我国房地产开发企业X-效率研究
——基于沪深房地产上市公司面板数据
2015-04-17汪智慧
■赵 伟 汪智慧
我国房地产开发企业X-效率研究
——基于沪深房地产上市公司面板数据
■赵 伟 汪智慧
本文选取92家沪深房地产开发上市公司2005—2013年的面板数据,通过随机前沿模型中的TFE和TRE模型来估计X-效率,结果发现:企业X-效率的均值在0.33到0.47之间,呈现一定的变动;不同组织形式和资产规模的企业X-效率存在着明显的区别,民营企业较高而国有企业较低,资产规模较大企业高于资产规模较小公司;全国性企业较区域性企业在2005—2009年较低,而在2010—2013年较高。因此,必须完善房地产开发企业法人治理结构,优化薪酬管理和信息沟通机制,支持和稳定房地产市场。
随机前沿模型;房地产开发上市公司;X-效率
赵 伟,武汉大学经济与管理学院经济学系副主任,武汉大学马克思主义理论与中国实践协同创新中心学术部副部长,武汉大学中国住房保障研究中心副主任、副教授、硕士生导师,博士;
汪智慧,武汉大学经济与管理学院硕士生。(湖北武汉 430072)
一、引言
1998年城镇住房制度改革以来,我国房地产市场经历了超级繁荣,但随着我国进入经济调整期,全国百城住宅均价在近两年内首次出现环比下跌的现象,房地产市场面临下行的压力,前期发展所积累的一些问题开始浮出水面,其中受到广泛关注的问题是房地产业的效率问题。一方面,房地产业对宏观经济有很强的带动效应。况伟大研究发现,房地产业和建筑业占GDP的比重均值合计为9.92%,其对经济增长率的贡献平均每年达0.99个百分点[1]。国民经济平稳发展的政策目标,使得房地产业的平稳健康发展显得极为重要。2014年中央政府工作报告首次提出“针对不同城市情况分类调控”,区别于自2005年以来以房价为主要控制目标的政策导向,提高效率将成为政府今后一段时期对房地产市场调控的方向。另一方面,效率是房地产企业优胜劣汰的基本准则。陈必安认为,我国房地产行业的上市公司整体效率偏低,存在着大约40%的潜在利润提升空间[2]。房地产业正处于从粗放到精细化转型的关口,房地产企业如何促进自身的竞争力并获得长期发展,发掘导致无效率的内部因素并进而消除这些因素带来的影响,是公司首先要考虑的问题。因此,对我国房地产行业上市公司的效率研究以及如何提升其效率引起了社会的高度关注。
房地产开发企业的效率可分为配置效率和X-效率,其中,X-效率是指企业生产效率在排除了技术进步和投入要素配置变化的情况下所剩余的效率[3]。对我国房地产开发企业X-效率的确定以及提高有着非常重要的意义:在理论上,本文采用适合样本数据的随机前沿模型最新进展成果,减少对X-效率的估计偏差;在现实意义上,对现阶段房地产开发企业X-效率的测算,有助于认识房地产行业的发展状况以及企业的生产状态,进而为房地产市场结构调整提供切实可行的决策,以发挥房地产业的经济支柱效应,使得我国经济可持续发展。
二、文献回顾
(一)X-效率
在微观经济理论中,企业的目标是通过有效地配置投入和产出来达到利润最大化或成本最小化。实际上,作为决策单元的企业并不一定在与它们的可得资源相一致的生产可能性边界上经营,其实际生产轨迹往往在生产可能性边界以下。Farrell将企业效率分为技术效率和配置效率[3],持有相似观点的是Yotopoulos和Lau[4],前者指企业在相同可测的投入数量的条件下生产出最大量产品,后者则是将一定投入价格和产出水平纳入考虑范围内最大化利润。如果企业不能达到生产理论最优边界,则认为企业生产无效率。企业间经济效率的不同可能由技术效率引起,也可能出于配置效率的不同。国内外许多学者曾用不同的方法对此进行过详尽的阐述。Hicks认为由于垄断企业拥有对投入要素价格直接的影响力故能够达到有效率的生产[5]。在此基础上,Debreu[6]和Farrell[3]进一步指出,在一些案例中经理人缺乏市场势力导致了企业的无效率。Harvey Leibenstein[7]将配置效率之外存在的其他效率类型等“非配置效率”称为“X-效率”,认为动机是其主要构成要素,并且在许多情形中X-效率是显著的,很有必要在增长过程方面改进X-效率。
(二)随机前沿分析方法的发展
随机前沿分析法(简写为SFA)是目前国内学者估算房地产行业效率所采取的两大主流方法之一,另一个是数据包络法(简写为DEA)。从DEA被应用于房地产行业的文献可以看出,这类文献选取地区——比如省或城市——作为房地产行业的效率决策单元,实际上企业才是做决定和执行经济活动的标准单元,这种不匹配使得以上研究所使用的数据缺乏信度。在技术上DEA还存在着以下内在的缺陷:一方面,它将多产出与多输入简化为单一产出-输入形式,采用线性规划计算出效率值;另一方面,在许多情况下它的非随机性质限制了研究者获得全面和可持续的结果。然而,作为一种经济计量方法的SFA巧妙地避免了这一问题,它比较灵活,能够区分变量在外部随机误差与技术效率的影响,通过设定潜在的成本/生产/利润函数结构,直接估计出企业的技术效率。近十几年房地产行业经历了以改善行业效率为目标的制度改革,主要为刺激机制框架,如价格区间和收入区间管制。因此,用随机前沿边界模型来估计房地产行业的生产效率水平越来越得到偏爱。
SFA在以下两个方面优于DEA:(1)其边界函数包含了统计噪音。(2)允许对估计值进行统计检验。但是,由于SFA设定了生产函数的具体形式,可能会由于错误的函数设定而造成估计偏差,然而这一问题可以通过采用多样化的函数形式来缓解随机前沿方法中的过度参数化问题。
(三)国内关于房地产行业应用随机前沿模型的相关研究
陈必安[2]通过对2000—2006年34家沪深房地产上市公司的财报数据研究发现,房地产上市公司的经营效率估值逐年增加,但整体效率偏低。这一现象被张红和王悦[8]再次证实,后者进一步研究发现,我国房地产上市公司X-效率差异较小且呈现趋同现象,而且随着资产规模、控股形式、业务地域布局等的差异,企业呈现出不同的效率状态。
已有对房地产开发公司效率研究的文献在以下两方面受到限制:第一,随机前沿方法在已有文献中的使用十分有限,目前国内估计效率普遍采用Battese and Coelli[9](简写为bc92)与Battese and Coelli[10](简写为bc95)模型,然而这只占已开发出的随机前沿模型的一小部分,而且这两个模型本身也存在限制。例如,bc92和bc95模型都设定截距在决策单元间是相同的,在非时变不可观察因素存在的情况下,这些模型会产生设定偏差,这种影响现在被无效项捕捉了,从而产生有偏差的结果。现有模型一直在改进并且持续有更为灵活与合理的模型被开发出来,新模型很少被反映在国内的研究中。第二,建立并精确使用适合给定研究目标与使用数据特征的随机前沿模型十分必要,比如,被频繁使用的bc92模型在评估有变化的时变效应时有优势,但是,如果所有样本公司的效率是同一个时变模式,则bc92受到限制。另外,如果在分析面板数据时使用截面数据模型,结果会由于不能利用面板数据的优势而出现偏差。
本文首次采用SFA时变最新模型真值固定效应模型(简称为TFE)和真值随机模型(简称为TRE)[11][12]来集中研究房地产开发企业X-效率,意欲将对房地产开发上市公司X-效率的研究限定在计量经济技术最新的进步上。
三、TFE和TRE随机前沿模型
本文所选采取模型的基本公式如下:
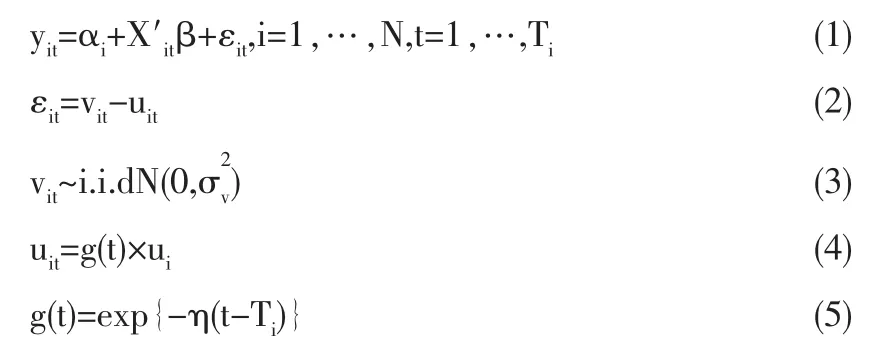
其中,yit是公司i在t时的产出对数,xit是投入对数的向量,t是代表技术变化的时间趋势项,误差项εit由双边误差项vit和单边误差项uit组成,vit代表统计噪音,uit代表技术无效性。假设个体具有特定的截距,vit服从正态分布,无效项uit具有时变特征且服从指数分布。
具体而言,它包含三种时变无效项随机前沿模型:(1)基于自变量与单元特定效应相关数据样本的正态-指数真值固定效应模型(简记为TFE1);(2)基于自变量与单元特定效应相关数据样本的正态-指数真值随机模型 (简记为TRE1);(3)基于自变量与单元特定效应不相关数据样本的正态-指数真值随机模型 (简记为TRE2)。
TFE需要解决两个关于非线性面板数据模型的问题:第一,由较大维度的参数空间所导致的纯粹计算问题,这可用极大似然哑变量方法解决;第二,当单元的数量相比面板的长度相对大的时候产生的附加参数问题,这时单元特定的截距是不一致估计的。不一致性污染了方差参数,而方差参数是对无效性进行二次评估中的关键因素,一般认为当面板的长度大于等于10时MLDV方法方才是合适的[13]。
在TRE中,αi实际上由固定效应α和单元随机特有效应wi整合而成,即形式如下:

将普通项整合为α+wi,是为了通过最大化似然来估计该随机效应模型。另外,通过模拟来整合合成扰动项εit。
本文选取的三个模型可以将随时间变化的无效性,从单元特定的时间不变的无可观测异质性中清理出来。它们不仅解决了模型在非时变不可观察因素存在的情况下,由于设定决策单元具有相同的截距所带来的设定偏差问题,而且允许从时变异质性中分离出非时变无效项。有人可能认为,一部分非时变不可观测的异质性的确属于无效项,或者这两个成分根本不应该分开。不过,正如Greene指出,在式(1)中无论设定αi或α,没有一个是令人满意地从事实推断结论,并且选择应是由手中数据的特征而定。另外,Greene考虑了时滞因素,由于房地产企业的生产周期为2~3年,如果模型不考虑时滞因素将导致有偏的无效项。
四、实证结果
(一)数据及其描述性统计
1.数据选取
本研究使用的数据来自国泰安数据库CSMAR和新浪财经网站提供的公司年报。样本的选取参照沪深上市公司中的“房地产”子板块,这一板块提供了关于房地产开发较为全面的样本。①
本文所使用数据为面板数据,以获得较截面数据更丰富的信息集,并放松一些有关截面数据模型所做的假设,以便得到关于无效项更现实的特征。在变量的选取上,由于经济数据的不充分和难于获取,许多本应该应用在本文的变量受到了限制。比如,由于在各年中房地产上市公司的职工人数较难获取,而职工人数与财务报表中应付工资及福利一项有较强的相关性,本文选择应付工资及福利来替代职工人数。另外,资本投入依照固定资本净值来测量,产出变量则以营业收入来代替。
2.数据的统计性描述
表1显示了用来估计前沿边界生产函数的变量的描述性统计值。
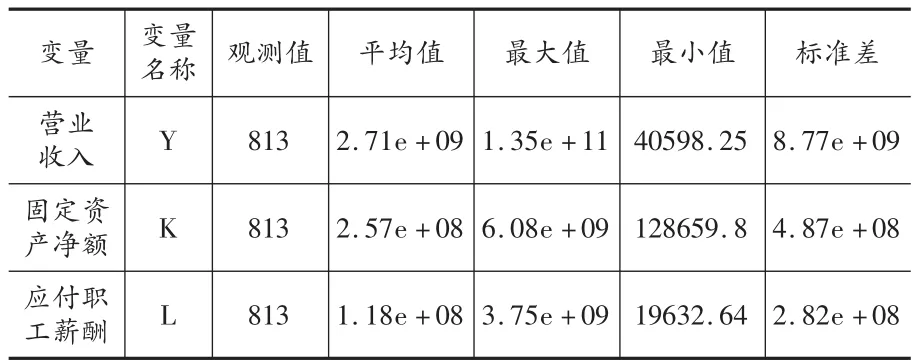
表1 估计前沿边界生产函数的描述性统计 (单位:百万元)
(二)模型对比与X-效率估计
1.超越对数生产函数
为了估计技术效率,需要对生产函数形式作出假设。已有文献一般采用柯布-道格拉斯生产函数和超越对数生产函数来模拟实际生产过程。然而,柯布-道格拉斯函数是凹性的,在被应用于随机模型时存在以下两个问题:(1)它遗漏的特征增加了误差项成分的方差,进而降低模型的统计的效率性,使得无效率得分被高估,一旦不可观测的因素和解释变量相关则也会引起有偏估计;(2)它假设在任何产出水平下公司满足规模报酬不变,这个假设不允许任何二阶形式,由于不同的房地产公司相对资产规模差距较大,因而这一假设十分不恰当。超越对数生产函数放松了这一假设,它使用二阶形式将产出由于规模经济而带来的变化纳入考虑。这种方法的后果是大量的待估参数问题,这些问题将影响非时变随机模型的模拟似然最大化过程,可以通过采用时变随机前沿模型来解决。因此,本文选用超越对数生产函数来分析技术效率。
本文基于92家沪深房地产上市公司在9年(2005—2013年)中的非平衡面板数据。数据集对一般研究者而言是可得的:只有投入和产出变量,产出的异质性,少于理想状态的投入。产出变量是上市公司每年在年报中披露的营业收入,单位以元计。本文在实证分析中采用的函数形式是下面的超越对数生产函数:
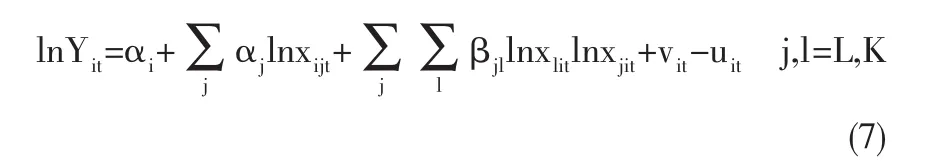
在上式中,下标i和t分别是个体公司和时间的下标;Yit是产出,即营业收入;xit为投入要素;下标j和l是劳动(L)和资本(K)。vit~i.i.dN(0,σ2v)是典型的统计误差项,这种统计误差是在任何关系中都可以找到的,uit是一个单边误差项。本文假设vit独立于uit。在第一个模型中,假设公司的无效项是固定不变的,因此公司个体的效应包含了无效项。在第二个和第三个模型中,公司的无效项随时间而变化。在这些模型中,偏峰状的随机误差项被翻译为无效项。在所有的模型中,公司的技术效率和解释变量无关。
2.模型对比
在这些含大量交叉项和较短时期的面板数据案例中,或许会发生事件参数问题。然而,伴生参数不影响TRE1的方差估计,但TFE数据会使得前沿边界和参数估计有偏。TRE2是使用面板数据估计无效项的最好的模型,因为时间参数问题的可能性对模型1是内在的,而TRE2考虑了技术效率和解释变量相关的事实。对于随机前沿模型,在样本空间中每期最有效的公司被认为是完全有效的,因此无效项的最小值是0。TRE1显示了较高的无效率水平,并且其分布也较为分散易变,然而其他模型的估计值较为相似。表2给出了模型估计结果。
为了显示不同模型公司效率排序的紧密程度,本文在全样本公司水平上计算了斯皮尔曼序列相关系数。其中,对于含有时变效率的模型,效率得分是公司在样本期的平均效率分数。结果显示,不同模型的使用导致了不同的待估效率的排序,且无效项间的线性相关关系非常强,例如TFE1和TRE1的斯皮尔曼序列相关系统为0.9235。考虑到估计的边界参数的相似度,高度相关的事实是可以理解的。由于附加参数问题,经过正确设定的TRE估算出的无效率在平均上比经过正确设定的TFE所估算出的无效率值偏差要小。所以,本文将选取TRE2的数据进一步分析2005—2013年房地产上市公司X-效率。
3.X-效率估计及分析
本文先从整体上对统计分析结果进行描述,然后分别从业务地区范围、资产规模和组织形式三个方面来分析2005—2013年房地产上市公司样本数据所测得的X-效率。2005—2013年房地产上市公司样本数据的X-效率描述如表3。
在2005—2013年中,总体上房地产上市公司的X-效率均值在0.33至0.47之间;房地产上市公司的X-效率均值呈现一定的变动,在2005—2008年呈现上升趋势,在2010—2013年则不断下滑。
依据房地产企业的行业特征,以下将分析业务地区范围、资产规模和组织形式三个因素对房地产上市公司的X-效率的影响。其中,按照业务地区范围可将房地产上市公司分为地域性房地产公司和全国性房地产公司两类。根据2013年公司年报总资产数据,将房地产上市公司以10亿元总资产、100亿元总资产和1000亿元总资产为分割线进行分类;按照组织形式,将房地产上市公司分为国有企业、民营企业、国有相对控股企业、民营相对控股企业和中外合资企业。表3展示了统计结果。为了更好地观察,本文将表3中按照资产规模分类和按照组织形式分类的X-效率数据转化为图形式,见图1-3。它们分别显示了2005—2013年房地产上市公司按照组织形式、资产规模和业务范围分类的效率均值变化。从图1可以看出,2005—2013年国有相对控股房地产上市公司X-效率较其他类企业偏高,而国有企业房地产上市公司X-效率在类别中表现较差;民营企业在2005—2006年表现不佳,随后其X-效率均值较其他4种公司的该项数值偏大。总体而言,各类公司X-效率有趋同的走向。从图2可以看出,2005—2009年房地产上市公司按资产规模分类X-效率差别较大,2009—2013年1000亿元以上企业X-效率明显高于资产规模较小的企业,且1000亿元以下的房地产上市公司X-效率值出现明显的下滑趋势。从图3可以看出,2005—2009年全国性房地产公司X-效率较低,而2010—2013年该值高于区域性房地产企业的X-效率估计值。
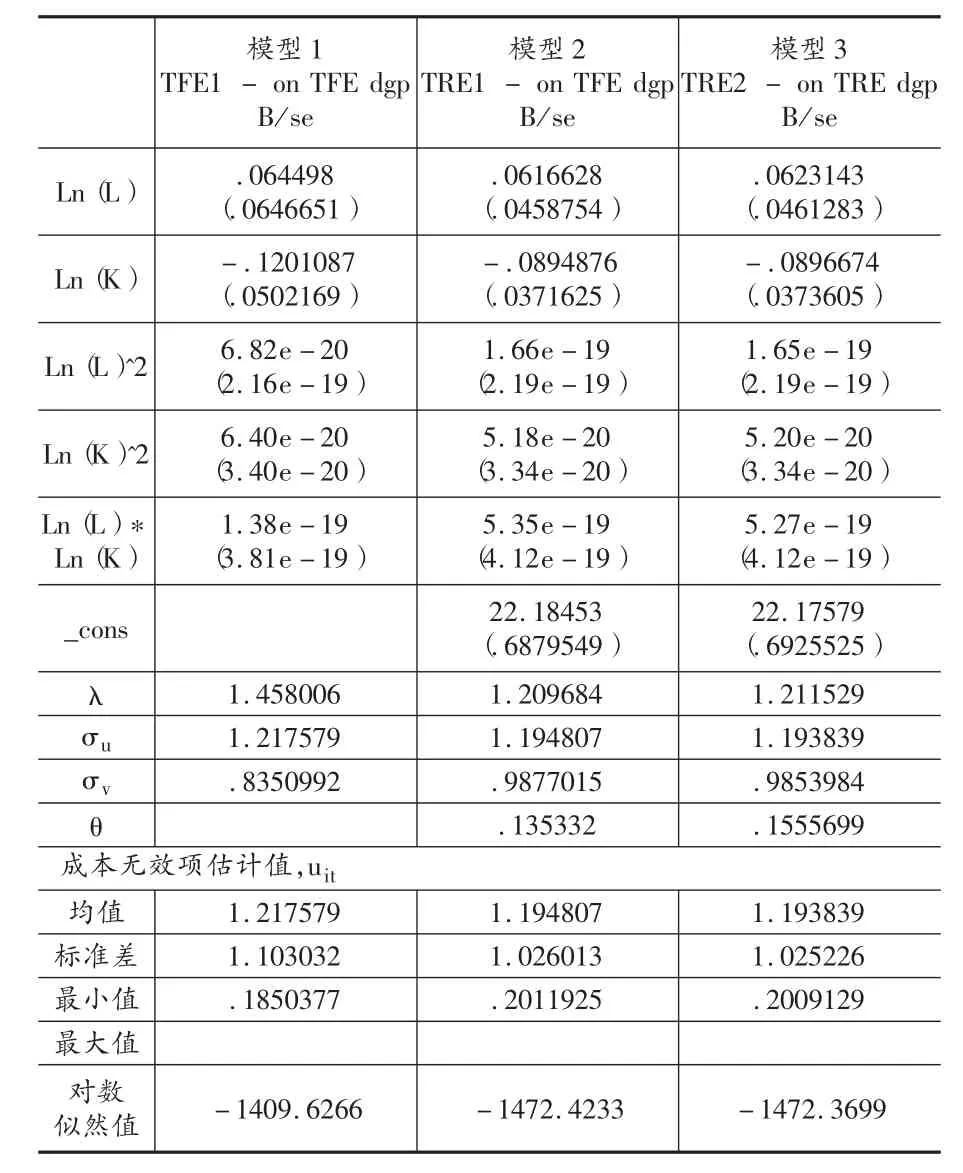
表2 沪深房地产开发上市公司统计结果
五、结论与建议
本文利用沪深房地产开发上市公司在2005—2013年微观水平的面板数据,讨论了房地产开发企业X-效率的理论和经验研究问题。基于TFE和TRE模型来估计X-效率,结果发现:(1)2005—2013年房地产开发上市公司X-效率的均值在0.33到0.47之间,房地产开发上市公司的X-效率均值呈现一定的变动,在2005—2008年呈现上升趋势,在2010—2013年则不断下滑;(2)不同组织形式和资产规模的房地产开发上市公司的X-效率存在着明显的区别,近年来,民营企业的X-效率较高而国有企业的X-效率较低,而资产规模较大的企业的X-效率高于资产规模较小的企业的X-效率;(3)2005—2009年全国性房地产开发企业X-效率较低,而2010—2013年该值高于区域性房地产企业的X-效率估计值。这一结论表明,目前我国房地产行业普遍存在着X-效率较低的问题,在经济新常态的背景下,国
有房地产企业以及总资产规模较小的房地产企业面临着市场转型较大的风险。本文提出以下建议。
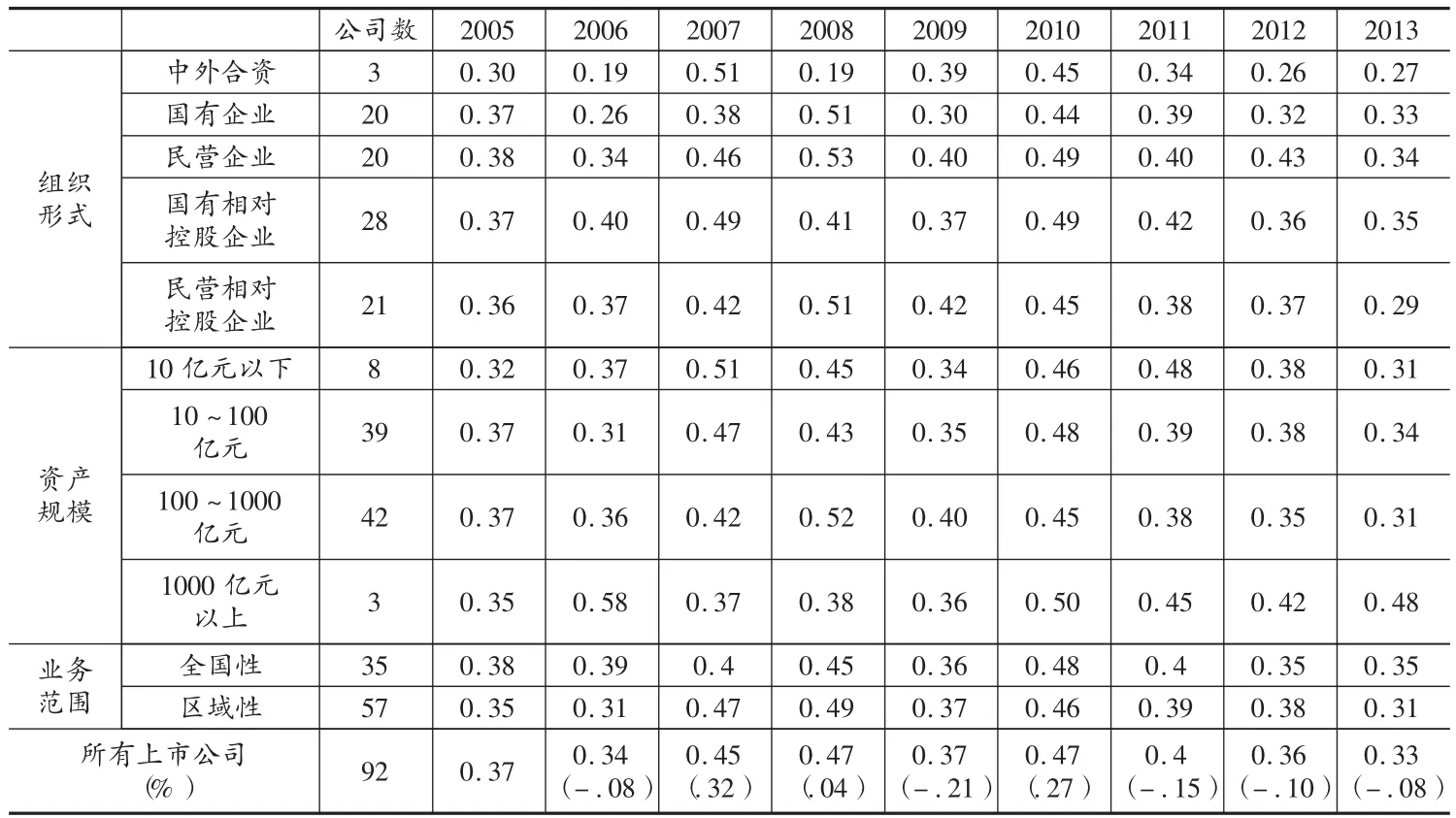
表3 2005—2013年所有房地产上市公司样本X-效率均值分类统计
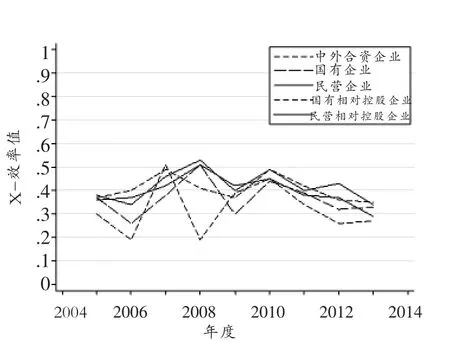
图1 2005—2013年按组织形式划分房地产上市公司X-效率均值统计
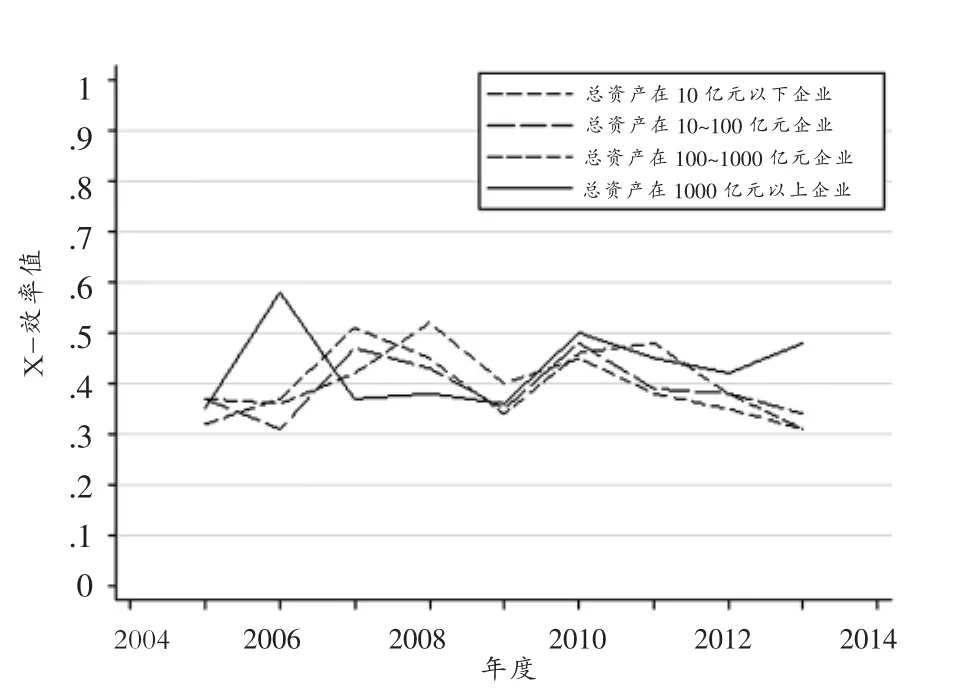
图2 2005—2013年按资产规模划分房地产上市公司X-效率均值统计
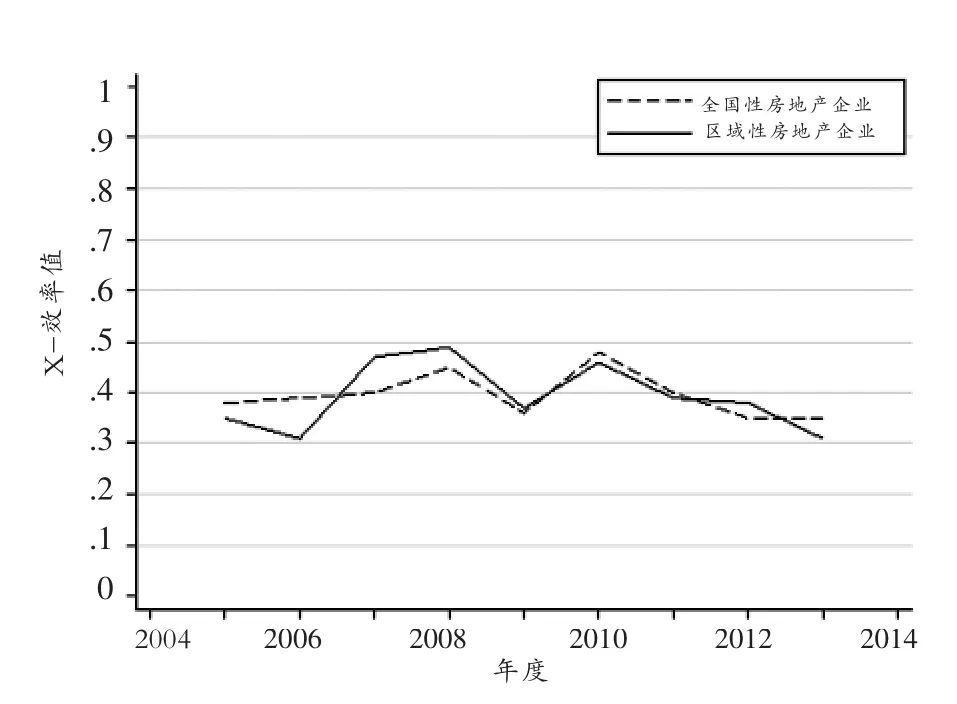
图3 2005—2013年按经营范围划分房地产上市公司X-效率均值统计
首先,完善房地产开发企业法人治理结构。房地产开发企业应改变目前较为普遍的家族制结构,聘用职业经理人,规范管理层与董事等的权责,保证房地产企业决策的高效性与正确性。
其次,在公司业务范围方面,公司应该结合自身特点,制定合理的区域发展计划,合理布局一、二线城市与三、四线城市的房地产开发业务。
再者,在人力资源利用方面,企业应该:优化薪酬管理,根据每种岗位特点设计相应的分层激励薪酬体系;培养企业文化,设计适宜员工工作的环境,增强员工对企业的忠诚度和工作效率;完善企业上下级之间以及部门之间的信息沟通机制,包括举办企业内部社交活动和短期部门间轮岗等,减少企业因沟通而造成的效率损失。
最后,在行业层面,我国房地产业协会应尽快完善房地产行业自律规范,尤其是关于违规行为的惩罚条例,并确保协会成员严格按照规范执行。同时,政府应制定支持和稳定房地产市场的政策,包括贷款利率、房产税改革、公积金政策等。
注释:
①本文样本做了以下筛选:(1)为了集中关注房地产开发类公司,样本剔除了分类为房产服务和园区开发的上市公司,前者如海印股份 (000861),后者如高新发展(000628)、中国国贸(600007)等;(2)根据房地产开发业务在公司业务中的情况来筛选样本,排除房地产开发业务占公司业务较低的公司,例如,中国宝安(000009)因房地产开发业务在公司去年全年收入中仅贡献11.03%而不在样本中,而幸福实业(600743)在2008年与北京市华远地产股份有限公司进行换股吸收合并,并将主营业务从服装、电力开发等转为房地产开发、销售商品房等,故其2005—2008年数据记为缺失;(3)删除了一些缺失部分数据的样本,例如,荣安地产(000517)由于在2006—2009年未上市而被从样本区间排除,顺发恒业(000631)由于在2009年合并报表使得样本区间会计内容不一致而被排除。
[1]况伟大.房地产相关产业与中国经济增长[J].经济学动态,2010,(2).
[2]陈必安.基于随机前沿方法的我国房地产上市公司X-效率分析[J].西北农林科技大学学报(社会科学版), 2008,(5).
[3]M.J.Farrell.The Measurement of Productive Efficiency.JournaloftheRoyalStatisticalSociety,1957,(3).
[4]PanA.YotopoulosandLawrenceJ.Lau.ATestforRelativeEconomicEfficiency:SomeFurtherResults.AmericanE-conomicReview,1973,(1).
[5]J.R.Hicks.A Suggestion for Simplifying the Theory of Money.Economica,New Series,1935,(5).
[6]GerardDebreu.TheCoefficientofResourceUtilization. Econometrica,1951,(3).
[7]HarveyLeibenstein.AllocativeEfficiencyvs."X-Efficiency".AmericanEconomicReview,1966,(3).
[8]张红,王悦.我国房地产上市公司X效率测算与统计分析——基于随机前沿方法 [J].中国房地产,2013,(24).
[9]G.E.Battese,T.J.Coelli.Frontier Production Functions,Technical Efficiency and Panel Data:with Application to Paddy Farmers in India.Journal of Productivity Analysis, 1992,(5).
[10]G.E.Battese,T.J.Coelli.AModelforTechnicalInefficiencyEffectsinaStochasticFrontierProductionFunctionfor PanelData.EmpiricalEconomics,1995,(20).
[11]Greene,W.ReconsideringHeterogeneityinPanelData Estimators of the StochasticFrontier Model.Journal of Econometrics,2005,(2).
[12]Greene,W.Fixed and Random Effects in Stochastic Frontier Model.Journal of Productivity Analysis,2005,(1).
[13]Belotti,F.,and G.Ilardi.Consistent Estimation of the “true”Fixed-effects Stochastic Frontier Model. CEIS Tor Vergata:Research Paper Series,2012,(10).
【责任编辑:陈保林】
F293.3
A
1004-518X(2015)08-0055-07
教育部人文社科项目“公共租赁住房配租机制研究”(12YJC790061)
