。

表1 待映射本体初步统计表
由于本文的映射策略还考虑了概念的分类体系对映射关系的影响,因此我们将描述HowNet概念的实体类、属性类以及属性值类义原以HowNet记录的形式加入到了原来的记录集合中,其中实体类义原的DEF不变,属性类和属性值类义原的DEF定义为其上位概念。
3 利用机器学习技术发现映射关系
本节主要介绍将机器学习技术用于HowNet与CCD的映射任务。将映射问题看作二分类问题,首先进行映射特征的选择;然后给出将样本集自动划分成训练集和测试集的策略;最后介绍分类器的选择和预测过程。
3.1 选择映射特征
文献[10]中提出的知网与同义词词林的融合特征,为CCD中的每个同义词集定义一个DEF描述,得到映射特征F3-F6(表2)。另外,利用CCD概念的Note和Definition属性,定义映射特征F7和F8。映射特征F1-F8的具体描述如表2所示。
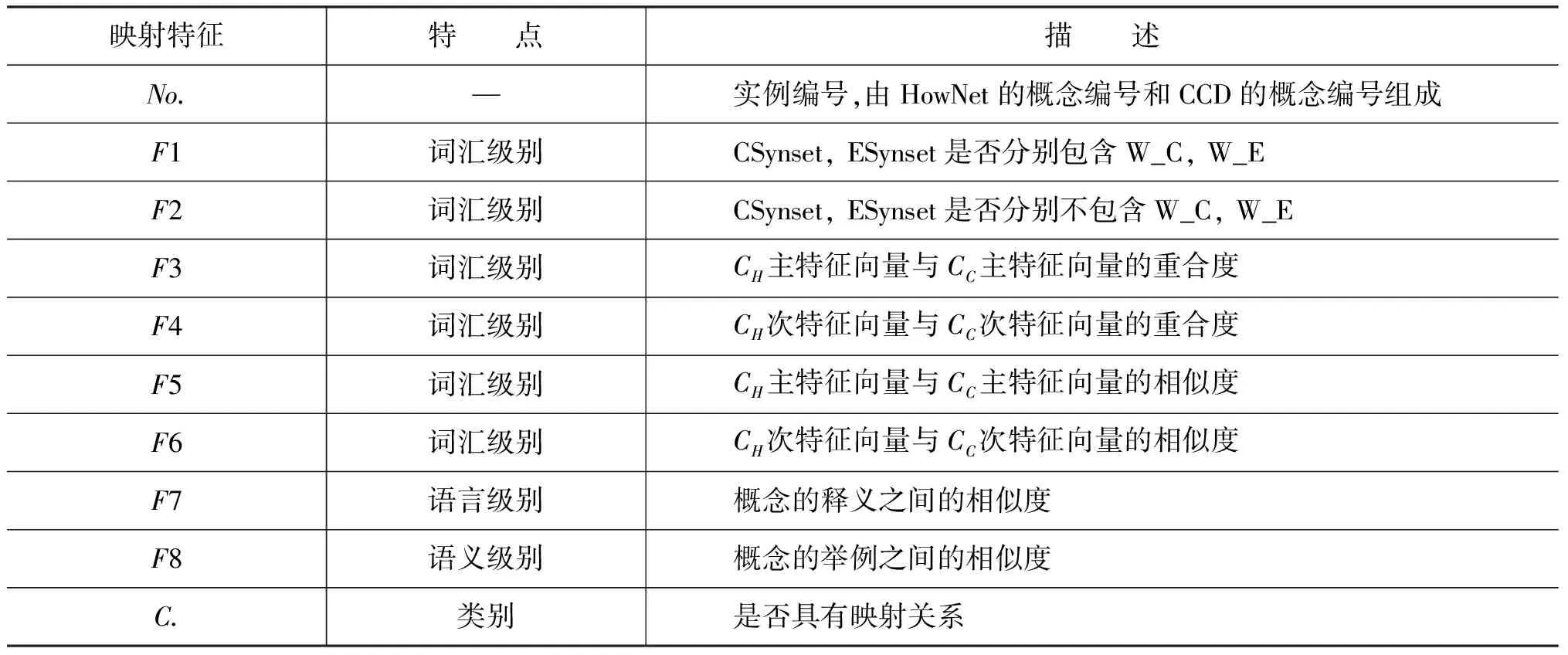
表2 HowNet与CCD的映射特征
其中,特征F3-F6的计算方法与文献[10]相同。用W_C表示HowNet中某个概念的中文词条,为了计算特征F7,首先从新华字典中获取W_C的名词性释义;如果该名词性释义有多项,则说明W_C为多义词,此时利用其相应的DEF中的主要特征和次要特征进行排歧、选择;如果字典中未给出W_C的名词性释义,则取其基本释义代替。然后再计算W_C的释义与CCD中概念的释义之间的余弦相似度。
对于特征F8,首先利用互联网语料训练得到Bigram语言模型,然后将CNote中出现的CSynset中的词语用W_C替换,将替换后的CNote的概率作为特征F8的值(采用加一平滑技术处理数据稀疏问题)。如果F8的值较大,则说明两个概念之间的语义相似度越高。
3.2 划分样本集合
将一个HowNet概念和一个CCD概念组成的概念对
对包含87 393个概念的OS和包含64 895个概念的OT进行统计,其中使得特征F1的值为真的映射样本的个数为37 021个,涵盖了29 086个HowNet概念和18 283个CCD概念。从这些映射样本中随机选取200个人工进行观察,发现其中有187个可以被看作正例。也就是说,如果把使得特征F1值为真的映射样本作为正例,其可信度能够达到98%。这主要是由于W_C和W_E之间具有相互排歧的作用。我们允许一定的误差存在,利用特征F1和F2对样本集合进行划分,即将特征F1和F2的值为真的映射样本分别作为正例和负例,其他包含了49 697个HowNet概念和29 503个CCD概念的大约16.5万个映射样本组成测试集。
3.3 分类器的选择和预测
目前,能够解决二分类问题的机器学习算法有很多,因此需要根据实际任务的特点进行选择。首先,利用分层抽样方法从负例集中抽取与正例集规模相当的样本,并将其与所有正例组成训练集;然后,对多个分类器在训练数据集上采用交叉验证的方法进行训练,选择F值最高的一个作为最终的分类器对测试样本进行预测,从而发现测试样本中的映射关系。由于特征F1和F2已被用于样本集合的划分,因此,在分类器的训练和预测阶段均不考虑样本的这两个特征。
4 基于相似度传播算法的映射关系调整
相似度传播算法[14](Similarity Flooding Algorithm,SF)是一种图匹配算法,它将图中的节点看作概念,节点之间的连边看作概念之间的关系,认为两个概念之间的映射结果不仅跟它们各自的特征有关,还跟其邻近概念,甚至图中所有其他概念的映射结果也有关。概念之间的相似度通过图中的连边在整个图上进行迭代传播。
本文不把待映射本体的分类结构HS和HT(如图3所示)按照文献[14]中的方法进行合并,因为这样会急剧增加节点个数。例如,对HS和HT中分别以节点A和B为根的子树进行合并,节点个数将由m+n+2个变为m*n+1个,而CCD和HowNet中很多概念都有几十甚至上百个子概念。

图3 相似度传播算法示意图
定义对概念对
另外,在执行相似度传播算法之前,还需要为每个概念对设置初始相似度值。以概念对
(1)
其中,σ(i+1)表示概念对
(2)
(3)

利用上述定点计算公式对测试样本的相似度值在整个图上进行迭代修正,达到基于相似度传播算法调整映射关系的目的。
5 实验及结果分析
5.1 负例选择实验
由于待映射本体中的每一对概念之间都有可能存在映射关系,因此样本集的大小为87 393×64 895,其中除了37 021个正例样本和约16.5万的测试样本外,剩下的均为负例样本。因此,必须对负例样本集进行压缩,使其规模与正例个数相当,且压缩后得到的负例样本的统计特性应与压缩之前比较接近。
本文的做法是,首先从所有负例集中随机选取1亿个样本得到样本集M;然后利用分层抽样方法从M中抽取与正例数量相当的样本,得到样本集N。对M和N中所有样本的特征的取值进行统计分析,其结果如图4所示(实验通过调用WekaAPI实现)。
图4中,F3-F8对应表2中定义的特征,Mean_0和Mean_1分别表示负例集在压缩之前和之后的特征值的均值,StdDev表示标准差,N的大小为37 038。假设M中样本的分布情况与整个负例集中的一致,那么由上图可知,通过分层抽样方法得到的N中样本的统计特性与M中的非常相似,因此我们可以认为样本集N可以代表整个负例样本集。

图4 负例集压缩前后的统计特性对比
5.2 分类器的选择实验
现在我们已经得到了一个包含37 021个正例和 37 038个负例的训练数据。此时我们希望找到一个在该训练集上表现较好的分类器,以对测试样本进行分类,从而发现更多的映射关系。我们分别对朴素贝叶斯(Naive Bayes,NB)分类器、决策树(Decision Tree, DT)分类器以及最大熵(Maximum Entropy, ME)分类器进行了实验和比较,分类器训练时均采用10折交叉验证方式,实验通过调用Weka API完成,其训练结果如表3所示。
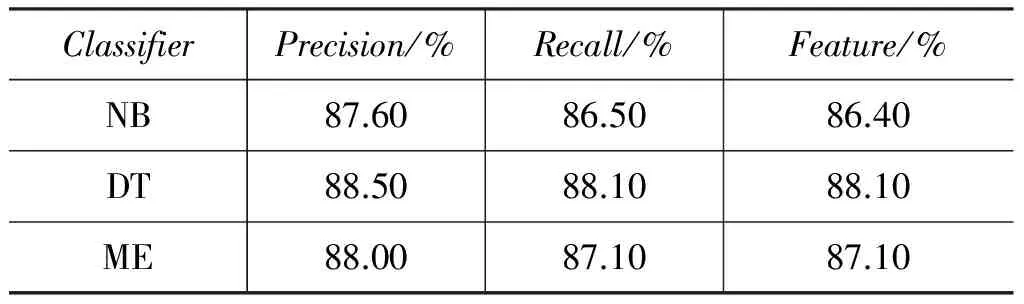
表3 分类器训练效果比较
上表中,Precision、Recall以及Feature表示分类器在训练集上的查准率、查全率以及F值。从表3可以发现,决策树在本文的训练集上表现最好,于是我们将其作为最终的分类器。图5为该决策树分类器的部分结构。
从图5可知,次特征向量(secdf_cos_sim,即特征F6)的相似度对类别的区分能力最强,被选定为根节点。完整的决策树模型共有49个节点,其中包含25个叶节点。
5.3 映射关系发现实验
依次利用以下三种方法发现从HowNet(OS)到CCD(OT)的映射关系。
(1) 基于特征频度统计和特征向量计算结合的方法[10]
该方法主要参考文献[10], 它首先通过反复试验设定阈值,然后执行多步判断,实现对概念对的分类。该过程可以看作是人工制定分类规则来判定概念之间是否存在映射关系。本文并未使用这样反复尝试的方法选定所需阈值,而是将阈值设定为相应特征值的均值。测试集中所有样本的特征的统计特性如表4所示。

图5 决策树分类器部分结构

F3F4F5F6F7F8Mean0.3540.5850.2360.2330.0430.005SedDev0.8941.7380.3460.3230.0970.073
根据表4的统计结果,对方法1中的相关阈值进行设定。其中主特征和次特征的重合度阈值分别设定为0.354和0.585;主特征和次特征的向量相似度阈值分别设定为0.236和0.233。
(2) 基于统计决策树的方法
文献[15]中也利用了决策树的方法进行本体映射,但是其决策规则均由人工进行构造,其分裂节点的阈值通过反复试验选定,这样的阈值选定策略不仅费时费力,而且对训练数据的适应能力较差。本文中的决策树模型则是通过机器学习方法自动训练得到,从而能有效地发现训练数据中所蕴含的分类规律。
(3) 基于相似度传播的方法
方法1和2仅考虑了概念的局部特征,没有充分利用本体固有的结构信息。本文中的相似度传播方法主要是在方法2的基础之上,利用本体的整体结构信息来对映射结果进行调整,使其更为合理,另外,该方法还可以发现测试集之外的映射关系。与方法1类似,该方法中映射阈值取为算法迭代一定次数(n=100)后相似度值的均值,即0.43。
从对测试集的映射预测结果中随机选取200个进行人工评价,以上三种映射方法的映射发现结果如表5所示(观察从HowNet到CCD的映射情况)。
其中,方法1中的“1∶1” (一对一)映射结果“11 504/95.00%”表示: 测试集中有11 504个HowNet概念,每个仅能映射到一个CCD概念上,
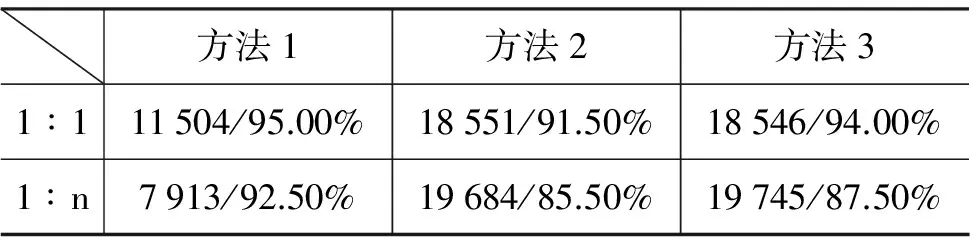
表5 HowNet到CCD的映射结果统计表
映射准确率为95.00%。“1∶n”(一对多)表示: 一个HowNet概念与多个CCD概念具有映射关系。
5.4 实验结果和错误分析
方法1主要基于概念词语的DEF描述的词汇级匹配特征,即如果两个概念的主要特征和次要特征具有较高的相似度,那么这两个概念可能具有映射关系。但就HowNet与CCD的映射任务而言,该方法仅能发现部分映射关系。
方法2在方法1的基础之上还考虑了其他一些特征,并利用机器学习技术自动的对基本匹配器进行组合,能够发现测试集中其他大部分映射关系。例如,HowNet概念“WC=丹麦首都,WE=capital_of_denmark”,其主要特征为“place|地方=1.0”,次要特征为“capital|国都=1.0,Denmark|丹麦=1.0,ProperName|专=1.0”;CCD概念“csynset = {丹麦首都, 哥本哈根},esynset = {copenhagen, kobenhavn, danish_capital}”,其主要特征为“country|国家=2.0,ProperName|专=2.0,Denmark|丹麦=2.0,politics|政=2.0,capital|国都=2.0”,次要特征为“place|地方=2.0”;通过计算,其主、次要特征的重合度和相似度均为0,因此无法利用方法1判断这对概念具有映射关系。但其特征F7、F8的值分别为0.306 186、1.326 442E-9,即这两个概念的释义和举例之间具有较高的相似度,从而在方法2中被认为具有映射关系。
方法3将方法2的分类结果的置信度值作为初值,利用概念的上下位关系,在整个分类结构上对初始映射结果进行迭代地调整。 例如,HowNet概念“WC=仓促,WE= precipitation”与CCD概念“csynset = {意外, 突然, 突如其来},esynset = {abruptness, precipitateness, precipitance, precipitancy, suddenness}”,根据样本集划分原则,由这两个概念构成的样本将被视为负例,但在方法3的实验结果中却认为它们之间存在映射关系,这与人的判断结果是一致的。因此,方法3能够发现测试集之外的映射关系。
前两种方法的映射错误主要来自单字多义概念之间的映射。例如,HowNet中由“阵”字表示的概念的义项有“WC=阵,WE=spell”、“WC=阵,WE=position”、“WC=阵,WE=battle_array”以及“WC=阵,WE=front”等,方法1、2都认为它们与CCD概念“csynset={阵, 一阵, 冲动, 发作, 爆发, 一阵子},esynset={burst, fit}”具有映射关系。
6 结语
本文利用机器学习技术和相似度传播算法对HowNet和CCD中名词性概念之间的映射作了初步探索并取得了较好的效果,但由于两部词典对概念粒度划分、属性定义的差异,还是未能对一部分概念进行映射。
本体映射是一项复杂的任务,本文就映射训练集缺乏、负例集压缩以及映射关系的全局调整给出了初步解决策略。但还有很多方面值得进一步考虑,例如,(1)用于划分样本集的假设限制太严,致使测试集规模偏小;(2)相似度算法在实现时的效率问题等。我们将在后续论文中对这些情况进行更深入的研究。
[1] Jerome E, Pavel S. Ontology matching[C]//Proceedings of the Springer-Verlag, Heidelberg (DE), 2007.
[2] Qu Y, Hu W, Chen G. Constructing virtual documents for ontology matching[C]//Proceedings of the 15th International World Wide Web Conference (WWW). Edinburgh (UK), 2006: 23-31.
[3] Gligorov, Risto, et al. Using Google distance to weight approximate ontology matches[C]//Proceedings of the 16th international conference on World Wide Web (WWW). Beijing, China, 2007: 767-776.
[4] Atencia M, Borgida A, et al. A formal semantics for weighted ontology mappings[C]//Proceedings of the Semantic Web-ISWC 2012: 17-33.
[5] Nagy M, Vargas-Vera M. Towards an automatic semantic data integration: Multi-agent framework approach[C]//Proceedings of the Chapter in Sematic Web.In-Tech Education and Publishing KG, 2010.
[6] Li J, Tang J, Li Y, et al. Rimom: A dynamic multistrategy ontology alignment framework. Knowledge and Data Engineering[C]//Proceedings of the IEEE Transactions on 21, 2009: 1218-1232.
[7] Zhang D, Lee W S. Web taxonomy integration using support vector machines[C]//Proceedings of the 13th international conference on World Wide Web (WWW). New York, 2004: 472-481.
[8] Rong S, Niu X, et al. A Machine Learning Approach for Instance Matching Based on Similarity Metrics[C]//Proceedings of the Semantic Web-ISWC 2012: 460-475.
[9] Nezhadi A.H, Shadgar B, Osareh A. Ontology alignment using machine learning techniques[J]. International Journal of Computer Science & Information Technology (IJCSIT), 2011,3(2):139.
[10] 梅立军, 周强等. 知网与同义词词林的信息融合研究[J]. 中文信息学报. 2005,19(1):63-70.
[11] Matthew H, Simon J, Georgina M. A Practical Guide To Building OWL Ontologies Using Protégé 4 and CO-ODE Tools(1.)[J]. (2007-10-16)[2008-02-27].http://protege.stanford.edu,2001.
[12] 董振东. 语义关系的表达和知识系统的建造[J]. 语言文字应用,1998,(3):76-82.
[13] 刘杨,俞士汶,于江生. CCD语义知识库的构造研究[J].小型微型计算机系统. 2005,26(8):1411-1415.
[14] Melnik S, Garcia-Molina H, Rahm E. Similarity Flooding: A Versatile Graph Matching Algorithm and Its Application to Schema Matching[C]//Proceedings of the 18th International Conference on Data Engineering (ICDE), 2002: 117-128.
[15] Duchateau F, Bellahsene Z, Coletta R. A flexible approach for planning schema matching algorithms[M].On the Move to Meaningful Internet Systems: OTM 2008. Springer Berlin Heidelberg, 2008: 249-264.

向春丞(1988—),硕士研究生,主要研究领域为计算语言学。E⁃mail:ccxiang@pku.edu.cn穗志方(1970—),通讯作者,博士,教授,主要研究领域为计算语言学、文本知识工程。E⁃mail:szf@pku.edu.cn詹卫东(1972—),博士,教授,主要研究领域为现代汉语语法、计算语言学、语言知识工程。E⁃mail:zwd@pku.edu.cn
中国中文信息学会语音专委会举办“见证言语工程(二)”纪念册发布会
2015年4月18日,中国中文信息学会语音信息处理专委会在清华大学FIT大楼举办“见证言语工程(二)”纪念册发布会。
我国音韵学和语言学的研究有较长的历史,但言语工程、实验语音学的研究只有几十年历史。面对世界高技术蓬勃发展、国际竞争日益激励的严峻挑战,国内一批专家开创了言语相关的研究。“见证言语工程”纪念册(第二册)收录了中国社会科学院鲍怀翘研究员、同济大学计算机系柴佩琪教授、中国科学院声学所李昌立研究员、中国科学院自动化研究所陈道文硏究员、清华大学计算机科学与技术系吴文虎教授、中国科学院声学研究所吕士楠研究员和中国社会科学院语言研究所曹剑芬研究员等七位80岁以上老专家的事迹,内容包括老专家自述语音研究历程、科研成果、学术论著和个人感悟等,是我国言语和语音信息处理珍贵的历史记录和见证。
纪念册收录的80岁以上言语工程领域的老专家们齐聚发布会,共同见证我国言语工程前进的风雨历程,一一讲述了“见证言语工程(二)”产生的经过,撰写时的感触。
此次发布的《见证言语工程(二)》是2013年4月发布的《见证言语工程(一)》纪念册的续册。《见证言语工程(一)》收录了方棣棠、张家騄、袁保宗、徐近霈、黄泰翼和林茂灿等六位时年80岁以上老专家为我国言语工程领域所做的开创性的工作。该系列的纪念册“前言”由中国科学院院士、清华大学教授张钹撰写;“题字”有中文信息学会理事长、哈尔滨理工大学教授李生提写;由蔡莲红教授整理完成。Dolby公司赞助了该系列纪念册的出版及发布。袁保宗教授作为第一册的代表,参加了本次发布会。
参加此次发布会的人员包括学会副秘书长杨尔弘教授、专委会主任清华大学郑方教授、专委会前主任清华大学蔡莲红教授、专委会副主任中科院自动化所陶建华研究员、哈尔滨工业大学韩纪庆教授、专委会秘书长清华大学贾珈副教授,全国人机语音通讯学术会议常设机构委员会主席团成员北京交通大学朱维彬教授、清华大学徐明星副教授和王东博士,以及30余位师生代表,蔡莲红教授主持了发布会,杨尔弘教授代表中国中文信息学会、郑方教授代表语音专委会分别致辞。
On Mapping between HowNet and CCD
XIANG Chuncheng1, SUI Zhifang1,2, ZHAN Weidong1
(1. Key Laboratory of Computational Linguistics(Peking University), Ministry of Edacation, Peking University, Beijing 100871, China; 2. Collaborative Innovation Center for Language Ability, Xuzhou, Jiangsu 221009, China)
Ontology matching is the key solution to the semantic heterogeneity problem.Focusing on the Noun concept of HowNet and CCD, this paper applies machine learning to identify the initial mapping relationships, disicussing the the feature selection, sample collections division and classifier selection. Further, employing the overall structure of the ontology, the similarity propagation algorithm is introduced to adjust the initial mapping globally. Experiment result shows that the precision of 1:1 and 1:n mapping relationships reaches 94% and 87.5%, respectively.
ontology matching; machine learning; stratified cross sampling; similarity propagation algorithm
1003-0077(2015)03-0044-08
2013-04-08 定稿日期: 2013-07-28
国家重点基础研究发展计划(2014CB340504),国家自然科学基金(61375074)。
TP391
A
